2025年10月31日·1 分
プラットフォームを形作った Joe Beda の初期の Kubernetes 設計判断
宣言型 API、コントロールループ、Pods、Services、ラベルなど、Joe Beda の初期 Kubernetes の判断がモダンなアプリプラットフォームをどう形作ったかをわかりやすく解説します。
宣言型 API、コントロールループ、Pods、Services、ラベルなど、Joe Beda の初期 Kubernetes の判断がモダンなアプリプラットフォームをどう形作ったかをわかりやすく解説します。
Joe Beda は Kubernetes 初期設計の主要メンバーの一人で、Google の内部システムから得た教訓をオープンプラットフォームに持ち込みました。彼の影響は流行の機能を追うことではなく、実際の本番混乱に耐えうる単純なプリミティブを選ぶことにあり、それが日々のチームにとって理解可能であることを重視していました。
そうした初期の判断こそが、Kubernetes が単なる「コンテナツール」以上のものになった理由です。モダンなアプリケーションプラットフォームの再利用可能なカーネルへと変わりました。
“コンテナオーケストレーション”は、機械が壊れたりトラフィックが急増したり、新しいバージョンをデプロイしたりする際にアプリを稼働させ続けるためのルールと自動化の集合です。人がサーバーを監視する代わりに、システムがコンテナをコンピュータにスケジュールし、クラッシュしたら再起動し、耐障害性のために分散し、ユーザーが到達できるようネットワークを配線します。
Kubernetes が普及する前、チームは基本的な疑問に答えるためにスクリプトやカスタムツールをつぎはぎしていました:
そのような自作システムは動くこともありましたが、動かなくなるときはひどく、アプリやチームが増えるたびに一回限りのロジックが積み重なり、運用の一貫性を保つのが難しくなりました。
この記事では、初期の Kubernetes 設計判断(Kubernetes の“形”)を辿り、なぜそれらが現代のプラットフォームに今も影響を与えているのかを説明します:宣言型モデル、コントローラー、Pods、ラベル、Services、強力な API、一貫したクラスタ状態、差し替え可能なスケジューリング、拡張性。あなたが直接 Kubernetes を運用していなくても、これらの考え方の上に成り立つプラットフォームを使っているか、同じ問題に苦労している可能性が高いです。
以前は「コンテナを動かす」といっても、数個のコンテナを走らせるだけのことが多く、チームは bash スクリプト、cron、ゴールデンイメージ、寄せ集めのツールでデプロイを賄っていました。何か壊れると修正は誰かの頭の中にあったり、信用されない README に残っていたりして、運用は一連の一回限りの介入の連続でした:プロセスの再起動、ロードバランサの再指向、ディスクの掃除、どのマシンに安全に触れるかの推測など。
コンテナはパッケージングを簡単にしましたが、本番の厄介な点を取り除いたわけではありません。スケールするとシステムはより多様な方法で頻繁に壊れます:ノードが消える、ネットワークが分断される、イメージの展開が不揃いになる、実行されているものが想定とずれる。単純なデプロイが崩壊の連鎖になることがあり、あるインスタンスは更新され、あるものはされず、あるものはハングし、あるものは到達可能だが不健康、などが起こります。
真の問題はコンテナを起動することではなく、絶え間ない変化の中で「正しい」コンテナを「正しい」形で動かし続けることでした。
チームはオンプレ、VM、初期クラウドプロバイダ、そして様々なネットワーク・ストレージ構成を同時に扱っていました。各プラットフォームは固有の語彙と障害パターンを持ち、共通モデルがなければ移行のたびに運用ツールを作り直し、人の再訓練が必要になりました。
Kubernetes は、マシンがどこにあってもアプリとその運用ニーズを記述するための一貫した方法を提供することを目指しました。
開発者はセルフサービスを望みました:チケットなしでデプロイし、容量を頼まずスケールし、混乱なくロールバックできること。運用は予測可能性を望みました:標準化されたヘルスチェック、再現可能なデプロイ、何が動いているべきかの明確な真実の源泉。
Kubernetes は派手なスケジューラを目指したわけではありません。混沌とした現実を論理的に扱える基盤を目指したのです。
初期の最も影響力のある選択の一つは、Kubernetes を宣言型にしたことでした:欲しい状態を記述すると、システムが現実をその記述に合わせるよう働きます。
サーモスタットは日常の良い例です。数分ごとにヒーターを手動で入れたり切ったりする代わりに、望ましい温度(例えば 21°C)を設定します。サーモスタットは部屋を監視し、その目標に近づけるようヒーターを調整します。
Kubernetes も同じです。クラスタに対して「このコンテナをあのマシンで起動して、失敗したら再起動して」と逐次命令するのではなく、「このアプリを 3 コピーで動かしたい」と宣言します。Kubernetes は継続的に実際に何が動いているかをチェックし、ドリフトを修正します。
宣言型設定はしばしば誰かの頭にある「運用チェックリスト」を減らします。設定を適用すれば Kubernetes が配置、再起動、変更の調整を担当します。
また、変更のレビューが容易になります。変更は一連の ad-hoc コマンドではなく、設定の差分として可視化されます。
望ましい状態が書き残されていれば、開発・ステージング・本番で同じアプローチを使い回せます。環境は異なっていても“意図”は一貫しているため、デプロイがより予測可能で監査しやすくなります。
宣言型システムには学習曲線があります:「次に何をするか」ではなく「何が真であるべきか」を考える必要があります。良いデフォルトと明確な慣習に依存するため、それがないと技術的には動くが理解・保守が難しい設定が生まれます。
Kubernetes が成功したのは単にコンテナを一度動かせるからではなく、それらを時間を通じて正しく動かし続けられるからです。大きな設計判断は“コントロールループ(コントローラー)”をシステムの中核に据えたことでした。
コントローラーは単純なループです:
これは一度きりのタスクというよりオートパイロットです。ワークロードを“見守る”のではなく、宣言したいことを宣言すればコントローラーがクラスターをその結果へ向かって操舵し続けます。
このパターンにより、現実世界の問題が起きても Kubernetes が耐性を持つ理由がわかります:
失敗を特別扱いするのではなく、コントローラーはそれらをルーチンな「状態不一致」として扱い、同じ方法で修正します。
従来の自動化スクリプトは安定した環境を前提にすることが多い:ステップ A を実行し、次に B、次に C。分散システムではその前提が常に破られます。コントローラーは冪等(何度実行しても安全)で、最終的整合性を持つため、目標が達成されるまで繰り返し試みます。
Deployment を使ったことがあれば、コントロールループを頼りにしています。内部では、要求された数の Pod が存在することを保証する ReplicaSet コントローラーと、ローリングアップデートやロールバックを予測可能に管理する Deployment コントローラーが動いています。
Kubernetes は“単一のコンテナだけ”をスケジュールすることもできましたが、Joe Beda のチームは Pod を導入しました。Pod はクラスターがマシンに配置する最小のデプロイ可能単位を表します。多くの実アプリは単一プロセスではなく、密に結びついた小さなプロセス群だからです。
Pod は同じ運命を共有する 1 つ以上のコンテナをラップします:一緒に開始し、同じノードで動き、スケールも一緒です。これにより サイドカー のようなパターンが自然に実現します—ログ送信、プロキシ、設定リロード、セキュリティエージェントなど、メインのアプリに常に付随すべき補助プロセスです。
補助プロセスを毎回アプリに組み込ませる代わりに、Kubernetes は別のコンテナとしてパッケージ化しつつも一つのユニットのように振る舞わせます。
Pod によって実用的になった重要な仮定が二つあります:
localhost 経由で通信でき、シンプルかつ高速です。\n- ストレージ: Pod 内のコンテナはボリュームを共有できます。補助が書いたファイルをメインが読めるなど、外部ホップが不要です。これらの選択はカスタムの接着コードの必要性を減らし、プロセスレベルでの分離を保ちました。
新規ユーザーは「1 コンテナ = 1 アプリ」と期待しがちで、Pod レベルの概念(再起動、IP、スケーリング)に戸惑います。多くのプラットフォームは意見を持ったテンプレート(例えば「web サービス」「worker」「job」)を提供して Pod を裏で生成し、サイドカーや共有リソースの利点を利用しつつ日常的に Pod の細部を考えなくて済むようにしています。
Kubernetes の静かに強力な選択肢の一つは、ラベルを一級のメタデータとして扱い、セレクターを“ものを見つける”手段の主流としたことです。固定的な関係(例:「この 3 台が私のアプリを動かす」)を埋め込む代わりに、共有属性でグループを記述することを奨励しました。
ラベルは Pod、Deployment、Node、Namespace などに付けられるシンプルな key/value ペアです。クエリ可能な「タグ」として機能します:
app=checkoutenv=prodtier=frontendラベルは軽量でユーザー定義できるため、チーム、コストセンター、コンプライアンス領域、リリースチャネルなど、組織の現実をモデル化できます。
セレクターはラベルに対するクエリです(例:「app=checkout かつ env=prod の全ての Pod」)。これにより、Pod が再スケジュール、スケール、置換されても、システムは適応できます。基盤となるインスタンスが常に変化しても設定は安定します。
この設計は運用面でスケールします:数千のインスタンスの識別子を管理する代わりに、いくつかの意味のあるラベルセットを管理します。これが疎結合の本質です:メンバーが変わっても安全に接続できる“グループ”へ接続します。
ラベルが存在すると、それはプラットフォーム全体の共通語彙になります。トラフィックルーティング(Services)、ポリシー境界(NetworkPolicy)、可観測性のフィルタ(メトリクス/ログ)、さらにはコスト追跡やチャージバックにも使えます。単純なアイデア—一貫してタグ付けする—が自動化のエコシステムを開きます。
Pod は置換され、再スケジュールされ、スケールアップ/ダウンします。したがって IP や実行するマシンは変わります。Service の核心的なアイデアはシンプルです:変化する Pod 群に対して安定した“入り口”を提供すること。
Service は一貫した仮想 IP と DNS 名(例:payments)を提供します。その名前の裏で Kubernetes は Service のセレクターに合致する Pod を継続的に追跡し、適切にルーティングします。Pod が死んで新しい Pod が現れても、アプリ側の設定を触る必要はありません。
このアプローチは多くの手動配線を取り除きました。IP を設定ファイルに埋め込む代わりに、アプリは名前に依存できます。アプリをデプロイして Service をデプロイすれば、他のコンポーネントは DNS 経由で見つけられます—カスタムレジストリやハードコーディングは不要です。
Service は健全なエンドポイント間でのデフォルトの負荷分散も導入しました。これにより各内部マイクロサービスごとにロードバランサを構築する必要が減り、単一 Pod の故障の影響範囲を減らし、ローリングアップデートをより安全にします。
Service は L4(TCP/UDP)トラフィックには向いていますが、HTTP のルーティング規則、TLS 終端、エッジポリシーまではモデル化しません。そこを扱うのが Ingress や近年では Gateway API です:Service の上にホスト名・パス・外部エントリポイントをきれいに扱う層を提供します。
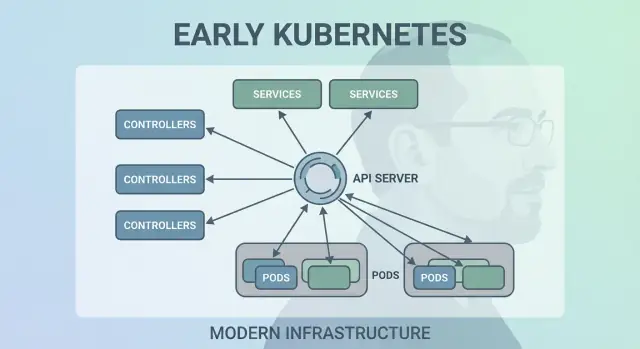
初期の静かに急進的な選択の一つは、Kubernetes を“操作するモノ”ではなく「対話するための API」として扱ったことでした。その API ファーストの姿勢は、Kubernetes を単なるクリックする製品ではなく拡張・スクリプト化・統治できるプラットフォームにしました。
API が表面であると、プラットフォームチームはどの UI、パイプライン、または内部ポータルが上に乗っていても、アプリの記述と管理の方法を標準化できます。「アプリをデプロイする」は「API オブジェクト(Deployment、Service、ConfigMap など)を送信・更新する」ことになり、アプリチームとプラットフォームの間の契約が明確になります。
すべてが同じ API を通るので、新しいツールは特別なバックドアを必要としません。ダッシュボード、GitOps コントローラー、ポリシーエンジン、CI/CD システムは適切にスコープされた権限で通常の API クライアントとして動けます。
その対称性は重要です:要求が人間から来たのかスクリプトから来たのか内部ポータルから来たのかに関わらず、同じルール、認可、監査、Admission の仕組みが適用されます。
API のバージョニングにより、Kubernetes を一夜にして壊すことなく進化させることが可能になりました。非推奨は段階的に行え、互換性はテストされ、アップグレードは計画的に実施できます。長期間クラスタを運用する組織にとって、これが「アップグレードできる」と「詰まる」の差です。
kubectl が示すことkubectl は Kubernetes 自体ではなく—それは一つのクライアントです。こうした心構えは、ツールを kubectl からオートメーション、Web UI、カスタムポータルに差し替えても、契約が API であるためシステムの一貫性が保たれることを示しています。
Kubernetes はクラスタが今どのようであるべきか—どの Pod が存在し、どのノードが健全で、どの Service がどこを指すか、どのオブジェクトが更新中か—の単一の“真実の源”を必要としました。それが etcd です。
etcd はコントロールプレーンのデータベースです。 Deployment を作成したり ReplicaSet をスケールしたり Service を更新したりすると、望ましい設定は etcd に書き込まれます。コントローラーや他のコントロールプレーンコンポーネントはその保存された状態をウォッチして、現実を一致させようと働きます。
Kubernetes クラスタは動く部品が多くあります:スケジューラ、コントローラー、kubelet、オートスケーラ、Admission チェックなどが同時に反応します。もし各コンポーネントが異なる“真実”を参照していると、レースが起きます—例えば二つのコンポーネントが同じ Pod について相反する決定を下すといった具合です。
etcd の強い整合性は、コントロールプレーンが「これが現在の状態だ」と言ったときに全員が揃っていることを保証します。その揃いがコントロールループを予測可能にし、混沌ではなくします。
etcd がクラスタの設定と変更履歴を保持しているため、次の場面で保護対象になります:
コントロールプレーンの状態を重要データとして扱ってください。定期的に etcd スナップショット を取り、復元をテストし、バックアップをクラスタ外に保管します。マネージド Kubernetes を使う場合はプロバイダが何をバックアップしてくれるか、また自前で保護すべきもの(永続ボリュームやアプリデータなど)を把握してください。
Kubernetes は「ワークロードがどこで動くか」を後回しにしませんでした。初期からスケジューラは独立したコンポーネントであり、Pod を実際に実行できるノードとマッチさせる明確な仕事を持っていました。
大まかにはスケジューリングは二段階です:
この構造により、スケジューリングを全体を書き直さずに進化させることが可能になりました。
重要な設計選択は責務を分けたことです:
これらの関心事が分離されているため、ある領域の改良(例:新しい CNI プラグイン)がスケジューラのモデルを強制的に書き換えることはありません。
リソース認識は requests と limits から始まり、スケジューラに有意義なシグナルを与えました。そこから豊かな制御(node affinity/anti-affinity、pod affinity、priorities と preemption、taints と tolerations、トポロジー意識のスプレッディング)が同じ基盤の上に積み上がりました。
このアプローチにより共有クラスタが可能となりました:重要サービスを優先度と taint で隔離しつつ、全員が高い利用率の恩恵を受けられます。より良い bin-packing とトポロジー制御により、信頼性を犠牲にせずによりコスト効率の良い配置が可能です。
Kubernetes はビルドパック、アプリルーティング、バックグラウンドジョブ、設定慣習などをすべて最初から備えた意見強めの PaaS として出すこともできました。しかし Joe Beda と初期チームはコアをより小さな約束(ワークロードを確実に実行し回復させ、それらを公開し、一貫した API を提供する)に絞りました。
“完全な PaaS” は一つのワークフローとトレードオフをすべての人に押し付けることになります。Kubernetes は幅広い基盤を目指し、Heroku 的な開発者向けの簡潔さ、エンタープライズの統治、バッチや機械学習パイプライン、あるいはインフラの細かな制御など、さまざまなプラットフォームスタイルをサポートできるようにしました。
Kubernetes の拡張メカニズムは機能を安全に成長させる道を作りました:
Certificate や Database)を追加できる。\n- コントローラー/オペレーター でそれらのリソースを望ましい状態パターンで調整できる。\n- Admission controller / webhook でポリシーを強制し、API 境界でデフォルトを付与できる。これにより内部プラットフォームチームやベンダーはアドオンとして機能を提供でき、RBAC、Namespace、監査ログなど Kubernetes のプリミティブをそのまま活用できます。
ベンダーにとってはフォークせずに差別化製品を提供でき、内部チームにとっては組織ニーズに合わせた「Kubernetes 上のプラットフォーム」を作れる利点があります。
リスクはエコシステムの氾濫です:CRD が多すぎる、重複するツール、慣習の不一致。ガバナンス(標準、所有権、バージョニング、非推奨ルール)がプラットフォーム作業の一部になります。
Kubernetes の初期の選択は単なるコンテナスケジューラを作っただけではなく、再利用可能な“プラットフォームカーネル”を作りました。だから多くの内部開発者向けプラットフォーム(IDP)は本質的に「Kubernetes + 意見を持ったワークフロー」です。宣言型モデル、コントローラー、そして一貫した API により、高レベルの製品を構築できるようになり、デプロイ、再調整、サービス発見を毎回再発明する必要がなくなりました。
API が製品表面であるため、ベンダーやプラットフォームチームは一つのコントロールプレーンを標準化し、その上に異なる体験を作れます:GitOps、マルチクラスタ管理、ポリシー、サービスカタログ、デプロイ自動化など。多くの統合が API を標的にしており、特定の UI をターゲットにしているわけではない、という点が Kubernetes がクラウドネイティブプラットフォームの共通分母になった大きな理由です。
抽象がきれいでも、最も困難な作業は依然として運用です:
運用の成熟度を明らかにする質問を投げてください:
良いプラットフォームは基盤のコントロールプレーンを隠しすぎず、抜け穴(escape hatch)を苦痛にしないで認知負荷を下げます。
実践的な視点:プラットフォームはチームが「アイデア → 実行サービス」に移るのを手助けするべきで、初日に全員を Kubernetes エキスパートにすることを強制しないかが重要です。Koder.ai のようなツールはチャットから実際のアプリ(React の Web、Go バックエンド + PostgreSQL、Flutter モバイルなど)を生成してスナップショットやロールバックを提供し、素早く反復できるようにすることで“作る側”の速度を上げる取り組みの一例です。どのツールを採用しても、目標は同じです:Kubernetes の強力なプリミティブを維持しつつ、それらの周りのワークフロー負荷を減らすことです。
Kubernetes は複雑に感じることがありますが、その“奇妙さ”の多くは意図的です:多様なプラットフォームを構成するために組み合わせ可能な小さなプリミティブの集合なのです。
まず:「Kubernetes はただの Docker のオーケストレーションだ」 は違います。Kubernetes は主にコンテナを起動することではなく、障害、ロールアウト、変わる需要の中で「望ましい状態」と「実際の状態」を継続して照合することにあります。
次に:「Kubernetes を使えばすべてがマイクロサービスになる」 というのも誤りです。Kubernetes はマイクロサービスをサポートしますが、モノリス、バッチジョブ、内部プラットフォームもサポートします。単位(Pods、Services、ラベル、コントローラー、API)は中立的であり、アーキテクチャの選択をツールが強制するわけではありません。
難しいのは通常 YAML や Pod ではなく、ネットワーキング、セキュリティ、複数チームの利用 に関わる事柄です:アイデンティティとアクセス管理、シークレット管理、ポリシー、Ingress、可観測性、サプライチェーン制御、チームが安全にデプロイできるようにするためのガードレール作りなど。
計画する際は初期の設計判断を次のように考えてください:
あなたの実際の要件を Kubernetes のプリミティブとプラットフォームレイヤーにマッピングしてください:
ワークロード → Pods / Deployments / Jobs
接続 → Services / Ingress
運用 → コントローラー、ポリシー、可観測性
評価や標準化を行うなら、このマッピングを書き出して関係者とレビューし、トレンドではなくギャップに基づいて段階的にプラットフォームを構築してください。
もし“作る”側の速度を上げたいなら、デリバリーワークフローがどのように意図をデプロイ可能なサービスに変えるかを検討してください。チームによってはキュレートされたテンプレートの集合で足りるかもしれませんし、別のチームは Koder.ai のような AI 支援ワークフローで初期の動作するサービスを素早く生成してからカスタマイズするという選択をするかもしれません。どちらにせよ、下層では Kubernetes の設計判断が効いています。
コンテナオーケストレーションは、マシンの障害、トラフィック変動、デプロイ発生時にアプリを動かし続けるための自動化です。実際には以下を扱います:
Kubernetes はこれを異なるインフラ環境で一貫して行うモデルを広めました。
主な問題はコンテナを起動することではなく、継続的な雑音の中で「正しい」コンテナを「正しい形」で動かし続けることでした。大規模化すると次のような事態が常態化します:
Kubernetes は標準のコントロールプレーンと共通語彙を提供することで、運用を再現可能かつ予測可能にすることを目指しました。
宣言型システムでは、あなたは達成したい“結果”を記述します(例:"レプリカを3つ実行する")。システムは継続的に実際の状態と照らし合わせて一致させようとします。
実際のワークフロー:
kubectl apply や GitOps)これにより“頭の中にある運用手順”が減り、変更は一連の ad-hoc コマンドではなく差分としてレビューできるようになります。
コントローラーは次のような反復ループ(control loop)です:
この設計により一般的な障害は特別扱いではなく“状態の不一致”として定常的に処理されます。例えば、Pod がクラッシュしたりノードが消えたりすると、関連するコントローラーは「望ましいレプリカ数に足りない」と認識して置き換えを作成します。
Kubernetes は“Pod”をスケジューリング単位とします。多くの実アプリケーションは単一プロセスではなく、密に連携する小さなプロセス群であるためです。
Pod が可能にするパターン:
localhost で通信可能)経験則:ライフサイクルやネットワーク ID、ローカルデータを共有する必要があるコンテナだけを同じ Pod にまとめるべきです。
ラベルは軽量な key/value タグ(例:app=checkout, env=prod)で、セレクターはそのラベルに対するクエリです。インスタンスがエフェメラル(頻繁に入れ替わる)であっても、ラベルとセレクターによって“属性でグループ化する”ことで関係性を安定させられます。
運用のヒント:小さなラベル体系(app、team、env、tier)を標準化し、ポリシーで強制すると後で混乱が減ります。
Service は変化する Pod 群への安定した“表玄関”を提供します。Service は仮想 IP と DNS 名を持ち、マッチする Pod を継続的に追跡してトラフィックをルーティングします。
Service を使うべきとき:
HTTP のルーティングや TLS 終端、外部入口は通常 Service の上に Ingress や Gateway API を重ねて扱います。
Kubernetes は API を製品表面(product surface)として扱います。すべてが API オブジェクト(Deployment、Service、ConfigMap など)として表され、kubectl はその API クライアントの一つに過ぎません。
実用的な利点:
内部プラットフォームを作るなら、特定の UI ではなく API 契約を中心にワークフローを設計してください。
etcd はコントロールプレーンのデータベースであり、クラスタの“現在あるべき姿”のソースオブトゥルースです。Deployment を作成したり Service を更新したりすると、その望ましい構成は etcd に書き込まれ、コントローラーがそれを見て現実を一致させようとします。
実務的な注意点:
マネージド Kubernetes を使う場合は、プロバイダが何をバックアップしてくれるかを確認し、永続ボリュームやアプリデータなど自分で守るべきものを把握してください。
Kubernetes はコアを小さく保ち、機能を拡張で追加できるようにしました:
これにより組織ごとのプラットフォーム機能を安全に追加できますが、ツールの氾濫(CRD が多すぎる、重複するツール、慣習の不一致)というリスクも伴います。評価時には標準の Kubernetes と独自拡張の境界、アップグレードとロールバック方針、ガードレールの有無、Day-2 運用の責任範囲を確認してください。