2025年11月07日·1 分
ジェフリー・ヒントンのニューラルネットワーク革新をやさしく解説
バックプロップやボルツマンマシン、ディープネット、AlexNetまで、ジェフリー・ヒントンの主要なアイデアをわかりやすく整理し、現代のAIにどう影響したかを解説します。
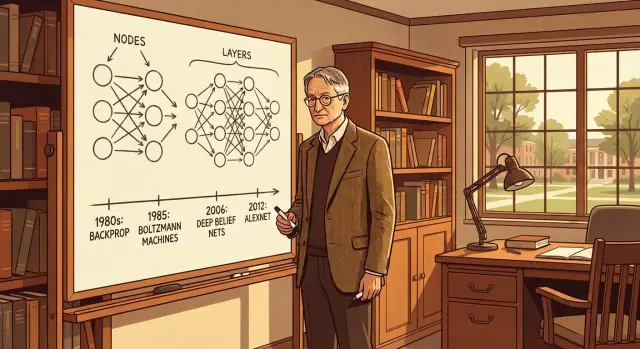
バックプロップやボルツマンマシン、ディープネット、AlexNetまで、ジェフリー・ヒントンの主要なアイデアをわかりやすく整理し、現代のAIにどう影響したかを解説します。
このガイドは、"ニューラルネットワークが全てを変えた" とよく聞く非専門の読者向けに、微積分やプログラミングを必要とせずに要点をわかりやすく説明することを目指しています。
ジェフリー・ヒントンが推進した考え方、それらが当時なぜ重要だったのか、そして今使われているAIツールとどうつながるかを平易な言葉でたどります。要するに、コンピュータにサンプルからパターン(言葉、画像、音)を学ばせるより良いやり方の物語だと考えてください。
ヒントンが「AIを発明した」わけではありませんし、現代の機械学習を一人で作り上げた人もいません。彼の重要性は、ニューラルネットワークが実務上動くようにする働きを何度も成し遂げた点にあります。彼は表現学習(有用な内部特徴を学ぶこと)を中心課題として扱う研究文化を築き、重要な概念や実験、実践的な手法を提示しました。
以下の節では次を分かりやすく解説します:
ここでのブレークスルーは、ニューラルネットワークがより実用的になる変化を指します:訓練が安定する、より良い特徴を学ぶ、新しいデータに対して正確に一般化する、あるいはより大きな課題に拡張できるようになる――といった変化です。派手なデモ一回より、アイデアを信頼できる手法に変えることに重きがあります。
ニューラルネットワークは「プログラマを置き換える」ために考案されたわけではありません。元々の約束はもっと具体的でした:画像、音声、テキストのような雑多な現実世界の入力から役に立つ内部表現を学び、エンジニアがすべてのルールを手作業で書かなくてもよい仕組みを作ることです。
写真はただの多数のピクセル値に過ぎません。音声録音は圧力の連続測定です。課題はそれらの生の数値を、エッジ、形、音素、単語、物体、意図といった人が関心を持つ概念に変えることです。
ニューラルネットワークが実用化する前は、多くのシステムが手作りの特徴(エッジ検出器やテクスチャ記述子など)に頼っていました。それは狭い条件では機能しましたが、照明が変わったりアクセントが違ったり、環境が複雑になると壊れやすかったのです。
ニューラルネットワークはデータから層ごとに特徴を自動で学ぶことでこれを解決しようとしました。システムが中間の有効なビルディングブロックを自力で見つけられれば、より良く一般化し、手作業の工数を減らして新しいタスクに適応できます。
アイデアは魅力的でしたが、いくつかの障壁が長くネットを実用化させませんでした:
ニューラルネットワークが不人気だった時期(特に1990年代や2000年代初頭)でも、ジェフリー・ヒントンのような研究者は表現学習の研究を続けました。彼は1980年代中頃からアイデアを提示し、エネルギーベースモデルのような古い概念も見直しました。ハードウェアやデータ、手法が追いつくまで粘り強く研究を続けたことが、コアの目的を生かし続ける助けになりました。
バックプロパゲーション(略してバックプロップ)は、ニューラルネットワークがミスから学ぶ手法です。ネットワークが予測をし、その誤差を測り、内部の「つまみ」(重み)を調整して次は少しだけ正しくなるようにします。
ネットワークが写真を「猫」か「犬」かと判定し、間違って「猫」と出したとします。正解は「犬」です。バックプロップは最終的な誤りから始めて、ネットワークの層を逆にたどり、どの重みが誤りにどれだけ寄与したかを計算します。
実用的な考え方はこうです:
これらの小さな動きは通常、勾配降下法というアルゴリズムで行われます。これは簡単に言えば「誤差の山を少しずつ下る」方法です。
バックプロップが広く採用される前は、多層ネットワークの訓練は信頼できず遅かったです。バックプロップは多層を同時に調整する体系だったため、より深いネットワークを訓練できるようになり、層ごとにより豊かな特徴(エッジ→形→物体など)を学べるようにしました。
この変化が次に来る多くのブレークスルーに重要な土台を与えました。
バックプロップはネットワークが人間のように「考えている」わけではありません。数学的なフィードバックであり、例に対してパラメータをより合うように調整する手法です。
また、バックプロップは単一のモデルではなく、さまざまなニューラルネットワークで使える訓練手法です。
詳しいネットワーク構造の穏やかな深掘りは /blog/neural-networks-explained を参照してください。
ボルツマンマシンは、ニューラルネットワークが役に立つ内部表現を学ぶためのヒントンの重要な一歩でした。
ボルツマンマシンはオン/オフの単純なユニット(現代版では実数値を取ることもあります)からなり、出力を直接予測するのではなくユニット全体の構成にエネルギーを割り当てます。エネルギーが低いほど「その構成はもっともらしい」となります。
たとえるなら、凹凸のあるテーブル上にビー玉を置くと、ビー玉は低い谷へ転がり落ちていきます。ボルツマンマシンも似たことをします:部分的な情報が与えられると(可視ユニットの一部がデータで固定される)、内部ユニットを「揺らして」学習した低エネルギーの状態へ落ち着こうとします。
古典的なボルツマンマシンの訓練は、多くの状態を繰り返しサンプリングしてモデルの信念とデータの違いを推定する必要があり、これが非常に遅いことが多いです。
それでもこのアプローチが与えた影響は次の点にあります:
今日の製品の多くは、拡張性や速度の面からフィードフォワードな深層ネットワークをバックプロップで訓練して使っています。ボルツマンマシンの遺産は、実用性というよりは概念的な影響—世界の「望ましい状態」を学ぶという考え方—として残っています。
ニューラルネットワークは単に曲線を当てはめるのが上手になっただけではなく、適切な特徴を発明することが上手になりました。これが表現学習の意味です:人間が特徴を設計するのではなく、モデルが内部表現を学んでタスクを容易にします。
表現は生の入力を要約するモデル自身の方法です。まだ「猫」というラベルではなく、タスクへ向かう途中の有用な構造です。初期層は単純な信号に反応し、後の層はそれらを組み合わせてより意味のある概念を形成します。
以前は多くのシステムが人間の専門家が設計した特徴に頼っていました(画像のエッジ検出や音声の手作りキュー、テキストの手作業統計など)。それらは狭い範囲では機能しましたが、条件が変わると壊れやすいという欠点がありました。
表現学習はデータ自体に合わせて特徴を適応させるため、精度が向上し、雑多な実入力に対して堅牢になります。
共通点は階層性です:単純なパターンが結合されて豊かなものになる。
画像認識では、ネットワークはまずエッジのようなパターンを学び、それらを角や曲線へと組み合わせ、次に車輪や目のような部品へ、最終的に自転車や顔のような全体へと構築していきます。
ヒントンのブレークスルーは、この階層的な特徴構築を実用化した点が大きく、これが深層学習が実務タスクで勝つ理由の一つです。
ディープビリーフネット(DBN)は、今日知られる深層ニューラルネットへの重要な橋渡しでした。概念的には、DBNは層を重ねる構造で、各層が下の層の表現を学び、段階的に抽象度を高めていきます。
手書き文字認識を教えることを想像してください。一度にすべてを学ぼうとするのではなく、DBNはまずエッジや筆跡といった単純なパターンを学び、その次にループや角といった組み合わせを学び、最終的に数字の部品に似た高次の形を学びます。
各層はまず正解ラベルなしに入力のパターンをモデル化し、その後スタック全体を特定タスク(例えば分類)に微調整します。
以前の深いネットワークはランダムに初期化すると訓練がうまくいかないことが多く、信号が層を通るうちに弱くなったり不安定になったりしてネットワークが望ましくない設定に落ち着くことがありました。
層ごとの事前学習は各層にデータ構造の妥当な理解を与え、全体が手当たり次第に探索する必要を減らしました。
事前学習がすべての問題を一気に解決したわけではありませんが、データや計算資源、訓練トリックが限られていた時期に深さを実用化する助けになりました。DBNは多層で良い表現を学べることを示し、深さが単なる理論でなく実用的な道であることを証明しました。
ニューラルネットワークはよく「試験問題を丸暗記している」ようになってしまうことがあります。これは過学習と呼ばれ、訓練データでは高精度でも新しい実データでは性能が落ちる問題です。
たとえば運転試験のために前回通ったルートを丸暗記していると、同じルートならうまくいきますが別のルートになれば困ります。本当の運転スキルを学んでいないからです。これが過学習です。
ドロップアウトはヒントンらによって広められた訓練トリックです。訓練中にネットワークのユニットをランダムに一部「オフ」にします。
これによりネットワークはどの経路にも過度に依存できなくなり、情報を複数の接続に分散して学ぶようになります。メモの数ページがランダムに使えなくなる環境で勉強するようなもので、特定の表現を丸暗記するのではなく概念を理解することを促します。
主な効果は一般化性能の向上です。ドロップアウトは大きなネットワークでも丸暗記に陥りにくくし、より堅牢に未知データへ適用できるようになりました。そのため多くのディープラーニング設定で標準的な手法になっています。
AlexNet以前、「画像認識」は魅力的なデモであるだけでなく測定可能な競技でした。ImageNetのようなベンチマークは「写真を見て中身を当てられるか?」というシンプルな問いを投げかけますが、カテゴリ数や画像数が膨大である点が重要でした。
そのスケール感により、小規模実験では有望に見えても実世界で通用しないアイデアと、実際に拡張できる方法が分かれていきました。進歩は通常段階的でしたが、AlexNet(Alex Krizhevsky、Ilya Sutskever、Geoffrey Hintonによる)は結果を大きく押し上げ、変化が一気に感じられる出来事になりました。
AlexNetは深い畳み込みニューラルネットワークが従来のコンピュータビジョン手法を上回ることを示しました。その成功には三つの要素が噛み合っていました:
これは単なる「より大きなモデル」ではなく、実世界タスクで深層ネットを効果的に訓練する実践的なレシピを示しました。
画像上を小さな「窓」を滑らせることを想像してください。切り出した領域の中でネットワークは単純なパターン(エッジ、角、筋)を探します。このパターン検出器は画像のどこにあっても同じように使われるため、左でも右でも同じようにエッジを見つけられます。
これを何層も重ねると階層ができます:エッジがテクスチャになり、テクスチャが部品になり、部品が物体になります。
AlexNetは深層学習が信頼に足る方向だと示しました。厳しい公的ベンチマークで深層ネットが支配すれば、検索、写真タグ付け、カメラ機能、アクセシビリティなど製品の改善につながるはずだと多くの企業が判断しました。これによりニューラルネットワークは「有望な研究」から製品戦略上の明白な方向へと変わりました。
ディープラーニングは「一夜にして」到来したわけではありません。何年もかけていくつかの要素が揃ったときに劇的に見えるようになったのです。
より多いデータ。 ウェブやスマートフォン、ImageNetのような大規模データにより、ニューラルネットワークは数千例ではなく数百万例から学べるようになりました。小規模データでは大きなモデルは単に丸暗記してしまいます。
より多い計算(特にGPU)。 深いネットワークの訓練は同じ計算を何十億回も行うことを意味します。GPUはそれを手頃で高速にしてくれ、以前は数週間かかったものが数日や数時間で済むようになりました。これにより研究者はより多くのアーキテクチャやハイパーパラメータを試せるようになりました。
より良い訓練トリック。 実践的な改善が「訓練が成功するかしないか」のランダム性を減らしました:
これらはニューラルネットワークの核となるアイデアを変えたわけではなく、動作させるための信頼性を高めました。
計算資源とデータが閾値を超えると、改良が積み上がって見えるようになります。良い結果がさらに投資を呼び、より大きなデータと高速なハードウェアが得られ、さらに良い結果を出す──外から見るとジャンプのように見えますが、内側では複利的に進んでいます。
スケールアップには実際のコストが伴います:エネルギー消費の増加、高価な訓練、効率的に展開する労力増加。小さなチームがプロトタイプを作るのと、資金のある研究所が初期から大規模訓練を行うのとの間に差が生まれがちです。
ヒントンの主要な考え方――データから有用な表現を学ぶこと、深層ネットを安定して訓練すること、過学習を防ぐこと――はアプリの「ここがこうだ」と指差せる個別機能ではありません。ですが、日常的な機能がより高速で正確に、使いやすく感じられる基盤を作っています。
現代の検索は単にキーワードを一致させるだけではありません。クエリとコンテンツの表現を学ぶことで「ベストなノイズキャンセリングヘッドホン」のような検索が、まったく同じ語句を含まないページでも良い候補を返せるようになります。同じ表現学習がレコメンデーションにも応用され、説明文が異なる二つのアイテムが「似ている」と判断されることを可能にします。
翻訳は、文字から単語、意味への階層的な学習が進んだことで大きく改善しました。基礎となるモデルの種類は進化していますが、訓練の常套手段――大規模データ、最適化の工夫、正則化の考え方――は信頼できる言語機能を作る上で今も重要です。
音声アシスタントや文字起こしは、雑多な音声をきれいなテキストに写像するニューラルネットワークに依存しています。バックプロップはそれらを調整するエンジンであり、ドロップアウトのような手法は特定の話者やマイクのクセを丸暗記しないようにします。
写真アプリは顔認識、類似シーンのグルーピング、"beach"で検索して手作業のラベルなしに結果を返すなどができます。これは表現学習の応用で、エッジ→テクスチャ→物体という流れが大規模なタグ付けや検索を可能にしています。
スクラッチでモデルを訓練しない場合でも、これらの原則は日々のプロダクト作業に現れます:事前学習済みモデルから始め、訓練と評価を安定化させ、システムがベンチマークを丸暗記し始めたら正則化を使う、といった具合です。
これが、現代の「vibe-coding」系ツールが高性能に感じられる理由でもあります。Koder.aiのようなプラットフォームは現世代の大規模言語モデルやエージェントのワークフローの上に乗り、プレーンランゲージの仕様からウェブやバックエンド、モバイルアプリを素早く作り出し、ソースコードをエクスポートして通常の開発チームと同様にデプロイできるようにします。
高レベルな訓練直感を知りたい方は /blog/backpropagation-explained を参照してください。
大きなブレークスルーは単純化された物語にされがちで、覚えやすくなりますが実際の経緯や重要な点を隠してしまうことがあります。
ヒントンは中心的な人物ですが、現代のニューラルネットワークは多数のグループの何十年にもわたる成果の集合です。最適化手法を開発した人、データセットを作った人、GPUで訓練を可能にしたエンジニア、大規模でアイデアを実証したチーム――多くの貢献が積み重なって現在があります。
ヒントンの業績の中でも、彼の学生や共同研究者が重要な役割を果たしました。実際の物語は連鎖的な貢献の積み重ねです。
ニューラルネットワークの研究は20世紀中頃から続いており、興奮と失望の周期がありました。変わったのはアイデアの存在ではなく、大規模モデルを安定して訓練できる能力と実問題での明確な勝利が示された点です。ディープラーニング時代は突然の発明ではなく再興と考える方が正確です。
深いモデルは有効なことが多いですが万能ではありません。訓練時間、コスト、データ品質、漸減する利得など現実的な制約があります。タスクによっては小さなモデルがチューニングしやすく、ノイズに強く、目的に合っているため優れることもあります。
バックプロップはラベル付きフィードバックを用いてパラメータを調整する実用手法です。人間はずっと少ない例から学び、豊富な先験知識を使い、同じ種類の明示的な誤差信号に依存しません。ニューラルネットは生物学に触発され得ますが、脳の正確なコピーではありません。
ヒントンの物語は単なる発明の列挙ではなくパターンです:単純な学習アイデアを持ち続けて徹底的に試し、周辺の要素(データ、計算、訓練トリック)を順に改善してスケールさせるまで続ける。
実用的な習慣が最も移植可能です:
見出しだけを取って「大きなモデルが勝つ」と追いかけるのは不十分です。サイズを追うだけでは:
より良いデフォルトは:小さく始めて価値を証明し、明確に性能を制限している部分だけをスケールする ことです。
日々の実践に落とすなら次が良い続きです:
バックプロップの基本ルールから、意味を捉える表現、ドロップアウトのような実践的工夫、AlexNetのような実証デモまで――弧は一貫しています:データから有用な特徴を学び、訓練を安定させ、実際の結果で進捗を検証する。これが守るべきプレイブックです。
ジェフリー・ヒントンは、多くの研究者がニューラルネットワークは行き詰まっていると考えていた時期に、実際に動くようにするための研究を繰り返し行った点で重要です。
「AIを発明した」わけではなく、彼の貢献は表現学習を推進し、学習手法を改良し、手作業でルールを書くのではなくデータから特徴を学ぶことを重視する研究文化を築いた点にあります。
ここでの「ブレークスルー」とは、ニューラルネットワークがより頼りになり、実用的になった変化を指します:訓練が安定する、内部表現が向上する、新しいデータへ一般化できる、あるいはより大きなタスクに拡張できるようになった、ということです。
派手なデモそのものよりも、アイデアを繰り返し使える手法に変えた点を重視しています。
ニューラルネットワークは、ピクセルや音声波形、テキストといった生の入力を、役に立つ表現(内部特徴)に変えることを目指しています。
エンジニアがすべての特徴を手作業で設計するのではなく、モデル自身が例から層を重ねて学ぶことで、照明やアクセント、表現の違いにも強くなります。
バックプロパゲーションは、モデルがミスから学ぶための訓練手法です:
これは通常、勾配降下法のようなアルゴリズムと組み合わせて、誤差を小さくする方向へ小さな一歩を繰り返します。
バックプロップは多層を一度に系統的に調整できるようにしたため重要でした。
これにより奥行き(深さ)のあるネットワークが実用的になり、層ごとに豊かな特徴階層(例:エッジ→形→物体)を学べるようになりました。ランダム初期化だけでは多層の学習が不安定になりがちだったのです。
ボルツマンマシンは、ユニットの全体構成に対して「エネルギー」を割り当て、低エネルギーの構成を「もっとらしい」と扱うモデルです。
重要だった点は:
ただし古典的なボルツマンマシンはサンプリングが遅く、大規模化が難しいため、今日の実用製品ではあまり直接使われていません。
表現学習とは、モデル自身がタスクを容易にする内部特徴を学ぶことを指します。人が手で作った特徴ではなく、データから自動で有益な中間表現を獲得します。
実務上の利点は堅牢性です:学習された特徴は照明やマイク、話者の違いなど現実の変動に対して、手作りの特徴より適応しやすいことが多いです。
ディープビリーフネットワーク(DBN)は、各層が下の層を表現することを学ぶ積み重ね構造です。概念的には、まず単純なパターン(エッジや筆跡)を学び、その上でより複雑な構造を順に学んでいきます。
層ごとの事前学習(プリトレーニング)は“ウォームスタート”を提供し、全体を一度にランダムに学習するより安定して深さを実用化する助けになりました。最終的にスタック全体を微調整して分類などのタスクに適用します。
ドロップアウトは、訓練中にランダムにユニットを「消す」ことで過学習を抑えます。
これによりネットワークはある特定の経路に依存することができなくなり、部分が欠けても成立するような特徴を学ぶことを強制されます。結果として未知のデータへの一般化性能が向上し、大きなネットワークでも丸暗記に陥りにくくなりました。
AlexNetは「深い畳み込みネットワーク + GPU + 大量ラベル付きデータ(ImageNet)」という実用的なレシピが機能することを示しました。
これは単にモデルを大きくしただけではなく、ハードなベンチマークで従来手法を一気に上回る実証になり、業界の投資を引き寄せた点で決定的でした。
バックプロップの基本ルールから、表現が意味を捉える仕組み、ドロップアウトのような実用的な工夫、そしてAlexNetのような実証デモまで、流れは一貫しています:データから有益な特徴を学び、訓練を安定させ、実際の結果で検証する。
このプレイブック(実践手順)は今も価値があります。