2025年11月26日·1 分
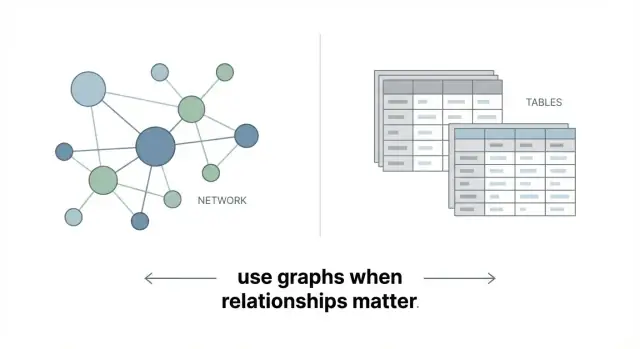
関係が重要なときにこそ強いグラフデータベース — すべてに最適というわけではない
接続が問いの本質を左右する場面で、グラフデータベースは強みを発揮します。適したユースケース、トレードオフ、リレーショナルやドキュメントDBが向く場面を解説します。
接続が問いの本質を左右する場面で、グラフデータベースは強みを発揮します。適したユースケース、トレードオフ、リレーショナルやドキュメントDBが向く場面を解説します。
グラフデータベースはデータをテーブルの集合ではなくネットワークとして保存します。核心はシンプルです:
これだけです:グラフデータベースは接続されたデータを直接表現するように作られています。
グラフでは、リレーションシップは後付けではなく実際にクエリ可能なオブジェクトとして保存されます。リレーションシップは自身のプロパティを持てます(例:PURCHASED のリレーションシップに日付、チャネル、割引を保持できる)し、ノードからノードへ効率的にたどれます。
これが重要なのは、多くのビジネスの問いが本質的に経路や接続に関するからです:「誰が誰とつながっているか?」「このエンティティは何手先にあるか?」「この2つのものの共通リンクは何か?」といった問いです。
リレーショナルデータベースは構造化されたレコード(顧客、注文、請求書)に強みがあります。そこにも関係は存在しますが、通常は外部キーで間接的に表現され、複数ホップをつなぐには複数テーブルのジョインが必要になります。
グラフは接続をデータのそばに保持するため、複数ステップの関係を探るのがモデリングもクエリもより分かりやすくなります。
グラフは関係性が主題である場合に優れます—レコメンデーション、不正リング、依存関係マップ、ナレッジグラフ。単純なレポートや集計、非常に表形式のワークロードに自動的に勝るわけではありません。目的はすべてを置き換すことではなく、接続が価値を生むところにグラフを使うことです。
多くのビジネスの問いは単一レコードではなく、どう繋がっているかに関するものです。
顧客は単なる行ではなく、注文、デバイス、住所、サポートチケット、紹介、場合によっては他の顧客と結びついています。トランザクションは単なるイベントではなく、加盟店、支払い方法、場所、時間窓、関連活動のチェーンと結びつきます。「誰が何とつながっていて、どう繋がっているか」が問題なら、関係データが主役になります。
グラフデータベースはトラバースのために設計されています:あるノードを起点にエッジをたどってネットワークを“歩く”。
テーブルを何度もジョインする代わりに、関心のある経路を表現します:Customer → Device → Login → IP Address → Other Customers。この一歩ずつの枠組みは、不正調査、依存関係の追跡、レコメンデーションの説明に自然に合います。
違いが顕著になるのは、複数ホップ(2、3、5手先など)必要で、どこに興味深い接続が現れるか事前に分からない時です。
リレーショナルモデルではマルチホップの質問は長いジョインの連鎖と、重複回避や経路長制御の追加ロジックになりがちです。グラフでは「最大Nホップまでの全経路を見つける」は普通で可読なパターンです—特に多くのグラフデータベースで使われるプロパティグラフモデルではなおさらです。
エッジは単なる線ではなくデータを持てます:
これらにより「過去30日以内に接続された」「最も強いつながり」「高リスク取引を含む経路」といった問いが、別途ルックアップテーブルを作らずに尋ねられます。
接続性が価値の源泉であるなら、グラフはモデリングもクエリも自然に感じさせます。
友だち、フォロワー、同僚、チーム、紹介などネットワーク形状のものはノードとリレーションで綺麗に表現できます。「共通のつながり」「ある人までの最短経路」「2つのグループをつなぐのは誰か?」といった問いは、複数のジョインに押し込むと不自然または遅くなりがちです。
推薦エンジンは多段の接続に依存することが多い:user → item → category → 類似アイテム → 他のユーザー。グラフは「Xを好きな人はYも好き」「共に閲覧されたアイテム」「共有属性や行動でつながる商品を見つける」に適しています。シグナルが多様でリレーションシップの種類を増やし続ける場合に特に有効です。
不正検知は稀に孤立して発生しないため、アカウント、デバイス、トランザクション、電話番号、メール、住所が共有識別子の網を形成します。グラフはリングや繰り返すパターン、間接的なリンク(例えば一見無関係な2つのアカウントが活動の連鎖で同じデバイスに行き着く)を見つけやすくします。
サービス、ホスト、API、コール、所有関係の主目的は依存関係:"これが変わると何が壊れるか?"。グラフは影響分析、根本原因の探索、「ブラスティング半径」クエリに向きます。
人、会社、製品、文書を事実や参照と結ぶナレッジグラフは、検索、エンティティ解決、そしてある事実の由来(プロベナンス)を追跡するのに役立ちます。
グラフは接続に関する問いで真価を発揮します。テーブルを何度も結合する代わりに、関係の問いを直接尋ねられるので、ネットワークが大きくなってもクエリが読みやすく保てます。
よくある質問:
カスタマーサポート("なぜこの提案をしたか?")、コンプライアンス("所有のチェーンを見せて")、調査("どう広がったか?")で有用です。
グラフは自然な集まりを見つけます:
これを使ってユーザーをセグメント化したり、不正クルーを見つけたり、共買い傾向を理解できます。ポイントは“グループ”が単一のカラムではなく接続で定義されることです。
「誰がつながりの網の中で最も多くの経路に乗っているか?」「どの商品が2つの顧客セグメント間の強い橋になっているか?」といった問いです。中心ノードはインフルエンサーや重要インフラ、ボトルネックを示します。
グラフは繰り返し現れる形状の検索に強い:
たとえば Cypher では三角形パターンは次のように書けます:
MATCH (a)-[:KNOWS]-\u003e(b)-[:KNOWS]-\u003e(c)-[:KNOWS]-\u003e(a)
RETURN a,b,c
自分で Cypher を書かなくても、この例はクエリが頭に浮かぶ図と対応していることを示しています。
リレーショナルは設計どおりトランザクションや構造化レコードに強みがあります。データがテーブルにきれいに収まり、主に ID やフィルタ、集計で取得するならリレーショナルが簡単で安全です。
ジョインは時折で浅ければ問題ありません。摩擦が生まれるのは重要な問いが常に多くのジョインを必要とするときです。
例:
SQLでは長いセルフジョインや複雑なロジックになり、接続深度が増すとチューニングも難しくなります。
グラフはリレーションシップを明示的に保存するため、多段のトラバースが自然な操作です。クエリはテーブルをつなぐ代わりにノードとエッジをたどります。
その結果:
チームが頻繁に “接続先をたどる” 質問(「〜とつながっているか」「〜を介して」「Nステップ以内」)をするなら、グラフは検討に値します。
コアの負荷が 高頻度トランザクション、厳格なスキーマ、レポーティング、単純なジョインであるなら、まずはリレーショナルを選ぶべきです。多くの実システムでは両者を併用します。詳細は /blog/practical-architecture-graph-alongside-other-databases を参照してください。
前述のとおり、グラフはリレーションシップが“主役”のときに冴えます。アプリの価値が接続のトラバースに依存しないなら、グラフは複雑さだけ増やす結果になります。
ほとんどのリクエストが「IDでユーザー取得」「プロフィール更新」「注文作成」で、必要なデータが単一レコードや予測可能な少数テーブルにあるなら、グラフは不要です。ノードやエッジを設計し、トラバースをチューニングし、新しいクエリスタイルを学ぶ時間がコストになります。
月別売上、地域別注文、チャネル別コンバージョンなどのダッシュボードは、SQLやカラムナー分析の方が向いています。グラフでも集計はできますが、重い OLAP ワークロードには最適解とは限りません。
複雑なジョインや厳密な制約、高度なインデックス、ストアドプロシージャ、確立された ACID パターンに頼る場合は、リレーショナルが自然な選択です。多くのグラフもトランザクションをサポートしますが、周辺のエコシステムや運用パターンがチームの期待と異なることがあります。
チケット、請求書、センサ読み取り値などが独立して大量にありクロスリンクが少ない場合、グラフは無理に当てはめると不自然です。そういう時はまずリレーショナル(やドキュメント)で整え、将来的に関係中心の質問が増えたらグラフを検討します。
良いルール:主要クエリを“connected”“path”“neighborhood”“recommend”のような言葉なしに説明できるなら、最初からグラフを選ぶ必要はないことが多いです。
グラフは接続を素早くたどるのに長けていますが、そこには代償があります。グラフが効率が悪い、コストが高い、運用が異なる点を理解しておきましょう。
グラフはホップを速くするために関係を保持・インデックス化するため、同等のリレーショナル構成よりメモリやストレージコストが高くなることがあります。特に共通検索向けのインデックスを追加したり、関係データを常時アクセス可能にすると顕著です。
スプレッドシートのような大規模テーブルスキャンや集計が主体のワークロードでは、グラフは遅いか高コストになることがあります。グラフは「誰が何とつながっているか?」のトラバースに最適化されており、大量の独立レコードの計算には向きません。
バックアップ、スケーリング、モニタリングなどの運用がリレーショナルとは異なります。あるプラットフォームはスケールアップ(より大きなマシン)が得意で、別のものはスケールアウトをサポートしますが整合性・レプリケーション・クエリパターンに細心の設計が必要です。
プロパティグラフや Cypher のようなクエリアプローチを学ぶ時間が必要になります。学習曲線は管理可能ですが、既存の SQL ベースのレポーティングワークフローを置き換える場合はコストになります。
実用的な方法は、関係がプロダクトの価値を生む箇所だけにグラフを使い、レポートや集計は既存システムに残すことです。
モデリングを考える単純な方法は:ノードはモノ、エッジはモノ同士の関係。人、アカウント、デバイス、注文、商品、場所がノード。"Bought"、"logged_in_from"、"works_with"、"is_parent_of" がエッジです。
多くの製品指向のグラフDBはプロパティグラフモデルを使い、ノードとエッジの両方がプロパティ(key–value)を持てます。例:PURCHASED エッジに date、amount、channel を持たせられ、"詳細を持つ関係"を自然にモデル化できます。
RDF は subject–predicate–object のトリプルで知識を表現します。相互運用や標準化された語彙に強い一方、リレーションシップの詳細を追加のノード/トリプルに分ける傾向があります。実務では RDF はオントロジーや SPARQL の文脈で、プロパティグラフはアプリ寄りのモデリングで好まれます。
初期は構文を暗記する必要はなく、グラフクエリが通常 経路とパターン として表現されることを理解すれば十分です。
グラフは多くの場合 スキーマ柔軟 であり、新しいノードラベルやプロパティをマイグレーションなしに追加できます。ただし柔軟性には規律が必要です:命名規約、必須プロパティ(例:id)、リレーションシップ種類のルールを定めましょう。
意味を説明するリレーションタイプ("FRIEND_OF" と "CONNECTED" の違いなど)を選び、向きでセマンティクスを明確にし(例:FOLLOWS はフォロワー→クリエイター)、関係自体に事実がある場合はエッジにプロパティを持たせます(時間、信頼度、ロール、重みなど)。
「問題が関係駆動」であるとは、難しいのがレコードの保存ではなく、物事のつながりを理解すること、そして経路によって意味が変わることです。
まずステークホルダーが頻繁に聞く上位5〜10の質問をプレーンな言葉で書いてください。グラフ候補は普通「connected」「through」「similar」「within N steps」「who else」といった語句を含みます。
例:
質問がまとまったら、名詞と動詞を書き出します:
次に、何をリレーションにし何をノードにするかを決めます。実用的なルール:属性が多く多数の当事者と繋がるものはノードにする(例:Order や Login イベント)。
結果を絞り、関連度でランク付けするためのプロパティを追加しましょう。高価値なプロパティ例:time、amount、status、channel、confidence score。
もし重要な問いの多くが複数ホップの接続に加えてこれらのプロパティによる絞り込みやランク付けを必要とするなら、関係駆動の問題でありグラフが適している可能性が高いです。
ほとんどのチームはすべてをグラフに置き換えません。実用的なのは、既にうまく機能している“正本”を残し、関係重視の問いに特化したグラフを補助エンジンとして使うアプローチです。
トランザクション、制約、正規エンティティはリレーショナルに保持し、接続クエリに必要なノードとエッジだけをグラフに投影します。これにより監査とデータガバナンスがシンプルなまま高速なトラバースが可能になります。
明確にスコープされた機能(例:レコメンデーション、リスクスコア、不正検知、ID解決)に紐づけたほうが成功しやすいです。1つの機能、1チーム、1つの計測可能な成果から始め、価値が証明できれば徐々に拡張します。
もしプロトタイプの立ち上げがボトルネックなら、Koder.ai のようなvibe-codingプラットフォームで簡単なグラフ対応アプリを素早く立ち上げることも可能です:チャットで機能を記述すると React UI と Go/PostgreSQL バックエンドを生成し、データチームがグラフスキーマとクエリを検証しながら反復できます。
グラフの鮮度要件に応じて選びます:
よくあるパターンは:SQL にトランザクションを書き → 変更イベントを出す → グラフを更新、です。
ID がずれるとグラフは煩雑になります。安定した識別子(例:customer_id, account_id)を定義し、各フィールドとリレーションの「所有者」を文書化してください。二つのシステムが同じエッジ(例:"knows")を作れるなら、どちらが優先かを決めておきます。
パイロットを計画する場合は /blog/getting-started-a-low-risk-pilot-plan にある段階的なローアウト手順を参照してください。
グラフのパイロットは実験のように扱い、全部書き換えるのではなく検証を目標にします。目的は「関係中心のクエリがよりシンプルかつ高速になるか」を実証することです。
JOIN が多すぎる、脆い SQL、遅い「誰が誰とつながっているか」の質問を引き起こすデータセットから始めます。ワークフローを一つに限定し(例:customer ↔ account ↔ device、または user ↔ product ↔ interaction)、エンドツーエンドで答えたい数個のクエリを定義します。
速度だけでなく次を測りましょう:
「ビフォー」の数値がなければ「アフター」を信頼できません。
何でもかんでもノード/エッジにするのは誘惑ですが避けてください。ノードやリレーションのラベルは増やし過ぎないこと。新しいラベルや関係は実際のクエリで必要になることを根拠に追加しましょう。
プライバシー、アクセス制御、データ保持の方針を早めに決めます。関係データは個別レコード以上の情報を明らかにすることがあり得ます(例えば接続から行動が推測される)。誰が何をクエリできるか、結果の監査方法、削除要件の扱いを定めてください。
バッチかストリーミングの簡単な同期でグラフを供給し、既存システムを正本に保ちます。パイロットで価値が示せれば、慎重にスコープを拡大していきます。
データベースを選ぶときは技術先行ではなく、まず答えるべき問いから始めてください。グラフは 接続 と 経路 が最も困難な問題である場合に輝きます。
ほとんどに「はい」と答えたら、特に「2+ホップのパターンマッチング」が必要な場合はグラフが強い適合になります。
主に ID やメールでの単純検索 や 集計(月別売上など)が中心であれば、リレーショナルやキー・バリュ/ドキュメントストアの方が単純で安価です。
上位10のビジネス質問をプレーンな文で書き、実データで小さなパイロットを試してください。クエリの時間を計り、表現しにくかった点と必要になったモデル変更を短く記録します。パイロットが「もっとジョインを書くだけ」や「キャッシュが増えた」になればグラフは合わない可能性が高いです。逆に、クエリが簡潔になり応答が改善するなら拡張を検討してください。
グラフデータベースは、ノード(エンティティ)とリレーションシップ(接続)を、両方にプロパティを持てる形で保存します。主に「AはBとどう繋がっているか?」や「Nステップ以内に誰がいるか?」のような、接続に関する問いに最適化されています。
リレーションシップが実際のクエリ対象として保存される、つまり単なる外部キーではなく「クエリできる実体」です。複数ホップを効率的にたどれることや、リレーションシップ自体に date や amount、risk_score といったプロパティを持たせられる点が、接続重視の質問を扱いやすくします。
リレーショナルは外部キーで関係を間接的に表現し、複数ホップの問いには多くの JOIN が必要になることが多いです。グラフは接続をデータのそばに保持するため、可変深度のトラバーサル(2〜6ホップなど)を自然に表現できます。
コアの問いが経路・近傍・パターンに関係する場合にグラフが有効です。具体例:
グラフに向く典型的な問いは:
次の場合はグラフが不適切であることが多いです:
そのようなケースではリレーショナルや分析向けストアの方が簡単で安価です。
エッジ(リレーションシップ)としてモデル化すべきなのは、主に2つのエンティティをつなぐもので、かつその関係自体に属性がある場合です(時間、役割、重みなど)。逆に、属性が多く多数の当事者と繋がる「イベント」や「注文」はノードにする方が扱いやすいことが多いです(例:Order や Login イベント)。
期待されるトレードオフ:
プロパティグラフではノードとリレーションシップの両方にプロパティ(key–value)を持たせられ、アプリ寄りのモデリングに向いています。RDFは三つ組(subject–predicate–object)で知識を表現し、語彙の共有や相互運用性に強みがあります。用途に応じて選んでください。
プロパティグラフ → アプリ中心の関係属性が重要 RDF+SPARQL → 相互運用と共通語彙が重要
既存システムを全部置き換える必要はありません。典型的なパターンは:
同期は「SQLへ書く → 変更イベントを公開 → グラフを更新」の流れがよく使われます。詳細は /blog/practical-architecture-graph-alongside-other-databases と /blog/getting-started-a-low-risk-pilot-plan を参照してください。