2025年5月05日·1 分
顧客エスカレーションのタイムライン管理Webアプリを作る
顧客エスカレーション、期限、SLA、所有権、アラートを追跡するWebアプリを作るための段階的な計画。レポーティングと統合も含む。
顧客エスカレーション、期限、SLA、所有権、アラートを追跡するWebアプリを作るための段階的な計画。レポーティングと統合も含む。
画面設計や技術選定を始める前に、組織内で「エスカレーション」が具体的に何を指すのかを定めてください。老朽化したサポートケース、稼働に関わるインシデント、重要アカウントからのクレーム、あるいは重症度の閾値を超えたリクエストなど、異なるチームが異なる意味で使っているとアプリは混乱を組み込みます。
チーム全員が合意できる一文の定義を書き、いくつかの例を付けてください。例えば:「エスカレーションとは、上位サポートレイヤーまたは経営陣の関与を必要とし、時間制約のあるコミットメントを伴う顧客問題のこと」といった具合です。
また、v1で膨らませたくないもの(定型チケットや内部タスクなど)も定義しておきましょう。
成功基準は「作りたいもの」ではなく「改善したいこと」を反映するべきです。一般的なコア成果は:
初日から追える指標を2〜4個選んでください(例:違反率、各ステージ滞留時間、再割り当て回数)。
主要ユーザー(エージェント、チームリード、マネージャー)と二次ステークホルダー(アカウントマネージャー、オンコールのエンジニア)を列挙し、それぞれが迅速に行う必要のある作業(所有権の取得、理由付きで期限延長、次に何が来るかの確認、顧客向けの要約作成など)をメモしてください。
現行の失敗事例を具体的なストーリーで記録します:ティア間のハンドオフ漏れ、再割り当て後の期日不明、延長承認の不一致など。
これらのストーリーを使って必須項目(タイムライン+所有権+監査可能性)と後回しにする機能(高度なダッシュボード、複雑な自動化)を分けてください。
目的が明確になったら、エスカレーションがチーム内でどのように進むかを書き下してください。共通のワークフローがあることで「特例」が不整合やSLA見落としにつながるのを防げます。
まずはシンプルなステージと許容遷移を設定します:
各ステージが何を意味するか(入場条件)と退出するために何が真でなければならないか(退出条件)を文書化してください。これにより「解決済みだが顧客待ち」といった曖昧さを避けられます。
エスカレーションは1文で説明できるルールで作られるべきです。一般的なトリガー例:
トリガーが自動でエスカレーションを作るのか、エージェントに提案するのか、承認を要するのかを決めてください。
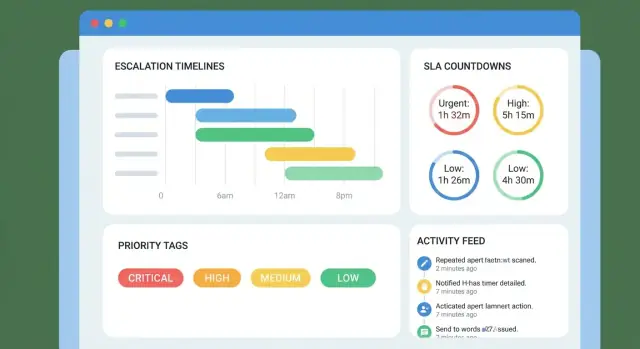
タイムラインはイベント次第です。最低限記録すべきは:
誰が再割り当てできるか、承認が必要な場合(例:跨チームやベンダーへの引き渡し)、担当者がシフト外になった場合の処理をルール化してください。
最後に、タイミングに影響する依存関係をマップします:オンコールスケジュール、ティアレベル(T1/T2/T3)、外部ベンダー(彼らの応答ウィンドウ含む)。これは後のタイムライン計算やエスカレーションマトリクスに影響します。
信頼できるエスカレーションアプリはほとんどがデータ設計の問題です。タイムライン、SLA、履歴が明確にモデル化されていないと、UIや通知は常に「違和感」が出ます。まずはコアエンティティと関係性に名前を付けましょう。
最低限計画すべきもの:
各マイルストーンをタイマーとして扱います:
start_at(時計が始まる時刻)due_at(計算された期限)paused_at / pause_reason(オプション)completed_at(達成時刻)due_at がなぜ存在するのか(ルール)も保存してください。これにより後からの争いの解決が容易になります。
SLAは通常「常時」ではありません。SLAポリシーごとにカレンダーをモデル化してください:営業時間か24/7か、祝日、地域別スケジュール。
締め切りはサーバー側で一貫した時刻(UTC)で計算しつつ、常にケースのタイムゾーン(または顧客のタイムゾーン)を保存してUIで正しく表示できるようにします。
初期に決めておくべき選択:
CASE_CREATED, STATUS_CHANGED, MILESTONE_PAUSED など)、またはコンプライアンスと責任追跡のためにはイベントログを推奨します(パフォーマンスのために現在値カラムは併用してもよい)。すべての変更に対して誰が/何を変えたか/いつ/ソース(UI、API、自動化)と、関連アクションを追跡する相関IDを記録してください。
権限はエスカレーションツールが信頼を得るか、スプレッドシートでの運用に戻るかを分けます。誰が何をできるかを早めに定義し、UI・API・エクスポート全体で一貫して適用してください。
v1はシンプルに保ち、実際のサポート業務に合うロールを用意します:
プロダクト内で権限チェックは明示的に行い、エラーで止めるよりコントロールを無効化する方が親切です。
エスカレーションは複数グループにまたがることが多いので、可視性を次の次元でスコーピングすることを計画します:
良いデフォルトは:ユーザーは自分が担当、ウォッチャー、または所属チームのケースにアクセスでき、さらに明示的に共有されたアカウントにもアクセス可能とする方法です。
すべてのデータを全員に見せる必要はありません。一般的に敏感なフィールドは顧客のPII、契約詳細、内部メモです。フィールドレベルの権限例:
v1ではメール/パスワード+MFAで十分なことが多いです。ユーザーモデルは後でSAML/OIDCを追加できるように設計し(ロールやチームを内部で保持し、SSOグループをログイン時にマッピングする)、権限を書き換えずに対応できるようにしてください。
権限変更は監査対象アクションとして扱ってください。ロール更新、チーム再割り当て、エクスポートのダウンロード、設定編集などを「誰が/いつ/何を変えたか」で記録します。これはインシデント時の保護やアクセスレビューで重要です。
エスカレーションアプリは日常的に使われる画面で成功するかどうかが決まります:サポートリードが最初に見るもの、ケースの理解に要する時間、次の期日を見落とさないか。
最初は業務の90%をカバーする小さなページセットから始めます:
ナビゲーションは予測可能に:左サイドバーか上部タブで「Queue」「My Cases」「Reports」など。キューをデフォルトランディングにします。
ケース一覧では次に何をするかを決めるのに役立つ項目だけを表示します。よいデフォルト行には:顧客、優先度、現在の担当、ステータス、次の期日、警告表示(例:「2時間後に期限」「1日遅延」)を含めます。
高速で実用的なフィルタと検索も追加します:
スキャンしやすくするために列幅を整え、ステータスチップは一貫性を持たせ、緊急度にだけ使う強調色を1色に限定してください。
ケースビューで瞬時に答えが得られるようにします:
高速アクションを上部に置き(メニューの奥に隠さない):Reassign、Escalate、Add milestone、Add note、Set next deadline。各アクションは何が変わったかを確認し、タイムラインを即時更新するべきです。
タイムラインは約束の明確なシーケンスのように読めるべきです。含める項目:
プログレッシブディスクロージャーを使って最新イベントを先に表示し、古い履歴は展開できるようにします。監査ログがある場合はタイムラインからリンク(例:「変更ログを見る」)を付けてください。
読みやすいコントラスト、色だけでなくテキストでも状態を示す(「Overdue」など)、すべての操作をキーボードで可能にする、ラベルはユーザー言語に合わせる(「SLAを更新」ではなく「次の顧客更新期限を設定」など)。これによりプレッシャーが高い場面での誤操作を減らせます。
アラートはエスカレーションタイムラインの“心拍”です:人がずっとダッシュボードを見ている必要はなく、適切な瞬間に適切な人に伝えることが目的です。ノイズを最小にしつつ行動を促すことを目標にしてください。
最初はアクションに直結する少数のイベントから始めます:
v1は確実に配信でき、計測できるチャネルに絞ります:
SMSやチャットはルールとボリュームが安定してから追加してください。
エスカレーションをケースのタイムラインに紐づく時間ベースの閾値として表現します:
このマトリクスは優先度やキューごとに設定可能にして、P1インシデントと請求問合せが同じ振る舞いにならないようにします。
重複除去(同じアラートを二度送らない)、バッチ化(類似アラートをまとめる)、静音時間(非クリティカルなリマインダーを遅延させる)を実装してください。ログには必ず記録を残しておきます。
すべてのアラートは次をサポートするべきです:
これらの操作を監査ログに保存して、「誰も見ていなかった」ことと「誰かが見て保留にした」ことを区別できるようにします。
多くのエスカレーションアプリが失敗する原因は、既存データを二重入力させることです。v1ではタイムラインを正確に保ち、通知を適時にするために必要な統合だけを行ってください。
どのチャネルがケース作成/更新を行えるかを決めます:
インバウンドのペイロードは小さく保つ:ケースID、顧客ID、現在のステータス、優先度、タイムスタンプ、短いサマリ。
重要な出来事を他システムに通知するために:
Webhookは署名付きリクエストとイベントIDで重複除去できるようにします。
双方向で同期する場合はフィールドごとにソースオブトゥルースを宣言してください(例:チケッティングツールがステータスを管理、アプリがSLAタイマーを管理)。競合解決ルールを定義し、リトライとバックオフ、失敗用のデッドレターキューも用意します。
v1は外部IDを使った最小限のスキーマで顧客と連絡先をインポートします:アカウント名、階層、主要連絡先、エスカレーション優先設定。深いCRMのミラーリングは避けてください。
認証方法、必須フィールド、レートリミット、リトライ、テスト環境を含む短いチェックリストを文書化し、最小のAPI契約(1ページ程度)を公開してバージョン管理してください。これにより統合が予期せず壊れるのを防げます。
バックエンドは2つをうまくやる必要があります:エスカレーションのタイミングを正確に保つこと、そしてケース数が増えても速く動くこと。
チームが維持できる最もシンプルなアーキテクチャを選んでください。典型的なMVCアプリにREST APIを組み合わせるだけでv1は十分なことが多いです。既にGraphQLがうまく機能しているならそれでもよいですが、追加の複雑さは避けてください。データベースは管理されたもの(例:Postgres)にして、エスカレーションロジックに注力できるようにします。
もしワークフローの検証を素早く行いたいなら、Koder.ai のようなプロトタイピングプラットフォームでコアループ(キュー→ケース詳細→タイムライン→通知)を試し、プランニングしながらソースコードをエクスポートするのも手です。Koder.ai のデフォルトスタック(React, Go + PostgreSQL)は監査が重要なアプリに実用的です。
エスカレーションはスケジュール処理に依存するため、次の処理が必要です:
ジョブは冪等にし(2回実行されても安全)、リトライ可能にしてください。ケース/タイムラインごとに「last evaluated at」タイムスタンプを保存し、重複アクションを防ぎます。
すべてのタイムスタンプはUTCで保存し、UIでユーザーのタイムゾーンに変換してください。夏時間、うるう日、ポーズ中の時計などのエッジケース用のテストを追加します。
キューや監査ログビューにはページネーションを使い、フィルタやソートに合わせたインデックスを追加します。一般的なインデックス:(due_at), (status), (owner_id), (status, due_at) のような複合。
ファイルはDBとは別に保管する計画にしてください:サイズ/タイプ制限、アップロードスキャン(もしくは外部プロバイダー連携)、保持ポリシー(例:12か月で削除、法的保留例外)。メタデータはケース管理テーブルに保存し、ファイル本体はオブジェクトストレージに置きます。
レポーティングはエスカレーションアプリを単なる共有受信箱から経営ツールに変えます。v1では「SLAを守れているか?」と「どこで詰まっているか?」の2つに答える単一ページで十分です。定義を全員が合意していることが信頼できるレポートの前提です。
レポートは基になる定義が信頼できてこそ意味があります。平易に定義を書き、データモデルに反映してください:
どのSLAクロックをレポートするか(初回応答、次回更新、解決)も決めておきます。
ダッシュボードは軽量でも実行可能であるべきです:
運用ビューは日々の負荷分散に使います:
v1はCSVエクスポートで十分です。エクスポートは権限に紐づけ(チームベースのアクセス、ロールチェック)し、各エクスポートの監査ログ(誰が/いつ/どんなフィルタで/行数)を残してください。これにより「謎のスプレッドシート」を防ぎ、コンプライアンスを支えます。
最初のレポートページを早く出して、サポートリードと週次で1か月レビューしてください。欠けているフィルタ、分かりにくい定義、「これが答えられない」といったフィードバックがv2の最良の入力になります。
エスカレーションタイムラインアプリのテストは「動くか?」だけでなく「高圧状態で現場が期待する振る舞いをするか?」が重要です。タイムラインルール、通知、ハンドオフに負荷をかける現実的なシナリオに注力してください。
テストの多くはタイムライン計算に注ぎましょう。小さなミスが大きなSLA争いを招きます。
営業時間計算、祝日、タイムゾーンをカバーするテストを用意し、ポーズ(顧客待ち、エンジニア待ち)、途中での優先度変更、エスカレーションによる目標変更などを網羅します。エッジケースも必須:営業終了1分前の作成、SLA境界で始まるポーズなど。
通知はシステム間の隙間で失敗しがちです。次を確認する統合テストを書いてください:
メール、チャット、Webhookを使うなら、単に「何かが送られた」ではなくペイロードとタイミングをアサートしてください。
VIP顧客、長期化ケース、頻繁な再割り当て、再オープンされたインシデント、キューのスパイクなど、現実的なサンプルデータを用意します。これによりキュー/ケースビュー/タイムラインの可読性を説明なしで検証できます。
1チームで1〜2週間のパイロットを実施してください。毎日問題を収集:不足フィールド、ラベルの混乱、通知ノイズ、タイムラインルールの例外など。
ユーザーがアプリの外で何をしているか(スプレッドシート、別チャネル)を追跡し、ギャップを発見します。
広範な導入前に「完了」の定義を書きます:主要SLA指標が期待通り、重要な通知が信頼できる、監査ログが完全、パイロットチームが回避策なしでエスカレーションを実行できること。
最初のバージョンを出すことがゴールではありません。エスカレーションタイムラインアプリは日常的な失敗(ジョブの見落とし、遅いクエリ、通知設定ミス、SLAルール変更など)を耐え抜いて「実用」になります。デプロイと運用をプロダクトの一部として扱ってください。
リリースプロセスは退屈で再現可能にしてください。最低限自動化と文書化する項目:
ステージング環境があれば現実的なデータ(匿名化)でシードし、本番と同様の通知/タイムライン挙動を検証してください。
通常のアップタイムチェックでは見つからない問題があります。次の監視ポイントを用意してください:
「エスカレーションリマインダーが送られていない場合はA→B→Cを確認する」といった小さなオンコールプレイブックを用意しておくと、ハイプレッシャー時の復旧が速くなります。
エスカレーションデータには顧客名やメール、機密メモが含まれます。早めにポリシーを定めてください:
保持設定は構成可能にしておき、ポリシー変更でコード修正が必要にならないようにします。
v1でもシステムを健全に保つための管理機能は必要です:
短く実務ベースのドキュメントを書いてください:「エスカレーションを作る」「タイムラインをポーズする」「SLAを上書きする」「誰が何を変更したかを監査する」など。
アプリ内に軽いオンボーディングフローを入れ、ユーザーをキュー、ケースビュー、タイムラインアクションに案内し、参照用の /help ページへのリンクを置いてください。
v1はコアループを実証することが目的:ケースに明確なタイムラインがあり、SLA時計が予測通り動き、適切な人に通知が届くこと。v2はその上で本当に価値が出るものだけを追加してください。短く明確なバックログを維持し、実際の利用状況が出てから引き上げましょう。
v2の項目は(a)大規模で手作業を削減する、または(b)コストの高いミスを防ぐ、のどちらかであるべきです。単に設定項目を増やすだけなら複数チームからの実証が出るまで先送りしてください。
顧客ごとのSLAカレンダー(営業時間、祝日、契約上の応答時間)はv2で効果が高いことが多いです。
次にプレイブックやテンプレート(事前定義のエスカレーションステップ、想定ステークホルダー、メッセージ下書き)を追加すると応答の一貫性が上がります。
割り当てがボトルネックになったらスキルベースのルーティングやオンコールスケジュールを検討します。最初はスキルの数を絞り、デフォルトのフォールバック担当と明確な上書き制御を用意してください。
自動エスカレーションは、重症度変化、キーワード、センチメント、再度の連絡などでトリガーできます。まずは「提案(suggested escalation)」から始め、自動実行は慎重に。トリガー理由をすべて記録して信頼と監査性を確保してください。
エスカレーション前に必須フィールド(影響、重症度、顧客ティア)を求める、ハイシビリティのエスカレーションには承認ステップを入れるなど、ノイズを減らしレポートの信頼性を保つ仕組みを追加します。
自動化パターンを構想中なら /blog/workflow-automation-basics を、パッケージングの調整なら /pricing を参照して機能とプランの整合性を確認してください。
まず全員が合意できる一文の定義から始めて(いくつかの例を添える)、その一方で非該当事項(定型チケットや社内タスクなど)も明示して、v1が一般的なチケット管理に広がらないようにします。
その上で、SLA違反率、各ステージの滞留時間、再割り当て回数など、すぐに計測できる2〜4の成功指標を書き出してください。
機能完成ではなく運用改善を反映する成果を選びます。実務上のv1指標の例:
日々の運用で算出できる小さなセットを選んでください。
共通理解のある小さなステージセットを使い、各ステージの入退出条件を明確にします。例:
各ステージに入る・出るために何が満たされているべきかを書き出すと、「解決済みだが顧客待ち」のような曖昧さを防げます。
タイムラインとSLA判定を立証できる最低限のイベントを記録します:
どのタイムスタンプがどう使われるか説明できないなら、v1では収集しない方が良いです。
各マイルストーンを次のようなタイマーとしてモデル化します:
start_atdue_at(計算済み)paused_at と pause_reason(オプション)completed_atさらに、 を生成したルール(ポリシー+カレンダー+理由)を保存します。これにより、最終期限だけを保存するより監査や争いの解決が容易になります。
すべてのタイムスタンプはUTCで保存し、UI/API境界でユーザーのタイムゾーンに変換して表示します。SLAカレンダー(24/7か営業時間か、祝日、地域ごとのスケジュール)を明示的にモデル化してください。
また、夏時間の変更、営業終了間際に作成されたケース、境界で始まるポーズなどのエッジケースをテストに含めてください。
v1は実際のワークフローに沿ったシンプルな役割から始めると現場で使われやすいです:
さらにチーム/地域/アカウントでのスコーピングや、内部ノートやPIIといった敏感フィールドのフィールドレベル権限を設けてください。
毎日使う画面を最初に設計します:
スキャンしやすく、コンテキスト切替を減らす設計にしてください。主要アクションはメニューの奥に隠さないこと。
高信号の通知セットから始めます:
v1は1〜2チャネル(通常はインアプリ+メール)に絞り、T–2h / T–0h / T+1h のような閾値でエスカレーション行動を定義します。重複除去、バッチ化、静音時間を導入し、確認(Acknowledge)やスヌーズは監査可能にしてください。
タイムラインを正確に保つために必要な連携だけ行ってください:
双方向同期を行う場合はフィールドごとのソースオブトゥルースを明確にし、競合ルールを定義してください(「最後に書き込んだ者が勝ち」は往々にして誤り)。最小限のバージョン管理されたAPI仕様を公開すると統合が安定します。詳しくは /blog/workflow-automation-basics と /pricing を参照してください。
due_at