2025年4月03日·2 分
AIアプリにおけるフロントエンドとバックエンドの状態管理
AIアプリでUI、セッション、データ状態がフロントエンド/バックエンド間でどのように流れるかを学び、同期、永続化、キャッシュ、セキュリティに関する実践的パターンを解説します。
AIアプリにおける「状態」の意味
「状態」とは、アプリが次の瞬間に正しく動作するために覚えておくべきすべてです。
ユーザーがチャット画面で送信を押したとき、アプリは入力した文、アシスタントが既に返した内容、リクエストが実行中かどうか、設定(トーン、モデル、ツール)が有効かどうかを忘れてはいけません。これらすべてが状態です。
平易に言うと
状態を考える便利な視点は:アプリの現在の事実—ユーザーに見せる内容やシステムが次に何をするかに影響する値、です。フォーム入力のような明白なものに加えて、以下のような「目に見えない」事実も含まれます:
- ユーザーがどの会話にいるか
- 最後の応答がストリーミング中か完了しているか
- メッセージの一覧と順序
- ツール呼び出しとその結果(検索結果、DB参照、ファイル抽出など)
- エラー、リトライ、レート制限のバックオフ
なぜAIアプリはより多くの要素を扱うのか
従来のアプリはデータを読み表示し更新を保存することが多いですが、AIアプリは追加のステップや中間出力を伴います:
- 単一のユーザー操作が複数のバックエンド操作(LLM 呼び出し、ツール呼び出し、追加の LLM 呼び出し)を引き起こすことがある。
- 応答は逐次的に到着する(トークンのストリーミング)ため、UI は部分的な状態を管理する必要がある。
- コンテキストが重要:システムは会話メモリ、ツール出力、モデル設定をリクエスト間で整合させる必要がある。
この余計な動きが、AIアプリで状態管理が隠れた複雑さになりやすい理由です。
このガイドで扱うこと
以下では状態を実用的なカテゴリ(UI 状態、セッション状態、永続データ、モデル/ランタイム状態)に分け、それぞれがどこに置くべきか(フロントエンド vs バックエンド)を示します。さらに同期、キャッシュ、長時間ジョブ、ストリーミング更新、セキュリティについても扱います—状態は正しく保護されて初めて役に立ちます。
クイックな例シナリオ
ユーザーが「先月の請求書を要約して、異常な点をマークして」と尋ねるチャットアプリを想像してください。バックエンドは (1) 請求書を取得し、(2) 分析ツールを実行し、(3) 要約を UI にストリーミングし、(4) 最終レポートを保存するかもしれません。
これがシームレスに感じられるためには、メッセージ、ツール結果、進捗、保存された出力を追跡しつつ、会話を混同したりユーザー間でデータを漏らしたりしてはなりません。
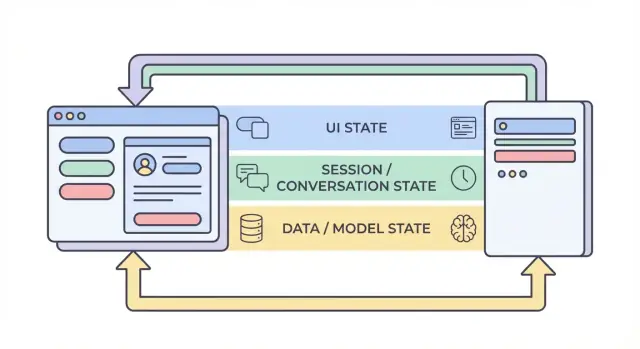
状態の4層:UI、セッション、データ、モデル
人々が AI アプリで「状態」と言うとき、非常に異なるものを混同することが多いです。状態を UI、セッション、データ、モデル/ランタイムの4つに分けると、どこに置くべきか、誰が変更できるか、どう保存すべきかを判断しやすくなります。
1) UI 状態(ユーザーが今していること)
UI 状態はブラウザやモバイルアプリのライブな瞬間的状態:テキスト入力、トグル、選択項目、どのタブが開いているか、ボタンが無効かどうか、などです。
AI アプリは UI 特有のいくつかの詳細を追加します:
- ローディング表示や「思考中」状態
- ストリーミングされるトークン(生成されるにつれて部分的に表示されるテキスト)
- 送信前のローカル下書きメッセージ
UI 状態はリセットしやすく、失っても安全であるべきです。ページをリフレッシュすると失われることがあり、通常それで問題ありません。
2) セッション/会話状態(ユーザーのフローに紐づく共有コンテキスト)
セッション状態はユーザーを継続的なやり取りに結びつけます:ユーザー識別、会話 ID、メッセージ履歴の一貫したビューなど。
AI アプリではこれに以下が含まれることが多いです:
- メッセージ履歴(またはそれへの参照)
- ツールトレース(どの関数/ツールが呼ばれ、どんな結果が返ったか)
- 「作業セット」の選択(現在のプロジェクト/ドキュメント、選択されたモデル、ワークスペース)
この層はフロントエンドとバックエンドの両方にまたがることが多いです:フロントエンドは軽量な識別子を保持し、バックエンドがセッションの継続性とアクセス制御の権威になります。
3) データ状態(ストレージの耐久的レコード)
データ状態は意図的にデータベースに保存するものです:プロジェクト、ドキュメント、埋め込み、設定、監査ログ、課金イベント、保存された会話記録など。
UI やセッション状態とは異なり、データ状態は:
- 耐久的(再起動後も残る)
- クエリ可能(検索/フィルタができる)
- 監査可能(後で何が起きたか理解できる)
べきです。
4) モデル/ランタイム状態(AI が今どのように構成されているか)
モデル/ランタイム状態は回答を生成するために使われる操作設定です:システムプロンプト、許可されたツール、temperature/max tokens、安全設定、レート制限、一時キャッシュなど。
その一部は設定(安定したデフォルト)で、一部はエフェメラル(短命キャッシュやリクエストごとのトークン予算)です。多くはバックエンドに置くのが妥当で、一貫して制御され不必要に公開されないようにします。
なぜ分離がバグを減らすのか
これらの層が混ざると、典型的な失敗が起きます:UI に保存されていないテキストが表示される、バックエンドがフロントエンドの期待と異なるプロンプト設定を使う、会話メモリがユーザー間で「漏れる」など。明確な境界は真実の所在を明確にし、何を永続化すべきか、何を再計算できるか、何を保護すべきかを分かりやすくします。
フロントエンドとバックエンドのどちらに置くか(理由付き)
AI アプリでバグを減らす信頼できる方法は、状態の各要素について、それがブラウザ(フロントエンド)にあるべきか、サーバー(バックエンド)にあるべきか、あるいは両方かを決めることです。この選択は信頼性、セキュリティ、ユーザーがリフレッシュや新しいタブを開いたときの「驚き」に影響します。
フロントエンド状態:高速、一時的、ユーザー主導
フロントエンド状態は素早く変わり、リフレッシュをまたいで残す必要のないものに最適です。ローカルに置くことで UI は応答性が高くなり、不要な API 呼び出しを避けられます。
フロントエンド専用の一般例:
- ユーザーが入力中の下書きメッセージテキスト
- テーブルのローカルフィルタやソート順
- モーダルの開閉状態、選択タブ、ホバー状態
リフレッシュで失っても許容されることが多いです。
バックエンド状態:権威的、機密的、共有されるもの
バックエンドには信頼されるべきもの、監査されるべきもの、強制されるべきものを置くべきです。他のデバイスやタブが見る必要があるもの、あるいはクライアントを改変されても正しく保たれるべきものが該当します。
バックエンドのみの一般例:
- 権限やロール(ユーザーが何をできるか)
- 課金/サブスクリプション状況や使用制限
- 長時間ジョブ(ドキュメントインデックス作成、大きなエクスポート、ファインチューニング実行)の状態
間違った状態が金銭的損失やデータ漏洩、アクセス制御の破綻につながるなら、それはバックエンドに置くべき、という心構えが有効です。
共有状態:調整はするが真実の一つの所在を持つ
共有される状態もあります:
- 会話タイトル
- チャットで選ばれた知識ソース
- デバイス間で使われるユーザープロファイル項目
共有される場合でも「真実の所在(source of truth)」を選びましょう。通常、バックエンドが権威で、フロントエンドは速度のためにキャッシュを持ちます。
経験則(とよくあるアンチパターン)
状態を必要な場所に近づけつつ、リフレッシュやデバイス変更、中断をまたいで残すべきものは永続化しましょう。
クライアントだけに機密や権威的な状態を置くアンチパターン(例:クライアント側の isAdmin フラグやプラン階層、ジョブ完了状態を真実として扱う)は避けてください。UI はそれらを表示してよいですが、検証はバックエンドが行うべきです。
典型的な AI リクエストのライフサイクル:クリックから完了まで
AI 機能は「1つの操作」のように感じられますが、実際はブラウザとサーバーにまたがる一連の状態遷移です。ライフサイクルを理解すると、UI の不一致、コンテキストの欠落、重複請求を避けやすくなります。
1) ユーザーアクション → フロントエンドが意図を準備
ユーザーが 送信 をクリックします。UI はローカル状態を即座に更新します:「保留中」のメッセージバブルを追加したり、送信ボタンを無効化したり、現在の入力(テキスト、添付、選択されたツール)をキャプチャしたりします。
この時点でフロントエンドは相関識別子を生成または添付すべきです:
- conversation_id:どのスレッドか
- message_id:クライアント側の新規ユーザーメッセージ ID
- request_id:試行ごとに一意(リトライ時に有用)
これらの ID により、応答が遅れたり二重に届いたりしても双方が同じイベントについて話せます。
2) API 呼び出し → サーバーが検証し永続化
フロントエンドはユーザーメッセージと ID を含む API リクエストを送ります。サーバーは権限、レート制限、ペイロード形式を検証し、ユーザーメッセージを(少なくとも不変のログレコードとして)conversation_id と message_id をキーに永続化します。
この永続化により、リクエスト中にページをリフレッシュしても「幻の履歴」が生じるのを防げます。
3) サーバーがコンテキストを再構築
モデルを呼ぶためにサーバーは信頼できるソースからコンテキストを再構築します:
conversation_idの最近のメッセージを取得- 関連レコード(ドキュメント、設定、ツール出力)を引く
- 会話ポリシー(システムプロンプト、メモリルール、トランケーション)を適用
重要な考え方:クライアントに完全な履歴を頼らないこと。クライアントは古くなり得ます。
4) モデル/ツール実行 → 中間状態
サーバーはモデル呼び出しの前や途中でツール(検索、DB 参照)を呼ぶかもしれません。各ツール呼び出しは request_id に紐づけて追跡し、監査や安全なリトライができるようにします。
5) 応答(ストリーミングまたは非ストリーミング)→ UI 完了
ストリーミングではサーバーが部分的なトークン/イベントを送ります。UI は保留中のアシスタントメッセージを逐次更新しますが、最終イベントで完了とマークされるまで「進行中」と扱います。
6) 想定すべき失敗ポイント
リトライ、二重送信、順序違いの応答は起きます。サーバー側での重複排除には request_id を使い、UI 側では message_id で整合させて(アクティブなリクエストに合わない遅延チャンクを無視するなど)扱ってください。常に「失敗」状態をわかりやすく表示して、安全なリトライで重複メッセージを作らないようにします。
セッションと会話メモリ:コンテキストを混乱なく保つ
再試行の重複を防ぐ
Koder.aiにリクエストIDや冪等キーをエンドポイントに組み込ませましょう。
セッションはユーザーのアクションをつなぐスレッドです:どのワークスペースにいるか、最後に検索したもの、編集中の下書き、AI の返信をどの会話に続けるかなど。良いセッション状態はページ間でアプリを連続的に感じさせ、理想的にはデバイス横断でも自然に動作しますが、バックエンドをすべての発言のゴミ箱にしてはいけません。
セッション状態の目標
目指すのは:(1) 継続性(ユーザーが離れて戻れる)、(2) 正確性(AI が正しい会話コンテキストを使う)、(3) 分離(セッション同士が漏れない)です。複数デバイスをサポートするなら、セッションをユーザースコープ+デバイススコープとして扱いましょう:「同じアカウント」=「同じ開いている作業」ではない場合があります。
Cookie vs トークン vs サーバーセッション
セッション識別には通常どれかを選びます:
- Cookies:ブラウザが自動的に送るため Web に最も簡単。伝統的なセッションに向くが、
HttpOnly、Secure、SameSiteなどのセキュアフラグを設定し、CSRF に対処する必要がある。 - トークン(例:JWT):モバイルや API に向いており、クライアントが明示的に付与できる。スケールしやすいが、取り消しやローテーションは追加設計が必要。トークン内に機密状態を詰め込むべきではない。
- サーバーセッション:サーバーがセッションデータを(Redis 等に)保持し、クライアントは不透明なセッション ID だけ持つ。取り消し/更新が容易だが、セッションストアの運用とスケーリングが必要。
会話メモリ戦略
「メモリ」はモデルに送り返す状態を指します。
- フル履歴:最も正確だがコストがかかり、古い機密コンテンツを表面化する可能性がある。
- 要約履歴:ランニングサマリー+直近数ターン。安価で通常は十分。
- ウィンドウ方式:直近 N メッセージのみ。単純だが重要な過去の判断を失う可能性がある。
実用的なパターンは要約+ウィンドウです:予測可能で、モデルの驚きの挙動を抑えます。
ツール呼び出し:再現可能で監査可能に
AI がツール(検索、DB クエリ、ファイル読み取り)を使うなら、各呼び出しを入力、タイムスタンプ、ツールバージョン、戻り値(またはその参照)と共に保存しましょう。これにより「なぜ AI がそう言ったか」を説明でき、デバッグのために実行を再生でき、ツールやデータセットが変わったときに結果が変わった原因を検出できます。
プライバシーのガードレール
長期的メモリをデフォルトで保存しないでください。継続性に必要なもの(会話 ID、要約、ツールログ)のみを保持し、保持期間を設定し、製品上の明確な理由とユーザー同意がない限り生のユーザーテキストを永続化しないでください。
状態を安全に同期する:真実の所在と競合処理
同じ「もの」が複数箇所で編集可能になると状態が危険になります—UI、別タブ、バックグラウンドジョブなど。解決策は巧妙なコードというよりは所有権を明確にすることです。
真実の所在を定義する
各状態項目についてどのシステムが権威かを決めてください。多くの AI アプリでは会話設定、ツール権限、メッセージ履歴、課金限度、ジョブ状態などはバックエンドが正規のレコードを持つべきです。フロントエンドは速度のためにキャッシュと派生状態を持てますが、矛盾があればバックエンドが正しいと仮定すべきです。
実用的なルール:リフレッシュで失うと困るなら、それはバックエンドにある可能性が高い。
楽観的 UI 更新(注意して使う)
楽観的更新はアプリを即時に感じさせます:設定を切り替えたら UI を即更新し、その後サーバーで確認する。これは低リスクで可逆な操作(例:会話をスターする)には有効です。
ただし、サーバー側が拒否したり変更を加える可能性がある場合(権限チェック、クオータ、バリデーション、サーバー側デフォルト)、混乱を招きます。その場合は「保存中…」を表示してサーバー確認後に UI を更新してください。
競合処理(複数タブで同一会話を編集)
競合は、異なる開始バージョンに基づいて二つのクライアントが同じレコードを更新するときに起きます。例:タブ A とタブ B が両方モデルの temperature を変更する。
軽量なバージョニングを使い、バックエンドが古い書き込みを検出できるようにします:
updated_atタイムスタンプ(単純で人間がデバッグしやすい)- ETag /
If-Matchヘッダ(HTTP ネイティブ) - インクリメンタルなリビジョン番号(明示的な競合検出)
バージョンが一致しない場合は競合レスポンス(多くは HTTP 409)を返し、最新のサーバーオブジェクトを返しましょう。
ミスマッチを減らす API 設計
書き込みの後は、保存されたオブジェクト(サーバー生成のデフォルト、正規化フィールド、新しいバージョンを含む)を API が返すと良いです。これによりフロントエンドはキャッシュをすぐ置き換えられ、何が変わったかを推測する必要がなくなります。
キャッシュとパフォーマンス:高速化と古い状態のバランス
キャッシュは AI アプリを高速にする最短の方法の一つですが、状態の二重コピーも生みます。間違ったものを、あるいは間違った場所でキャッシュすると、高速だが混乱する UI を出荷してしまいます。
クライアントで何をキャッシュするか
クライアント側キャッシュは体験を重視すべきで、権威ではありません。適切な候補は最近の会話プレビュー(タイトル、最後のメッセージの抜粋)、UI 設定(テーマ、選択モデル、サイドバー状態)、楽観的 UI 状態(「送信中」のメッセージ)などです。
クライアントキャッシュは小さく破棄可能に保ち、消えてもサーバーから再取得すればアプリが動くようにしてください。
サーバーで何をキャッシュするか
サーバーキャッシュは高コストまたは頻繁に繰り返される作業に焦点を当てるべきです:
- 再利用が安全なツール結果(例:同じ都市の天気検索を5分間再利用)
- 埋め込みルックアップやベクター検索結果(短い TTL で)
- レート制限状態やスロットリングのカウント(API とコストを守るため)
トークン数、モデレーション判定、ドキュメント解析結果など、決定論的で高コストな派生状態もここでキャッシュできます。
キャッシュ無効化の基本(難しくしない)
実用的なルールは三つ:
- 入力をエンコードする明確なキャッシュキーを使う(
user_id, model, tool パラメータ, document バージョン)。 - 基データがどれくらい早く変わるかに基づいた TTL を設定する。短い TTL の方が賢いロジックより安全。
- 正確性が速度より重要なときはキャッシュをバイパスする:ユーザーがドキュメントを更新した後、権限を変更した後、またはリフレッシュを要求したとき。
キャッシュエントリがいつ不正確になるか説明できないなら、キャッシュしてはいけません。
共有キャッシュに機密や個人データを置かない
API キー、認証トークン、生のプロンプトなど機密情報を CDN 等の共有レイヤーに入れないでください。ユーザーデータをキャッシュする必要がある場合はユーザー単位で分離し、保存時に暗号化するか、主要なデータベースに保持してください。
影響を測る:速度 vs 古い UI
キャッシュは仮定ではなく実証すべきです。p95 レイテンシ、キャッシュヒット率、そしてユーザーに見えるエラー(例:「レンダリング後にメッセージが更新された」)を追跡してください。高速だが後で UI と矛盾する応答は、少し遅くても一貫した応答より悪い場合があります。
永続化と長時間処理:ジョブ、キュー、およびステータス状態
状態を安全に保つ
サーバー側の認可チェックと安全なバリデーションパターンを状態書き込みに生成します。
一部の AI 機能は数秒で終わりますが、PDF のアップロードと解析、ナレッジベースの埋め込みとインデックス作成、多段階のツールワークフローは数分かかることがあります。これらでは「状態」は画面上だけでなく、リフレッシュ、リトライ、時間をまたいで生き残るものです。
何を永続化するか(とその理由)
実際にプロダクト価値を解放するものだけを永続化してください。
会話履歴:メッセージ、タイムスタンプ、ユーザー識別、どのモデル/ツールが使われたかは明白な保存対象です。再開、監査、サポートに役立ちます。
ユーザー/ワークスペース設定:好みのモデル、temperature のデフォルト、機能トグル、システムプロンプト、デバイス間で追従すべき UI 設定はデータベースに置きます。
ファイルと成果物:アップロード、抽出テキスト、生成レポートは通常オブジェクトストレージに置き、データベースにメタデータ(所有者、サイズ、コンテンツタイプ、処理状態)を保持します。
長時間タスクのためのバックグラウンドジョブ
リクエストが通常の HTTP タイムアウト内に確実に終わらない場合は作業をキューに移してください。
典型パターン:
- フロントエンドが
POST /jobsのような API を呼び、入力(ファイル ID、conversation ID、パラメータ)を渡す。 - バックエンドはジョブをキューに入れ、すぐに
job_idを返す。 - ワーカーが非同期でジョブを処理し、結果を永続ストレージに書き込む。
これにより UI は応答性を保ち、リトライが安全になります。
UI が信頼できるステータス状態
ジョブ状態は明示的にし問い合わせ可能にしてください:queued → running → succeeded/failed(オプションで canceled)。これらの遷移をサーバー側にタイムスタンプやエラー詳細と共に保存します。
フロントエンドでの反映例:
- Queued/running: スピナーを表示し重複アクションを無効にする。
- Failed: 簡潔なエラーと Retry ボタンを表示。
- Succeeded: 成果物を読み込むか会話を更新。
GET /jobs/{id}(ポーリング)や SSE/WebSocket のようなストリーム更新を提供し、UI が推測しないようにします。
冪等性キー:重複書き込みを避けるリトライ
ネットワークタイムアウトは起きます。フロントエンドが POST /jobs をリトライするとき、同じジョブが二重に作られるのは避けたいです。
論理的アクションごとに Idempotency-Key を要求してください。バックエンドはキーを結果と共に保存し、同じキーの繰り返し要求には同じ結果を返します。
クリーンアップと有効期限ポリシー
長時間稼働する AI アプリは急速にデータを蓄積します。早めに保持ルールを定義してください:
- 古い会話は N 日後に期限切れにする(ユーザーが設定できるようにするのも良い)。
- 元ソースが削除されたら派生成果物を削除する。
- 失敗したジョブや中間ファイルは定期的に消去する。
クリーンアップは状態管理の一部です:リスク、コスト、混乱を減らします。
ストリーミング応答とリアルタイム更新:部分的状態の管理
ストリーミングでは「答え」は単一の塊ではなくなります。部分トークン(単語ごとに到着するテキスト)や部分的なツール作業があることを扱う必要があります。これにより UI とバックエンドで何が一時的で何が最終なのか合意しておく必要があります。
バックエンド:単なるテキストではなく型付きイベントをストリームする
クリーンなパターンは、型とペイロードを持つ小さなイベントのシーケンスをストリームすることです。例:
token:増分テキスト(または小さなチャンク)tool_start:ツール呼び出しが始まった(例:「検索中…」、id 付き)tool_result:ツール出力が準備完了(同じ id)done:アシスタントメッセージが完了error:何かが失敗した(ユーザー向けメッセージとデバッグ id を含む)
このイベントストリームは、生テキストストリーミングよりバージョン管理やデバッグが容易で、フロントエンドはツール状況を推測せずに正確に表示できます。
フロントエンド:追記専用更新、そして最終コミット
クライアントではストリーミングを追記専用として扱います:「下書き」のアシスタントメッセージを作り、token イベントが届くたびに拡張します。done を受け取ったらコミットを行い:メッセージを最終としてマークし、(ローカルに保存するなら)永続化して、コピーや評価、再生成などの操作を解放します。
これによりストリーム中に履歴を書き換えるようなことを避け、UI を予測可能に保てます。
中断の処理(キャンセル、切断、タイムアウト)
ストリーミングは半端な作業の発生確率を高めます:
- ユーザーがキャンセル:キャンセル信号を送り、トークン表示を止め、下書きをキャンセルとして可視化する。
- ネットワーク切断:ストリームを停止し「再接続中…」を表示し、完了を想定しない。
- サーバーのタイムアウト/エラー:下書きを失敗として最終化し、新しいリクエストでリトライできるようにする(ストリームを黙って繋ぎ合わせない)。
リハイドレーション:安定した状態を再構築する
ページがストリーム中にリロードされた場合は、最後にコミットされたメッセージと保存された下書きメタデータ(message id、これまでの蓄積テキスト、ツール状況)から再構築してください。ストリームを再開できない場合は下書きを中断表示にしてユーザーにリトライさせる方が、完了したように見せかけるより良いです。
セキュリティとプライバシー:状態をエンドツーエンドで保護する
アーキテクチャをコード化
状態モデルを記述すると、Koder.aiがReact、Go、PostgreSQLのスキャフォールドを生成します。
状態は単なる「保存するデータ」ではなく、ユーザーのプロンプト、アップロード、設定、生成物、それらを結びつけるメタデータです。AI アプリではその状態が通常より機密性が高い(個人情報、専有ドキュメント、内部判断)ことが多く、各層でセキュリティを設計する必要があります。
秘密情報はサーバーに置く
クライアントがアプリを偽装できるようなものはサーバー専用にしてください:API キー、プライベートコネクタ(Slack/Drive/DB の資格情報)、内部システムプロンプトやルーティングロジックなど。フロントエンドは「このファイルを要約して」と要求できますが、どの資格情報でどう実行するかはバックエンドが決めるべきです。
すべての書き込み(と多くの読み取り)を認可する
各状態変異を特権操作として扱ってください。クライアントがメッセージを作る、会話名を変更する、ファイルを添付する際、バックエンドは検証すべきです:
- ユーザーが認証済みか。
- リソースの所有者か(会話、ワークスペース、プロジェクト)。
- その操作を実行する権限があるか(ロール、プラン制限、組織ポリシー)。
これにより conversation_id を推測して別のユーザーの履歴にアクセスする攻撃を防げます。
ブラウザを信用しない:検証とサニタイズ
クライアント提供の状態はすべて信頼できない入力として扱ってください。スキーマや制約(型、長さ、許可される列挙)を検証し、保存先(SQL/NoSQL、ログ、HTML レンダリング)に応じてサニタイズしてください。状態更新(設定やツールパラメータ)を受け付ける際は、任意の JSON をマージするのではなくホワイトリストで許可フィールドを限定してください。
重要な操作の監査ログ
恒久的な状態を変える操作(共有、エクスポート、削除、コネクタアクセス)については、誰がいつ何をしたかを記録してください。軽量な監査ログはインシデント対応、サポート、コンプライアンスに役立ちます。
データ最小化と暗号化
機能提供に必要なものだけを保存してください。プロンプト全文を永続化する必要がないなら、保持期間や抹消を検討しましょう。機密データ(トークン、コネクタ資格情報、アップロードされたドキュメント)は保存時に暗号化し、転送は TLS を使ってください。運用メタデータとコンテンツを分離して、アクセス制御をより厳密にできるようにすると良いです。
実用的な参照アーキテクチャと構築チェックリスト
実用的なデフォルトはシンプルです:バックエンドが真実の所在、フロントエンドは速い楽観キャッシュ。UI は即時に感じられますが、失ったら困るもの(メッセージ、ジョブ状態、ツール出力、課金に関わるイベント)はサーバー側で確認・保存してください。
「vibe-coding」ワークフロー(プロダクト表面が迅速に生成されるような状況)では、状態モデルの重要性はさらに高まります。Koder.ai のようなプラットフォームはチャットからウェブ/バックエンド/モバイルアプリを迅速に出せますが、同じルールが当てはまります:真実の所在、ID、ステータス遷移を先に設計するほど安全に素早く開発できます。
参考アーキテクチャ(実際に出荷できる構成)
フロントエンド(ブラウザ/モバイル)
- UI 状態:開いているパネル、下書きプロンプトテキスト、選択モデル、一時的な「入力中」指標。
- キャッシュされたサーバー状態:最近の会話、最後に知られているジョブ状態、部分ストリームバッファ。
- いつも添付する単一のリクエストパイプライン:
session_id,conversation_id, 新しいrequest_id。
バックエンド(API + ワーカー)
- API サービス:入力検証、レコード作成、ストリーミング応答の発行。
- 耐久ストア(SQL/NoSQL):会話、メッセージ、ツール呼び出し、ジョブステータス。
- キュー + ワーカー:長時間タスク(RAG インデックス、ファイル解析、画像生成)。
- キャッシュ(オプション):ホットリード(会話サマリー、埋め込みメタデータ)、常にバージョン/タイムスタンプでキー化。
注:一貫性を保つ実用的な方法はバックエンドスタックを早期に標準化することです。例として Koder.ai が生成するバックエンドは Go と PostgreSQL、フロントエンドは React を使うことが多く、権威ある状態を SQL に集中させつつクライアントキャッシュを破棄可能に保つのが容易になります。
先に状態モデルを設計する
画面を作る前に、各層で依存するフィールドを定義してください:
- ID と所有権:
user_id,org_id,conversation_id,message_id,request_id。 - タイムスタンプと順序:
created_at,updated_at、メッセージの明示的sequence。 - ステータスフィールド:
queued | running | streaming | succeeded | failed | canceled(ジョブとツール呼び出し用)。 - バージョニング:競合安全な更新のための
etagまたはversion。
これにより UI が「見た目は正しいがリトライ、リフレッシュ、同時編集を整合できない」という古典的バグを防げます。
API 形状を一貫させる
機能間でエンドポイントを予測可能に保ってください:
GET /conversations(一覧)GET /conversations/{id}(取得)POST /conversations(作成)POST /conversations/{id}/messages(追加)PATCH /jobs/{id}(ステータス更新)GET /streams/{request_id}またはPOST .../stream(ストリーム)
どこでも同じエンベロープスタイル(エラー含む)を返すと、フロントエンドは一様に状態を更新できます。
状態が壊れやすい箇所に可観測性を追加する
すべての AI 呼び出しに request_id を付けてログに残し、ツール呼び出しの入出力(マスク化して)やレイテンシ、リトライ、最終ステータスを記録してください。「モデルが何を見たか、どのツールが実行されたか、どの状態を永続化したか」を簡単に答えられることが重要です。
構築チェックリスト(よくある状態バグを避けるため)
- バックエンドが真実の所在;フロントエンドキャッシュは明確に破棄可能。
- すべての書き込みは冪等(再試行しても安全)で、
request_id(および/または Idempotency-Key)を使う。 - ステータス遷移は明示的かつ検証される(
queuedからsucceededへの勝手なジャンプなし)。 - ストリーミング更新は ID/シーケンスでマージし、「最後に来たもの」だけで上書きしない。
- 競合は
version/etagかサーバー側のマージルールで扱う。 - PII と秘密はクライアント状態に保存しない;ログはデフォルトでマスク。
- デバッグ用ダッシュボードが一つにまとまっている:リクエスト、ツール呼び出し、ジョブステータス、エラー。
高速なビルドサイクル(AI 支援のコード生成を含む)を採用する場合は、スキーマ検証、冪等性、イベントストリーミングなどチェックリスト項目を自動的に強制するガードレールを追加することを検討してください。そうすれば「早く動く」ことが状態のドリフトにつながりにくくなります。実務では、Koder.ai のようなエンドツーエンドプラットフォームが役立つ場面があり、配信スピードを上げつつ状態処理パターンを一貫させることができます。