2025年7月09日·1 分
ジョー・アームストロングとErlang:信頼性プラットフォームのための「Let It Crash」
Joe ArmstrongがErlangにもたらした並行性、監視、そして「let it crash(クラッシュを許容する)」の考え方を探り、リアルタイムサービスでの信頼性向上にどう役立つかを解説します。
Joe ArmstrongがErlangにもたらした並行性、監視、そして「let it crash(クラッシュを許容する)」の考え方を探り、リアルタイムサービスでの信頼性向上にどう役立つかを解説します。
ジョー・アームストロングは単にErlangを作っただけでなく、その考え方を最も明確に、説得力を持って伝えた人物です。講演や論文、実践的な視点を通じて彼が広めた単純な考えはこうです:稼働し続けるソフトウェアが欲しいなら、障害を避けられると仮定して設計するのではなく、障害を前提に設計すること。
この記事はErlangのマインドセットを案内し、チャット、通話ルーティング、ライブ通知、マルチプレイヤーの調整、部分的に誤動作しても素早く一貫した応答を続ける必要があるインフラなど、信頼性の高いリアルタイムプラットフォームを構築する際にこの考え方がなぜ有効かを説明します。
リアルタイムが常に「マイクロ秒」や「厳密な締め切り」を意味するわけではありません。多くのプロダクトでは以下を意味します:
Erlangはこうした期待が妥協できない電気通信向けに作られ、そうしたプレッシャーがその最も影響力のあるアイデアを形作りました。
構文に飛び込む代わりに、Erlangを有名にし、現代のシステム設計でも繰り返し現れる概念に注目します:
途中で、これらの考えをアクターモデルやメッセージパッシングに結びつけ、監視ツリーとOTPを平易に説明し、BEAM VMがこのアプローチを実用的にする理由を示します。
Erlangを使っていなくても(今後使うことがなくても)、アームストロングのフレームワークは混乱した現実の中でも応答性と可用性を保つための強力なチェックリストになります。
電気通信のスイッチや通話ルーティングプラットフォームは、多くのウェブサイトのように「メンテナンスで止める」ことが許されません。通話、課金イベント、シグナリングトラフィックを常時処理し続けることが期待され、可用性や応答時間に厳しい要件が課されます。
Erlangは1980年代後半にEricssonの内部で、そうした現実にソフトウェアで対応する試みとして生まれました。ジョー・アームストロングと同僚たちは、単なる優雅さを追求していたわけではなく、運用者が常時負荷や部分的障害、現実世界の雑多な状況の下でも信頼できるシステムを作ろうとしていました。
考え方の重要な転換は、信頼性が「一度も失敗しないこと」と同じではないという点です。大規模で長期稼働するシステムでは何かは必ず壊れます:プロセスが想定外の入力に当たる、ノードが再起動する、ネットワークリンクが不安定になる、あるいは依存先がスタックする。\n そこで目標は以下になります:
このマインドセットが監視ツリーや「let it crash」のアイデアを合理的にしています:障害を異常ではなく通常の出来事として設計するのです。
一人の天才的発明の物語にしたくなる誘惑がありますが、実際はもっとシンプルです:電気通信の制約が異なるトレードオフを強いました。Erlangは並行性、隔離、回復を優先しましたが、それはサービスを稼働し続けるための実用的な道具だったからです。
問題志向の枠組みこそが、Erlangの教訓が今日でも変わらず適用できる理由です——アップタイムと迅速な回復が完全な予防より重要な場所ならどこでも有効です。
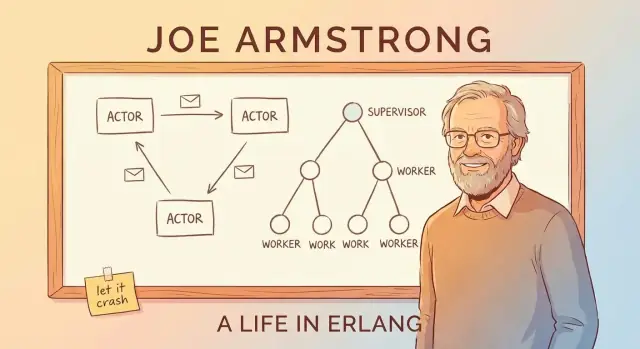
Erlangの核心的な考えは「同時に多くのことを行うこと」が後から付け足す特別な機能ではなく、システム構造の普通のやり方であるということです。
Erlangでは仕事を大量の小さな「プロセス」に分割します。各プロセスは一つの仕事を担当する小さなワーカーと考えてください:通話の処理、チャットセッションの追跡、デバイスの監視、支払いの再試行、キューの監視など。
これらは軽量なので大量に存在させても大きなハードウェアを必要としません。一つの重いワーカーが全てを抱え込む代わりに、素早く開始し、素早く停止し、素早く置き換えられる多数の専任ワーカーが存在します。
多くのシステムは多くの部分が密に結合した単一の大きなプログラムとして設計されています。そのようなシステムが重大なバグ、メモリ問題、ブロッキング操作に当たると、故障が外側へ波及します——まるで一つのブレーカーが落ちて建物全体が停電するように。
Erlangはその逆を促します:責務を隔離する。小さなワーカーの一つが誤動作しても、関連のない作業を落とさずにそのワーカーだけを止めて置き換えられます。
これらのワーカーはどう協調するのか?お互いの内部状態を直接触りません。メッセージを送ります——共同のホワイトボードを共有するのではなく、付箋を渡すようなものです。
あるワーカーが「新しいリクエストです」「ユーザーが切断しました」「5秒後に再試行して」と送ります。受け取ったワーカーはその付箋を読み、何をするかを決めます。
利点は封じ込めです:ワーカーが隔離されメッセージでやり取りするので、障害がシステム全体に広がりにくくなります。
Erlangの「アクターモデル」を理解する簡単な方法は、多数の小さく独立したワーカーで構成されたシステムを想像することです。
アクターはプライベートな状態とメールボックスを持つ自己完結型の単位です。アクターは基本的に三つのことをします:
それだけです。隠れた共有変数も、他のワーカーのメモリに手を伸ばすこともありません。あるアクターが別のものを必要とするなら、メッセージで依頼します。
複数のスレッドが同じデータを共有すると、同時に同じ値を変更しようとしてタイミング次第で結果が変わるレースコンディションが発生します。これが再現しにくい間欠的なバグの原因になります。
メッセージパッシングでは各アクターが自分のデータを所有します。他のアクターは直接それを変更できません。すべてのバグが消えるわけではありませんが、同時アクセスに起因する問題は劇的に減ります。
メッセージは「ただ届く」わけではありません。もしアクターが処理より速くメッセージを受け取れば、そのメールボックス(キュー)は伸びます。それがバックプレッシャーです:システムが間接的に「ここが過負荷だ」と伝えています。
実務ではメールボックスのサイズを監視し、負荷を削る、バッチ処理する、サンプリングする、あるいはキューが無限に伸びないように仕事をより多くのワーカーに振るなどの施策を取ります。
チャットアプリを想像してください。各ユーザーに通知配信を担当するアクターがいるかもしれません。ユーザーがオフラインになるとメッセージは届き続け、メールボックスは増えます。適切に設計されたシステムではキューに上限を設け、重要度の低い通知を破棄したり、ダイジェストモードに切り替えたりして、一人の遅いユーザーがサービス全体を劣化させないようにします。
「let it crash」はいい加減なエンジニアリングのスローガンではありません。これは信頼性の戦略です:コンポーネントが悪い状態や想定外の状態に陥ったら、じわじわ動き続けるより速やかに停止すべき、ということです。
一つのプロセス内であらゆるエッジケースを処理しようとする代わりに、Erlangは各ワーカーを小さく焦点を絞ったものにすることを勧めます。もしそのワーカーが本当に対処できないもの(破損した状態、仮定の破綻、予期しない入力)に当たったら、プロセスを終了させます。システムの別の部分がそれを再起動します。
これにより主要な問いは「どうやって障害を防ぐか」から「障害が起きたときにどうクリーンに回復するか」に移ります。
あらゆるところで防御的に書くと、簡単な処理フローが条件分岐やリトライ、部分的な状態で迷路のようになります。「let it crash」はプロセス内の複雑さをいくらか引き換えにします:
重要なのは回復が即決かつ再現可能であること。場当たり的な対処ではなく、予測できる回復を行うべきです。
これは一時的で隔離可能な障害(ネットワークの一時的な問題、悪いリクエスト、スタックしたワーカー、外部のタイムアウト)に最も合います。
逆に適さないのはクラッシュが取り返しのつかない害を引き起こす場合:
クラッシュは戻ってくることが迅速かつ安全であるときにのみ有効です。実務的にはワーカーを既知の良好な状態で再起動することが必要です——多くの場合は設定を再読込したり、耐久ストレージからインメモリキャッシュを再構築したりして、壊れた状態を無かったことにせずに復帰します。
Erlangの「let it crash」はクラッシュを放置するわけではありません。重要なパターンは監視ツリー(supervision tree)です:ここではスーパーバイザが管理者のように振る舞い、ワーカーが実際の仕事を行う(通話処理、セッション管理、キュー消費など)。ワーカーが誤動作したら管理者が気づいて再起動します。
スーパーバイザは壊れたワーカーをその場で「直そう」とはしません。代わりに単純で一貫したルールを適用します:もしワーカーが死んだら新しいものを起動する。これにより回復経路が予測可能になり、コード全体にばらまかれたアドホックなエラーハンドリングが減ります。
同様に重要なのは、スーパーバイザが再起動しない判断を下すこともできる点です。何度もクラッシュするものは深刻な問題を示しており、繰り返し再起動することが状況を悪化させる場合があります。
監視は一律ではありません。一般的な戦略には:
良い監視設計は依存関係マップから始まります:どのコンポーネントがどれに依存し、「新しい開始」がそれらにとって何を意味するか。
セッションハンドラがキャッシュプロセスに依存しているなら、ハンドラだけを再起動すると不整合な状態に接続されるかもしれません。適切なスーパーバイザの下にグループ化したり、一緒に再起動することで乱れた故障モードを一貫した回復に変えられます。
Erlangが言語なら、OTP(Open Telecom Platform)は「let it crash」を長期間運用可能にする部品箱です。
OTPは単一のライブラリではなく、一連の慣習と既製のコンポーネント(behaviours)です。サービス構築で退屈だが重要な部分を解決します:
gen_server:状態を保持し一度に1つずつリクエストを処理する長時間実行ワーカーsupervisor:定義されたルールに従って失敗したワーカーを自動再起動するapplication:サービス全体の起動・停止とリリースでの振る舞いを定義するこれは「魔法」ではなく、コールバックが明確に定義されたテンプレートです。プロジェクトごとに新しい仕組みを発明する代わりに既知の形に差し込めます。
チームはしばしば場当たり的なバックグラウンドワーカーや再起動ロジックを自作します。動く間は問題ありませんが、壊れたときに困ります。OTPは全員を同じ語彙とライフサイクルに導くことでそのリスクを減らします。新しいエンジニアはまず独自フレームワークを学ぶ必要がなく、Erlangエコシステムで広く理解されているパターンを頼れます。
OTPは「プロセスの役割」と「責任」を考えさせます:ワーカーとは何か、コーディネータとは何か、何を誰が再起動するのか、自動再起動してはいけないものは何か。
また、明確な命名、明示的な起動順序、予測可能なシャットダウン、組み込みの監視シグナルといった良い運用習慣を促します。その結果、障害から回復し、時間の経過で進化し続け、人手による常時の監視なしに機能し続けるソフトウェアが出来上がります。
小さなプロセス、メッセージパッシング、そして「let it crash」というErlangの大きなアイデアは、BEAM仮想マシン(VM)なしでは本番で扱いにくいでしょう。BEAMはこれらのパターンを自然で壊れにくくするランタイムです。
BEAMは大量の軽量プロセスを動かすように設計されています。OSスレッドに頼るのではなく、BEAM自身がErlangプロセスをスケジュールします。
実務的な利点は負荷下での応答性です:作業は小さな単位に切られ公平に回されるため、一つの忙しいワーカーがシステム全体を長時間独占することが意図されていません。多数の独立タスクから成るサービスに非常によくフィットします。
各Erlangプロセスは独自のヒープと独立したガベージコレクションを持ちます。重要な点は:あるプロセスのメモリ回収が全体を停止させないことです。
さらに、プロセスは隔離されています。あるプロセスがクラッシュしても他のプロセスのメモリを壊すことはなく、VM自体は稼働し続けます。この隔離が監視ツリーを現実的にする基盤です:障害は封じ込められ、壊れた部分を再起動して対処します。
BEAMは分散を自然にサポートします:複数のErlangノード(別々のVMインスタンス)を動かし、メッセージで通信させられます。「プロセスがメッセージで話す」という理解があれば、分散はその延長です——ただしプロセスが別のノードに存在するだけです。
BEAMは生のスピードを約束するものではなく、並行性、障害封じ込め、回復をデフォルトにすることで信頼性を理論ではなく実践に落とし込みます。
Erlangの有名な機能の一つにホットコードスワッピングがあります:ランタイムとツールが支援する条件で、実行中のシステムの一部を最小限のダウンタイムで更新できます。実際の約束は「二度と再起動しない」ではなく「短い障害が長期の停止に拡大するのを防ぐ」です。
Erlang/OTPでは、ランタイムが同時に二つのモジュールバージョンを保持できます。既存のプロセスは古いバージョンを使って処理を終え、新しい呼び出しは新しいバージョンを使い始めることができます。これによりバグ修正や機能展開を全員を蹴散らすことなく行えます。
適切に行えば、フルリスタートの回数を減らし、メンテナンスウィンドウを短くし、本番で何かが滑り込んだときの回復を速めます。
すべての変更がライブで安全に差し替えられるわけではありません。特に注意が必要な変更例:
Erlangは制御された移行の仕組みを提供しますが、アップグレードパスを設計するのは開発者の仕事です。
ホットアップグレードは、アップグレードとロールバックを日常的な操作と見なすときに最も効果的です。バージョン管理、互換性、明確な「元に戻す」手順を最初から計画しておきます。実務ではステージングされたロールアウト、ヘルスチェック、監視を伴う監視ベースの回復と組み合わせます。
Erlangを使わない場合でも教訓は移ります:「安全に変更する」ことを第一級要件にする設計を行ってください。
リアルタイムプラットフォームは完璧な時間保証より、問題が常に起きる中で応答性を維持することが重要です:ネットワークが揺らぎ、依存先が遅くなり、ユーザートラフィックが急増する。ジョー・アームストロングが推したErlangの設計は失敗を前提とし、並行性を当たり前に扱うため、こうした現実に適合します。
Erlang的な考えが輝く場面は多数の独立した活動が同時に起きるところです:
多くのプロダクトは「各処理が10msで終わる」といった厳密な保証を必要としません。必要なのはソフトリアルタイム:通常のリクエストに対する一貫して低いレイテンシ、部分故障時の迅速な回復、高可用性でユーザーがほとんど影響を感じないこと。
実システムは以下のような問題に直面します:
Erlangのモデルは各活動(ユーザーセッション、デバイス、支払い試行)を隔離することを促します。ひとつの大きな「何でも処理する」コンポーネントを作る代わりに、各ワーカーが一つの仕事を行い、メッセージでやり取りし、壊れたらクリーンに再起動します。
この「すべての障害を防ぐ」から「障害を封じ込め、素早く回復する」への視点の転換こそが、プレッシャー下でもリアルタイムプラットフォームを安定させる鍵です。
Erlangが「決して落ちないシステム」を約束するかのように言われることがありますが、現実はもっと実用的です。「let it crash」は信頼できるサービスを作るための道具であり、難しい問題を無視する免罪符ではありません。
スーパービジョンを深刻なバグを隠す手段と考えるのは誤りです。プロセスが起動直後に即死するような場合、スーパーバイザは何度も再起動し続け、クラッシュループを生み、CPUを浪費し、ログを大量に吐き、元の障害以上に大きな障害を引き起こすことがあります。
良いシステムはバックオフ、再起動頻度の制限、最終的にはエスカレーションする振る舞いを備えます。再起動は健全な状態に戻すための手段であって、壊れた不変条件を隠す方法ではありません。
プロセスを再起動すること自体はしばしば簡単ですが、正しい状態を回復することは難しいです。状態がメモリ内だけにある場合、クラッシュ後に「正しい」とは何かを決める必要があります:
耐障害性はデータ設計を置き換えるものではなく、明確にすることを要求します。
クラッシュは早期に見つけられ、理解できてこそ役に立ちます。つまりログ、メトリクス、トレースへの投資が必要です——「再起動したから大丈夫」では済みません。再起動率の上昇、キューの伸び、依存先の遅延をユーザーに影響が出る前に察知したいのです。
BEAMの強みがあっても、システムは普通の原因で失敗します:
Erlangのモデルは障害を封じ込め、回復しやすくしますが、障害そのものを取り除くわけではありません。
Erlangの最大の贈り物は構文ではなく、障害が必ず起きる状況で動き続けるサービスを作る習慣です。その習慣はほぼどんなスタックにも適用できます。
まず失敗境界を明確にします。システムを独立して故障できるコンポーネントに分け、それぞれが明確な契約(入力、出力、そして「異常」の定義)を持つようにします。
次に、すべてを防ごうとするのではなく回復を自動化します:
これらの習慣を単にコードに書くだけでなく、ツールやライフサイクルに組み込むと実際に機能します。たとえばチームがKoder.aiを使ってチャット経由でウェブやバックエンド、モバイルアプリを作るワークフローでは、Planning Modeやスナップショット、ロールバックといった機能が自然に明確な計画、反復可能なデプロイ、安全な迭代を促します。これはErlangが普及させた運用上の考え方と整合します:変化と失敗を想定し、回復を退屈な作業にする。
既に使っているツールで「監視」のようなパターンを近似できます:
パターンをコピーする前に実際に何が必要か決めてください:
実用的な次のステップを知りたい場合は /blog のガイドや /docs の実装詳細、評価中なら /pricing の計画を参照してください。
Erlangは実用的な可用性の考え方を普及させました:部品は壊れる前提で設計する、そして次に何をするかを決めておくことです。
すべてのクラッシュを防ぐ代わりに、フォールトの分離、迅速な検出、自動回復を重視します。これはチャット、通話ルーティング、通知、協調サービスなどのリアルタイム系プラットフォームにぴったり当てはまります。
この文脈での「リアルタイム」は多くの場合 ソフトリアルタイム を意味します:
ミリ秒単位の厳密な保証ではなく、停止や連鎖的な障害を避けることが重要です。
「並行性をデフォルトにする」は、少数の巨大なコンポーネントではなく、多くの小さな独立したワーカーで構成することを意味します。
各ワーカーはセッションやデバイス、リトライループなど狭い責務を持ち、スケーリングや障害の封じ込めが容易になります。
軽量プロセスは大量に生成できる小さな独立ワーカーです。
実務的には:
メッセージパッシングは共有の可変状態を直接触らず、メッセージでやり取りするやり方です。
これにより、競合状態(レースコンディション)のような同時実行に起因するバグの多くを減らせます。各ワーカーが自分の状態を所有し、他はメッセージでしか要求できません。
バックプレッシャーは、ワーカーが処理より速くメッセージを受け取り、メールボックスが増大する現象です。
現実的な対処法は:
「let it crash」は、ワーカーが不正な状態に到達したら**速やかに失敗させる(fail fast)**という戦略です。無理に動かし続けるより、構造化された回復に任せたほうが全体として安定します。
ただしこれは怠慢の言い訳ではなく、再起動が安全かつ迅速に行える場合に有効です。
監視ツリーは、スーパーバイザがワーカーを監視し定められたルールで再起動する階層構造です。
利点は回復経路が一貫して予測可能になること:
OTPは、Erlangでの運用を現実的にするための標準パターン群(behaviours)と慣習のセットです。
代表的な部品:
gen_server:状態を持つ長時間実行ワーカーsupervisor:失敗したワーカーの再起動方針application:サービス全体の起動/停止とリリース定義これらにより、チームは共通のライフサイクルと語彙を使ってシステムを構築できます。
Erlangを使っていなくても、同じ原則を他のスタックに適用できます:
詳細は投稿内の /blog や /docs を参照してください。