2025年8月06日·1 分
集中型通知制御のためのWebアプリの作り方
チャネル横断で通知を一元管理するWebアプリの設計と構築方法。ルーティングルール、テンプレート、ユーザー設定、配信トラッキングまでを扱います。
集中型通知管理が解決すること
集中型通知管理とは、製品が送るすべてのメッセージ――メール、SMS、プッシュ、アプリ内バナー、Slack/Teams、Webhookコールバック――を一つのコーディネートされたシステムの一部として扱うことを意味します。
各機能チームが個別に「メッセージを送る」ロジックを構築する代わりに、イベントが入ってきてルールが何を行うかを決め、配信がエンドツーエンドで追跡される単一の場所を作ります。
解消される痛み
通知がサービスやコードベースに散在していると、同じ問題が何度も起きます:
- ロジックの重複: 複数チームがリトライ、レート制限、購読解除、フォーマットを再実装する。
- メッセージの一貫性欠如: 同じ「パスワードリセット」や「請求書準備完了」のメッセージがチャネルや製品領域で異なり、ユーザーやサポートを混乱させる。
- 監査トレイルの欠如: 顧客が「届かなかった」と言ったとき、何が送られ、誰に、いつ、なぜ送られたかを答えるのが難しい。
集中化はアドホックな送信を、一貫したワークフローに置き換えます:イベントを作成し、設定とルールを適用し、テンプレートを選び、チャネルで配信し、結果を記録します。
誰が恩恵を受けるか
通知ハブは通常以下にサービスを提供します:
- 管理者: チャネル、テンプレート、ルーティング、コンプライアンスルールを再デプロイなしで設定できる。
- サポートチーム: 配信試行を検索・検証し、障害を特定して自信を持って対応できる。
- プロダクトチーム: 新しい通知パイプラインを構築する代わりにイベントを発行して機能を速く提供できる。
- エンドユーザー: 設定(オプトイン/アウト、静音時間、チャネル)を制御でき、予測可能な結果が得られる。
成功の指標
このアプローチが機能しているとわかるのは:
- リトライ、スロットリング、フォールバックチャネルが標準化され、インシデント量が減る。
- コピーの修正、ルーティングの調整、新しい受信者の追加が数分ででき、リリースサイクルを待たない。
- レポーティングが明確である:チャネル別配信率、配信時間、失敗理由、誰が何を変更したか。
要件と範囲:チャネル、ユースケース、制約
アーキテクチャを描く前に、「集中型通知制御」が自社にとって何を意味するかを明確にしてください。要件を明確にすることで最初のバージョンを集中させ、通知ハブが中途半端なCRMにならないようにします。
通知タイプを定義する(なぜ違うか)
サポートするカテゴリを列挙します。これがルール、テンプレート、コンプライアンスに影響を与えます:
- トランザクション系: パスワードリセット、領収書、アカウント変更。通常は必須で時間に敏感。
- マーケティング系: プロモーション、ニュースレター、製品発表。常にオプトイン/アウトに敏感。
- アラート: セキュリティ警告、障害、疑わしいアクティビティ。緊急度が高く、一部の設定をバイパスする場合がある。
- リマインダー: 予定、更新、未完了タスク。時間ウィンドウとスロットリングが重要。
各メッセージがどのカテゴリに属するかを明確にしておくと、「マーケティングをトランザクションとして偽装する」ことを防げます。
チャネル選択:今サポートすべきか後でか
運用可能な小さなセットを初日から選び、後で対応するチャネルをドキュメント化してデータモデルが将来を妨げないようにします。
今サポート(典型的MVP): メール + リアルタイムチャネル(プッシュまたはアプリ内)またはプロダクトが依存するならSMS。
後で対応: チャットツール(Slack/Teams)、WhatsApp、音声、郵便、パートナWebhook。
またチャネル制約(レート制限、到達性要件、送信者識別子、送信コスト)も書き出してください。
スコープを守るための非ゴール設定
集中型通知管理は「顧客関連のすべて」と同じではありません。一般的な非ゴール:
- 完全なコンタクトデータの強化はしない(ユーザー/受信先は最小限に)
- セグメンテーション、A/Bテスト、分析ダッシュボードを備えたキャンペーンビルダーは対象外
- チケッティング/エスカレーションワークフローは対象外(既存ツールと連携する)
コンプライアンスと保持要件
ルールを早期にキャプチャして後付けにしない:
- チャネルと通知タイプ別のオプトイン/同意(特にマーケティング)
- 購読解除処理(必要な場合はワンクリック)とサプレッションリスト
- 保持期間: メッセージ本文とメタデータの保存期間(例:30/90/365日)
- 監査可能性: テンプレート、ルーティング、設定を誰がいつ変更したか
既にポリシーがある場合は内部リンク(例:/security、/privacy)を参照し、これらをMVPの受け入れ基準として扱ってください。
通知ハブの高レベルアーキテクチャ
通知ハブはパイプラインとして理解するとわかりやすいです:イベントが入り、メッセージが出て、各ステップが可観測です。責務を分離しておけば、チャネル(SMS、WhatsApp、プッシュ)を後から追加しても全体を書き換える必要がありません。
コアコンポーネント
1) イベント受け口(API + コネクタ) アプリ、サービス、外部パートナーが「何かが起きた」イベントを単一のエントリポイントに送ります。典型的な取り込み経路はRESTエンドポイント、Webhook、SDKコールです。
2) ルーティングエンジン ハブは「誰に」通知するか、「どのチャネルで」か、「いつ」かを決定します。この層は受信者データと設定を読み、ルールを評価して配信計画を出力します。
3) テンプレーティング + パーソナライズ 配信計画を受けて、チャネル特有のメッセージ(メールHTML、SMSテキスト、プッシュペイロード)をテンプレートと変数でレンダリングします。
4) 配信ワーカー これらはプロバイダ(SendGrid、Twilio、Slackなど)と統合し、リトライを処理し、レート制限を順守します。
5) トラッキング + レポーティング すべての試行を記録します:受理、送信、配達、失敗、開封/クリック(可能な場合)。これが管理ダッシュボードと監査トレイルの基盤になります。
同期処理 vs 非同期処理
軽量な受付(バリデーションして202 Acceptedを返す等)以外は同期処理を避け、非同期でルートと配信を行います:
- 取り込み後にキュー化してプロバイダ障害やトラフィックスパイクからアプリを保護する
- チャネルや優先度ごとにキューを分ける(トランザクション系 vs マーケティング)ことで一つのストリームが他を枯渇させないようにする
環境と設定
dev/staging/prod を早期に計画します。プロバイダ資格情報、レート制限、フィーチャーフラグは環境別設定に保存(テンプレートには保存しない)してください。テンプレートはバージョン管理して、ステージングでテストしてから本番に影響を与えるようにします。
ルールとコンテンツの責任分担
実用的な分割例:
- エンジニア:イベントスキーマ、統合、ガードレール(タイムアウト、リトライ、冪等性)を担当
- 管理者/オペス:ルーティングルールとテンプレート文言を担当。高リスクチャネルには承認ワークフローを設ける
このアーキテクチャは安定した基盤を提供しつつ、日常のメッセージ変更をデプロイサイクルから切り離します。
イベントモデルとデータ契約
集中通知管理システムはイベントの品質に依存します。製品の異なる部分が同じ事象を異なる形で記述すると、ハブは翻訳や推測や破綻に追われます。
明確なイベントスキーマを定義する
すべてのプロデューサが従える小さく明示的な契約から始めてください。実用的なベースライン:
- event_name: 安定した識別子(例:
invoice.paid,comment.mentioned) - actor: それを引き起こしたもの(ユーザーID、サービス名)
- recipient: 対象(ユーザーID、チームID、またはリスト)
- payload: メッセージ作成に必要なビジネスフィールド(amount、invoice_id、comment_excerpt 等)
- metadata: ルーティングや運用のためのコンテキスト(tenant/workspace ID、timestamp、source、localeヒント)
この構造によりイベント駆動通知が理解しやすくなり、ルーティング、テンプレート、配信トラッキングをサポートできます。
契約のバージョニング(変更を恐れない)
イベントは進化します。破壊的変更を防ぐには、例えば schema_version: 1 のようにバージョンを付けます。破壊的な変更が必要な場合は新しいバージョン(あるいは新しいイベント名)を公開し、移行期間は両方をサポートします。複数のプロデューサが1つのハブにデータを送る場合に特に重要です。
バリデート、サニタイズ、冪等化
受信イベントは自社システムからでも信頼できない入力として扱います:
- バリデーション: 必須フィールドと型を検証し、破損イベントは拒否または隔離する
- サニタイズ: テンプレートレンダリング時の注入やフォーマット問題を避けるために文字列を消毒する(HTMLメール、Slack/Teamsマークダウン、SMS)
- 冪等性キー:
idempotency_key(例:invoice_123_paid)を追加して、リトライがマルチチャネル通知で重複送信を生まないようにする
強いデータ契約はサポートチケットを減らし、統合を速め、レポーティングと監査ログを信頼できるものにします。
ユーザー、受信先、通知設定
通知ハブは「誰か」を知り、「どうやって連絡するか」を知り、「何を受け取ることに同意しているか」を知らないと機能しません。ID、連絡データ、設定を第一級オブジェクトとして扱ってください。
受信先とユーザーの区別
User(ユーザー)(ログインするアカウント)とRecipient(受信先)(メッセージを受け取れるエンティティ)を分けます:
- ユーザーは複数の受信先を持てる(勤務先メール、個人メール、SMS番号)
- 受信先は共有先(チームメールボックスやオンコールローテーション)になり得る
各連絡先には値(例:メールアドレス)、チャネル種別、ラベル、所有者、検証ステータス(未検証/検証済み/ブロック)を保持します。最後の検証時刻や検証方法(リンク、コード、OAuth)などのメタデータも持ちます。
設定:チャネル、トピック、時間
設定は表現力がありつつ予測可能にします:
- トピック別(例:Billing、Security、Deployments)
- チャネル別(Email、SMS、Push、Slack)
- 静音時間(受信先のローカルタイムゾーン)、ただし重要アラートの例外あり
これを階層化されたデフォルトでモデル化します:組織 → チーム → ユーザー → 受信先。下位レベルが上位を上書きできます。これにより管理者がベースラインを設定し、個人が個別制御できます。
同意、オプトアウト、証拠
同意は単なるチェックボックスではありません。保存するもの:
- チャネル・トピックごとのオプトイン/オプトアウトのタイムスタンプ
- 同意の出所(UI、API、インポート)と実行者(ユーザー/管理者/システム)
- 購読解除理由(フリーテキストまたは列挙値)や一時抑止の期限
- 必要な場合の証拠(ダブルオプトイントークン、Webhookコールバック、署名記録)
同意の変更は監査可能で、/settings/notifications のような単一の場所からエクスポートできるようにしてください。サポートが「なぜ届いたのか/届かないのか」に答えられる必要があります。
ルーティングルール:誰に何をどこでいつ
獲得したクレジットで節約
Koder.aiのコンテンツや紹介プログラムでクレジットを獲得して、構築コストを削減します。
ルーティングルールは通知ハブの「頭脳」です:誰に通知すべきか、どのチャネルで、どの条件で、を決定します。良いルーティングはノイズを減らしつつ重要なアラートを逃しません。
ルール入力("いつ"と"誰")
ルールが評価できる入力を定義します。最初は少数だが表現力のあるものに:
- イベントタイプ(例:
invoice.overdue,deployment.failed,comment.mentioned) - ユーザーセグメント(ロール、プラン、チーム、地域、所有権—誰が対象になるか)
- 重大度/優先度(info、warning、critical)
- 時間帯(営業時間 vs 夜間;静音時間)
- ロケール(テンプレート言語やフォーマット選択)
これらの入力はイベント契約から導出されるべきで、管理者が通知ごとに手入力するものではないようにします。
ルールアクション("どうやって")
アクションは配信挙動を指定します:
- チャネル選択: Email、SMS、Push、Slack/Teams、Webhook、アプリ内インボックス
- スロットリング/ダイジェスト: 繰り返し制限(例:「30分以内最大1回」)や非緊急メッセージのバッチ化
- エスカレーション: X分内に確認されなければオンコールにエスカレーション
- オンコールへのルーティング: スケジュールと統合して夜間のインシデントを正しい人に送る
優先度、フォールバック、失敗処理
ルールごとに明確な優先度とフォールバック順序を定義します。例:まずプッシュ、プッシュ失敗ならSMS、最後にメール。
フォールバックは実際の配信シグナル(バウンス、プロバイダエラー、デバイス到達不能)に紐づけ、リトライループが止まるよう上限を設けます。
安全な編集とレビューのワークフロー
ルールはガイド付きUI(ドロップダウン、プレビュー、警告)で編集できるようにし、以下を備えます:
- Draft と published の状態
- 高影響変更に対するピアレビュー/承認
- シミュレーションモード(サンプルイベントで「誰に届くか?」を表示)
- 変更ごとの監査トレイル(管理者とタイムスタンプ)
テンプレートとローカリゼーションで一貫したメッセージ
テンプレートは集中管理された通知が「まとまりある体験」になる場所です。良いテンプレートシステムはトーンの一貫性を保ち、エラーを減らし、複数チャネル(メール、SMS、プッシュ、アプリ内)で意図的な体験を提供します。
テンプレート構造:予測可能でチャネル対応
テンプレートを単なるテキストの塊ではなく構造化資産として扱います。最低限保存するもの:
- 件名/タイトル(メール件名、プッシュタイトル、アプリ内ヘッダ)
- 本文(メールはHTML+プレーンテキスト、プッシュ/SMSは短/長バリアント)
- 変数(型指定されたプレースホルダ例:
{{first_name}},{{order_id}},{{amount}}) - フォーマットルール(チャネルごとの許容マークアップ、最大長、リンクポリシー)
変数はスキーマで明示して、イベントペイロードが必須項目をすべて提供しているかをシステムで検証できるようにします。これにより「Hi {{name}}」のような未レンダリングメッセージの送信を防げます。
ローカリゼーション:ロケール選択と翻訳不足時の扱い
受信者のロケール選択ルールを定義します:ユーザー設定→アカウント/組織設定→デフォルト(通常 en)。各テンプレートはロケールごとの翻訳を保持し、フォールバック方針を明確にします:
fr-CAがなければfrにフォールバックfrがなければテンプレートのデフォルトロケールにフォールバック- 必須翻訳が欠けている場合、そのロケールへの送信をブロックするか、デフォルトに切り替えてフォールバックを配信メタデータにログする
これにより翻訳不足がレポートで可視化され、黙って品質が低下することを防げます。
プレビューとテスト送信(管理者+QA)
テンプレートのプレビュー画面で管理者が以下を選択できるようにします:
- チャネル(Email/SMS/Push)
- ロケール
- サンプルイベントペイロード(実際にキャプチャしたイベントかモックのJSON)
パイプラインが送る最終メッセージを正確にレンダリングし、リンク書き換えや切り詰めルールを反映させます。誤送信を避けるため、サンドボックス受信者リストへのテスト送信機能を提供してください。
バージョニングと承認で事故を防ぐ
テンプレートはコードのようにバージョン管理します:変更ごとに不変の新バージョンが作られます。ステータス例:Draft → In review → Approved → Active。ロールベースの承認を必須にすることも可能です。ロールバックはワンクリックで行えるようにします。
監査可能性のために、誰がいつ何をなぜ変えたかを記録し、テンプレート編集と配信結果を相関させて(/blog/audit-logs-for-notifications を参照)失敗増加と編集を結び付けられるようにします。
チャネル統合と配信パイプライン
ライブ環境に移行
準備ができたら通知アプリをデプロイ・ホストし、長いリリースサイクルなしで反復できます。
通知ハブの信頼性はラストマイル、つまり実際にメールやSMSやプッシュを配信するチャネルプロバイダに依存します。目的は各プロバイダを「プラグイン」のように扱い、チャネル間で一貫した配信挙動を保つことです。
各チャネルにまず1つのプロバイダを統合する
初めは各チャネルにつき単一で十分にサポートされたプロバイダを選びます(例:SMTPまたはメールAPI、SMSゲートウェイ、プッシュはAPNs/FCM経由)。統合は共通インターフェースの背後に隠しておき、後でプロバイダを交換・追加してもビジネスロジックを書き換えないようにします。
各統合は以下を扱うべきです:
- 認証とリクエスト署名
- ペイロードマッピング(あなたのメッセージ → プロバイダ形式)
- プロバイダ固有の制約(添付上限、送信者ID、オプトアウトヘッダ)
単なるAPI呼び出しではなく配信パイプラインを作る
「通知を送る」をキュー化→準備→送信→結果記録、という明確なステージを持つパイプラインとして扱います。アプリが小さくてもキューベースのワーカーモデルはプロバイダコールの遅延でウェブアプリがブロックされるのを防ぎ、リトライを安全に実装する場所を提供します。
実用的なアプローチ:
- Webアプリは「配信ジョブ」をキューに書く
- ワーカーがジョブを引き、プロバイダを呼び、結果を保存する
- 一部プロバイダは後でステータスを非同期に通知するのでWebhookで更新する
ステータスとエラー処理の標準化
プロバイダは様々なレスポンスを返します。それらを内部の単一ステータスモデルに正規化します(例:queued、sent、delivered、failed、bounced、suppressed、throttled)。
デバッグのために生のプロバイダペイロードは保存しますが、ダッシュボードやアラートは正規化ステータスを基に作ります。
リトライ、バックオフ、レート制限、バッチ
指数バックオフと最大試行回数でリトライを実装します。トランジェントなエラー(タイムアウト、5xx、スロットリング)のみリトライし、永久的なエラー(無効な番号、ハードバウンス)はリトライしないでください。
プロバイダごとにレート制限を守るためのスロットリングを追加します。高ボリュームイベントではプロバイダがサポートする場合にバッチ処理(例:バルクメールAPI呼び出し)を利用してコストとスループットを改善します。
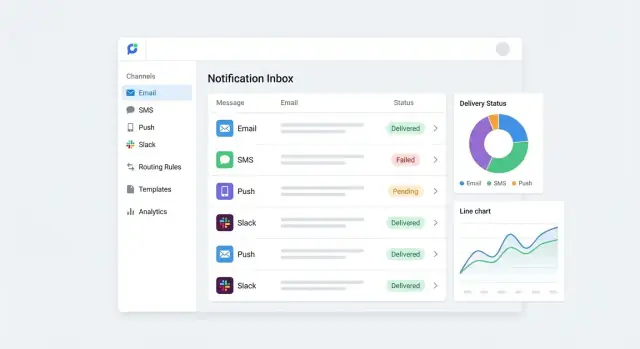
トラッキング、ステータス、レポーティングダッシュボード
集中通知ハブは可視性によって信頼されます。顧客が「そのメール届かなかった」と言ったときに、何が送られ、どのチャネルで何が起きたかを迅速に答えられる必要があります。
明確な配信状態を定義する
チャネルを越えてレポーティングが一貫するように小さな配信状態セットを標準化します。実用的なベースライン:
- queued(受理され送信待ち)
- sent(プロバイダに引き渡し済み)
- delivered(チャネルがサポートする場合に配達確認)
- bounced(恒久的配信失敗、通常メール)
- failed(送信できなかった、またはプロバイダに拒否された)
- opened(可能な場合。メールプロバイダで追跡可能だがSMS/プッシュではしばしば不可)
これらは単一の最終値ではなくタイムラインとして扱ってください—各メッセージ試行は複数のステータス更新を出す可能性があります。
検索可能なメッセージログを作る
サポートと運用が使いやすいメッセージログを作成します。最低限、以下で検索できるように:
- 受信者(ユーザーID、メール、電話)
- イベント(例:
invoice.paid,password.reset) - 期間(今日、過去7日など)
重要な詳細を含めます:チャネル、テンプレート名/バージョン、ロケール、プロバイダ、エラーコード、リトライ回数。デフォルトで安全に:機密フィールドはマスク(メール/電話の部分的な伏字)し、アクセスはロールで制限します。
上流イベントとメッセージの相関
各通知にトレースIDを追加して、トリガーしたアクション(チェックアウト、管理更新、Webhook)に結び付けます。同じトレースIDを:
- 元のイベントレコード
- 通知リクエスト
- すべての配信試行とステータス更新
これにより「何が起きたか?」を複数システムを横断して探すのではなく、単一のフィルタ済みビューで確認できます。
実用的なダッシュボード
意思決定に役立つ指標にフォーカスしてください:
- チャネルとイベント別のボリューム(スパイクを検出)
- プロバイダ/テンプレート/理由別の失敗(障害や不良データを発見)
- 送信数と失敗率で見たトップテンプレート(改善の優先度付け)
チャートから元のメッセージログへドリルダウンできるようにして、すべての指標が説明可能であることを保証します。
セキュリティ、アクセス制御、監査可能性
通知ハブは顧客データ、プロバイダ資格情報、メッセージ内容に触れるため、セキュリティは設計段階から組み込む必要があります。目標はシンプル:適切な人だけが振る舞いを変えられ、秘密は秘匿され、すべての変更が追跡可能であることです。
ロールベースアクセス制御(RBAC)
まずは小さなロールセットを始め、重要な操作にマッピングします:
- Admin: 組織設定、ユーザー、保持ポリシーの管理
- Notification Manager: ルーティングルール、テンプレート、ローカリゼーション文字列の編集
- Integration Manager: チャネルプロバイダキー(メール/SMS/プッシュ)、Webhook、コールバックURLの追加/更新
- Viewer/Auditor: ダッシュボードと監査履歴の読み取り専用
最小権限をデフォルトにして、新規ユーザーがルールや資格情報を編集できないようにしてください。
シークレットの扱いと資格情報ローテーション
プロバイダキー、Webhook署名シークレット、APIトークンは端から端までシークレットとして扱います:
- 保管時は暗号化(KMS/マネージドキーボルト)し、配信サービスのみ復号を許可
- ローテーションをダウンタイムなしに行えるように複数のアクティブキーを保存して段階的切り替えを可能にする
- ログやエラートレースでは機密フィールドをマスクし、PIIを含むメッセージ本文のログは避ける
信頼できる監査ログ
すべての設定変更は不変の監査イベントとして書き込みます:誰が何をいつどこ(IP/デバイス)から変更し、変更前後の値(シークレットはマスク)を含めます。ルーティングルール、テンプレート、プロバイダキー、権限割当の変更を追跡し、コンプライアンスレビューのために簡単にエクスポート(CSV/JSON)できるようにします。
保持と削除リクエスト
データ型ごとの保持期間(イベント、配信試行、コンテンツ、監査ログ)を定義し、UIに明記します。該当する場合は削除リクエストに対応し、受信者識別子を削除または匿名化しつつ集計メトリクスとマスク済み監査記録を保持できるようにします。
管理者とエンドユーザー向けUX
コードの管理を保持
生成されたソースコードを所有して、通知システムを移植可能で保守しやすく保ちます。
集中通知ハブは使いやすさで成功が左右されます。ほとんどのチームは日常的に「通知を管理」するわけではありません――問題が起きたときやインシデント時に初めて使います。UIは速く把握でき、安全に変更でき、結果が明確に見えるように設計してください。
管理コンソール:重要なページ
Rules(ルール) はコードのようにではなくポリシーのように読みやすくすべきです。「IF event… THEN send…」という表現でテーブル化し、チャネルのチップ(Email/SMS/Push/Slack)と受信者を表示します。シミュレータ:イベントを選んで誰に何が届くかを確認できるようにします。
Templates(テンプレート) はサイドバイサイドのエディタとプレビューが有効です。管理者がロケール、チャネル、サンプルデータを切り替えられるようにします。テンプレートはバージョン管理し「公開」ステップとワンクリックロールバックを提供します。
Recipients(受信先) は個人とグループ(チーム、ロール、セグメント)をサポートします。所属が見えるようにして(「なぜAlexはオンコールにいるのか?」)、受信先がどのルールで参照されているかを表示します。
Provider health(プロバイダ健全性) は一目でわかるダッシュボードが必要です:配信遅延、エラー率、キュー深度、最終インシデント。各問題に人間に読める説明と次のアクション(例:「Twilio認証失敗—APIキー権限を確認」)をリンクします。
エンドユーザー設定:混乱なく制御できる
設定は軽量に:チャネルのオプトイン、静音時間、トピック/カテゴリのトグル(例:「Billing」「Security」「Product updates」)。ページ上部にプレーンな要約を表示(「セキュリティアラートはSMSでいつでも届きます」)。
購読解除フローは尊重と準拠を両立:マーケティングはワンクリック購読解除、重要アラートはオフにできない旨を明確に表示(「アカウントセキュリティのため必須」)。ユーザーがチャネルを無効化した場合、何が変わるかを確認させる(「SMSは停止されます;メールは有効のまま」)。
実運用向けのツール
運用者にはプレッシャー下でも安全に使えるツールが必要:
- 再送(ガードレール付き:レート制限、確認、デフォルトで元受信者のみ)
- 予約済通知のキャンセル と監査トレイル
- ノイジーなイベントソースの一時抑止(時間制限付き)
- インシデントモード:ルーティングを上書き(オンコールへエスカレーション)し、非必須メッセージを一時停止
空状態と実行可能なエラー
空状態は次のステップを示すべきです(「まだルールがありません—最初のルーティングルールを作成」)と次のアクションへのリンク(例:/rules/new)。エラーメッセージは何が起きたか、何に影響したか、次に何をすべきかを示し、内部用語を避けます。可能なら「再接続」などのクイックフィックスとサポートチケット用の「詳細をコピー」ボタンを提供します。
MVP計画、テスト、ロールアウト戦略
集中通知ハブは大きなプラットフォームに成長しますが、最初は小さく始めるべきです。MVPの目的は最小限の部品でエンドツーエンドの流れ(イベント → ルート → テンプレート → 送信 → トラック)を実証し、安全に拡張することです。
迅速に最初の動くバージョンを作るには、Koder.ai のようなvibe-codingプラットフォームを使うと管理コンソールとコアAPIを素早く立ち上げられます:ReactベースのUI、GoバックエンドとPostgreSQLで構築し、チャット駆動のワークフローで反復します。プランニングモード、スナップショット、ロールバック機能でルール、テンプレート、監査ログを安全に洗練させてください。
概念を証明するための最小MVP
最初のリリースは意図的に狭くします:
- 1つのイベントタイプ(例:「パスワードリセット要求」または「invoice paid」)
- 1チャネル(多くはメール)と1つのプロバイダ統合
- 基本テンプレート(name, date, amount のようなシンプルな変数)とプレーンフォールバックメッセージ
- 小さな管理UI:送信とステータス(queued/sent/failed)を閲覧できる
このMVPは「正しいメッセージを正しい受信者に確実に送り、何が起きたかを見られるか」を答えるべきです。
配信と信頼を守るテスト
通知はユーザーに直接影響するため、自動テストの投資効果は高いです。重点は三つ:
- ルーティングテスト: イベントと受信者設定が与えられたときに選ばれるチャネルと抑止ルールを検証
- テンプレートテスト: サンプルデータでテンプレートをレンダリングし必須変数の存在とエスケープ(壊れたHTMLや不正なSMSテキストを防ぐ)を検証
- リトライと失敗テスト: プロバイダのタイムアウトやエラーをシミュレートし、リトライポリシー、冪等性(重複しない)、dead-letterハンドリングを確認
CIではサンドボックスプロバイダアカウントへの小さなE2Eテストを追加してください。
サプライズなしのロールアウト
段階的なデプロイを採用:
- シャドウモード: イベントを処理して「送信するはず」レコードを生成するが実際には配信しない
- 段階的トラフィック: 内部ユーザー→少量の本番イベントへと段階的に拡大
- レガシーへのフォールバック: ハブが失敗した場合は自動的に従来の送信経路に戻す
MVP後のロードマップ
安定化後は段階的に拡張します:チャネル追加(SMS、プッシュ、アプリ内)、より豊かなルーティング、テンプレートツールの改善、より深い分析(配信率、配信時間、オプトアウト傾向)など。
よくある質問
Webアプリ文脈での集中型通知管理とは何ですか?
集中型の通知管理は、イベント(例:invoice.paid)を取り込み、ユーザーの設定とルーティングルールを適用し、チャネルごとにテンプレートをレンダリングしてプロバイダ(メール/SMS/プッシュ等)を通じて配信し、結果をエンドツーエンドで記録する単一のシステムです。
これは、各所で「ここでメールを送る」ロジックを個別に実装する手法に代わり、運用と監査が可能な一貫したパイプラインを提供します。
自社プロダクトに通知ハブが必要かどうかはどう判断しますか?
早期のサインには以下が含まれます:
- 複数チームがリトライ、スロットリング、配信停止、フォーマットを再実装している
- 同じアクションに対してチャネルや機能ごとに文言が不揃いになっている
- ログが散在していて「送信されたか?」に迅速に答えられないサポート状況
- プロバイダが劣化したときに頻繁に障害が発生する(キューなし、フォールバックなし、標準的なリトライがない)
これらが繰り返されるなら、通知ハブは短期間で投資に見合う効果を出すことが多いです。
まずサポートすべきチャネルはどれですか?(どれを後回しにすべきか)
まず運用可能な小さなセットから始めてください。
- メール+リアルタイムチャネルのどちらか(プッシュまたはアプリ内)
- あるいは、プロダクトにとってSMSが中心の場合はSMSを選ぶ
Slack/Teams、Webhook、WhatsAppなどは「後で対応」のチャネルとして文書化し、データモデルが将来の拡張を阻害しないようにしておきますが、MVPでは統合を避けます。
集中型通知制御が機能することを証明するMVPには何が含まれるべきですか?
実際のループ(イベント → ルーティング → テンプレート → 配信 → トラッキング)を最小限の複雑さで証明することが目標です:
- 1つのイベントタイプ(例:パスワードリセット、invoice paid)
- 1チャネル(多くはメール)と1つのプロバイダ
- 必要変数の検証を含む基本的なテンプレート
- 最低限のメッセージログ(
queued/sent/failed)
目標は機能の幅ではなく、信頼性と可観測性です。
通知に使うべきイベントスキーマはどのようなものですか?
ルーティングやテンプレートが推測に頼らないよう、小さく明確なイベント契約を使ってください:
event_name(安定した識別子)actor(誰が引き起こしたか)recipient(誰に対してか)payload(メッセージ作成に必要なビジネスフィールド)- (テナント、タイムスタンプ、ソース、ロケールヒントなど)
リトライやチャネル間での重複通知をどう防ぎますか?
冪等性は、プロデューサがリトライしたときやハブ側がリトライするときの重複送信を防ぎます。
実践的なアプローチ:
- イベントごとに
idempotency_keyを必須にする(例:invoice_123_paid) - 受付時や配信ジョブ作成時に重複排除する
- そのキーに紐づく決定(ルーティング計画やテンプレートのバージョン)を保存する
これはマルチチャネルやリトライが多いフローで特に重要です。
ユーザー、受信先、通知設定はどうモデル化すべきですか?
IDと連絡先を分離してモデル化してください:
- User(ユーザー):ログインするアカウント
- Recipient(受信先):アドレス可能なエンドポイント(メール、電話、デバイストークン、Slack ID)やグループ(チームメールボックス、オンコール)
受信先ごとに検証ステータス(未検証/検証済み/ブロック)を保持し、設定は階層的なデフォルト(組織 → チーム → ユーザー → 受信先)で上位を下位が上書きできるようにします。
最初から組み込むべきコンプライアンスと同意に関する機能は何ですか?
チャネルと通知タイプごとに同意をモデル化し、監査可能にしておきます:
- チャネル/トピックごとのオプトイン/オプトアウトのタイムスタンプ、出所、実行者
- 必要に応じたワンクリックの購読解除処理
- 一時的抑止のためのサプレッションリストと有効期限
- コンテンツとメタデータの保持期間
サポートが「なぜ届いた/届かなかった?」に答えられるよう、単一のエクスポート可能な同意履歴ビューを用意してください。
異なるプロバイダ間で配信状況を一貫して追跡するには?
プロバイダ固有の結果を一貫した内部ステータスに正規化してください:
queued,sent,delivered,failed,bounced,suppressed,throttled
デバッグのために生のプロバイダレスポンスは保存しますが、ダッシュボードやアラートは正規化されたステータスを基に出します。ステータスはタイムラインとして扱い、各メッセージ試行が複数の更新を持つことを想定します。
ルーティングやテンプレートでミスを防ぐ管理ツールや安全策は?
安全策とガードレールを用意してください:
- ルール/テンプレートは Draft → Published の状態管理と、重要変更に対する承認フロー
- シミュレーション(「誰に届くか?」を確認)機能
- バージョン化されたテンプレートのワンクリックロールバック
- 再送の制御(確認、レート制限、デフォルトで元の受信者のみ)
- 一時的抑止やインシデントモードで非必須メッセージを停止
すべての変更は不変の監査ログで記録し、誰がいつ何を変えたかを残します。