2025年3月16日·1 分
顧客エスカレーションと優先サポートのための Web アプリを作る
エスカレーションをルーティングし、SLAを強制し、優先サポートを明確なワークフローとレポーティングで整理するWebアプリの計画、設計、構築方法を学ぶ。
エスカレーションをルーティングし、SLAを強制し、優先サポートを明確なワークフローとレポーティングで整理するWebアプリの計画、設計、構築方法を学ぶ。
画面やコードを書く前に、アプリの目的と守るべき挙動を決めてください。エスカレーションは単なる「怒った顧客」ではなく、より早い対応、高い可視性、厳密な連携が必要なチケットです。
エージェントや顧客が推測しなくて済むよう、平易な言葉でエスカレーション基準を定義します。一般的なトリガーは:
また、エスカレーションに該当しないもの(例:使い方の質問、機能要望、小さなバグ)と、それらをどこへ回すかも定義してください。
ワークフローに必要な役割と各役割の操作を列挙します:
各ステップで「誰がチケットを所有するか」(引き継ぎを含む)と「所有権」が意味するもの(応答要件、次回更新時間、エスカレーション権限)を明確に書き出してください。
出荷を早め、トリアージを一貫させるために入力チャネルは小さく始めます。多くのチームは メール + Webフォーム から始め、SLAとルーティングが安定してから チャット を追加します。
アプリが改善すべき測定可能な成果を選びます:
これらの決定が、以降のプロダクト要件になります。
優先サポートアプリはデータモデルにかかっています。基盤が正しければ、ルーティング、レポーティング、SLA強制がシンプルになります。
最低限、各チケットは次を保持すべきです:リクエスター(連絡先)、会社(顧客アカウント)、件名、説明、添付ファイル。説明は元の問題記述として扱い、その後の更新はコメントに残して経緯が分かるようにしてください。
エスカレーションは一般サポートより構造が必要です。よく使われるフィールド:severity(どれだけ重大か)、impact(どれだけのユーザー/収益に影響するか)、priority(どれだけ迅速に対応するか)。トリアージを速めるために影響を受けるサービス(例:Billing、API、Mobile App)フィールドを追加します。
締め切りは「SLA名」だけでなく、明確な期日(例:「first response due」「resolution/next update due」)を保存してください。システムはこれらのタイムスタンプを計算できますが、エージェントには正確な時刻を見せるべきです。
実用的なモデルは通常次を含みます:
これにより協業が整理されます:会話はコメント、アクションはタスク、所有権はチケットに。
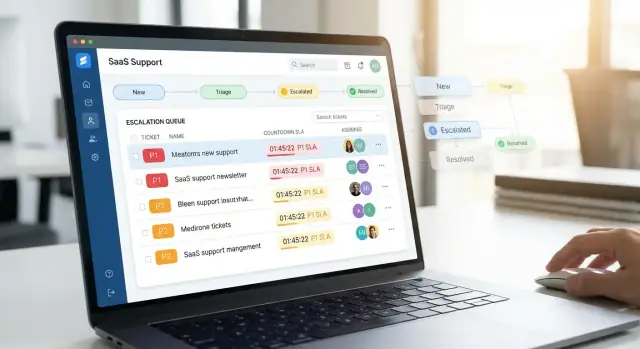
小さく安定したステータス集合を使ってください:New, Triaged, In Progress, Waiting, Resolved, Closed。ほとんど同じようなステータスは避けてください—余分な状態はレポートや自動化を不安定にします。
SLA追跡と説明責任のために、一部のデータは追記のみ(append-only)にすべきです:作成/更新タイムスタンプ、ステータス変更履歴、SLAの開始/停止イベント、エスカレーションの変更、及び各変更を行った人物。監査ログ(またはイベントテーブル)を使うと、推測なしに何が起きたかを再構築できます。
優先度とSLAルールはアプリが強制する「契約」です:何が先に扱われるか、どれだけ速く対応するか、誰が説明責任を持つか。スキームはシンプルに保ち、明確に文書化し、理由なく上書きできないようにします。
四段階にするとエージェントが素早く分類でき、マネージャーが一貫して報告できます:
UIで「影響」(どれだけのユーザー/顧客か)と「緊急度」(どれだけ時間的に敏感か)を明示して誤分類を減らしてください。
データモデルは顧客プラン/ランク(例:Free/Pro/Enterprise) と 優先度 によってSLAを変えられるようにすべきです。通常、少なくとも二つのタイマーを追跡します:
例:Enterprise + P1 なら初回応答15分、Pro + P3 は営業日で8時間など。ルール表をエージェントに見せ、チケットページからリンクできるようにしてください。
SLAはプランに24/7カバレッジが含まれるかどうかで異なることが多いです。
チケットには「SLA残り時間」とそのSLAが使っているスケジュールの両方を表示して、エージェントがタイマーを信頼できるようにしてください。
実際のワークフローでは一時停止が必要です。一般的なルールは、チケットが Waiting on customer(または第三者待ち)になったらSLAを一時停止し、顧客が返信したら再開する、です。
明確にしておくこと:
サイレント違反を避けてください。違反処理はチケット履歴に可視なイベントを作るべきです。
少なくとも二つのアラート閾値を設定します:
通知は優先度とランクに基づいてルーティングし、P4のノイズで人をページしないようにしてください。詳細は /blog/notifications-and-on-call-alerting に接続します。
トリアージとルーティングで優先サポートアプリは時短を生むか混乱を作るかが決まります。目標は簡単:新しいリクエストはすぐに正しい場所に入り、明確な所有者と次のアクションがあること。
未割当または要レビューのチケット専用トリアージ受信箱から始めます。高速かつ予測可能に:
良い受信箱はクリック数を最小化します:エージェントはリストからチケットを取り、再ルーティング、エスカレーションできるべきで、すべてを開く必要はありません。
ルーティングはルールベースにしますが、非エンジニアでも読めるように。よく使う入力:
各ルーティング決定の“理由”を保存してください(例:「Matched keyword: SSO → Auth team」)。これにより異議申し立ての解決や研修が容易になります。
最良のルールでも逃げ道は必要です。認可ユーザーにルーティングの上書きを許可し、次のようなエスカレーション経路をトリガーできるようにします:
Agent → Team lead → On-call
上書きには短い理由を必須にし、監査エントリを作成してください。後でオンコールページングと連携するなら、エスカレーション操作をそこに結びつけます(/blog/notifications-and-on-call-alerting を参照)。
重複チケットはSLA時間を無駄にします。軽量ツールを追加します:
リンクされたチケットは親のステータス更新や公開メッセージを継承すべきです。
所有権状態を明確に定義します:
所有者はリストビュー、チケットヘッダー、アクティビティログのどこでも見えるようにし、「誰がこれを持っているの?」の問いに即答できるようにします。
優先サポートアプリは、エージェントが触ってから最初の10秒で成功するか失敗するかが決まります。ダッシュボードは即座に三つの質問に答えるべきです:今何を注視すべきか、なぜ、そして次に何をすべきか。
多くのタブを作るより、ユーティリティの高いビューを少数用意します:
エージェントが各行を“読む”必要がないように、明確で一貫したシグナルを使います:
タイポグラフィはシンプルに:主要アクセント色1つ、情報階層をタイトに(タイトル→顧客→ステータス/SLA→最終更新)。
各チケット行でフルページを開かずに次の操作ができるべきです:
バックログを素早く掃くために一括操作(割り当て、クローズ、タグ適用、ブロッカー設定)を追加します。
パワーユーザー向けにキーボードショートカットを提供します:/で検索、j/kで移動、eでエスカレーション、aで割り当て、g→qでキューに戻るなど。
アクセシビリティは、十分なコントラスト、フォーカス状態の表示、ラベル付きコントロール、スクリーンリーダーに優しいステータステキスト(例:「SLA:残り12分」)を確保してください。テーブルはレスポンシブにして、小さい画面でも重要フィールドが隠れないようにします。
通知は優先サポートアプリの“神経系”です:チケットの変化をタイムリーな行動に変えます。目的は多く通知することではなく、正しい人に、正しいチャネルで、対応に十分なコンテキストを付けて通知することです。
メッセージをトリガーするイベントを明確にします。高信号の型は:
各メッセージはチケットID、顧客名、優先度、現在の所有者、SLAタイマー、チケットへのディープリンクを含むべきです。
日常業務には アプリ内通知、耐久性のある更新や引き継ぎには メール を使います。本当にオンコールの場面では、SMS/プッシュ をP1のエスカレーションや差し迫った違反など緊急イベント用のオプションチャネルとして追加します。
アラート疲れは対応速度を殺します。グルーピング、サイレント時間、重複除去などの制御を追加します:
顧客向け更新と内部メモのテンプレートを用意して、トーンと網羅性を維持します。配信状況(送信済み/配信済み/失敗)を追跡し、チケットごとに通知タイムラインを持たせて監査とフォローアップを容易にします。チケット詳細ページに「Notifications」タブを置くと見やすいです。
チケット詳細ページはエスカレーション作業そのものが行われる場所です。エージェントが数秒でコンテキストを把握し、チームと連携し、顧客に間違いなく伝えるための支援をするべきです。
投稿作成時にCustomer Reply と Internal Note を明示的に選ばせ、それぞれ別のスタイリングとプレビューを表示します。内部メモはランブックへのリンクやクイックフォーマット、プライベートタグ(例:「needs engineering」)をサポートし、顧客返信はフレンドリーなテンプレートをデフォルトにして送信内容を正確にプレビューさせます。
時系列のスレッドにメール、チャットのトランスクリプト、システムイベントを含めます。添付ファイルは安全性を優先:
顧客提供ファイルを表示する際は誰がいつアップロードしたかを明示してください。
マクロ を導入し、事前承認された返信とトラブルシューティングチェックリスト(例:「ログ収集」「再起動手順」「ステータスページ文言」)を挿入できるようにします。チームで共有できるマクロライブラリをバージョン履歴付きで管理すると一貫性とコンプライアンスに役立ちます。
メッセージに加えてコンパクトなイベントタイムラインを表示します:ステータス変更、優先度更新、SLAの一時停止/再開、担当者移譲、エスカレーションレベルの変化など。これにより「何が変わったのか?」のやり取りを減らし、事後レビューがしやすくなります。
@メンション、フォロワー、リンクされたタスク(エンジニアリングのチケット、インシデントドキュメント)を有効にします。メンションは適切な人だけに通知し、フォロワーには重要な変更時にまとめてサマリーを送るようにしてすべての編集で通知が飛ばないようにしてください。
エスカレーションには顧客のメール、スクリーンショット、ログ、内部メモが含まれることが多いので、早い段階でガードレールを整えてエージェントが速く動けるようにしつつデータを過度に共有しないようにします。
まず簡潔に説明できる少数の役割(例:Agent, Team Lead, On-Call Engineer, Admin)を定め、各役割が閲覧/編集/コメント/再割り当て/エクスポートのうち何をできるか定義します。
実用的には「デフォルト拒否」権限を採用します:
ワークフローに必要なデータだけ収集します。全文のメッセージボディや完全なIPアドレスが不要なら保存しないでください。保存する場合は必須項目と任意項目を明確にし、他システムからデータをコピーするのは理由がある場合に限定します。
アクセスパターンは「サポートエージェントはチケットを解決するのに必要最小限のみ見るべきだ」と仮定し、まずはアカウントスコープとキュースコープで制御し、複雑なルールは後で追加してください。
可能ならSSO/OIDCなどの実績ある認証を使い、パスワードを使う場合は強度を要求し、昇格した役割には多要素認証を必須にします。
セッションの強化:
シークレットはソース管理に置かず管理されたシークレットストアに保存します。機密データへのアクセス(誰がエスカレーションを見たか、添付をダウンロードしたか、チケットをエクスポートしたか)をログに残し、監査ログは改ざん耐性かつ検索可能にします。
チケット、添付、監査ログの保持ルールを定義します(例:添付はN日後に削除、監査ログはより長期間保持)。顧客や内部報告用のエクスポートを提供しつつ、特定のコンプライアンス認証を主張するなら実際に検証できるようにしてください。簡単な「データエクスポート」フローと管理者専用の「削除リクエスト」ワークフローが出発点として良いです。
エスカレーションアプリは変化しやすさが重要です。ルール、SLA、統合は頻繁に変わるので、チームが保守しやすいスタックを優先してください。
「完璧」より慣れているツールを選びます。代表的な組み合わせ:
既に社内にモノリスがあるならそのエコシステムに合わせるとオンボーディングと運用が楽になります。
また、大規模なエンジニアリソースを本格投入する前にプロトタイプして繰り返す選択肢として、Koder.ai のようなビベコーディングプラットフォームでワークフローを素早く試す方法もあります。
コアレコード(チケット、顧客、SLA、エスカレーションイベント、担当割り当て)はリレーショナルDB(Postgresが一般的)を推奨します。トランザクション、制約、レポート向けクエリが有利です。
件名や会話テキスト、顧客名の高速検索には後から検索インデックス(Elasticsearch/OpenSearch)を追加検討します。最初はPostgresの全文検索で十分なことが多いです。
SLAタイマーや連携作業はウェブリクエストで走らせるべきではありません:
ジョブキュー(例:Celery、Sidekiq、BullMQ)を使い、ジョブは冪等にしてリトライで重複アラートが起きないようにします。
REST か GraphQL かは別として、リソース境界(tickets, comments, events, customers, users)を定義しておきます。一貫したAPIスタイルは統合とUIの開発を加速します。Webhookエンドポイントの計画(署名シークレット、リトライ、レート制限)も早めに行ってください。
少なくとも dev / staging / prod を用意します。staging は prod 設定をミラー(メールプロバイダ、キュー、Webhook など)し、安全なテスト資格情報を使って検証できるようにします。デプロイとロールバック手順を文書化し、設定は環境変数で管理してください。
統合があって初めてアプリは「確認するだけの場所」から、チームが本当に使うシステムになります。顧客が既に使っているチャネルから始め、その後エスカレーションイベントに反応する自動化フックを追加します。
メールは通常最も効果の高い統合です。受信メール転送(support@ など)を受け、以下をパースします:
送信時はチケットから送信し、スレッディングヘッダを保って返信が同じチケットに戻るようにします。顧客が見たものを正確に示すクリーンな会話タイムラインを保存してください(内部メモとは分ける)。
Slack/Teams/インターコム系ウィジェットなどは、会話をチケットに変換してトランスクリプトと参加者を残すだけで十分です。すべてのメッセージを同期するのではなく、エージェントが制御できる「直近20メッセージを添付」ボタンなどを提供してノイズを制御します。
CRM同期で「優先サポート」の自動化が可能になります。会社、プラン/ランク、アカウントオーナー、主要連絡先を取り込み、CRMアカウントをテナントにマップして新しいチケットに優先ルールを継承させます。
ticket.escalated、ticket.resolved、sla.breached のようなイベント用Webhookを提供します。安定したペイロード(ticket ID、タイムスタンプ、severity、customer ID)を含め、受信側が正当性を確認できるよう署名を付けてください。
「テスト送信」「Webhook検証」などの管理フローを用意し、/docs/integrations にドキュメントをまとめておくと導入が早まります。よくあるトラブルシューティング(SPF/DKIM問題、欠けているスレッディングヘッダ、CRMフィールドマッピング)も記載してください。
優先サポートアプリは緊張した場面で“ソース・オブ・トゥルース”になります。SLAタイマーのずれ、ルーティングの誤動作、権限漏れは信頼を速やかに失わせます。信頼性を機能として扱い、重要なものをテストし、何が起きているかを計測し、障害に備えてください。
結果を変えるロジックに自動テストを集中させます:
エンドツーエンドの小さなテストスイート(チケット作成→トリアージ→エスカレーション→解決)を用意して、UIとバックエンド間の仮定違いを検出します。
デモ用だけでなく実用的なシードデータを用意します:いくつかの顧客、複数ランク(標準 vs 優先)、さまざまな優先度、異なる状態のチケット。再オープン、顧客待ち、複数担当者などの厄介なケースも含めるとQAが再現しやすくなります。
「何が、誰に対して、なぜ失敗したか」を答えられるようにインストルメントします:
シフト変更時に高負荷になるビュー(キュー、検索、ダッシュボード)で負荷試験を行います。
最後に独自のインシデントプレイブックを用意してください:新ルール用の機能フラグ、DBマイグレーションのロールバック手順、自動化を無効にしながらエージェントが作業できるクリアな手順など。
優先サポートWebアプリは、エージェントがプレッシャー下で信頼するようになって初めて“完成”です。小さく始めて、実際の利用で測り、短いサイクルで改善することが近道です。
すべての機能を出したい衝動に抵抗してください。最初のリリースは「新しいエスカレーション」から「説明責任を持って解決」までの最短経路をカバーするべきです:
Koder.ai を使う場合、このMVP形は一般的なデフォルト(React UI、Goサービス、PostgreSQL)にマップしやすく、スナップショットとロールバック機能がSLA算出、ルーティング、権限境界の調整時に便利です。
パイロットグループ(1地域、1プロダクトライン、あるいは1つのオンコールローテーション)へ展開し、週次のフィードバックレビューを行います。構成はシンプルに:エージェントを遅らせた要因、欠けていたデータ、ノイズが多いアラート、エスカレーション管理が破綻した箇所(ハンドオフ、所有権不明、誤ルーティング)を洗い出してください。
実用的な手法として、アプリ内に軽量な変更ログを置き、エージェントが改善を見られるようにすると声が反映されている実感が生まれます。
一貫した使用が得られたら、運用上の問いに答えるレポートを導入します:
これらのレポートはエクスポートしやすく、非技術的なステークホルダーにも説明しやすい形にしてください。
ルーティングとトリアージルールは最初は間違っています—それは普通です。誤ルートや解決時間、オンコールのフィードバックに基づいてルールを調整し、マクロや定型文も時間で洗練してください。時間を短縮し、インシデントコミュニケーションを改善するものを残し、効果のないものは削除します。
「次の30日」など短く見えるロードマップを製品内に置き、ヘルプとFAQへのリンクを設けてトレーニングが部族知識にならないようにします。公開情報があるなら /pricing や /blog などの内部リンクで見つけやすくしてください。
UIに判定基準を組み込み、平易な言葉で定義してください。典型的なエスカレーショントリガーは以下の通りです:
また、エスカレーションに該当しないもの(使い方の質問、機能要望、小さなバグ)と、それらをどこへルーティングするかも明確にしてください。
ワークフロー内で「何ができるか」で役割を定義し、各ステップでの所有権をマッピングします:
各ステータスごとに、誰がチケットを所有するか、要求される応答/次回更新時間、エスカレーションやルーティングの上書き権限を明記してください。
トリアージを一貫させ、早く出せるように最小限のチャネルから始めます。一般的にはメール+Webフォームで開始し、次にチャットを追加します:
これにより、スレッド処理やトランスクリプト同期、リアルタイムノイズなどの初期の複雑さを削減できます。
最低限、各チケットは以下を保持すべきです:
エスカレーション向けには、、、、(例:API、請求)などの構造化フィールドを追加してください。SLAについては、 や のような明示的な期日タイムスタンプを保存し、エージェントが正確な締め切りを見られるようにします。
小さく安定したステータスセット(例:New, Triaged, In Progress, Waiting, Resolved, Closed)を使い、各ステータスが運用上何を意味するか定義します。
SLAと説明責任を監査可能にするため、以下は追記不可(append-only)にします:
イベントテーブルや監査ログがあれば、現在の状態だけに頼らずに何が起きたかを再構築できます。
優先度はシンプルに(例:P1–P4)し、SLAは顧客のプラン/ランク + 優先度に紐づけます。少なくとも二つのタイマーを追跡します:
上書きを可能にする場合は理由を必須にし、その記録を監査履歴に残して報告の信頼性を保ってください。
時間を明示的にモデル化します:
どのステータスがどのタイマーを一時停止するか(一般的には Waiting on customer/third party)を定義し、違反時に何が起きるか(タグ付け、通知、自動エスカレーション、オンコールのページング)を決めます。違反は“サイレント”にせず、チケット履歴に可視のイベントとして残してください。
未割当・要レビュー用のトリアージ受信箱を作り、優先度、SLA期限、顧客ランクでソートできるようにします。ルーティングはルールベースにしつつ非エンジニアでも読めるように:
各ルーティング決定の“理由”を保存(例:「Matched keyword: SSO → Auth team」)し、認可ユーザーによる上書きは理由を必須にして監査ログを残します。
最初の10秒で答えを出すことを優先してください:
バックログ処理のための一括アクション、パワーユーザー向けのキーボードショートカット、アクセシビリティ(コントラスト、フォーカス状態、スクリーンリーダー対応)も実装してください。
早い段階でデータ保護のガードレールを設けます:
信頼性面では、SLA計算、ルーティング、権限に関する自動テストを重点的に実行し、タイマーや通知は冪等なバッチジョブで処理して重複アラートを防いでください。