2025年5月15日·1 分
顧客データをエンリッチするWebアプリの作り方
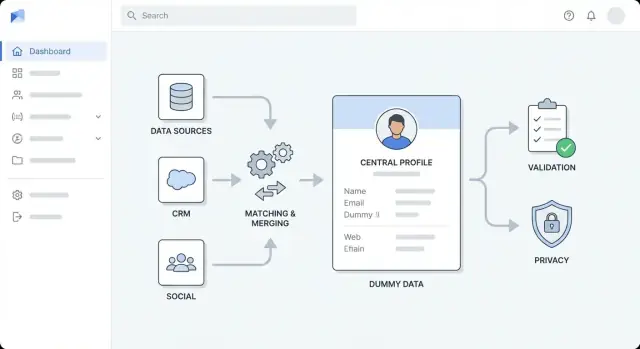
顧客レコードをエンリッチするWebアプリの作り方:アーキテクチャ、統合、マッチング、検証、プライバシー、監視、導入のポイントを解説します。
目的、ユーザー、エンリッチ範囲を定義する
ツールを選んだりアーキテクチャ図を引く前に、「エンリッチ」が組織で何を意味するかを正確に定義してください。チームはしばしば複数のエンリッチの種類を混ぜてしまい、進捗を測れなかったり「完了」の基準で揉めたりします。
何がエンリッチに該当するか?
改善したいフィールドカテゴリと理由を明確にしましょう:
- ファーモグラフィック:会社規模、業界、本社所在地、資金調達ステージ
- コンタクト:役職、検証済みメール/電話、役職レベル、役割
- 行動指標:プロダクト使用シグナル、インテント、エンゲージメントスコア
- カスタム項目:社内テリトリー、アカウント階層、ICP適合スコア
どのフィールドが必須で、どれがあると良いか、そして決してエンリッチしてはいけない(例:機微な属性)フィールドを明示してください。
アプリを誰が使い、何のために使うか?
主要なユーザーとその主要タスクを特定します:
- Sales ops:重複削減、アカウントの標準化、ルーティング改善
- Marketing ops:リードのエンリッチでセグメンテーションとターゲティングを改善
- Support:チケット対応時にアカウントコンテキストを提示
- Analysts:信頼できるデータセットでのレポート作成
各ユーザーグループは異なるワークフロー(バルク処理 vs 単一レコードのレビュー)を必要とするため、早い段階でニーズを把握してください。
成果、スコープの境界、成功指標を定義する
成果を定量的に列挙します:マッチ率の向上、重複の減少、リード/アカウントのルーティング高速化、セグメンテーション精度の改善など。
スコープの境界も明確に:どのシステムが対象か(CRM、請求、プロダクト分析、サポートデスク)を最初のリリースで含めるか除外するか決めます。
最後に成功指標と許容できる誤差率(例:エンリッチ適用率、検証率、重複率、エンリッチが不確実なときの「安全失敗」ルール)を合意してください。これは以降の構築の指針になります。
顧客データのモデル化とギャップの特定
何かをエンリッチする前に、システム内で「顧客」が何を意味するか、既に何を知っているかを明確にします。これにより、保存できないエンリッチに課金したり、後で混乱するマージを避けられます。
現在のフィールドとソースのインベントリ
名前、メール、会社、ドメイン、電話、住所、役職、業界などのフィールドカタログを作り、各フィールドの出所(ユーザー入力、CRMインポート、請求システム、サポートツール、プロダクトのサインアップフォーム、エンリッチプロバイダー)を記録します。
また、どのように収集されるか(必須か任意か)と変化頻度も記録してください。例えば役職や会社規模は時間で変化する一方、内部の顧客IDは原則変わらないはずです。
アイデンティティモデルを定義:個人、会社、アカウント
多くのエンリッチワークフローは少なくとも二つのエンティティを扱います:
- 個人(コンタクト/リード):メール、電話、役割を持つ個人
- 会社(組織):ドメイン、所在地、ファーモグラフィックを持つ事業体
必要なら、複数人を一つの会社に紐づけ、プランや契約日、ステータスなどの属性を持つアカウントを定義するか検討してください。
どのような関係をサポートするか(例:多くの人 → 一つの会社、一人が時間を跨いで複数の会社に所属する等)を明記します。
よくあるデータ問題を文書化する
繰り返し発生する問題を列挙します:欠損値、フォーマット不整合("US" vs "United States")、インポートで作られる重複、古いレコード、出所間の矛盾(請求先住所 vs CRM住所)など。
必須キーを選び、信頼レベルを設定する
マッチと更新に使う識別子を選びます。典型的にはメール、ドメイン、電話、内部の顧客IDです。
各識別子に信頼レベルを割り当て:どれが権威あるものか、どれが“ベストエフォート”か、どれを上書きしてはならないかを決めます。
所有権と編集権限を明確にする
どのフィールドを誰が所有するか(Sales ops、Support、Marketing、Customer success)に合意し、編集ルールを定義します:人間が変更できるもの、オートメーションが変更できるもの、承認が必要なもの。
このガバナンスにより、エンリッチ結果が既存データと衝突した際の時間を節約できます。
エンリッチソースとデータ契約を選ぶ
統合コードを書く前に、エンリッチデータの出所と利用可能範囲(保存や使用に関する制約)を決めてください。これがないと、技術的には動くがコストや信頼性、コンプライアンスを壊す機能を出してしまうことがあります。
典型的なエンリッチソース
通常は複数の入力を組み合わせます:
- 内部システム:CRM、請求、サポートチケット、プロダクト分析、メールプラットフォーム、データウェアハウス
- サードパーティAPI:会社のファーモグラフィック、コンタクト検証、業種コード、テクノグラフィック、リスクシグナル
- アップロードされたリスト:営業、イベント、パートナー、データプロバイダーからのCSV
- Webhook:メール検証やIDプロバイダー等、変化を即時に通知するツールからのリアルタイム更新
ソースの評価方法
各ソースについて、カバレッジ(有用な結果が返る頻度)、鮮度(更新の速さ)、コスト(呼び出し/レコード毎)、レート制限、利用規約(何を保存できるか、どのくらいの期間か、目的は何か)でスコアを付けます。
また、プロバイダーが信頼度スコアや明確な**出所情報(プロベナンス)**を返すかを確認してください。
データ契約を定義する
すべてのソースを契約として扱い、フィールド名とフォーマット、必須/任意フィールド、更新頻度、期待されるレイテンシ、エラーコード、信頼度の意味を定義します。
「プロバイダーフィールド → あなたの正規化フィールド」のマッピングと、nullや競合値のルールも明記してください。
フォールバックと保存の決定
ソースが使えない、または低信頼の結果を返したときの挙動を計画します:バックオフで再試行、後でキューに入れる、別のソースにフォールバックする等。
何を保存するか(検索やレポーティングに必要な安定属性)と、何をオンデマンドで計算するか(高コストまたは時事性の高いルックアップ)を決めます。
最後に、機微な属性(個人識別子、推測されたデモグラフィック等)の保存制限と保持ルールを文書化します。
ハイレベルなアーキテクチャを設計する
ツールを選ぶ前に、アプリの形を決めてください。明確なハイレベルアーキテクチャはエンリッチ作業を予測可能にし、“一時しのぎ”が恒久的な汚れに変わるのを防ぎ、チームの見積りを助けます。
チームに合うアーキテクチャスタイルを選ぶ
多くのチームはまずモジュラーなモノリスから始めるのが良いです:デプロイ単位は一つでも、内部は明確に分割(インジェクション、マッチング、エンリッチ、UI)します。構築、テスト、デバッグが簡単です。
独立したスケーリングが必要、または別チームが別々の部分を所有する明確な理由が出たらマイクロサービス化に移行します。一般的な分割例は:
- APIサービス(同期リクエスト、認証、レコードCRUD)
- ワーカーサービス(非同期エンリッチ、再試行)
- UI(レビュー、承認、バルク操作)
関心事を層に分ける
変更が全体に波及しないよう境界を明確にします:
- インジェスト層:CRMやファイルからの取り込みと正規化
- エンリッチ層:ベンダー/内部ソースの呼び出しと結果保存
- 検証層:データ品質ルールの適用と例外フラグ
- ストレージ層:顧客プロファイル、生データペイロード、監査履歴
- プレゼンテーション層:UIビュー、レビューキュー、承認
初めから非同期エンリッチを設計する
エンリッチは遅く、失敗しやすい(レート制限、タイムアウト、部分的なデータ)ので、ジョブとして扱います:
- APIはジョブを作り応答を早く返す
- ワーカーはキュー経由でジョブを処理(再試行とバックオフ付き)
- UIはジョブのステータスを表示し、再実行を可能にする
環境と設定を計画する
dev/staging/prodを早期に用意し、ベンダーキー、閾値、機能フラグはコードではなく設定で管理して、環境ごとにプロバイダーを差し替えやすくします。
1枚絵のダイアグラムで整合させる
シンプルな図(UI → API → DB、キュー → ワーカー → エンリッチプロバイダー)を用意し、実装前のレビューに使って責任範囲で合意します。
早期プロトタイピング(任意)
ワークフローとレビュー画面を先に検証したい場合、Koder.aiのようなvibe-codingプラットフォームでコアアプリを素早くプロトタイプできます:レビュー/承認用のReactベースUI、GoのAPI層、PostgreSQLのストレージ。
ジョブモデル(再試行付き非同期エンリッチ)、監査履歴、RBACを検証してからプロダクション化のためにソースをエクスポートする、という流れが有効です。
ストレージ、キュー、補助サービスを整備する
エンリッチプロバイダーをつなぐ前に“配管”を正しく整えます。ストレージとバックグラウンド処理の決定は後から変えにくく、信頼性、コスト、監査性に直接影響します。
主データベース:プロファイル+履歴
構造化データと柔軟な属性をサポートするデータベースを選びます。Postgresはコアフィールド(名前、ドメイン、業界)と半構造化のエンリッチフィールド(JSON)を両立できるため一般的です。
同様に重要なのは変更履歴の保存です。値を無音で上書きするのではなく、誰/何がいつどのように変えたか(例:「vendor_refresh」「manual_approval」)を記録してください。承認やロールバックの際に役立ちます。
キュー:エンリッチと再試行
エンリッチは本質的に非同期です:APIはレート制限する、ネットワークは失敗する、ベンダーは遅い。バックグラウンド用のジョブキューを導入します:
- 単一レコードとバルクのエンリッチ要求
- バックオフ付き再試行
- 定期リフレッシュ(例:30/90日ごと)
- 繰り返し失敗するジョブのデッドレター処理
これによりUIは応答性を保ち、ベンダー障害でアプリ全体がダウンするのを防げます。
キャッシュ:高速検索とレート管理
小さめのキャッシュ(多くはRedis)が、頻出クエリ(例:「ドメインで会社を検索」)やベンダーのレート制限・クールダウン管理に役立ちます。冪等キーの保存にも便利で、重複インポートで重複エンリッチを防げます。
ファイルストレージと保持
CSVのインポート/エクスポート、エラーレポート、レビューで使う差分ファイル用のオブジェクトストレージを計画します。
保持ルールも早めに定めてください:デバッグや監査のために生のベンダーペイロードを必要最小限に保存し、ポリシーに沿ってログを期限切れにします。
インジェストと正規化パイプラインを構築する
ユーザーに公開する
新しいアプリをデプロイ・ホスティングし、本番準備ができたらカスタムドメインを追加。
エンリッチアプリは、投入するデータの質で決まります。インジェストは情報がシステムに入る方法を決め、正規化はマッチ、エンリッチ、レポートに十分一貫した形に整えます。
データの入り口を決める
多くのチームは複数の入力を使います:
- プロダクトや内部ツールが新規/更新顧客を送るAPIエンドポイント
- CRMや請求システムからのWebhookで近リアルタイム更新
- プッシュできないシステム向けの定期取得(夜間同期)
- バックフィルや一時的なアップロード用のCSVインポート
いずれを採用するにせよ、"生の取り込み"ステップは軽量に保ちます:データを受け取り、認証し、メタデータをログし、処理用にキューイングするだけにします。
早期に正規化と標準化を行う
受け取った雑多な入力を一貫した内部形に変える正規化層を用意します:
- 名前:空白トリム、可能ならフルネーム分割、ケース処理
- 電話:E.164形式に変換、国の仮定を明示
- 住所:street、locality、region、postal code 等で正規化し、原文も保持
- ドメイン/メール:小文字化、URLの追跡パラメータ除去、構文検証
検証、隔離、冪等性を保つ
レコードタイプごとの必須フィールドを定義し、チェックに失敗したレコードは拒否または**隔離(quarantine)**します。隔離されたアイテムはUIで確認・修正できるようにしてください。
Webhookや不安定なネットワークでの再試行で重複処理が起きないよう、冪等性キーを追加します。簡単な方法は (source_system, external_id, event_type, event_timestamp) のハッシュを使うことです。
フィールドごとの由来を追跡する
できれば各フィールドごとにプロベナンス(ソース、取り込み時刻、変換バージョン)を保存します。こうすることで「なぜこの電話番号が変わったのか?」や「どのインポートがこの値を生んだか?」に答えられます。
マッチング、重複排除、マージを実装する
エンリッチを成功させるには「誰が誰か」を確実に識別することが重要です。明確なマッチルール、予測可能なマージ動作、不確かなときのセーフティネットが必要です。
マッチルール(と信頼閾値)を定義する
まずは決定的な識別子から始めます:
- 厳密キー:正規化したメール、小切手済みの顧客ID、税番号、検証済みドメイン
識別子がない場合には確率的マッチを追加します:
- あいまいマッチ:氏名+会社ドメイン、氏名+所在地、電話の類似度
マッチスコアを割り当て、閾値を設定します:
- 高閾値以上は自動マージ
- 中間は手動レビューキュー
- 低いものは拒否
重複排除とマージロジックの計画
同一顧客と判定された際のフィールド選択ルールを決めます:
- フィールド優先順位:"検証済みメールが未検証に勝つ"、"新しいタイムスタンプが勝つ"、"CRMはエンリッチよりコンタクトオーナーを優先"など
- ソース信頼スコア:ソースを順位付けして競合を解決
- 競合処理:可能なら両方の値を保持(複数の電話番号など)、負けた値は履歴に保存
監査トレイルとレビューのワークフロー
すべてのマージは監査イベントを生成すべきです:トリガーした主体、変更前後の値、いつ、マッチスコア、関連レコードID。
曖昧なマッチには、候補レコードを並べて比較するレビュー画面と「マージ/マージしない/追加情報を要求する」オプションを提供します。
誤って大量マージすることへの安全策
バルクマージには追加の確認を要求し、ジョブごとのマージ上限を設け、"ドライラン"プレビューをサポートします。
監査履歴を使ったアンドゥ(マージの取り消し)パスも用意しておくとミスが永続化しません。
エンリッチAPIの統合と信頼性対策
エンリッチは外部世界と接触する部分です——複数のプロバイダー、レスポンスのばらつき、予測不能な可用性。各プロバイダーをプラガブルなコネクタとして扱い、ソースの追加・交換・無効化が容易になるように設計します。
プロバイダコネクタを作る(認証、再試行、エラー写像)
各エンリッチプロバイダーごとに一つのコネクタを作り、一貫したインターフェース(例:enrichPerson(), enrichCompany())を提供します。コネクタ内にプロバイダー固有ロジックを閉じ込めます:
- 認証(APIキー、OAuthトークン、トークン更新)
- 一時的失敗に対する標準再試行
- エラーの写像(プロバイダー固有のエラーを
invalid_request,not_found,rate_limited,provider_downのような自社カテゴリに変換)
これにより下流処理は各プロバイダーの癖に対処する必要がなくなります。
レート制限はスロットリングとバックオフで対処
多くのエンリッチAPIはクォータを課します。プロバイダーごと(場合によりエンドポイントごと)にスロットリングを行い、上限を超えないようにします。
制限に達した場合は、Retry-Afterヘッダーを尊重し、ジッタ付きの指数バックオフを使ってください。
タイムアウトや部分応答も再試行対象としてとらえ、無視しないようにします。
信頼度とエビデンスを保存する(ポリシー内で)
エンリッチ結果は確定的でないことが多いです。プロバイダーの信頼度スコアがあれば保存し、さらにマッチ品質やフィールドの完全性に基づく独自スコアも付けます。
契約やプライバシーポリシーが許す範囲で、監査やユーザー信頼のために生のエビデンス(ソースURL、識別子、タイムスタンプ)を保存してください。
マルチプロバイダ戦略:「最善を選ぶ」
複数プロバイダーをサポートする場合、選択ルールを定義します:安価優先、信頼度最高優先、フィールドごとの"ベスト"選択など。
どのプロバイダーが各属性を提供したかを記録しておけば、変更の説明やロールバックが容易です。
定期リフレッシュルール
エンリッチは陳腐化します。"90日ごとに再エンリッチ"、"キー項目の変更で再取得"、"信頼度が下がったら更新"などのポリシーを実装してください。
スケジュールは顧客やデータ種別ごとに設定可能にして、コストとノイズを制御します。
データ品質ルールと検証を組み込む
規模に合わせてプランを選ぶ
まずは無料から始め、展開が拡大したらPro、Business、Enterpriseへ移行。
新しい値が信頼できるものでなければエンリッチは意味がありません。検証を第一級機能として扱い、雑なインポート、不安定なサードパーティ応答、マージ時の誤りからユーザーを守ります。
フィールドレベルの検証ルールを定義する
まずはフィールドごとの“ルールカタログ”を作り、UIフォーム、インジェストパイプライン、公開APIで共有します。
一般的なルールはフォーマットチェック(メール、電話、郵便番号)、許容値リスト(国コード、業界リスト)、範囲(従業員数、売上帯)、依存関係(country = USならstate必須)などです。
ルールはバージョン管理して、安全に変更できるようにします。
実務に即した品質チェックを追加する
基本的な検証に加え、ビジネス上で意味のある品質チェックを実行します:
- 完全性:利用に最低限必要なフィールドは揃っているか?
- 一意性:ドメインや税IDなど“ユニーク”が重複していないか?
- 整合性:関連フィールドは矛盾していないか(国と電話番号の国番号等)?
- 最新性:値は古くないか、更新が必要か?
レコードとソースをスコア化する
チェック結果をスコアカードに落とし込みます:レコード単位(総合ヘルス)とソース単位(有効で最新の値をどれくらい返すか)。
スコアを自動化の判断に使います。例えばある閾値以上のエンリッチのみ自動適用する、など。
失敗は予測可能にルーティングする
検証に失敗したレコードを単に破棄せず、処理方針を明確にします。
一時的な問題は“data-quality”キューに送って再試行し、根本的な不備は手動レビューに回します。失敗したペイロード、ルール違反、推奨修正案を保存します。
エラーをわかりやすくする
インポートやAPIクライアントには、どのフィールドが何故失敗したのか、そして有効な値の例を明確で実行可能なメッセージで返してください。
これによりサポート負荷が下がり、クリーンアップが早まります。
レビュー、承認、バルク作業のためのUIを作る
エンリッチパイプラインは、人が変更をレビューし自信を持って下流システムに反映できて初めて価値を発揮します。UIは「何が起きたか、なぜか、次に何をすべきか」を明確にする必要があります。
設計すべきコア画面
顧客プロファイルが中心です。主要識別子(メール、ドメイン、会社名)、現在のフィールド値、エンリッチステータスバッジ(例:未エンリッチ、進行中、レビュー要、承認済み、却下)を表示します。
変更履歴タイムラインを追加し、"会社規模が11–50から51–200に更新された"のように平易な言葉で説明します。各エントリは詳細を開けるようにします。
重複候補が見つかったらマージ提案を表示します。候補レコードを横並びで表示し、推奨される"生き残り"レコードとマージ後のプレビューを提示します。
実務に合ったバルク操作
多くの作業はバッチ単位で行われます。以下のようなバルクアクションを用意します:
- 選択レコードをエンリッチ(または夜間処理にキューイング)
- 推奨マージを一括承認/却下
- 監査やオフラインレビュー用に結果をCSVエクスポート
破壊的操作(マージ、上書き)には明確な確認ステップを設け、可能なら"元に戻す"ウィンドウを提供します。
高速検索、フィルタ、フィールド別の由来表示
メール、ドメイン、会社、ステータス、品質スコアでのグローバル検索とフィルタを用意します。
「レビュー要」や「低信頼度更新」のようなビューを保存できるようにしてください。
各エンリッチフィールドには由来(ソース、タイムスタンプ、信頼度)を表示します。
「この値はなぜ?」パネルを置くと信頼を築き、無駄なやり取りを減らせます。
非技術者向けのガイド付きワークフロー
決断を二択にし、導くUIにします:"提案値を受け入れる"、"既存を維持"、"手動で編集"。詳細が必要な場合は"高度な設定"の下に隠しておきます。
セキュリティ、プライバシー、コンプライアンスの基本
エンリッチメントワークフローをプロトタイプ
チャットプランからエンリッチメントアプリをプロトタイプし、プランニングモードで調整。
顧客エンリッチアプリは機微な識別子(メール、電話番号、会社情報)に触れ、多くの場合サードパーティからデータを引くため、セキュリティとプライバシーを後回しにしてはいけません。
ロールベースのアクセス制御(RBAC)
最小権限のデフォルトで明確なロールを設計します:
- Admin:ユーザー、ロール、コネクタ、保持ポリシーの管理
- Ops:エンリッチジョブの実行、競合の解決、マージ承認
- Viewer:レポートやサポート向けの参照のみ
「データをエクスポートする」「PIIを表示する」「マージを承認する」など粒度の細かい権限を用意し、開発環境に本番データが流れないよう分離します。
機微データの保護
すべての通信にTLSを使い、データベースやオブジェクトストレージには静止時の暗号化を施します。
APIキーはシークレットマネージャで管理し、ソース管理に平文で置かないこと。定期的にローテーションし、環境ごとにスコープを限定します。
UIでPIIを表示する場合はデフォルトでマスク(末尾2–4桁のみ表示など)し、全表示には明示的な権限を要求します。
同意とデータ利用制約
エンリッチが同意や契約条件に依存する場合、その制約をワークフローに組み込みます:
- フィールドごとにデータソース、目的、許可される利用をトラッキング
- 保存する理由と範囲を文書化(社内ページ /privacy や /docs/data-handling のような短い方針が役立つ)
- 不要なフィールドは収集しない(データが少ないほどリスクは低い)
監査、保持、削除
アクセスと変更の監査トレイルを作ります:
- レコードを誰が閲覧/エクスポートしたかをログ
- 誰が何をいつ変更したか(変更前/後の値、ジョブID、プロバイダー)をログ
プライバシー要求に対応するため、保持スケジュール、レコード削除、忘れられる権利のワークフロー(ログ、キャッシュ、バックアップのコピーも可能な限り削除または期限切れ処理)を用意します。
監視、分析、運用制御
監視は稼働監視だけでなく、ボリューム、プロバイダー、ルールの変化に合わせてエンリッチの信頼性を保つ手段です。
各エンリッチ実行を計測可能なジョブとして扱い、時系列でトレンドを取れる信号を出します。
実務に役立つ指標
まずは成果に紐づく少数の指標から始めます:
- ジョブスループット(レコード/分)と1回あたりの完了時間
- 成功率と失敗率(失敗種別別:検証、マッチ、プロバイダー)
- プロバイダー待ち時間(p50/p95)とタイムアウト数
- マッチ率(どれだけ自信を持ってエンリッチを紐づけられたか)
- 防止した重複数(チェックがなければ誤ってマージされていた件数)
これらで「データが改善しているのか、ただ動かしているだけか」を判断します。
アラートとガードレール
ノイズではなく変化に反応するアラートを設定します:
- 障害や隔離レコードの急増
- キューの滞留やコンシューマの遅延(パイプラインが詰まっている)
- プロバイダーのエラー急増(429/5xx)、レイテンシ増加、タイムアウト増
アラートには具体的な対処を結びつけます(プロバイダーを一時停止、同時実行数を下げる、キャッシュや古いデータに切り替える等)。
運用者向けダッシュボード
最近の実行状況(ステータス、件数、再試行)と隔離レコードの一覧をオペレーター向けに表示します。
“再生(replay)”コントロールや安全なバルク操作(プロバイダのタイムアウトを再試行、マッチだけ再実行)を用意します。
ログによるトレース性
構造化ログと、1レコードが通る経路(取り込み → マッチ → エンリッチ → マージ)に沿う相関IDを採用します。
これによりサポートやインシデントのデバッグが格段に速くなります。
インシデントプレイブックとロールバック
プロバイダー劣化時、マッチ率が崩壊した時、重複が漏れた時の短いプレイブックを用意します。
ロールバック手段(例:一定期間内のマージを元に戻す)を保持し、/runbooks に文書を置いておくと良いでしょう。
テスト、ローンチ、反復計画
テストとローンチはエンリッチアプリが信頼されるための重要な工程です。目的は「テストを増やすこと」ではなく、マッチング、マージ、検証が実世界の雑なデータに対して予測可能に動くという信頼を得ることです。
危険な部分を優先的にテストする
レコードを静かに壊す可能性があるロジックを優先してテストします:
- マッチルール:厳密、あいまい、複合マッチのユニットテスト(近似重複やフィールド入れ替えケースを含む)
- マージ結果:フィールド優先順位、競合処理、"上書き禁止"ルールのテスト
- 検証のエッジケース:壊れたメール、国際電話フォーマット、国が抜けた場合、重複識別子、"不明"値
実顧客データを晒さないために合成データセット(生成された名前、ドメイン、住所)を使って精度を検証します。
バージョン管理された"ゴールデンセット"を持ち、回帰が明白になるようにします。
ブラスト半径を小さくする段階的ローンチ
小さく始めて拡大します:
- パイロット:一チームか一セグメント(例:SMBリードのみ)で開始
- 限定アクション:最初はCRMへ書き戻さない"提案"モードで運用
- 段階的拡張:レコード数を増やし、低リスクフィールドについて自動書き込みを有効化
開始前に成功指標(マッチ精度、承認率、手動編集の削減、エンリッチ時間)を定義してください。
ワークフローと統合チェックリストを文書化する
ユーザーと統合者向けに短いドキュメントを作り、製品エリアや /pricing からリンクします。統合チェックリスト例:
- API認証方式、レート制限、再試行挙動
- エンリッチリクエストの必須フィールド
- Webhook/イベントのペイロード(とバージョニング)
- エラーコードと"部分的エンリッチ"のルール
- 監査ログの期待とデータ保持
継続的改善のため、失敗した検証、頻繁に手動で上書きされる項目、不一致を軽くレビューするサイクルを設け、ルールやテストを更新します。
参考となる実務的チェックリストは /blog/data-quality-checklist に置いておくと良いでしょう。
自前構築 vs 加速:実務的な注意
目標ワークフローが固まっていて、仕様から動くアプリまでの時間を短縮したい場合は、Koder.aiを使って初期実装(React UI、Goサービス、PostgreSQL)を生成するのも手です。
多くのチームはこのアプローチでレビューUI、ジョブ処理、監査履歴を早く立ち上げ、その後要件に応じてスナップショットやロールバック機能を追加しつつ自分たちのパイプラインへ移行します。Koder.aiは無料〜エンタープライズの複数プランがあり、実験フェーズと本番要件を合わせやすい選択肢です。