2025年7月21日·2 分
インシデント影響分析のためのWebアプリをステップバイステップで作る
サービス依存、リアルタイム信号、分かりやすいダッシュボードを使ってインシデントの影響を計算するウェブアプリの設計と構築方法を学びます。
サービス依存、リアルタイム信号、分かりやすいダッシュボードを使ってインシデントの影響を計算するウェブアプリの設計と構築方法を学びます。
計算やダッシュボードを作る前に、組織で「影響」が何を意味するかを決めてください。このステップを飛ばすと、見た目は科学的でも誰の行動にも結びつかないスコアが出来上がります。
影響は、インシデントがビジネスの重要事項に与える測定可能な結果です。一般的な次元には:
主要な次元を2〜4個選び、明確に定義してください。例えば:「Impact = 影響を受けた有料顧客数 + リスクにさらされたSLA分数」だと具体的です。「グラフが悪く見えるもの=影響」としないでください。
役割によって意思決定が異なります:
各観客が指標を翻訳せずに自分の重要な質問に答えられるように「影響」の出力を設計してください。
許容される遅延を決めてください。「リアルタイム」は高コストで不要な場合が多く、**近リアルタイム(例:1〜5分)**で意思決定に十分なことが多いです。
これをプロダクト要件として書き残してください。取り込み方法、キャッシュ、UIに影響します。
MVPは次のようなアクションを直接支援すべきです:
ある指標が意思決定に影響しないなら、それは「影響」ではなく単なるテレメトリです。
画面設計やDB選定の前に、インシデント発生時に「影響分析」が答えるべきことを書き出してください。目標は初日からの完璧な精度ではなく、レスポンダーが信頼できる一貫性と説明可能な結果です。
影響を算出するために取り込む/参照すべきデータをまず決めます:
多くのチームは初日で完璧な依存関係や顧客マッピングを持っていません。データが欠けている場合に手動入力を許すか決めてください:
これらはアドホックなメモではなく、検索可能な明示的フィールドとして設計してください。
最初のリリースは次を確実に出せるべきです:
影響分析は意思決定ツールなので制約が重要です:
これらをテスト可能な文として書き出してください。検証できなければ、障害時に頼れません。
データモデルは取り込み、計算、UIの契約です。正しく作ればツールを入れ替えても同じ質問に答えられます:「何が壊れた?」「誰が影響を受けた?」「どれくらいの期間?」
最低限、次をファーストクラスのレコードとしてモデル化してください:
IDは安定して一貫性を保ってください。既にサービスカタログがあるならそれを真実の源(source of truth)として扱い、外部ツールの識別子をマッピングしてください。
インシデントに複数のタイムスタンプを保存してレポートや分析を支援します:
また影響スコアリング用の計算済み時間窓(例:5分バケット)も保存してください。これによりリプレイや比較が簡単になります。
二つのグラフをモデル化します:
単純なパターンとして customer_service_usage(customer_id, service_id, weight, last_seen_at) のようなテーブルを作り、顧客がどれだけそのサービスに依存しているかでランク付けできるようにします。
依存関係は進化します。計算は当時の状況を反映すべきです。エッジに有効期間を持たせてください:
dependency(valid_from, valid_to)顧客契約や利用スナップショットも同様にバージョン管理してください。履歴を持てば過去のインシデントを正確に再実行し、SLA報告を一貫して出せます。
影響分析は入力次第です。ここでの目標は、既に使っているツールから信号を引き出し、それらをアプリが扱える一貫したイベントストリームに変換することです。
インシデント時に「何かが変わった」ことを確実に示すソースから始めてください:
一度にすべてを取り込もうとしないでください。検知・エスカレーション・確認をカバーするソースを選びます。
ツールによって統合パターンが異なります:
実践的には、重要信号はWebhook、ギャップ埋めはバッチインポートという組み合わせが良いです。
ソースがalert、incident、annotationと呼んでいても、すべてを単一の「event」形状に正規化してください。最低限標準化する項目:
データは汚れている前提で設計してください。冪等性キー(source + external_id)で重複を除き、到着順ではなく occurred_at によるソートで順序の乱れを許容し、欠落するフィールドには安全なデフォルトを適用しつつレビューを促すフラグを立てます。
UIに小さな「未マッチサービス」キューを置くと、黙ったままのエラーを防ぎ影響結果の信頼性が上がります。
依存関係マップが間違っていれば、信号とスコアリングが完璧でもブラスト半径は誤ります。目標は、インシデント中にも後続分析でも信頼できる依存グラフを作ることです。
エッジをマップする前にノードを定義してください。インシデントで参照する可能性のあるすべてのシステムについてサービスカタログのエントリを作成します:API、バッチワーカー、データストア、サードパーティベンダー、共有の重要コンポーネントなど。
各サービスには最低限、所有者/チーム、ティア/重要度(顧客向けか内部か)、SLA/SLO目標、ランブックやオンコールドキュメントへのリンク(例:/runbooks/payments-timeouts)を含めます。
二つの補完的ソースを使います:
これらを別々のエッジタイプとして扱い、信頼度が理解できるようにします(例:「チームが宣言」/「過去7日間に観測」)。
依存は有向でなければなりません:Checkout → Payments と Payments → Checkout は異なります。方向性により「Paymentsが劣化したらどの上流が失敗するか?」といった推論が可能になります。
また ハード依存 vs ソフト依存 をモデル化してください:
この区別は影響を過大評価するのを防ぎ、優先順位付けを助けます。
アーキテクチャは週単位で変わります。スナップショットを保存していなければ2ヶ月前のインシデントを正確に分析できません。
依存グラフのバージョンを時系列で保存(毎日、デプロイごと、変更時)し、ブラスト半径計算時にはインシデント時刻に最も近いグラフスナップショットを参照してください。そうすれば「誰が影響を受けたか」は当時の現実を反映します。
信号(アラート、SLO消費、合成チェック、顧客チケット)を取り込んだら、アプリは雑多な入力を一貫した表現に変換する必要があります:何が壊れたか、どれほど悪いか、誰が影響を受けているか?
MVPは次のいずれかで十分です:
どの方法でも中間値(閾値到達、重み、ティア)を保存して、なぜスコアが出たか説明できるようにしてください。
早い段階で全てを1つの数値に潰しすぎないでください。いくつかの次元を別々に追跡し、そこから総合深刻度を導出します:
これにより「利用可能だが遅い」対「誤った結果を返す」といった正確なコミュニケーションが可能になります。
影響はサービスの健康だけでなく、それを受けた人です。
利用マッピング(テナント→サービス、顧客プラン→機能、ユーザートラフィック→エンドポイント)を用いて、インシデントに合わせた時間窓内で影響顧客を算出してください(開始時刻、軽減時刻、バックフィル期間など)。
サンプリングログや推定トラフィック、部分的なテレメトリなどの前提を明示してください。
オペレーターは誤検知、段階的ロールアウト、一部テナントのみの影響などを手動で修正する必要があります。
手動での深刻度、次元、影響顧客の編集を許可する場合は次を必須にしてください:
この監査トレイルによりダッシュボードの信頼性が守られ、事後レビューが速くなります。
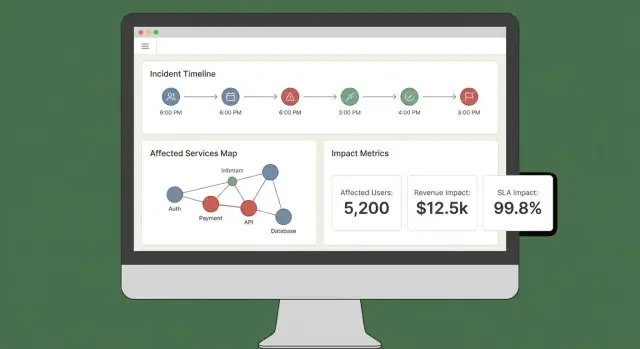
良い影響ダッシュボードは素早く3つの質問に答えます:何が影響を受けているか? 誰が影響を受けているか? どれくらい確信があるか? これらを得るのに5つのタブを開かなければならないようでは、ユーザーは出力を信用しません。
少数の「常にある」ビューから始めて、実際のインシデントワークフローに対応させます:
説明のないスコアは恣意的に感じられます。すべてのスコアは入力とルールに遡れるべきです:
「Explain impact」パネルやドロワーを用意すれば、メインビューを散らかさずに説明が可能です。
サービス、リージョン、顧客ティア、時間範囲で簡単にスライスできるようにしてください。チャートの任意の点や行をクリックして、変更を引き起こした生データ(モニタ、ログ、イベント)にドリルダウンできるようにします。
アクティブなインシデント中はポータブルな更新が必要です。次を含めてください:
既にステータスページがあるなら /status のような相対ルートでリンクすると広報チームがすばやく参照できます。
人々がアプリを信頼するには、誰が何を見られるか/変更できるかを管理し、変更の記録を残す必要があります。
実際のインシデント運用に合わせた小さな役割セットを定義します:
権限は職位ではなくアクションに合わせて割り当ててください。例えば「顧客影響レポートをエクスポートできる」はコマンダーと一部の管理者に付与する権限です。
インシデント影響分析は顧客識別子、契約ティア、連絡先を扱うことがあるため、デフォルトで最小権限を適用してください:
次の操作を十分な文脈で記録してください:
監査ログは追記専用で、タイムスタンプと実行者識別を付け、インシデントごとに検索可能にしてください。
今サポートできること(保持期間、アクセス制御、暗号化、監査範囲)とロードマップ上の事項を文書化してください。
アプリ内に短い「Security & Audit」ページ(例:/security)を用意すると、インシデント中に訊かれる雑多な質問が減ります。
影響分析はインシデント中に次のアクションを促す必要があります。アプリはインシデントチャネルの“コパイロット”のように振る舞い、着信信号を明確な更新に変え、重要な変化があれば人を促します。
レスポンダーが既に作業しているチャネル(Slack、Microsoft Teams、専用ツール)と統合を始めてください。目的はチャネルを置き換えることではなく、文脈に応じた更新を投稿し共有記録を保つことです。
実用的なパターンはチャネルを入力と出力の両方として扱うことです:
プロトタイプを早く回すなら、まずは一連のワークフロー(インシデントビュー → 要約 → 通知)を端から端まで組んでみてからスコアを洗練するのが良いです。Koder.ai のようなプラットフォームは、ReactダッシュボードとGo/PostgreSQLバックエンドをチャット駆動で素早く試作し、チームがUXを確認したらソースコードをエクスポートできます。
影響が明確な閾値を越えたときだけ通知を出し、アラートスパムを避けてください。一般的なトリガー:
閾値を越えたら「何が変わったか」「誰が行動すべきか」「次に何をすべきか」を説明するメッセージを送ってください。
すべての通知に「次のステップ」リンクを含めて、レスポンダーが素早く動けるように:
これらは相対リンクにして安定させ、環境間で動くようにしてください。
同じデータから二つのサマリ形式を作ってください:
定期サマリ(例:15〜30分ごと)と、外部発信前に承認ステップを挟む「生成」アクションの両方をサポートしてください。
影響分析はインシデント時と事後の両方で信頼される必要があります。検証は二つを証明するべきです:(1) システムは安定で説明可能な結果を出す、(2) その結果は後の合意(事後レビュー)と合致する。
最初はスコアリングロジックとデータ取り込みの二点に対する自動テストを用意してください:
テストフィクスチャは読みやすく保ち、誰かがルールを変更した時にスコア変化の理由がわかるようにしてください。
リプレイモードは信頼獲得への近道です。過去のインシデントをアプリで再生し、「当時の段階でシステムがどう表示したか」を実際の結論と比較してください。
実用的なヒント:
実際のインシデントはきれいな障害ばかりではありません。検証スイートに次のシナリオを含めてください:
各ケースでスコアだけでなく、どの信号と依存関係/顧客が結果を引き起こしたかという説明をアサートしてください。
精度を運用的に定義し、追跡してください。計算された影響を事後レビューの結果(影響サービス、期間、顧客数、SLA違反、深刻度)と比較し、差分を検証課題(カテゴリ:データ欠落、依存関係誤り、閾値不適切、信号遅延)として記録します。
時間が経つにつれ目標は「完璧」ではなく、「驚きが減り、インシデント時の合意が速くなる」ことです。
インシデント影響分析のMVPを出すには信頼性とフィードバックループが重要です。最初のデプロイ選択は将来の理論的スケールよりも変化の速さを優先してください。
明確なプラットフォームチームやサービス境界が無いなら**モジュラー単一体(modular monolith)**で始めるのが現実的です。一つのデプロイ単位は移行、デバッグ、エンドツーエンドテストを簡素化します。
サービス分割は次のような実際の痛みが出てから:
実用的な折衷案は 一つのアプリ + バックグラウンドワーカー(キュー) + 必要なら別の取り込みエッジ です。
素早く進めたいなら Koder.ai のようなツールでプロトタイプを加速するのも選択肢です。チャット駆動のワークフローでReact UI、Go API、PostgreSQLデータモデルを素早く作り、スコアリングやワークフローを反復できます。
コアエンティティ(インシデント、サービス、顧客、所有権、計算スナップショット)には**リレーショナルストレージ(Postgres/MySQL)**を使ってください。クエリしやすく、監査や拡張が容易です。
高頻度の信号(メトリクス、ログ起点イベント)は生データ保持やロールアップがSQLで高コストになったら時系列ストア/カラムナストアを追加します。
依存クエリがボトルネックになったり依存モデルが非常に動的にならない限り、グラフDBは後回しで問題ありません。多くのチームは隣接リストテーブルとキャッシュで十分です。
影響分析アプリもツールチェーンの一部です。次を計測・公開してください:
UIに「ヘルス + 鮮度」ビューを用意すると、レスポンダーが数字を信頼するか疑うかの判断に役立ちます。
MVP範囲は狭く定めてください:少数の取り込みツール、明確な影響スコア、誰がどれだけ影響を受けたかを答えるダッシュボード。その後で反復します:
モデルをプロダクトとして扱い、バージョン管理し、安全にマイグレーションし、事後レビューのために変更を文書化してください。
影響(Impact)は、インシデントがビジネスにとって重要な成果に与える測定可能な結果です。
実用的な定義としては、2〜4の主要な次元(例:影響を受けた有料顧客数+リスクにさらされたSLA分数)を明示し、「グラフが悪く見えるものすべて」を除外します。これにより出力は単なるテレメトリではなく意思決定に結びつきます。
最初の10分でチームが取るべきアクションに結びつく次元を選んでください。
MVPで扱いやすい代表的な次元:
説明可能性を保つため、2〜4個に絞ることを推奨します。
各役割がトップの質問に訳さず答えられるように出力を設計してください:
これらのいずれにも使えない指標は、おそらく「影響」ではなく単なるテレメトリです。
「リアルタイム」はコストが高く、多くのチームでは**近リアルタイム(例:1〜5分)**で十分なことが多いです。
遅延目標は要件として明記してください。これが採取方法(webhook vs ポーリング)、キャッシュ戦略、UIの期待値に影響します。
またUI上で「データ更新は2分前」といった形で現状の鮮度を示すことも有効です。
MVPはレスポンダーが下す決定を直接支援するべきです。まずは必要な意思決定を列挙し、それぞれに対応する出力を用意してください:
もしある指標が決定を変えないなら、それは「影響」ではなく単なるテレメトリです。
通常、影響を算出するために最低限必要な入力は次のとおりです:
データが欠落したり信号が不正確な場合でもアプリが有用であるように、明示的でクエリ可能な手動入力項目を許容してください:
変更には必ず「誰が/いつ/なぜ」を記録して、信頼性を保ってください。
信頼できるMVPは次を生成すべきです:
オプションで価値が高いのは、信頼区間付きの(SLAクレジット、サポート負荷、収益リスク)です。
すべてのソースを一つのイベントスキーマに正規化し、計算が一貫するようにしてください。最低限標準化する項目:
occurred_at、detected_at、resolved_atservice_id(ツールのタグ/名前からマッピング)まずは説明可能で簡潔な方法から始めましょう:
中間値(閾値到達、重み、ティア、信頼度)を保存して、スコアの理由を確認できるようにしてください。また、可用性/レイテンシ/エラー/データ正確性/セキュリティなどの次元を別々に追跡した上で総合値を導出するのが良いです。
このセットがあれば「何が壊れたか」「誰が影響を受けたか」「どれくらいの期間か」を算出できます。
source混乱を扱うために、冪等性キー(source + external_id)で重複除去し、occurred_atに基づく順序づけで到着順の乱れを許容してください。