2025年10月11日·1 分
Kafka のイベントストリーミング:キューが向くときとログが有利なとき
Kafka のイベントストリーミングはイベントを順序付きログとして扱うことで設計を変えます。いつシンプルなキューで十分か、いつログが有利かを解説します。
Kafka のイベントストリーミングはイベントを順序付きログとして扱うことで設計を変えます。いつシンプルなキューで十分か、いつログが有利かを解説します。
多くのプロダクトは、最初はシンプルなポイントツーポイント統合で始まります。システムAがシステムBを呼ぶ、あるいは小さなスクリプトがデータを別の場所にコピーする。プロダクトが成長し、チームが分かれ、接続の数が増えるまでそれで十分です。やがて、ちょっとしたフィールドやステータスの変更が依存関係の連鎖を通じて波及するため、すべての変更に複数のサービス間の調整が必要になります。
まず壊れるのはスピードです。新機能を追加するには複数の統合を更新し、いくつかのサービスを再デプロイし、古い振る舞いに依存しているものがないことを祈る必要があります。
次にデバッグがつらくなります。UIで何かがおかしいとき、基本的な問いに答えるのが難しい:何が起きたのか、どの順序で起きたのか、どのシステムが今見ている値を書いたのか?
欠けている要素はしばしば監査トレイルです。データが一方のデータベースから別のデータベースに直接プッシュされたり、その途中で変換されると履歴を失います。最終状態は見えても、その状態に至るイベントの順序は見えません。インシデントレビューやカスタマーサポートは、過去を再生して何がどう変わったかを確認できないため苦しみます。
ここで「誰が真実を持つか」の議論が始まります。あるチームは「請求サービスが真実の源だ」と言い、別のチームは「注文サービスだ」と言います。実際には各システムが部分的な見解を持っており、ポイントツーポイントの統合はその不一致を日常の摩擦に変えます。
単純な例を挙げると:注文が作られ、支払いされ、返金される。3つのシステムが直接お互いを更新すると、リトライやタイムアウト、手動修正があるとそれぞれ異なる話が残ることがあります。
ここから生まれる設計上の核心的な問いが Kafka のイベントストリーミングの背後にあります:単に仕事を別の場所に移動させたいだけか(キュー)、それとも多くのシステムが読み、巻き戻し、信頼できる共有の永続的な記録が必要か(ログ)?答えによって作り方、デバッグの仕方、進化のさせ方が変わります。
Jay Kreps は Kafka の形成に寄与し、それ以上に多くのチームがデータ移動を考える方法に影響を与えました。有用な視点の転換は単純です:メッセージを一度きりの配達と見なすのをやめ、システムの活動を記録として扱い始めること。
核となる考え方はシンプルです。重要な変更を不変の事実のストリームとしてモデル化します:
各イベントは後から編集されるべきではない事実です。後で何かが変わったら、新しい真実を示すイベントを追加します。時間とともに、これらの事実が積み重なってログ、つまり追記のみの履歴が形成されます。
ここが Kafka のイベントストリーミングと多くの基本的なメッセージング設定との違いです。多くのキューは「送って、処理して、削除する」ことを前提に作られています。作業が純粋に引き渡しで済むならそれで問題ありません。ログの見方は「履歴を保持して、多くのコンシューマーが今も後でも使えるようにする」と言います。
履歴を再生できることは実用上の強力な機能です。
レポートが間違っていたら、同じイベント履歴を固定した分析ジョブに再実行してどこで数字が変わったかを確認できます。バグで誤ったメールが送られたなら、イベントをテスト環境に再生して正確なタイムラインを再現できます。新機能が過去のデータを必要とするなら、消費者を最初から動かして自分のペースで追いつかせることができます。
具体例として、すでに何ヶ月も支払いを処理している後に不正検知を追加するとします。支払いとアカウントのイベントのログがあれば、過去を再生して実際のシーケンスでルールを訓練・調整したり、古い取引のリスクスコアを算出して「fraud_review_requested」イベントをバックフィルできます。データベースを書き換える必要はありません。
これが強制することに注目してください。ログベースのアプローチはイベント名を明確にし、安定させることを促します。また、多くのチームやサービスがそれらに依存することを受け入れさせます。以下のような有益な問いも生まれます:真実の源は何か?このイベントは長期的に何を意味するか?ミスをしたときはどうするか?
価値は人物ではなく、共有ログがシステムの記憶になれるということを理解する点にあります。記憶があれば、新しいコンシューマーを追加してもシステムが壊れずに成長できます。
メッセージキューはソフトウェアのためのやることリストのようなものです。プロデューサーが仕事を列に入れ、コンシューマーが次のアイテムを取り出して仕事をし、そのアイテムは消えます。システムの主眼は各タスクをできるだけ早く一度だけ処理することにあります。
ログは違います。ログは起きた事実の順序付けられた記録で、耐久的に保持されます。コンシューマーはイベントを「取り去る」わけではありません。自分のペースで読み、後で再び読むことができます。Kafka のイベントストリーミングでは、そのログが中核の考え方です。
覚えやすい実用的な違い:
保持が設計を変えます。キューだと、後で古いメッセージに依存する新機能(分析、不正検知、バグ後の再生)が必要になると、別のデータベースを追加したり、コピーをどこかに保存し始めることが多いです。ログだと再生が普通です:最初から(または既知のチェックポイントから)読み直して派生ビューを再構築できます。
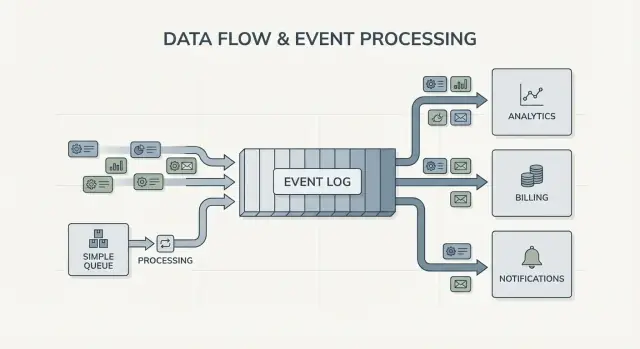
ファンアウトも大きな違いです。チェックアウトサービスが OrderPlaced を出すとします。キューでは通常どこか一つのワーカーグループに処理させるか、複数のキューに仕事を複製します。ログでは請求、メール、在庫、検索インデックス、分析が同じイベントストリームを独立して読むことができます。各チームは自分のペースで動け、新しいコンシューマーを追加してもプロデューサーを変更する必要はありません。
だから心的モデルは単純です:仕事を移動するならキューを使い、会社の複数箇所が今や将来に渡って読みたいイベントを記録するならログを使います。
イベントストリーミングはデフォルトの問いをひっくり返します。「このメッセージを誰に送るべきか?」と問う代わりに、「今何が起きた?」を記録することから始めます。小さな違いに聞こえますが、システムのモデル化方法を変えます。
OrderPlaced や PaymentFailed のような事実を公開し、システムの他の部分は反応するかどうか、いつ反応するか、どのように反応するかを決めます。
Kafka のイベントストリーミングがあると、プロデューサーは直接統合の一覧を必要としなくなります。チェックアウトサービスは一つのイベントを公開すればよく、それを分析、メール、不正チェック、将来のレコメンデーションが使うかどうか知らなくても構いません。新しいコンシューマーは後から現れ、古いものは一時停止でき、プロデューサーの振る舞いは変わりません。
これはミスからの回復方法も変えます。メッセージだけの世界では、コンシューマーが何かを見逃したりバグを起こしたりするとデータはしばしば「失われる」か、カスタムのバックアップを作っていない限り取り戻せません。ログがあればコードを直して履歴を再生し、正しい状態を再構築できます。多くの場合、信頼できない手作業のDB変更やワンオフのスクリプトよりもこちらの方が優れています。
実務では、この転換は次のような変化として現れます:イベントを耐久的な記録として扱う、プロデューサーを修正する代わりに購読して機能を追加する、読み取りモデル(検索インデックス、ダッシュボード)をスクラッチから再構築できる、サービス間の何が起きたかのタイムラインが明確になる。
可観測性も向上します。イベントログが共通の参照になると、何かが壊れたときにビジネスの順序(注文作成、在庫確保、支払いリトライ、発送予定)に沿って追うことができます。ビジネス事実に集中しているため、散在するアプリケーションログより理解しやすいことが多いです。
具体例:2時間にわたる割引バグで注文の価格が誤っていたとします。修正を出し、影響を受けたイベントを再生して合計を再計算し、請求書を更新し、分析を刷新できます。これにより、どのテーブルを手作業で修正するかを推測するのではなく、派生結果を再計算して修正を行います。
仕事を移動することで十分で、長期的な記録を作る必要がないならシンプルなキューが適切です。目的は作業をワーカーに手渡して実行させ、終わったら忘れることです。過去を再生する必要がなく、古いイベントを検査したり新しいコンシューマーを後から追加したりしないならキューの方がシンプルです。
キューはバックグラウンドジョブに向きます:サインアップメールの送信、アップロード後の画像リサイズ、夜間レポートの生成、遅い外部APIの呼び出しなど。これらではメッセージは単なる作業チケットです。ワーカーが仕事を終えればチケットの役目も終わります。
キューは通常のオーナーシップモデルにも合います:一つのコンシューマーグループが仕事を担当し、他のサービスは同じメッセージを独立して読むことを期待されません。
次の条件が大半当てはまるならキューで十分です:
例:ユーザーの写真をアップロードするプロダクト。アプリは「画像をリサイズする」タスクをキューに書き込み、ワーカーAがそれを拾ってサムネイルを作り、保存してタスクを完了とマークする。タスクが二度実行されても出力は同じ(冪等)なので、at-least-once 配信で問題ない。他のサービスがそのタスクを後で読む必要はない。
ニーズが「共有された事実(多くのコンシューマー)」「リプレイ」「監査」「先週システムが何を信じていたか?」の方向に傾き始めたら、Kafka のイベントストリーミングやログベースのアプローチが有効になります。
イベントが一度きりのメッセージではなく共有の履歴になり始めたとき、ログベースのシステムは効果を発揮します。送って忘れるのではなく、多くのチームが自分のペースで読んだり再生したりできる順序付けられた記録を保持します。
最も明確なシグナルは複数のコンシューマーです。OrderPlaced のような単一イベントが請求、メール、不正検知、検索インデックス、分析に供給される場合、ログなら各コンシューマーが同じストリームを独立して読みます。カスタムのファンアウトパイプラインを構築したり、誰が最初にメッセージを受け取るかを調整したりする必要がありません。
もう一つの利点は「当時我々は何を知っていたか?」に答えられることです。顧客が請求を争う場合やレコメンデーションが誤っていた場合、追記のみの履歴があれば事実が到着した順に再生できます。これは単純なキューに後付けするのは難しい監査トレイルです。
また、新しい機能を古いものを書き換えずに追加できる実用的な方法も得られます。数ヶ月後に「配送状況」ページを追加するなら、新しいサービスは既存の履歴からサブスクライブして状態をバックフィルできます。上流の各チームにエクスポートを頼む必要はありません。
次のようなニーズが一つ以上当てはまるとき、ログベースは大抵価値を発揮します:
典型的なパターンは、注文とメールで始まったプロダクトが成長して、財務が収益レポートを欲しがり、プロダクトがファネルを見たがり、運用がライブダッシュボードを欲しがるケースです。新しいニーズごとにデータを別のパイプラインでコピーするとコストが急速に出てきます。共有のイベントログは、イベントの形が変わっても同じ信頼できるソースでチームが構築できるようにします。
キューとログのどちらにするかは、プロダクトの判断として扱うと分かりやすくなります。今週動くかどうかだけでなく、1年後に何が真であってほしいかから始めてください。
公開者と読者をマップする。今イベントを作るのは誰で、今読むのは誰かを書き出し、将来的にありそうな消費者(分析、検索インデックス、不正検知、通知)を追加します。多くのチームが同じイベントを独立して読む見込みがあるならログが合理的になります。
履歴を再読する必要があるかを問う。具体的に:バグ後の再生、バックフィル、異なる速度で読む消費者など。キューは一度渡すのに優れており、ログは再生できる記録が必要なときに優れます。
「完了」の定義を決める。あるワークフローでは完了は「ジョブが実行された」(メール送信、画像リサイズ)ことです。別のワークフローでは完了は「イベントが耐久的な事実になった」(注文が置かれた、支払いが承認された)ことです。耐久的な事実はログへ向かわせます。
配信期待と重複の扱いを決める。at-least-once 配信は一般的で、重複は起き得ます。重複が問題になるなら冪等性を計画してください:処理済みイベントIDの保存、ユニーク制約の利用、または繰り返しても安全な更新設計。
薄いスライスから始める。扱いやすい一つのイベントストリームを選び、そこから広げます。Kafka を選ぶなら最初のトピックを集中させ、イベント名を明確にし、無関係なイベントを混ぜないようにします。
具体例:OrderPlaced が将来配送、請求、サポート、分析に供給するなら、ログが各チームに自分のペースで読み、ミスがあれば再生できる利点を与えます。レシートメールだけが必要ならシンプルなキューで十分でしょう。
小さなオンラインストアを想像してください。最初は注文を受け取り、カードを課金し、配送リクエストを作るだけで十分です。最も簡単な実装はチェックアウト後の一つのバックグラウンドジョブ「process order」です。支払いAPIに問い合わせ、データベースの注文行を更新し、配送に連絡します。
そのキュースタイルは、ワークフローが一つで明確、消費者が一つだけで再試行やデッドレターで多くの障害を賄えるならよく機能します。
しかしストアが成長すると問題が出てきます。サポートは自動の「注文はどこ?」更新を欲し、財務は日次の収益数値を欲し、プロダクトチームは顧客向けメールを増やしたい。不正チェックは発送前に入るべきです。単一の「process order」ジョブだと同じワーカーを何度も編集して分岐を増やし、コアフローに新たなバグを招くことになります。
ログベースにすると、チェックアウトは小さな事実をイベントとして出し、各チームがそれに基づいて構築できます。典型的なイベントは:
OrderPlacedPaymentConfirmedItemShippedRefundIssued重要な変化は責任の所在です。チェックアウトサービスは OrderPlaced のオーナーです。決済サービスは PaymentConfirmed のオーナーです。配送は ItemShipped を所有します。後から新しいコンシューマーが現れてもプロデューサーを変える必要はありません:不正検知サービスは OrderPlaced と PaymentConfirmed を読んでリスクを評価し、メールサービスは領収書を送り、分析はファネルを作り、サポートツールはタイムラインを保持します。
ここで Kafka のイベントストリーミングが効きます:ログが履歴を保持するため、新しいコンシューマーは始めから(あるいは既知のポイントから)巻き戻して追いつけます。上流の各チームに別の webhook を依頼する必要はありません。
ログはデータベースを置き換えません。現在の状態(最新の注文ステータス、顧客レコード、在庫数、トランザクショナルルール)は引き続きデータベースが必要です。ログは変更の記録で、データベースは「今何が真か」を問い合わせる場所です。
イベントストリーミングはシステムをきれいに感じさせますが、いくつかの一般的なミスはメリットを消してしまいます。多くはイベントログを記録ではなく遠隔操作のコントローラのように扱う点から来ます。
頻出の罠は、イベントをコマンドとして書くことです。たとえば SendWelcomeEmail や ChargeCardNow のように。これだと消費者はプロデューサーの意図に強く結びついてしまいます。イベントは事実の方がよく機能します:UserSignedUp や PaymentAuthorized。事実は時間が経っても再利用しやすいです。
重複とリトライも大きな痛みの源です。現実のシステムではプロデューサーは再試行し、コンシューマーは再処理します。計画しないと二重請求や二重メール、クレームが発生します。解決は特別なものではありませんが意図的に行う必要があります:冪等ハンドラ、安定したイベントID、そして「既に適用済み」を検出するビジネスルール。
一般的な落とし穴:
スキーマとバージョニングは特別に注意が必要です。JSON で始めたとしても、必須フィールド、任意フィールド、変更のローアウト方法など明確な契約が必要です。フィールド名の変更のような小さな変更が分析や請求、モバイルアプリを静かに壊すことがあります。
もう一つの罠は過剰な分割です。チームが機能ごとにストリームを作りすぎると、月末に「注文の現在状態は何か?」に答えられなくなります。ストリーミングはデータモデルの必要性をなくしません。現在の真実を表す堅牢なデータベースは依然として必要です。ログは履歴であってアプリ全体ではありません。
キューと Kafka のイベントストリーミングで迷っているなら、いくつかの簡単なチェックから始めてください。これで、単純なワーカー間の受け渡しが必要か、長年使えるログが必要かが分かります。
もし「リプレイ不要」「消費者は1つ」「メッセージは短命」にすべて「はい」と答えるなら基本的なキューで十分です。もし「リプレイが必要」「複数の消費者」「長期保持」が一つでもあれば、ログベースのアプローチは一つの事実のストリームを他システムが拡張していくための共有ソースとして有効です。
答えを小さなテスト可能な計画に落とし込んでください。
orderId)と「正しい順序」が何を意味するか文書化する。プロトタイプを急ぐなら、Koder.ai の planning mode でイベントフローをスケッチして設計を繰り返し、イベント名やリトライルールを確定する前に実験できます。Koder.ai はソースコードのエクスポート、スナップショット、ロールバックをサポートするので、プロデューサー・コンシューマーの一片を試してイベント形状を調整し、本番負債を残さずに進められます。
キューは、処理されて忘れられる「作業チケット」に向いています(例:メール送信、画像リサイズ、ジョブ実行)。ログは、多くのシステムが後で読み返したり再生したりできる「事実」を保持するのに向いています(例:OrderPlaced、PaymentAuthorized、RefundIssued)。
新機能を追加するたびに複数の統合に手を入れる必要が出てきて、デバッグが「この値を誰が書いた?」という問いになったら手詰まりを感じます。ログは共通の記録になるため、点在するデータベース状態を推測する代わりに履歴を調べて再生できます。
監査トレイルやリプレイが必要なときに効果を発揮します:履歴を再処理してバグを修正する、古いデータから新機能をバックフィルする、当時の知見を調査する、あるいはプロデューサーを変えずに複数のコンシューマー(請求、分析、サポート、不正検知)をサポートしたい場合などです。
システムが成長すると、リトライやタイムアウト、手動修正などで状態が乱れやすくなります。サービス同士が直接更新し合うと、何が起きたかで意見が分かれるようになります。追記のみのイベント履歴は、たとえ一部の消費者が落ちていても整列した一連の順序を提供します。
イベントは過去形の不変の事実としてモデル化します。たとえば:
OrderPlaced(ProcessOrderではなく)PaymentAuthorized(ChargeCardNowではなく)UserEmailChanged(UpdateEmailではなく)何かが変わったら古いイベントを編集するのではなく、新しい事実を表すイベントを追加します。
重複は起きるものと仮定し(at-least-once 配信が一般的)、各コンシューマーをリトライに耐えるよう設計します。具体策:
優先順位の基本は:正確さが先、速度が後です。
追加的な変更を優先します:既存フィールドは残し、新しいフィールドをオプションで追加し、フィールド名の変更や削除は避けます。破壊的な変更が必要な場合は、イベント(またはトピック/ストリーム)にバージョンを付けて、消費者を段階的に移行します。
薄いエンドツーエンドのスライスから始めます:
OrderPlaced → 領収書メール)orderId や userId)ループが動くことを確認してから範囲を広げましょう。
いいえ。現在の状態(今何が真であるか)やトランザクションには引き続きデータベースが必要です。ログは履歴であり、派生ビュー(分析テーブル、検索インデックス、タイムライン)を再構築するために使います。実務上の分担は:DBはプロダクトの読み書き、ログは配布、再生、監査です。
Planning mode は公開者/購読者のマッピング、イベント名の定義、冪等性と保持期間の決定に便利です。小さなプロデューサー・コンシューマーのスライスを実装してスナップショットやロールバックで調整し、安定したらソースコードをエクスポートして運用に移せます。