2025年11月29日·2 分
顧客フィードバックループを管理するウェブアプリの作り方
顧客フィードバックを収集・ルーティング・追跡・クローズするためのワークフロー、役割、指標を備えたウェブアプリの設計と構築方法を学ぶ。
顧客フィードバックを収集・ルーティング・追跡・クローズするためのワークフロー、役割、指標を備えたウェブアプリの設計と構築方法を学ぶ。
フィードバック管理アプリは「メッセージを保存する場所」ではありません。チームが入力 → アクション → 顧客へ見えるフォローアップへ確実に移行し、その後に学べる仕組みを作るためのシステムです。
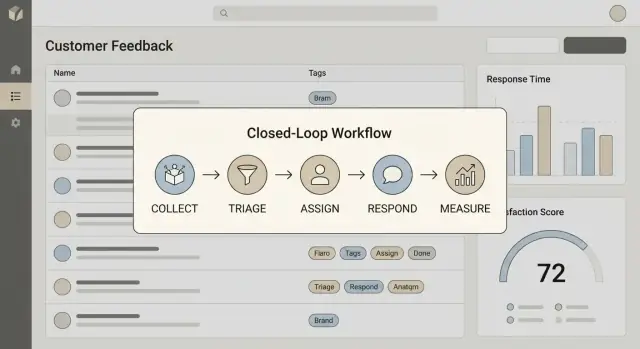
チームが繰り返し言える一文を作りましょう。ほとんどのチームにとって、ループを閉じるには次の四段階が含まれます:
これらのステップが欠けていると、アプリはバックログの墓場になりがちです。
最初のバージョンは日常業務で使われる実際の役割に応えるべきです:
「クリックごとの決定」を具体的にします:
速度と品質を反映する少数の指標を選びます。例:初回応答時間、解決率、フォローアップ後のCSAT変化。これらが後の設計判断の指針になります。
画面設計やデータベース選定をする前に、フィードバックが作成されてから応答されるまでに何が起きるかをマップしましょう。簡単なジャーニーマップはチームを「完了」の定義でそろえ、実作業に合わない機能を作ることを防ぎます。
フィードバックソースを列挙し、それぞれがどのデータを安定して提供するかを記載します:
入力が異なっても、アプリはそれらを一貫した「フィードバック項目」形に正規化して、チームが一か所でトリアージできるようにするべきです。
実用的な最初のモデルには通常以下を含みます:
開始時のステータス例:New → Triaged → Planned → In Progress → Shipped → Closed。ステータスの意味は文書化して、チーム間で「Planned」が別の意味にならないようにします。
重複は避けられません。早めにルールを定義しましょう:
一般的なアプローチは、1つの代表(canonical)フィードバック項目を保持し、他を重複としてリンクして帰属(誰が要望したか)を残すことです。これにより作業が断片化しません。
フィードバックループアプリは、初日から人々が迅速にフィードバックを処理できるかで成功が決まります。目指すフローは「スキャン → 決定 → 次へ進む」と感じられること。ただし判断のための文脈は保存されるべきです。
インボックスはチームの共有キューです。強力な少数のフィルタで迅速なトリアージを支援します:
初期から「保存済みビュー」を追加しましょう(シンプルでも良い)。チームによってスキャン方法は異なります:Supportは「urgent + paying」を、Productは「feature requests + high ARR」を見たがります。
項目を開くと以下が見えるべきです:
目標は「この人は誰か、何を意味しているか、既に返信したか」を答えるために別タブを開かせないことです。
詳細ビューからのトリアージは1クリックで決定できるようにします:
二つのモードが必要になることが多いです:
どちらを選ぶにせよ、「文脈付きで返信する」を最終ステップにして、ループを閉じる行為がワークフローの一部になるようにします。
フィードバックアプリはすぐに共有の記録システムになります:プロダクトはテーマを、サポートは迅速な返信を、経営はエクスポートを求めます。誰が何をできるか(そして何が起きたかを証明する)を定義しておかないと信頼が崩れます。
複数社にサービスするなら、各ワークスペース/組織を初日から厳格な境界として扱ってください。すべてのコアレコード(feedback item、customer、conversation、tags、reports)に workspace_id を含め、すべてのクエリをそれにスコープします。
これは単なるDBの話ではなく、URL、招待、分析にも影響します。安全なデフォルトは:ユーザーは一つ以上のワークスペースに所属し、権限はワークスペースごとに評価されることです。
最初はシンプルに保ちます:
次に、画面ではなくアクションに権限を割り当てます:閲覧 vs 編集、重複のマージ、ステータス変更、データエクスポート、返信送信。これにより後から「閲覧のみ」ロールを追加しても大幅な書き換えが不要になります。
「誰がこれを変えた?」という議論を防ぐために、監査ログを用意します。主要イベントを actor、timestamp、変更前後で記録します:
適切なパスワードポリシーを施し、エンドポイント(特にログインと受信)にレートリミットをかけ、セッション管理を保護します。
将来的なSAML/OIDCなどのSSO対応を想定して設計しておくとよいです:アイデンティティプロバイダIDを保存し、アカウント連携を計画しておくと、エンタープライズの要望が来たときに辛いリファクタを避けられます。
初期の最大のアーキテクチャリスクは「スケールするか」ではなく「速く変更できるか、壊さずに変更できるか」です。フィードバックアプリは、チームが実際にトリアージ、ルーティング、返信する方法を学ぶにつれて急速に進化します。
モジュラーなモノリスが最初の選択としてよく合います。デプロイは一つ、ログは一つ、デバッグはシンプル—それでいてコードベースは整理できます。
実用的なモジュール分割例:
「フォルダとインターフェースを分ける」ことを先に考え、苦痛になれば部分を抽出する方針にします。
チームが自信を持って出せるフレームワークとライブラリを選びます。退屈でよく知られたスタックは勝ちやすいです:採用とオンボーディングが容易、アップグレードが予測可能、プロダクションのデバッグが速い。
新奇なツールは、真の制約(高い受信率、厳しいレイテンシ、複雑な権限)に直面してからで良いでしょう。それまでは明瞭さと安定したデリバリを優先します。
コアエンティティ(feedback、customers、accounts、tags、assignments)はリレーショナルDBに自然に収まります。ワークフロー変更には良いクエリ、制約、トランザクションが必要です。
全文検索や高度なフィルタが重要になれば、専用の検索インデックスを追加できます(まずはDB内蔵の検索機能を使うのも手)。早期に真の2つの真実ソースを作らないでください。
メール送信、統合の同期、添付処理、ダイジェスト生成、Webhook発火など「あとでやる」処理は早めにキュー/ワーカーで処理します。
これによりUIは応答性を維持し、タイムアウトを減らし、失敗を再試行可能にします。初日からマイクロサービスに分ける必要はありません。
ワークフローとUIを素早く検証したいなら、構造化されたチャット仕様から初版を生成できるプラットフォーム(例: Koder.ai)を利用する選択肢もあります。ReactフロントエンドとGo + PostgreSQLのバックエンドを立ち上げ、計画段階で反復し、準備ができたらソースをエクスポートして通常の開発フローへ移せます。
ストレージ層はフィードバックループが速く信頼できるか、遅く混乱するかを左右します。日常作業(トリアージ、割り当て、ステータス)で問い合わせしやすいスキーマを目指しつつ、受領時の詳細を監査できるように保存します。
MVPでは少数のテーブル/コレクションで大半をカバーできます:
実用ルール:feedback は頻繁にクエリされる最小限にし、その他の詳細は events やチャネル固有のメタデータへ押し込む。
メール、チャット、Webhookでチケットが到着したら、受け取った生ペイロード(例:元のメールヘッダ+本文、WebhookのJSON)をそのまま保存します。これにより:
一般的なパターン:ingestions テーブルに source、received_at、raw_payload(JSON/テキスト/Blob)と作成/更新した feedback_id のリンクを持たせる。
ほとんどの画面は数個の予測可能なフィルタに還元されます。早期に以下へインデックスを追加します:
(workspace_id, status):インボックス/カンバンビュー(workspace_id, assigned_to):「自分の担当」(workspace_id, created_at):ソートと日付フィルタ(tag_id, feedback_id) または専用のタグ検索インデックス全文検索をサポートするなら、DBのテキスト検索か専用の検索インデックスを検討し、プロダクションで複雑な LIKE クエリを増やさないようにします。
フィードバックには個人データが含まれることが多いです。事前に決めておきます:
保持はワークスペースごとのポリシーとして実装し(例:90/180/365日)、スケジュールジョブで古い生ペイロードをまず期限切れにし、必要に応じて古いイベント/返信も削除します。
受信はフィードバックループがクリーンで有用なままか、混乱した山になるかを決めます。「送るのは簡単、処理は一貫している」を目標に。まず顧客が既に使っている数チャネルから始め、徐々に拡張します。
実用的な最初のセット:
初日から重厚なフィルタは不要ですが、基本的な保護は必要です:
すべてのイベントを内部の一つのフォーマットに正規化します:
生ペイロードと正規化レコードの両方を保持し、パーサー改善後に再処理できるようにします。
可能なら即時確認を送ります(メール/API/ウィジェット):感謝、次に何が起きるかを伝え、過剰な約束を避けます。例:「すべてのメッセージを確認します。追加情報が必要なら返信します。すべてに個別対応できないことがありますが、あなたのフィードバックは記録されます。」
インボックスが有用であり続ける条件は、チームが素早く三つの質問に答えられること:これ何?誰が担当?どれくらい緊急? トリアージは生メッセージを整理された作業に変える部分です。
フリーフォームタグは柔軟ですがすぐに断片化します("login", "log-in", "signin")。製品チームが既に考える方法に沿った小さな統制されたタクソノミーから始めます:
ユーザーに新タグを提案させることは許容しつつ、それを承認するオーナー(PMやサポートリード)を必須にしておくと、後でのレポーティングが意味あるものになります。
シンプルなルールエンジンを作り、予測可能なシグナルで自動ルーティングします:
ルールは透明にしておきます:「Routed because: Enterprise plan + keyword 'SSO'」のように理由を表示すると信頼されます。
各アイテムと各キューにSLAタイマーを追加します:
リストビューや詳細ページにSLA状況を表示し(「残り2時間」など)、重要性が個人の頭の中に閉じないように共有します。
停滞した項目への明確な経路を作ります:期限切れキュー、担当者向けの日次ダイジェスト、軽量なエスカレーション階層(Support → Team lead → On-call/Manager)。目的はプレッシャーではなく、重要な顧客フィードバックが静かに失われるのを防ぐことです。
ループを閉じることで、フィードバック管理システムは「収集箱」から信頼構築ツールになります。目標は簡単:各フィードバックは実際の作業に結びつき、要望した顧客に何が起きたかを伝えられること—手作業のスプレッドシートなしで。
単一のフィードバック項目が一つ以上の内部作業オブジェクト(バグ、タスク、機能)を指せるようにします。トラッキング全体を複製しようとせず、軽量の参照を保存します:
work_type(例:issue/task/feature)external_system(例:jira、linear、github)external_id と任意の external_urlこれによりツールを変えてもデータモデルは安定し、「このリリースに紐づく顧客フィードバックを全部見せて」といったビューが簡単に作れます。
リンクされた作業が Shipped(または Done/Released)になったら、関連するフィードバック項目に紐づく顧客全員へ通知できるようにします。
安全なプレースホルダ(名前、プロダクト領域、要約、リリースノートリンク)を使ったテンプレートメッセージを用意し、送信時に編集可能にしておくと不自然な文面を避けられます。公開ノートがある場合は相対パス(例:/releases)でリンクします。
確実に送信できるチャネルをサポートします:
どのチャネルでも、フィードバック項目ごとに監査可能なタイムラインで返信を追跡します:sent_at、channel、author、template_id、配信ステータス。顧客が返信してきた場合は受信メッセージもタイムスタンプ付きで保存し、ループが実際に閉じられたかを証明できるようにします。
レポートはチームの行動を変えるときにだけ有用です。まずは人々が日々確認する少数のビューを目指し、ワークフローデータ(ステータス、タグ、担当者、タイムスタンプ)が一貫していると確信できたら拡張します。
ルーティングとフォローアップを支援する運用ダッシュボードから始めます:
チャートはシンプルでクリック可能にし、マネージャがスパイクの具体的項目へドリルダウンできるようにします。
サポートとサクセスが文脈を持って回答できる「customer 360」ページを追加します:
このビューは重複質問を減らし、フォローアップを意図的にします。
チームは早期にエクスポートを求めます。提供するもの:
フィルタをどこでも一貫させます(タグ名、日付範囲、ステータス定義)。一貫性が「二つの真実」を防ぎます。
作成チケット数やタグ追加数のような「活動」を測るだけのダッシュボードは避けます。代わりに行動と応答に結びつく成果指標を優先します:初回応答時間、結果に到達した項目の割合、実際に対処された再発問題など。
フィードバックループは人々が日常的に使う場所にあると効果的です。統合はコピペを減らし、文脈を作業の近くに置き、「ループを閉じる」を習慣にします。
コミュニケーション、構築、顧客管理に使うシステムを優先します:
最初はシンプルに:一方向の通知+アプリへのディープリンク、後で(例:「Slackから担当を割り当て」など)書き戻しアクションを追加します。
ネイティブ統合が少数でも、Webhookで顧客や内部チームが好きなものに繋げられます。
安定した少数のイベントを提供します:
feedback.createdfeedback.updatedfeedback.closed冪等性キー、タイムスタンプ、テナント/workspace id、最小限のペイロードと詳細取得用URLを含めて、データモデルの進化で消費側が壊れないようにします。
統合はトークン失効、レート制限、ネットワーク問題、スキーマ不一致で失敗します。事前に設計しておきます:
もしこれをプロダクトとして提供するなら、統合は購入のきっかけにもなります。アプリ(とマーケティングサイト)から /pricing や /contact への明確な次のステップを示しましょう。
効果的なフィードバックアプリはリリース後に完成するものではなく、チームが実際にトリアージ、行動、返信する方法で形作られます。最初のリリースの目標は単純:ワークフローを検証し、手作業を減らし、信頼できるクリーンなデータを得ることです。
範囲を絞って素早く出して学ぶこと。実用的なMVPは通常:
エンドツーエンドでフィードバックを処理するのに不要な機能は後回しにします。
初期ユーザーは機能不足は許しますが、フィードバックの喪失や誤ルーティングは許しません。ミスが高コストになる箇所を重点的にテスト:
ワークフローへの信頼を目標にテストを行い、完璧なカバレッジを目指さないこと。
MVPでも以下の「地味だが必要」な要素を用意します:
パイロットから始めます:1チーム、限定チャネル、明確な成功指標(例:「高優先度フィードバックの90%に2日以内に応答」)。毎週摩擦点を集め、より多くのチームを招く前にワークフローを改善します。
利用データをロードマップの元にします:人がどこをクリックするか、どこで離脱するか、使われないタグ、ワークアラウンドが示す本当の要件など。
「ループを閉じる(closing the loop)」とは、Collect → Act → Reply → Learn の流れを確実にたどれることを意味します。実務では、各フィードバック項目が目に見える結果(実装、却下、説明、キュー入りなど)に至り、適切な場合には顧客向けの返答と時期が伴うことを指します。
速度と品質を反映する指標から始めましょう:
少数に絞って、見せかけの活動指標を追わないようにします。
すべてを単一の内部「フィードバック項目」形に正規化し、元データは残します。
実用的な方法:
これでトリアージが一貫し、パーサーを改善した際に古いメッセージを再処理できます。
コアモデルはシンプルでクエリしやすく保ちます:
短く共有されたステータス定義を書き、まずは線形のセットから開始します:
各ステータスが「次に何が起きるか」と「誰が次を担当するか」に答えるようにします。例えば “Planned” がチームごとに「多分」にならないように分けるか名前を変えます。
重複は「基になる同じ問題/要求」で定義します。単なる類似テキストで判断しないこと。
一般的なワークフロー:
こうすることで作業の断片化を防ぎつつ、需要の記録は残ります。
自動化はシンプルかつ監査可能に保ちます:
「なぜルーティングされたか」を表示して、人が信頼して修正できるようにします。まずは提案やデフォルトから始め、強制ルールは後で。
各ワークスペースを厳格な境界と扱います:
workspace_id を付与workspace_id でスコープ画面で判断するのではなく、アクション(閲覧/編集/マージ/エクスポート/送信)ごとにロールを定義します。変更履歴(監査ログ)を早期に入れておくと役立ちます。
モジュラーなモノリスから始め、境界を明確にします(auth/orgs、feedback、workflow、messaging、analytics)。トランザクション性が必要なワークフローにはリレーショナルDBを使います。
早期にバックグラウンドジョブを導入して以下を処理します:
こうすることでUIは速く保て、失敗は再試行可能になります。マイクロサービスへは後から分割可能です。
軽量な参照を保存し、別システムを丸ごと複製しないでください:
external_system(jira/linear/github)work_type(issue/task/feature)external_id(および任意の external_url)リンクした作業が になったら、テンプレート化した通知で関連する顧客全員に連絡します。公開メモがあれば相対パス(例: )でリンクします。
監査可能性のためにイベントタイムラインを使い、メインのfeedbackレコードに不要な負荷をかけないようにします。
/releases