2025年8月28日·1 分
インド向けEコマース検索のオートコンプリートと誤字許容
同義語、地域語、翻字、分析を活用して、インドのEコマース検索でのオートコンプリートと誤字許容を改善し、ゼロ結果を減らす方法を学びます。
なぜインドの製品名が検索を壊すのか
インドのEコマース検索がうまくいかない理由は単純です:人々は同じ物を同じように呼ばないからです。同じ商品でも英語、ヒンディー語、タミル語、あるいは混ざった表記で入力され、地域ごとに日常語が異なります。
買い物客は「atta」「aata」「gehu ka atta」やブランド名だけを検索するかもしれません。別の人は「jeera」「zeera」または単に「cumin」と打ちます。カタログにそのうちの一つしかなければ、ごく普通のクエリで何も返ってこないことがあります。
小さな綴りの違いが思ったより大きな影響を与えます。検索エンジンはクエリをほぼ文字通りに扱うことが多く、母音が一つ欠ける、余分なスペース、語順の違いなどが、正しい商品を上位から押し出したりゼロ結果にしてしまいます。
インドの製品名が多くのバージョンに分かれる主な理由:
- 複数の文字体系と翻字(ヒンディー語を英字で書く、地域による綴り違い)
- 同じ品目でも地域ごとの呼び方(食品、衣類、生活用品)
- ブランド名優先か一般名優先かの表記差(「Surf Excel 1kg」対「detergent powder」)
- 略語や口語表現(「kurti」対「kurta top」、「1 ltr」対「1L」)
- キーボードのタイプミスやオートコレクト(「pista」が「pita」になる、「saree」と「sarri」)
オートコンプリートと誤字許容は、買い物客の体験を変えます。オートコンプリートは検索が確定する前に、ストアが理解できる表現へ導いて入力の手間を減らします。誤字許容は「ほぼ正しい」クエリの失敗を防ぎ、綴りが完璧でなくても関連商品が表示されるようにします。
インドのEコマース検索におけるオートコンプリートと誤字許容の実際的な目標は「完璧な言語サポート」ではありません。測定可能な目標:ゼロ結果検索を減らし、商品発見を速めることで、買い物客が行き止まりではなく商品一覧にたどり着くことです。
平たんな言葉での要点
インドでの良い検索は派手なアルゴリズムより、実際に人々がどう商品名を入力するかを理解することに尽きます。多くの買い物客は英語と現地語を混ぜ、同じ物を三通りに綴り、検索がそれでも「分かってくれる」ことを期待します。
オートコンプリートは入力の途中で助ける部分です。誰かが「jeer…」と打っているときに「jeera rice」「jeera powder」「jeera whole」と提案できれば、手間を減らしカタログに存在する語へ優しく誘導できます。
誤字許容はユーザーがありそうなミスをしてもマッチさせる仕組みです。「zeera」対「jeera」や「shampo」対「shampoo」など。目的は意味を変えずに一般的な誤りを救うことです。誤字許容を広げすぎると短いクエリ「ram」が関係ない商品にヒットするなど変な一致が増えます。
同義語は単純です:違う言葉でも同じ意図。"Atta"と"wheat flour"は同じ商品群につながるべきです。インドのEコマースでは、同義語にブランドっぽい呼び方("biscuit"対"cookies")、地域用語、カテゴリのニックネームが含まれることが多いです。
翻字はインド語の単語を英字で入力することです。人によって"namkeen"、"nimeen"、"namkin"と打つことがあります。翻字ルールは、カタログが一つの綴りしか持っていなくてもこれらの変種をマッチさせる助けになります。
オートコンプリートと誤字許容を実務的に捉えると:
- オートコンプリートは有効で人気のあるクエリへユーザーを導く。
- 誤字許容はユーザーの綴りミスを救う。
- 同義語は異なる言葉を同じ購買意図に結び付ける。
- 翻字は異なる綴りを同じ現地語の用語に結び付ける。
これがわかれば、小さく制御されたマッピングセットを作り、実際の検索分析で拡張していけます。推測で作業するより確実です。
インド向け命名辞書の作り方(収集すべき入力)
良い検索辞書は推測ではなく自社データから始めます。目的は簡単:人々が実際にインドで商品をどのように呼ぶか(地域語、綴り、略語を含む)をキャプチャし、オートコンプリートと誤字許容の土台を作ることです。
まず、カタログを掘ります。商品タイトル、カテゴリ名、属性、バリアントラベル、ブランド、パックサイズ、単位には「公式」の表現が含まれていることが多いです。食料品なら "toor dal"、"arhar dal"、"split pigeon peas" のように具体名と一般名の両方があるかもしれません。
次に、実際の顧客語を集めます。検索ログは急いでいるときに人が何を打つかを示し、カスタマーサポートのチャットは探せないときにどう説明するかを見せます。数週間分のログでも "aata/atta"、"dahi/curd"、"chilli/chili" のような繰り返しパターンが浮かび上がります。
データソースは次の5つから作り、合併・クリーンします:
- カタログテキスト(タイトル、属性、バリアント、ブランド、サイズ)
- 検索クエリ(ゼロ結果クエリを含む)
- カスタマーサポートのチャットや通話メモ
- チームが既に使っている地域・現地用語
- 単位とバンドルの略記(ml、ltr、pcs、コンボ、1+1)
最後に、一般語とブランド語を分けます。"Atta"は多くの商品にマッチすべきですが、ブランド名が誤って別商品を引き寄せないようにします。後でルールが意図を曖昧にしないよう、ラベル付きの2つのリスト(一般語 vs ブランド)を保持してください。
手順:同義語と翻字の計画を作る
小さく始めます。検索と売上の中心となる20〜50カテゴリ(主食、ビューティー、人気家電など)を選び、作業を絞ります。影響が見えやすく、オートコンプリートと誤字許容の効果を早く確認できます。
チーム全員が編集できる共有の「命名テーブル」を作り、最初はスプレッドシートにしてから検索インデックスに同期します。
1) 正式表記(カノニカル)リストを作る
各カテゴリごとにシステムが“メイン”として扱う用語(カノニカル)を1つ選びます。仕入れ先の呼び方ではなく、顧客が認識する呼び方を使ってください。
次のような行を作ります:
| Canonical term | Synonyms (same product) | Common misspellings | Transliterations | Notes |
|---|---|---|---|---|
| cumin | jeera | jeera, jeeraa | zeera, zira | Keep “caraway” separate |
| face wash | cleanser | fash wash | fes wash | Don’t map to “face cream” |
単位やパックパターン(1kg、500 g、2x、コンボパック、family pack)は再利用可能なトークンとして別に扱います。ユーザーがフルで打つとゼロ結果を生みやすい部分です。
2) 「同じ商品」と見なす厳密なルールを設定
同義語は、顧客が同じ結果に満足する場合に限ります。チームが従える短いルールを書いてください:
- 許可:地域名の差、ブランド短縮形、一般的な綴り違い
- 許可:意味が同じならヒングリッシュ翻字
- 禁止:隣接する別商品(cleanser vs toner、cumin vs carom)
- 禁止:サイズの違いを同義語にすること(サイズはフィルター)
- 禁止:"healthy"や"premium"をベース商品と同義語にすること
3) 維持を簡単にする
カテゴリごとにオーナーを割り当て、最初は週次レビューを入れます。サポートが「見つからない」と言ったら、同じ日にテーブルに用語を追加するワークフローを作ります。
カスタム検索スタックに入れる場合、Koder.aiのようなツールは管理画面と同期ワークフローを素早く出すのに役立ちます。非技術チームが編集できる状態を保つことが重要です。
インドに合うオートコンプリート設計
オートコンプリートは速く、違和感なく、寛容であるべきです。インド向けEコマース検索で最大の利点は、最初の数文字で有用な候補を出せることです。人々は素早くタイプし、英語と現地語を切り替え、正確な綴りを覚えていないことが多いです。
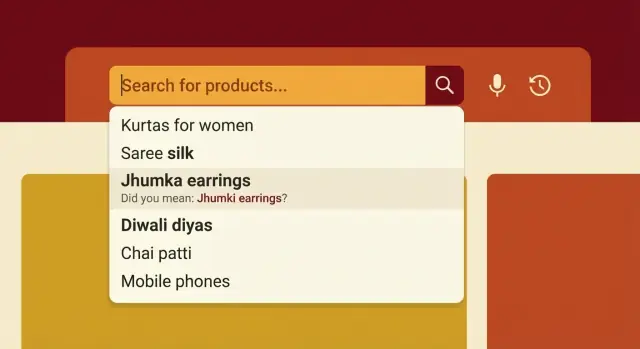
接頭辞(プレフィックス)に合わせてチューニングしましょう。最初の2〜4文字で高い意図を示す候補を出します。誰かが「sha」と打ったら、上位をレアな商品で埋めないでください。多くの買い物客が意味するであろう、かつ在庫が充実している候補を示します。
候補は単語だけでなくカテゴリを意識して出すと良いです。ユーザーが地域語の"shakkar"と入力したら、候補は明確に砂糖(sugar)カテゴリや人気のサブタイプ(粉、オーガニック等)を示すべきです。これにより混乱を減らせます。
候補は短く読みやすく保ちます。良いパターンは「ブランド + 商品」(本当に一般的な場合)か「商品 + 主要属性」です。サイズや長い型番、複数属性をいっぱい詰め込まないでください。
実務的なUIルール:
- 最大5〜8件の候補を表示し、上位3件はコンバージョンに最適化する。
- スペースや句読点を正規化して、"t-shirt"、"tshirt"、"t shirt"が同じ候補集合につながるようにする。
- 在庫があり有効な出品を優先する。
- 種類を混ぜる場合は慎重に:カテゴリ候補1〜2、次に商品、次にブランドの順にする。
- 売れないもの、廃番ブランドは候補に出さない。
例:買い物客が"dett"と入力すると、多くの人はブランド意図で"Dettol"を意味しますが、中には"handwash"や"sanitizer"を求めている場合もあります。オートコンプリートは"Dettol Handwash"、"Dettol Sanitizer"、カテゴリの"Handwash"を提示して両方の意図をカバーします。
このやり方を一貫して行えば、オートコンプリートと誤字許容は巧妙なアルゴリズムよりも、買い物客に次の自然な行動を示す手段になります。
乱れのない誤字許容の設定
自社ドメインで公開
社内ツールを自社ドメインで運用し、Eコマース運用に馴染ませます。
誤字許容はタイプミスがあっても人が商品を見つけられるようにしますが、緩すぎると"十分に近い"商品が誤って出てきてしまいます。目標は簡潔:明らかなミスを拾い、意図が変わりうる場合は慎重に扱うこと。
単語長に基づく安全な編集距離ルールから始めます。短い語は壊れやすいので厳しく。長い語はもう少し柔軟で良いです。
- 1〜4文字:0〜1編集まで許可(例:"atta" → "atta"、"atta" → "attta")
- 5〜8文字:最大2編集まで許可
- 9文字以上:最大3編集まで許可
- 複合語(複数語クエリ)は単語ごとに編集を適用するが、クエリ全体の合計編集数に上限を設ける
数字は別クラスとして扱います。"1kg"と"10kg"は交換不可で、"500ml"が"1500ml"になるべきではありません。実務ルール:数値トークン内部には誤字許容を適用しない、単位は変更しない。フォーマット調整("1 kg"、"1KG"、"1kg"など)は許容するに留める。
ブランド名や高意図語は"訂正"で汚さないでください。トップブランドやプライベートラベルなどの小さな保護リストを保持します。クエリが保護語に近い場合は、書き換えず候補を優先表示します。
モバイルではキーボード隣接ミスが多く、特にヒングリッシュで顕著です(例:a-s、i-o、n-mの近接キー)。ただし、その許容は語全体が強い一致を示す場合のみに限定します。
訂正が曖昧な場合は、静かに置き換えるのではなく候補として表示します。例:"dove"が"done"や"dovee"に分かれる可能性があるときは「Did you mean dove?」のように提案し、元の結果も残すことで信頼を保ちます。
翻字と現地語用語(実務ルール)
インドのクエリはしばしばスクリプトや習慣を混ぜます:"जीरा rice"、"jeera चावल"、"zeera rice"、"poha nashta"など。検索はこれらを別個の世界として扱うのではなく、同じ購買意図として扱うべきです。目標は簡単:複数の書き方を一つの明確な商品意味にマップすること。
小さく実践的なルールから始め、効果が見えてから拡張してください。
実務的な正規化ルール
- スクリプト混在を許容し、すべてを共有の"検索フォーム"に正規化してマッチさせる(解析用に元のクエリは保持)
- トップアイテムの翻字ペアだけをまず追加する(例:namkeen、bhujia、poha、jeera)。ユーザーが実際に打つ綴りを含める。
- 長母音の変種は重要な場合のみ明示的にペアを作る(poha vs pauha、jeera vs zeera)
- 音の入れ替え(v-w、b-v、j-z)は狭く慎重に適用:既知の商品トークンに限定し、クエリ全体に適用しない。
- ブランド名やSKUは基本的に入力どおりに保持し、不用意に書き換えない。
どの言語を先にサポートするか
野心ではなくトラフィックとゼロ結果を基準に選びます。一般的な順序は英語+ヒングリッシュを最初に、その後ヒンディー文字を追加する、という流れです。地域で需要が見えたら、そのログに基づいてカテゴリ単位で言語を追加してください。
アナリティクスループ:実際の挙動で検索を改善する
検索分析ダッシュボードを作る
検索ログを週次ダッシュボードに変えて、ゼロ結果・絞り込み・修正点を可視化します。
検索品質は一度きりの設定ではありません。週次の習慣として、人が何を打ち、何をクリックし、どこで諦めるかを見続けてください。これがインドのEコマース検索のオートコンプリートと誤字許容を推進する最良の方法です。
最初は少数のコア指標から始め、週ごとに一貫して追跡します:
- ゼロ結果率(全体と上位クエリ別)
- リファイン率(検索後に再入力やフィルタ追加が行われる割合)
- 検索後のカート追加(カートが雑音なら検索後のクリック)
- オートコンプリート利用率(候補クリック vs 手入力)
- 訂正の効果(誤字訂正されたクエリでクリックが増えたか)
週に一度、トップのゼロ結果クエリを引っ張り出して分類します。分類は簡単に保ち、チームが実際に使えるように:同義語不足(jeera vs zeera)、綴りの変種、ブランドやモデルのミスマッチ、言語/スクリプトの問題、カタログの欠落(商品未入荷)など。目的は「同義語が必要」か「在庫がない」かを分けることです。
オートコンプリートのデータはしばしば最も早い改善ポイントです。ユーザーが候補を無視して最後まで打ち切るなら、候補が一般的すぎる、順序が悪い、または地域用語が欠けている可能性があります。候補はクリックされているがユーザーが再検索するなら、見た目は正しいが結果が弱いことを示します。
誤字は単に許容を増やすのではなく監査を必要とします。毎週20〜50件の訂正クエリを抽出し、次のようにラベル付けします:
- Helpful(意図した商品に直った)
- Harmless(十分に近く、ユーザーは商品を見つけた)
- Harmful(別商品やカテゴリに誤って修正された)
これをプロダクトやマーケが2分で読める簡単なダッシュボードにまとめます:トップのゼロ結果クエリと原因、オートコンプリートの候補とクリック率、次リリースのための短いアクションリスト。Koder.aiのような内部ツールでダッシュボードと週次エクスポートを素早く作るのは良い初期プロジェクトです。
避けるべき一般的なミスと落とし穴
インドの検索問題の多くは「もっと同義語を増やす」ことではなく、予測可能なミスから生じます。これらが徐々にユーザーを間違った結果へ導き、信頼を損ないます。
最大の落とし穴の一つは過度に広い同義語です。"cream"と"lotion"を互換にすると、濃厚なフェイスクリームを求める人が軽いボディローションに誘導され、離脱につながります。同義語は隣接カテゴリではなく、同じ意図の変種だけをマップするようにしてください。
もう一つのミスはパックサイズや単位の意図を無視することです。"Oil 1L"と"Oil 5L"は買い物目的が違いますし、"atta 5 kg"と"atta 10 kg"も同様です。ルールが単位を無視すると、まとめ買いしたい人に小袋を提示してしまい、ランキングがランダムに見えます。
注意すべき高インパクトなミス:
- 近い商品を同義語にしてしまう(cream vs lotion、shampoo vs conditioner)
- サイズ、個数、単位ワードを無視する(1L、5L、500 ml、10 pcs)
- 誤字許容でブランド名を別ブランドに直してしまう
- 指定ピンコードで在庫がない候補をオートコンプリートで表示する
- ルールを設定して放置する(特にプロモや季節要因後)
ブランド名は特に注意が必要です。ユーザーが"Himalya face wash"と入力したのに誤字設定で別ブランドに修正されると不満が出ます。一般語("shampu")には寛容に、ブランドや型番には厳格に、という方針が安全です。
オートコンプリートは在庫のないものを提案すると逆効果になります。頻出クエリだからといって"ghee 2L"を提案して在庫が1Lしかないと期待外れになります。今日確実に提供できる候補を優先してください。
オートコンプリートと誤字許容を作るなら、販売週の後に新しいトップクエリ、増えた誤綴り、ゼロ結果をチェックする習慣を入れてください。結婚シーズン、モンスーン、試験シーズンといった小さなシフトでも人々の入力が変わります。
ルール変更を素早くテストしたければ、Koder.aiは検索ルールサービスと管理画面のプロトタイプを手早く作るのに役立ちます。
現実的な例:「jeera rice」と「zeera rice」の修正
買い物客が"zeera rice"と入力してゼロ結果になることがあります。探しているのは別の商品ではなく、発音どおりに綴っただけで"jeera rice"(クミンライス)を意味しています。
これを直すには2つの小さく安全な変更で十分です:一般的な綴りバリエーションの同義語と保守的な誤字ルールを追加します。この場合、"zeera"を"jeera"の翻字バリアントとして扱います。
実用的なマッピング例:
- クエリ同義語:zeera -> jeera
- クエリ同義語:zira -> jeera
- カタログ上の製品名はそのままにしておく(SKUを改名しない)
次に短い語に厳格な誤字許容ルールを追加します。例えば、トークン長が5文字以上のときにのみ1編集(1文字の誤り、欠落、入れ替え)を許可する、など。これで"jeera"対"jeeraa"のようなケースは拾えますが、非常に短い語の乱れによる変な一致は避けられます。
変更後、オートコンプリートは推測するのではなく買い物客を導くはずです。ユーザーが"zee…"と入力したときは次のような候補を出します:
- "jeera rice"
- "jeera basmati rice"
- "jeera (cumin)"
ユーザーが"zeera rice"を送信したときは、あなたの"jeera rice"商品を上位に表示し、ランキングルールによってはクミンやバスマティなど関連商品も表示します。
1週間後にチェックする指標例:
- "zeera"、"zira"、"jeera"のゼロ結果率
- 検索の再入力率(ユーザーは再入力したか)
- 検索後のカート追加率
- 同義語が関連ない商品を引っ張っていないかを確認するためのトップクリック
もし結果が悪化したら(例:"zira"が別のブランドやカテゴリに一致し始める)、その同義語グループだけを無効化して早急にロールバックします。設定はバージョン管理しておき、数分で戻せるようにしてください。こうしたフィードバックループがインド向けのオートコンプリートと誤字許容で重要です。
変更を出す前のクイックチェックリスト
同義語マネージャーを導入
マーチ、コンテンツ、サポートが編集できる同義語・翻字の管理画面を作成します。
新しい同義語、オートコンプリート、誤字設定を公開する前に、実際のクエリデータを混ぜた簡単な確認を行ってください。これで「役に立つ」変更がノイズの多い結果を作るのを防げます。
オートコンプリートと誤字許容向けの短い事前チェックリスト:
- 過去7〜14日のトップ50検索クエリを引っ張り、意図別にグループ化する(ブランド、一般商品、サイズや色のバリアント、問題解決型のクエリ)。意味が二つあり得るクエリは両方記録する。
- トップ50のゼロ結果クエリを抽出し、それぞれに対する修正を決める:既存カテゴリにマップ、同義語を追加(地域語や綴り)、欠品商品の追加、あるいは無関係ならブロックする。放置しない。
- 同義語と翻字リストにオーナー、最終更新日、短い理由を追加する。これでバラバラの編集を防げる。
- トップカテゴリで実際のユーザー表現を使ってオートコンプリートをテスト:英語、ヒングリッシュ、略語を試し、候補がニッチ商品に偏らず人気バリエーション(1kg、500g、pack of 2など)を含むか確認する。
- ブランドの誤綴り、複合数字("iPhone 15 pro 256")、似た単語("jeera/zeera"、"besan/besan flour")など20の厄介なクエリで誤字許容をストレステストし、上位結果が正しいか確認する。
失敗があれば小さな変更を先に出してください。広範囲の更新よりも段階的なリリースの方が安全です。
次のステップ:シンプルなローアウト計画(速く作る方法)
検索の問題が顕著なカテゴリ1つ(食料品、パーソナルケア、モバイルアクセサリなど)から始めます。1週間程度で影響を見られるようにスコープを狭くします。動かせる成功指標は2〜3つに絞る(ゼロ結果率、検索→商品クリック率、検索後のカート追加など)。
効果的なシンプルなローアウト例:
- Day 1: ベースラインを取得(現在の指標、トップクエリ、トップのゼロ結果クエリ)
- Days 2–3: 小さな辞書を導入(トップ50クエリの同義語とヒングリッシュ翻字、上位20のブランド/サイズパターン)
- Day 4: ガードレールを追加(意味が変わる所は除外する例:"atta"がカタログのコード"ATA"と混同しないように)
- Days 5–6: 監視(ゼロ結果が減ったか、無関係クリックが増えないかを確認)
- Day 7: 継続、調整、もしくはロールバックを決定し、次のバッチを計画する
変更は必ず戻せるようにします。同義語や誤字ルールをコードとしてバージョン管理し、スナップショットやロールバック経路を用意してください。もし新ルールで"face wash"が"dishwash liquid"を出すような事態が起きたら、数分で元に戻せることが重要です。
オーナーシップは巧妙なルールより重要です。週に30分のレビュー時間を1人に任せ、トップの新しいゼロ結果、誤字で救われた良い事例、低品質クリックのスパイクをチェックしてもらいましょう。
より早く構築・反復したければ、Koder.aiはチャットでのビルド、プランニングモードでルールと指標をマップ、エクスポート可能なソースコードを提供するのでチームで保守しやすくなります。スナップショットやロールバック機能があると、素早い元に戻しが必要な時に便利です。
測定結果に基づき次の改訂を計画してください。例えば"zeera rice"はコンバージョンが上がったが"jeera"が無関係な"zera"商品にマッチするようになった場合、次のアクションはそのルールを厳しくすることです。