2025年7月18日·1 分
オブザーバビリティとスロークエリログで本番を守る
オブザーバビリティとスロークエリログを使って、本番のアウトテージを検知・診断・予防する方法を学びます。計測、アラート、クエリの安全なチューニングの実践的手順つき。
オブザーバビリティとスロークエリログを使って、本番のアウトテージを検知・診断・予防する方法を学びます。計測、アラート、クエリの安全なチューニングの実践的手順つき。
本番はめったに一瞬で「壊れる」わけではありません。多くの場合、静かに劣化します:いくつかのリクエストがタイムアウトし始め、バッチが遅れ、CPUがじわじわ上がり、最初に気付くのは顧客です—あなたの監視はまだ「緑」を示しているのに。
ユーザーからの報告はたいてい曖昧です:「遅く感じる」。それは多数の根本原因に共通する症状です—データベースのロック競合、新しいクエリプラン、欠けたインデックス、ノイジーネイバー、リトライストーム、あるいは断続的に失敗する外部依存など。
視認性が低いと、チームは推測に頼ることになります:
多くのチームは平均値(平均レイテンシ、平均CPU)を追跡します。平均は痛みを隠します。ごく一部の非常に遅いリクエストが体験を台無しにする一方で、全体指標は問題なさそうに見えます。もし「稼働/停止」だけを監視しているなら、システムが技術的には稼働しているが実質的に使えない長い期間を見逃します。
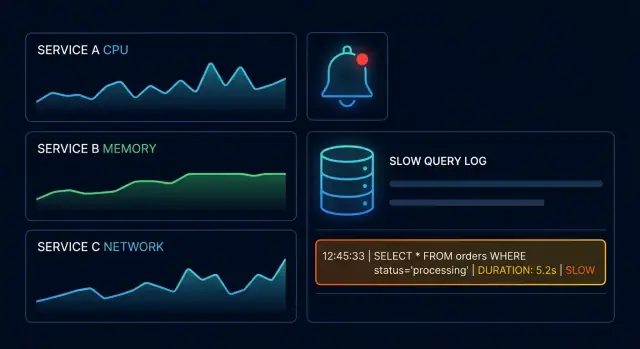
オブザーバビリティはシステムがどこで劣化しているか(どのサービス、どのエンドポイント、どの依存)を検出し絞り込むのに役立ちます。スロークエリログは、リクエストが停滞したときにデータベースが何をしていたか(どのクエリ、所要時間、どんな作業を行ったか)を証明するのに役立ちます。
このガイドは実践的です:より早く警告を得る方法、ユーザー向けレイテンシを特定のデータベース作業に結びつける方法、そして安全にクエリを調整する手順を扱います—ベンダー固有の約束に頼らずに。
オブザーバビリティとは、システムが生成する信号を見てその状態を理解できること—再現してみないとわからない、という状態から脱することです。ユーザーが遅さを感じていることを知るだけでなく、遅さがどこで起きているのか、なぜ始まったのかを突き止められる違いです。
メトリクスは時間経過の数値(CPU%、リクエスト率、エラー率、DBレイテンシ)です。クエリが速く、傾向や急上昇を見つけるのに向いています。
ログは詳細を持つイベント記録(エラーメッセージ、SQLテキスト、ユーザーID、タイムアウト)です。何が起きたかを人間が読める形で説明するのに最適です。
トレースはリクエストがサービスや依存をまたいで移動する様子を追います(API → アプリ → DB → キャッシュ)。どこに時間がかかっているか、どのステップが遅延を引き起こしたかを答えるのに理想的です。
有用なメンタルモデル:メトリクスは「何かが間違っている」と伝え、トレースは「どこで」、ログは「正確に何が」を教えてくれます。
健全なセットアップはインシデントへの対応を助け、次のような明確な答えを提供します:
監視は通常、事前定義されたチェックとアラート(「CPU > 90%」)に関することです。オブザーバビリティはさらに一歩進み、異常で未定義の障害モードに対して信号を切り分け、相関させて新しい質問を投げかける能力を提供します(例:ある顧客セグメントだけが遅いのは特定のDB呼び出しに紐づく、など)。
インシデント中に新しい質問をできる能力が、生のテレメトリを迅速で落ち着いたトラブルシューティングに変えます。
スロークエリログは「遅い」と定義した閾値を超えたデータベース操作の記録です。一般的なクエリログ(全てを記録する)と違って、スロークエリログはユーザーに見えるレイテンシや本番障害を引き起こしやすいステートメントを際立たせます。
ほとんどのデータベースは次のようなコアフィールドを取得できます:
このコンテキストのおかげで「このクエリが遅かった」から「このサービスからこの接続プール経由でこの時刻に遅かった」に変わり、複数のアプリが同じDBを共有しているときに重要になります。
スロークエリログは通常、単独の「悪いSQL」だけの話ではありません。データベースが余計な作業をしたか、待ちに入ったサインです。一般的な原因:
便利なメンタルモデル:スロークエリログは「作業(CPU/I/O負荷の高いクエリ)」と「待ち(ロック、飽和)」の両方を捉えます。
単一の閾値(例:「500ms超を記録」)はシンプルですが、典型レイテンシがずっと低い場合に痛みを見逃すことがあります。組み合わせを検討してください:
これによりスロークエリログは実行可能なまま、メトリクスはトレンドを表します。
パラメータがインライン化されると(メール、トークン、IDなど)スロークエリログが個人データを捕捉してしまうことがあります。パラメータ化クエリと、クエリ形状を記録する設定を優先してください。避けられない場合は、ログパイプラインで保存や共有前にマスキング/レダクションを加えます。
スロークエリはめったに「ただ遅い」だけでは終わりません。典型的な連鎖は:ユーザーのレイテンシ → APIレイテンシ → データベース圧迫 → タイムアウトです。ユーザーは最初にページのハングや読み込みの回転として感じます。間もなくAPIメトリクスに応答時間上昇が現れますが、アプリコードは変わっていないことがあります。
外から見ると、遅いデータベースは「アプリが遅い」に見えます。APIスレッドがクエリの完了を待ってブロックされるからです。アプリサーバのCPUやメモリは正常に見えても、p95/p99は上がります。アプリレベルのメトリクスだけ見ていると、HTTPハンドラやキャッシュ、デプロイを追いかけてしまい、本当のボトルネックである1つのクエリプランの後退を見逃します。
一度クエリが遅れると、システムは対処しようとし、その対処が悪化させることがあります:
チェックアウトエンドポイントが SELECT ... FROM orders WHERE user_id = ? ORDER BY created_at DESC LIMIT 1 を呼ぶとします。データ量が増え、インデックスの効果が薄れてクエリ時間が20msから800msに上がったとします。通常時は迷惑ですが許容できます。ピークトラフィック下では、APIリクエストがDB接続を待って積み上がり、2秒でタイムアウトし、クライアントがリトライします。数分で「小さな」スロークエリがユーザー目に見えるエラーになり、本番障害になります。
DBが苦しみ始めると、最初の手がかりは限られたメトリクスセットに現れます。目的はすべてを追うことではなく、変化を早く検出して原因箇所を絞ることです。
次の4つは、DB問題かアプリ問題か、あるいは両方かを判断するのに役立ちます:
いくつかのDB固有チャートが、ボトルネックがクエリ実行、同時実行、またはストレージにあるかを示します:
DBメトリクスとサービスの体験を組み合わせます:
ダッシュボードは素早く次を答えられるように設計します:
これらの指標が揃ったら—テールレイテンシの上昇、タイムアウトの増加、飽和の上昇—スロークエリログとトレースに pivot して正確な操作を特定します。
スロークエリログはDB内で「何が」遅かったかを示します。分散トレーシングは「誰がそれを要求したか」「どこから」「なぜ重要だったか」を示します。
トレースがあると「DBが遅い」アラートは具体的な物語になります:特定のエンドポイント(またはバックグラウンドジョブ)が一連の呼び出しをトリガーし、そのうちの1つがDB操作の待ちに大部分の時間を費やしている、という具合です。
APMのUIでは、高レイテンシのトレースから次を見ます:
GET /checkout や billing_reconcile_worker)トレースにフルSQLを入れるのはリスクがあります(PII、シークレット、大きなペイロード)。実用的な方法は、スパンにクエリ名/操作をタグ付けすることで、フル文を出さずに検索可能にすることです:
db.operation=SELECT と db.table=ordersapp.query_name=orders_by_customer_v2feature_flag=checkout_upsellこれによりトレースは安全で検索可能になり、コードパスを指し示します。
「トレース」→「アプリログ」→「スロークエリエントリ」へ橋渡しする最速の方法は共通の識別子です:
これで高価値な質問に速く答えられます:
スロークエリログは読みやすく実行可能であるときにのみ有用です。目的は「すべてを永遠にログする」ことではなく、クエリが遅い理由を説明するのに十分な詳細を、目立ったオーバーヘッドやコスト問題を起こさずにキャプチャすることです。
まずユーザー期待とDBの役割に合わせた絶対閾値を設定します。
>200ms、混在ワークロードなら >500ms次に、システム全体が遅くなったときでも問題を見つけられるよう相対ビューを追加します。
両方を使うと見落としを防げます:絶対閾値は常に悪いものを捕まえ、相対閾値は繁忙時の回帰を検出します。
ピーク時にすべての遅いステートメントをログするとパフォーマンスやノイズに悪影響を与えます。サンプリング(例:遅いイベントの10–20%を記録)を優先し、インシデント時にのみサンプリング率を上げます。
各イベントに次のようなアクション可能なコンテキストを含めてください:所要時間、参照/返却行数、データベース/ユーザー、アプリ名、可能ならリクエストIDやtrace ID。
生のSQLは散らかりがちです:異なるIDやタイムスタンプで同一クエリが別物に見えます。クエリフィンガープリント(正規化)を使って類似ステートメントをグルーピングし、例えば WHERE user_id = ? のようにします。
これで「どのクエリ形状が最もレイテンシを引き起こしているか?」に答えられます。
比較(before/after)に十分な期間だけ詳細なスロークエリログを保持します—実用的な開始点は通常 7–30日 です。
ストレージが問題なら古いデータをダウンサンプル(集計と上位フィンガープリントを残す)し、最近のウィンドウだけフルフェデリティを保持します。
アラートは「ユーザーがこれを感じる前に」知らせ、最初にどこを見るべきかを教えるべきです。その最も簡単な方法は、症状(ユーザーが感じること)と原因(それを引き起こしているもの)に基づくアラートを組み合わせ、オンコールが無視するように学習しないようノイズを制御することです。
ユーザーの痛みに相関する高シグナルの指標から始めます:
できればアラートを「ゴールデンパス」(checkout、login、search)に限定し、低重要度ルートでページングしないようにします。
症状アラートに加えて診断を短縮する原因指向のアラートを出します:
これらのアラートにはできればフィンガープリント、サニタイズしたパラメータの例、関連ダッシュボードやトレースビューへの直接リンクを含めます。
利用する手法:
すべてのページには「次に何をするか?」を含めるべきです—/blog/incident-runbooks のようなランブックへのリンクと最初の3チェック(レイテンシパネル、スロークエリリスト、ロック/接続グラフ)を指定します。
レイテンシがスパイクしたとき、迅速な回復と長引く障害との差は繰り返し可能なワークフローを持っているかどうかです。目標は「何かが遅い」から特定のクエリ、エンドポイント、そしてそれを引き起こした変更へと移ることです。
ユーザー症状(高レイテンシ、タイムアウト、エラー率増)から始めます。
p95/p99 レイテンシ、スループット、データベース健全性(CPU、接続、キュー/待ち時間)のような高シグナル指標で確認します。単一ホストの異常に踊らされず、サービス全体のパターンを見てください。
被害範囲を絞ります:
このスコーピングで間違った対象を最適化するのを防げます。
遅いエンドポイントの分散トレースを開き、最も長いもの順に並べます。
リクエストを支配するスパン(DB呼び出し、ロック待ち、または繰り返しのクエリ(N+1))を探します。リリースバージョン、テナントID、エンドポイント名などのコンテキストタグと照らし合わせ、遅延がデプロイや特定の顧客ワークロードと一致するか確認します。
疑わしいクエリをスロークエリログで検証します。
フィンガープリント(正規化クエリ)に注目し、総消費時間と件数で最悪のものを見つけます。影響を受けるテーブルや述語(フィルタや結合)を確認してください。ここで欠けたインデックス、新たな結合、クエリプランの変化が判明することが多いです。
リスクの低い緩和を最初に選びます:リリースをロールバックする、機能フラグを無効にする、負荷を削る、接続プール上限を増やす(競合を悪化させない場合のみ)等です。クエリを変更するなら、小さく測定可能な変更を行ってください。
配信パイプラインがそれをサポートするなら、ロールバックをヒーロー行為でなく第一選択可能なボタンとして扱ってください。Koder.ai のようなプラットフォームはスナップショットとロールバックワークフローでこれを支援し、遅いクエリパターンを偶発的に導入したリリースでの緩和時間を短くできます。
何が変わったか、どう検知したか、正確なフィンガープリント、影響を受けたエンドポイント/テナント、そして何が効いたかを記録します。それをフォローアップに変え、アラート追加、ダッシュボードパネル、パフォーマンスのガードレール(例:「p95でクエリフィンガープリントがX msを超えない」)などを設定します。
スロークエリが既にユーザーに影響を与えているときは、まず影響を減らし、その後パフォーマンスを改善します—インシデントを悪化させないことが最優先です。オブザーバビリティデータ(スロークエリサンプル、トレース、主要なDBメトリクス)はどのレバーを引くのが最も安全かを教えてくれます。
データ動作を変えない変更から始めます:
これらの緩和は時間を稼ぎ、p95レイテンシやDBのCPU/I/Oメトリクスで即時の改善が見られるはずです。
安定化後、実際のクエリパターンを治します:
EXPLAINで検証し、走査行数が減ることを確認するSELECT *を避ける、選択的な述語を追加、相関サブクエリの置換)変更は段階的に行い、同じトレース/スパンとスロークエリ署名で改善を確認します。
変更がエラー、ロック競合、負荷シフトを予測できない方法で増やすならロールバックします。ホットフィックスは変更を1つのクエリや1つのエンドポイントに限定でき、前後のテレメトリで安全性を検証できる場合に行います。
スロークエリを本番で直した後、本当の勝利は同じパターンが微妙な形で戻らないようにすることです。明確なSLOといくつかの軽量ガードレールが、1回のインシデントを恒久的な信頼性につなげます。
まずユーザー体験に直接結びつくSLIを設定します:
SLOは完璧さではなく、許容できるパフォーマンスを反映するように設定します。例:「p95 チェックアウトレイテンシを99.9%の分で600ms未満」。SLOが脅かされれば、リスクのあるデプロイを停止しパフォーマンスに注力する客観的理由になります。
多くの再発は回帰です。各リリースの前後比較を簡単にしておくと発見が早まります:
重要なのは平均ではなく分布(p95/p99)の変化をレビューすることです。
「遅くなってはいけない」エンドポイントとその重要クエリを少数選び、CIにパフォーマンスチェックを入れて閾値や許容ドリフトを超えたら落とすようにします。これによりN+1のバグ、意図しないフルテーブルスキャン、境界のないページングをリリース前に捕まえられます。
高速にサービスを作る場合(例:Reactフロントエンド、Goバックエンド、PostgreSQLスキーマを素早く生成・反復するKoder.ai のようなチャット駆動型アプリビルダー)、これらのガードレールはさらに重要です:速度は機能ですが、最初からテレメトリ(trace ID、クエリフィンガープリント、安全なログ)を組み込まないと意味がありません。
スロークエリレビューを誰かの仕事にします:
SLOで「良い状態」を定義し、ガードレールでドリフトを捕まえれば、パフォーマンスは繰り返しの緊急ではなく、配信の管理された一部になります。
DBに焦点を当てたオブザーバビリティセットアップは速く2つの質問に答えられるべきです:「データベースがボトルネックか?」 と 「どのクエリ(どの呼び出し元)が原因か?」。良いセットアップはそれを明らかにします—エンジニアが1時間も生ログをgrepする必要がないように。
必要なメトリクス(インスタンス、クラスタ、役割/レプリカごとに分けてあるのが理想):
スロークエリログに必要なログフィールド:
相関のためのトレースタグ:
期待すべきダッシュボードとアラート:
エンドポイントレイテンシのスパイクを特定のクエリフィンガープリントとリリースバージョンに結びつけられますか?レアで高コストなクエリを保持するためのサンプリングはどう扱いますか?ノイズの多いステートメントをフィンガープリントで重複排除し、時間的回帰をハイライトできますか?
組み込みのレダクション(PIIとリテラルの削除)、RBAC、ログとトレースの明確な保持制限を探してください。データをデータウェアハウス/SIEMにエクスポートするときにこれらの制御をバイパスしないことを確認します。
ベンダー評価中なら、要件を早めに揃え内部でショートリストを共有し、ベンダーを巻き込むと良いでしょう。簡単な比較やガイダンスが欲しければ /pricing を参照するか /contact で連絡してください。
まずエンドポイントごとの**テールレイテンシ(p95/p99)**を見て、平均だけで判断しないでください。次に、タイムアウト、リトライ率、データベースの飽和指標(接続待ち、ロック待ち、CPU/I/O)と相関させます。
これらが同時に動いているなら、トレースに切り替えて遅いスパンを特定し、スロークエリログに入って正確なクエリのフィンガープリントを特定します。
平均は外れ値を隠します。ごく一部の非常に遅いリクエストが体験を壊しても、平均値は「正常」に見えることがあります。
最低限これを追跡してください:
これらがユーザーが実際に体験する長いテールを明らかにします。
互いに補完する「どこ(where)」と「何(what)」として使います。
両者を組み合わせることでルート原因特定までの時間が劇的に短くなります。
通常は以下を含めます:
重要なのは「どのサービスがいつトリガーしたのか」「そのパターンが繰り返し発生しているか」を答えられることです。
利用者体験とワークロードに基づいて閾値を選びます。
実用的なアプローチ:
すべてを記録するのではなく、実行可能な範囲に保つのが目的です。
**クエリフィンガープリント(正規化)**を使って、同じクエリ形状をグループ化します。
例: WHERE user_id = ?(固定値ではなく)にすることで、IDやタイムスタンプの違いで同一クエリがバラけるのを防ぎます。
その後、フィンガープリントを以下でランク付けします:
生のリテラルをそのまま保存しないでください。
良い実践:
これでインシデント時のデータ露出リスクを下げられます。
典型的なカスケードは:
ループを断つには、リトライを減らし、プールの可用性を回復し、遅いクエリフィンガープリントに対処することが多いです。
症状と原因の両方でアラートを出します。
症状(ユーザー影響):
原因(調査開始のため):
マルチウィンドウ/バーンレートでノイズを減らしましょう。
まずローリスクな緩和策を取り、その後クエリを直します。
緩和(即効):
修正(本質):
変更の前後は同じトレーススパンとスロークエリフィンガープリントで効果を検証してください。