2025年5月21日·2 分
クライアント別SLAを集中して報告するWebアプリを作る
複数クライアントのSLAデータを収集・正規化し、ダッシュボード、アラート、エクスポート可能なレポートを提供するマルチクライアントWebアプリの計画、構築、ローンチ方法を解説します。
複数クライアントのSLAデータを収集・正規化し、ダッシュボード、アラート、エクスポート可能なレポートを提供するマルチクライアントWebアプリの計画、構築、ローンチ方法を解説します。
SLAの証拠はめったに一箇所にまとまっていません。稼働率は監視ツール、インシデントはステータスページ、チケットはヘルプデスク、エスカレーションのメモはメールやチャットにあることが多いです。各クライアントがわずかに異なるスタックや命名規則を使っていると、月次レポートが手作業のスプレッドシート業務になり、「実際に何が起きたか」の解釈で争いが起きやすくなります。
良いSLAレポーティングWebアプリは、目的の異なる複数の利用者をサポートします:
アプリは、役割に応じて同じ根本的な“真実”を異なる詳細度で提示するべきです。
中央集約SLAダッシュボードは次を提供します:
現場では、すべてのSLA数値がタイムスタンプと所有者を持つ生イベント(アラート、チケット、インシデントのタイムライン)に遡れることが理想です。
構築前に、範囲内と範囲外を定義してください。例:
明確な境界は後の議論を防ぎ、クライアント間で一貫した報告を維持します。
最小限として、集中SLAレポーティングは以下の5つのワークフローをサポートする必要があります:
初日からこれらのワークフローを中心に設計すれば、データモデル、統合、UXは実際の報告ニーズに合致します。
画面やパイプラインを作る前に、アプリが何を測定し、その数値をどう解釈するかを決めます。目的は一貫性です:同じレポートを見た二人が同じ結論に達すること。
大多数のクライアントが認識する小さなセットから始めます:
それぞれの指標が何を測るか、何を除外するかを明確にしてください。UIに短い定義パネルを置き、/help/sla-definitions へのリンクを設けると誤解を防げます。
SLAレポーティングが崩れるのはルールの不明確さが原因になることが多いです。クライアントが検証できる文で文書化し、それをロジックに翻訳してください。
カバーすべき要点:
デフォルトの期間(一般的には月次/四半期)を選び、カスタム範囲をサポートするかを決めます。カットオフに使うタイムゾーンを明確にしてください。
違反については:
各指標について、必要な入力(監視イベント、インシデント記録、チケットのタイムスタンプ、メンテナンスウィンドウ)をリスト化します。これが統合とデータ品質チェックの設計図になります。
ダッシュボードやKPIを設計する前に、SLAの証拠がどこにあるかを明確にします。多くのチームは“SLAデータ”が複数のツールに分散し、所有者が異なり、記録の意味も微妙に違うことに気づきます。
クライアント(およびサービス)ごとにシンプルなリストを作ります:
各システムについて、所有者、保持期間、API制限、時間分解能(秒単位か分単位か)、データがクライアント単位か共有かを記録します。
多くのSLAレポートアプリは組み合わせを使います:
実用的なルール:フレッシュネスが重要な場所はWebhooks、完全性が重要な場所はAPIプルを使う。
ツールごとに同じ事象の表現が異なります。アプリが依存できる小さなイベントセットに正規化します。例:
incident_opened / incident_closeddowntime_started / downtime_endedticket_created / first_response / resolved一貫したフィールドを含めてください:client_id、service_id、source_system、external_id、severity、タイムスタンプ。
すべてのタイムスタンプはUTCで保存し、表示時にクライアントの希望するタイムゾーンに変換してください(特に月次のカットオフで重要)。
ギャップも想定して設計しましょう:一部のクライアントはステータスページを持たない、あるサービスは24/7で監視されていない、ツールがイベントを失うことがある。レポート上で「監視データが3時間利用不可」などの部分的カバレッジを表示して、結果が誤解を招かないようにします。
複数顧客のSLAを報告する場合、アーキテクチャの判断がスケールとデータリーク防止を左右します。
まず必要なレイヤー名を決めます。"クライアント"は次のような意味を持ち得ます:
これらは権限、フィルター、設定の保存方法に影響するので早めに定義してください。
多くのSLAアプリは次のどれかを選びます:
tenant_id を付与。コスト効率が良く運用が簡単だが、厳格なクエリ規律が必要。妥協案として、大多数のテナントは共有DBで運用し、大口(エンタープライズ)向けに専用DBを提供することが多いです。
隔離は次の領域で守られなければなりません:
tenant_id を保持して結果を別テナントへ書き込まないこと行レベルセキュリティ、必須クエリスコープ、自動化されたテストなどをガードレールとして使ってください。
クライアントごとに目標や定義が異なるため、次のような設定をテナント単位で持てるようにします:
内部ユーザーはクライアントのビューを“なりすまし”で見る必要があることが多いです。自由なフィルターでなく明示的な切替を実装し、アクティブなテナントを目立つように表示、切替ログを残し、テナントチェックを回避するリンクを防いでください。
中央集約型SLAレポートはデータモデルが肝です。「月次SLA%だけ」をモデル化すると説明や争い対応が難しく、「生イベントだけ」だと報告が遅く高コストになります。目標は両方をサポートすること:トレース可能な生の証拠と、高速なロールアップ。
「誰が」「何を」「どう計算したか」を分離して保ちます:
次のようなテーブル(またはコレクション)を設計します:
service_down started_at/ended_at)SLAロジックは変わります(営業時間更新、除外の明確化、丸めルールの変更)。計算ごとに calculation_version(と可能ならルールセット参照)を付け、ルール改定後でも過去のレポートを再現できるようにします。
重要な箇所に監査フィールドを入れます:
クライアントは「なぜそうなったか」をよく尋ねます。次を計画してください:
この構造により、アプリは説明可能で再現性がありつつ高速に動作します。
入力が乱雑だとダッシュボードも信頼できません。信頼できるパイプラインは複数ツールからのインシデント/チケットデータを一貫して監査可能なSLA結果に変換し、重複、ギャップ、黙認された失敗を防ぎます。
取り込み、正規化、ロールアップを別段階として扱い、バックグラウンドジョブで動かしてUIを高速に保ち、リトライ可能にします。
この分離により、あるクライアントのソースが落ちても既存計算が壊れにくくなります。
外部APIはタイムアウトし、Webhookは二重配信されます。パイプラインは冪等であるべきです:同じ入力を複数回処理しても結果が変わらないこと。
一般的手法:
クライアントやツール間で「P1」「Critical」「Urgent」が同じ意味とは限りません。正規化レイヤーで次を統一します:
トレースのために元の値と正規化値の両方を保存してください。
検証ルール(タイムスタンプ欠損、負の期間、不可能なステータス遷移)を追加し、問題あるデータは黙って破棄せず隔離キューへ送り理由と「修正/マップ」ワークフローを用意します。
クライアントとソースごとに「最終正常同期」「未処理で最も古いイベント」「ロールアップが最新である時点」を計算し、データ鮮度指標として表示してください。これによりクライアントは数字を信頼でき、チームは問題を早く発見できます。
クライアントがポータルでSLAを確認する場合、認証と許可はSLA算出と同等に慎重に設計する必要があります。目標は単純:各ユーザーは見てよいものだけを見られ、後で証明できること。
最初はシンプルな役割セットから始め、必要になったら拡張します:
最小権限をデフォルトにし、新規アカウントは明示的に昇格されない限り viewer に配置します。
内部チームにはSSOを推奨してアカウントスプロールとオフボーディングリスクを低減します。OIDC(Google Workspace/Azure AD/Okta)をサポートし、必要ならSAMLも。クライアント向けにはSSOをアップグレードパスとして提供し、小規模組織向けにはメール/パスワード+MFAも許容します。
すべてのレイヤーでテナント境界を強制します:
誰がいつどのページを見たか、どのデータをダウンロードしたかをログに残します。これがコンプライアンスとクライアント信頼につながります。
オンボーディングフローでは管理者かクライアント編集者がユーザーを招待し、役割を設定し、メール確認を必須にし、退出時に即座にアクセス撤回できるようにします。
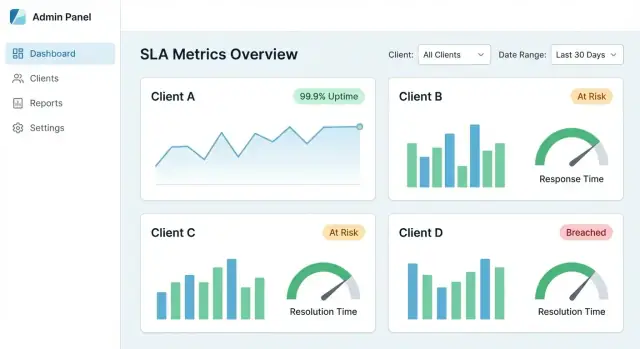
集中SLAダッシュボードが成功する条件は、クライアントが1分以内に次の3つに答えられること:SLAを満たしているか? 何が変わったか? ミスの原因は何か? UXは高レベルから証拠まで自然に導くべきで、内部データモデルの学習を強要してはいけません。
会話に合致する少数のタイルとチャートから始めます:
各カードはクリック可能にして、詳細への入り口にしてください。
フィルターは全ページで一貫し、ナビゲーション間で“保持”されるべきです。
推奨デフォルト:
上部にアクティブなフィルターチップを表示して、現在のビューが何か常に分かるようにします。
すべての指標には「なぜ?」への経路を用意します。良いドリルダウンの流れ:
説明できない数値は疑問視されます。特にQBRでは事実を裏付ける証拠が必要です。
各KPIにツールチップや情報パネルを付けて、計算方法、除外、タイムゾーン、データ鮮度を説明してください。例:「メンテナンスウィンドウを除外」「稼働率はAPIゲートウェイで計測」といった注釈を付けます。
フィルタリング結果を安定したURLで共有できるようにします(例:/reports/sla?client=acme&service=api&range=30d)。これにより中央集約ダッシュボードがクライアント向けレポーティングポータルになり、定期的なチェックや監査の基盤になります。
ダッシュボードは日常的に有用ですが、クライアントは転送可能なものを求めます:経営陣向けのPDF、アナリスト向けのCSV、ブックマークできるリンクなど。
同じSLA結果から3種類の出力をサポートします:
リンクベースのレポートではフィルター(期間、サービス、重大度)を明示しておき、数値の意味が分かるようにします。
各クライアントが週次/月次/四半期で自動的にレポートを受け取れるようスケジュール機能を追加します。配信先はクライアント固有のリストまたは共有受信箱にし、スケジュールはテナント単位で監査可能(作成者、最終送信、次回実行)にします。
シンプルに始めるなら、/reports からの「月次サマリー+ワンクリックダウンロード」を提供してください。
QBR/MBRのスライドに読めるテンプレートを用意します:
現実のSLAには例外(メンテナンス、サードパーティ障害)が含まれます。コンプライアンス注記を添付し、承認を要する例外は承認トレイルを残せるようにします。
エクスポートはテナント隔離とロール権限を尊重する必要があります。ユーザーは見えるクライアント・サービス・期間だけをエクスポートでき、ポータルのビューと完全に一致する(隠れた列でデータを漏らさない)ことを保証してください。
アラートはダッシュボードを単なる"面白い"ツールから実運用ツールに変えます。目的はメッセージを増やすことではなく、適切な人が早期に反応し、何が起きたかを記録し、クライアントに説明できることです。
まずは3カテゴリで始めます:
各アラートは明確な定義(指標、時間窓、しきい値、クライアントスコープ)に紐づけてください。
複数の配信方法を用意して既存のワークフローに合わせます:
マルチクライアント運用ではテナントルールでルーティングします(例:「Client A の違反はChannel Aへ、内部違反はオンコールへ」)。共有チャンネルにクライアント固有の詳細を送らないよう注意してください。
アラート疲れを防ぐために:
各アラートは次をサポートするべきです:
これがクライアント向け要約に再利用できる軽量な監査トレイルを作ります。
複雑なクエリロジックを露出させず、しきい値とルーティングを設定できる簡易エディタを提供します。ガードレール(デフォルト、バリデーション、プレビュー:「先月これで3回トリガーされます」)を用意してください。
SLAレポートはクライアントがサービス品質を判断するために重要になります。したがって速度、安全性、監査可能性がチャートと同じくらい重要です。
大口クライアントは何百万件ものチケットやイベントを生成します。ページを応答良く保つために:
生イベントは調査で重要だが永久保管はコストとリスクを増す。明確なルールを設定します:
レポーティングポータルには顧客名、タイムスタンプ、チケットノート、場合によってはPIIが含まれると想定します。
特定の標準を目指していなくても、運用証拠が信頼を生みます。
維持すべきもの:
SLAレポートアプリのローンチは一度に全てを出すより、正確性を実証してから反復的に拡張することが重要です。強いローンチ計画は再現性のある結果を出し、争いを減らします。
管理しやすいサービスとデータソースを持つ1社を選び、アプリの計算を既存のスプレッドシートやチケットエクスポート、ベンダーポータルの報告と並行して実行します。
よく差が出る箇所に注目:
差分を文書化し、アプリがクライアントの現行方法に合わせるべきか、より明確な標準に置き換えるべきかを決めます。
再現可能なオンボーディングチェックリストを作り、新規クライアント体験を予測可能にします:
チェックリストは工数見積りにも役立ち、/pricing の議論を助けます。
SLAダッシュボードは、新鮮で完全であると信頼されて初めて価値を持ちます。次を監視してください:
まずは内部アラートを送り、安定したらクライアント向けのステータス表示を導入します。
混乱が生じる箇所(定義、争いのポイント、「何が変わったか」)からフィードバックを収集し、小さなUX改善(ツールチップ、変更ログ、除外の明確な脚注)を優先してください。
内部MVP(テナントモデル、統合、ダッシュボード、エクスポート)を素早く出すなら、ボイラープレートに時間をかけずにvibe-coding的なアプローチが有効です。例として、Koder.ai はチャットを通じてマルチテナントWebアプリの草案と反復を支援し、ソースコードをエクスポートしてデプロイできます。SLAレポート製品はドメインルールとデータ正規化がコアの複雑点なので、この方法は実用的です。
Koder.ai の planning mode を使えば、エンティティ(tenants, services, SLA definitions, events, rollups)を整理し、React UI と Go/PostgreSQL のバックエンド基盤を生成して特定の統合や計算ロジックを拡張できます。
次のステップ(新しい統合、エクスポート形式、監査トレイル)を記した生きたドキュメントを保ち、関連ガイドを /blog にリンクしてクライアントとチームが自己解決できるようにします。
集中型SLAレポーティングは、稼働時間、インシデント、チケットのタイムラインをひとつのトレース可能なビューに取り込んで、ワンソースオブトゥルースを作ることが目的です。
実務上は次を実現するべきです:
最初は多くのクライアントに馴染みのある小さな指標セットから始め、説明できて監査可能になったら拡張します。
一般的な開始指標:
各指標に対して、何を測るか、何を除外するか、必要なデータソースを文書化してください。
まず文章でルールを書き、それをコード化します。
通常定義すべき項目:
二人が自然言語で合意できないなら、コード化しても争点になります。まず人が納得する文を書くことが重要です。
すべてのタイムスタンプをUTCで保存し、表示時にテナントの報告タイムゾーンで変換するのが基本です。
また事前に決めておくべき点:
UI上で明示してください(例:「報告期間の切り替えは America/New_York 基準です」)。
フレッシュネス(即時性)と完全性に応じて統合方法を組み合わせて使います:
実務ルール:フレッシュネスが重要ならWebhook、完全性が重要ならAPIプルを優先します。
異なるツールを同じ概念に揃えるために、小さな正規化されたイベントセットを定義します。
例:
incident_opened / incident_closeddowntime_started / マルチテナントモデルを選び、UI以外のレイヤーでも分離を徹底します。
重要な保護策:
tenant_id でスコープするエクスポートやバックグラウンドジョブは誤ってデータを流出させやすいので、テナントコンテキスト設計を慎重に行ってください。
高速なダッシュボードと説明可能性の両方を満たすため、生イベントと派生結果の両方を保存します。
実践的な分離:
また を付けて、ルール変更後でも過去の報告を再現できるようにしてください。
パイプラインを段階に分け、冪等性(idempotency)と再計算性を担保します:
信頼性のための実践:
運用的に役立つアラートを3種類用意します:
ノイズを減らすために重複抑止、静穏時間、エスカレーションを実装し、各アラートを確認・解決メモとリンクできるようにしてください。
downtime_endedticket_created / first_response / resolvedtenant_id、service_id、source_system、external_id、severity、UTCタイムスタンプといった一貫したフィールドを含めます。
calculation_version