2025年9月22日·1 分
Kafkaとは何か — 現代システムでの使われ方
Apache Kafkaとは何か、トピックとパーティションの仕組み、リアルタイムイベントやログ、データパイプラインにおけるKafkaの役割を学びます。
Apache Kafkaとは何か、トピックとパーティションの仕組み、リアルタイムイベントやログ、データパイプラインにおけるKafkaの役割を学びます。
Apache Kafkaは分散型のイベントストリーミングプラットフォームです。簡単に言えば、多くのシステムが「何が起きたか」という事実を公開でき、他のシステムがそれらを素早く、大規模に、順序を保って読み取れる共有される耐久的な“パイプ”です。
チームはデータをシステム間で確実に移動させたいときにKafkaを使います。あるアプリケーションが別のアプリケーションを直接呼び出して(相手が落ちていたり遅かったりすると失敗する)連携する代わりに、プロデューサーがイベントをKafkaに書き込みます。コンシューマーは準備ができたときにそれを読みます。Kafkaはイベントを設定可能な期間保存するので、障害からの回復や履歴の再処理が可能です。
このガイドはプロダクト志向のエンジニア、データ担当者、技術リーダー向けで、Kafkaの実践的なメンタルモデルを提供します。
中核的な構成要素(プロデューサー、コンシューマー、トピック、ブローカー)、パーティションによるスケールの仕組み、イベントの保存と再生方法、イベント駆動アーキテクチャにおける位置づけを学べます。さらに、一般的なユースケース、配信保証、安全性の基本、運用計画、Kafkaが適している場合・適していない場合についても触れます。
Kafkaは共有イベントログとして理解すると最も分かりやすいです:アプリケーションがイベントを書き込み、別のアプリケーションがそれらのイベントを後で(多くはリアルタイムに、時には数時間や数日後に)読み取ります。
プロデューサーは書き手です。プロデューサーは “order placed”、 “payment confirmed”、 “temperature reading” のようなイベントを公開します。プロデューサーは特定のアプリに直接イベントを送るのではなく、Kafkaに送ります。
コンシューマーは読み手です。ダッシュボードの更新、発送ワークフローの起動、分析へのデータロードなどを担います。コンシューマーはイベントの扱いを決め、自分のペースで読みます。
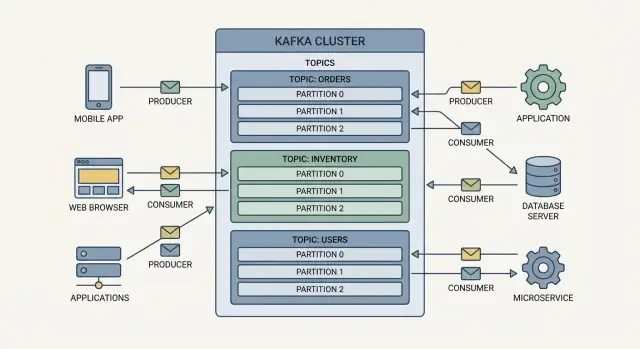
Kafkaのイベントはトピックにグループ化され、これは名前付きのカテゴリです。例えば:
orders(注文関連イベント)payments(支払いイベント)inventory(在庫変化)トピックはその種のイベントの「事実のソース(source of truth)」となり、複数チームがワンオフの連携を作らずに同じデータを再利用しやすくなります。
ブローカーはイベントを保存してコンシューマーに提供するKafkaサーバーです。実運用ではKafkaはクラスター(複数のブローカーで構成)として動き、より多くのトラフィックを扱い、マシンが故障しても稼働し続けられるようにします。
コンシューマーはしばしばコンシューマーグループで動きます。Kafkaはグループ内で読み取り作業を分散するため、コンシューマーのインスタンスを増やすことで処理を横にスケールできます—ただし各インスタンスが同じ作業を全部やるわけではありません。
Kafkaはまずトピック(関連イベントのストリーム)で仕事を分け、それぞれのトピックをさらにパーティション(そのストリームの小さい独立したスライス)に分けることでスケールします。
パーティションが1つのトピックは、コンシューマーグループ内で同時に1つのコンシューマーしか読めません。パーティションを増やせば、イベントを並列で処理するコンシューマーを増やせます。これがKafkaが大量のイベントストリーミングやリアルタイムデータパイプラインを支え、各システムがボトルネックになるのを防ぐ方法です。
パーティションはまた負荷をブローカー間に分散します。あるトピックのすべての読み書きを1台のマシンが処理するのではなく、複数のブローカーが異なるパーティションをホストしてトラフィックを分担します。
Kafkaは単一パーティション内の順序を保証します。イベントA、B、Cが同一パーティションにその順で書き込まれたら、コンシューマーはA → B → Cの順に読みます。
パーティション間の順序は保証されません。特定のエンティティ(顧客や注文など)で厳密な順序が必要な場合は、そのエンティティに関するすべてのイベントを同じパーティションに送るようにします。
プロデューサーがイベントを送るとき、キー(例:order_id)を含めることができます。Kafkaはキーを使って関連イベントを同じパーティションに一貫してルーティングします。これにより、そのキーに関して予測可能な順序が得られ、同時にトピック全体を多くのパーティションに分散してスケールできます。
各パーティションは他のブローカーにレプリケートできます。あるブローカーが故障した場合、レプリカを持つ別のブローカーが引き継げます。レプリケーションはKafkaがミッションクリティカルなPub/Subメッセージングやイベント駆動システムで信頼される大きな理由の一つで、可用性を改善し、各アプリが独自にフェイルオーバーロジックを構築する必要を減らします。
Apache Kafkaの重要な考え方は、イベントが単に渡されて終わるのではなく、ディスクに順序どおり書き込まれ、コンシューマーがそれを今読むことも後で読むこともできる点です。これによりKafkaはデータの移動だけでなく、何が起きたかの耐久的履歴を保持する役割も果たします。
プロデューサーがトピックにイベントを送ると、Kafkaはそれをブローカーのストレージに追記します。コンシューマーは保存されたログを自分のペースで読みます。コンシューマーが1時間ダウンしてもイベントは残っていて、復帰後に追いつくことができます。
Kafkaは保持ポリシーに従ってイベントを保持します:
保持はトピックごとに設定できるため、監査用トピックは高ボリュームなテレメトリとは別に扱えます。
一部のトピックは履歴アーカイブというよりチェンジログに近いものです(例:「現在の顧客設定」)。ログコンパクションは各キーについて少なくとも最新のイベントを残し、古く上書きされた記録を削除します。これにより最新状態の耐久的なソースを保持しつつ無制限の成長を抑えられます。
イベントが保存されているため、再生して状態を再構築できます:
実際には、再生はコンシューマーがどこから読み始めるか(オフセット)で制御され、システムが進化する際の強力な安全網になります。
Kafkaはシステムの一部が故障してもデータフローを保つように設計されています。これを実現するのがレプリケーション、各パーティションの「責任者」を決める仕組み、そして設定可能な**書き込み確認(acks)**です。
各トピックパーティションには1つのリーダーブローカーと1つ以上のフォロワーレプリカがあります。プロデューサーとコンシューマーはそのパーティションのリーダーと通信します。
フォロワーはリーダーのデータを継続的にコピーします。リーダーがダウンした場合、Kafkaは最新のフォロワーをプロモートして新しいリーダーにできるため、パーティションの可用性が保たれます。
ブローカーが故障すると、そのブローカーがリーダーを務めていたパーティションは一時的に利用不可になります。Kafkaのコントローラーが故障を検知してそのパーティションのリーダー選出をトリガーします。
十分に追いついているフォロワーがいれば引き継ぎが行われ、クライアントは読み書きを再開できます。同期済みレプリカがない場合、設定次第でKafkaは書き込みを停止して、確認済みデータの喪失を避けることがあります。
耐久性を左右する主な設定は:
概念的には:
重複を減らすために、チームはしばしば安全寄りのacksに冪等プロデューサーと堅牢なコンシューマー処理を組み合わせます。
より高い安全性は一般に多くの確認を待ち、より多くのレプリカを同期させる必要があるため、レイテンシーを増やしピークスループットを下げることがあります。
低レイテンシーの設定は、まれなデータ損失が許容されるテレメトリやクリックストリームには問題ない場合がありますが、支払い、在庫、監査ログでは通常より安全な設定が優先されます。
イベント駆動アーキテクチャ(EDA)は、ビジネス内で起きる出来事(注文が行われた、支払いが確定した、荷物が発送された)を他の部分が反応するイベントとして表現する設計手法です。
Kafkaは共有された「イベントストリーム」としてEDAの中心に置かれることが多いです。サービスAがサービスBを直接呼び出す代わりに、サービスAはKafkaのトピックにOrderCreatedのようなイベントを公開します。複数のサービスがそのイベントを消費してメール送信や在庫確保、詐欺チェックを開始でき、サービスAはそれらの存在を知らなくて済みます。
サービス間の通信がイベントを介して行われるため、すべてのやり取りに対してリクエスト/レスポンスAPIを調整する必要がありません。これによりチーム間の密結合が減り、新しい機能を追加するのが容易になります:既存のイベントを消費する新しいコンシューマーを導入するだけで済みます。
EDAは本質的に非同期です:プロデューサーは素早くイベントを書き込み、コンシューマーは自分のペースで処理します。トラフィックスパイク時には、Kafkaがバッファとなって下流システムが即座にダウンするのを防ぎます。コンシューマーはスケールアウトして追いつき、1つのコンシューマーが一時的にダウンしても、停止した位置から再開できます。
Kafkaをシステムの「アクティビティフィード」と考えてください。プロデューサーは事実を公開し、コンシューマーは自分が興味のある事実を購読します。このパターンは、リアルタイムデータパイプラインやイベント駆動ワークフローを可能にしつつ、サービスをよりシンプルで独立したものに保ちます。
Kafkaは多くの小さな「起きた事実」をシステム間で迅速かつ確実に、そして複数のコンシューマーが再利用できる形で移動する必要がある場面で利用されます。
アプリはしばしば追記専用の履歴を必要とします:ユーザーのサインイン、権限変更、レコード更新、管理者操作など。Kafkaはこれらのイベントの中央ストリームとして機能し、セキュリティツール、レポーティング、コンプライアンス出力が同じソースを読み取れるようにします。イベントは一定期間保持されるため、バグやスキーマ変更後に監査ビューを再構築するために再生できます。
サービスが直接呼び出し合う代わりに、"order created" や "payment received" のようなイベントを公開します。他のサービスはそれらを購読して自分のタイミングで反応します。これにより密結合が減り、部分的な障害時でもシステムが動き続け、新しい機能(例:詐欺検出)を既存イベントを消費するだけで追加できます。
Kafkaは運用システムから分析プラットフォームへデータを移動するバックボーンとしてよく使われます。アプリケーションデータベースの変更をストリームし、遅延を小さく保ってデータウェアハウスやデータレイクに届けられます。これにより本番アプリを重たい分析クエリから切り離せます。
センサーやデバイス、アプリのテレメトリはしばしばスパイクで到着します。Kafkaはバーストを吸収して安全にバッファリングし、下流処理が追いつけるようにします—監視、アラート、長期分析に有用です。
Kafkaはブローカーとトピックだけではありません。ほとんどのチームは日常的なデータ移動、ストリーム処理、運用を実用化する補助ツールに依存します。
Kafka ConnectはデータをKafkaへ取り込む(ソース)/**Kafkaから出す(シンク)**ための統合フレームワークです。ワンオフのパイプラインを作る代わりにConnectを走らせてコネクタを設定します。
典型例はデータベースからの変更取り込み、SaaSイベントの取り込み、Kafkaデータのデータウェアハウスやオブジェクトストレージへの配信です。Connectはリトライ、オフセット、並列処理といった運用面も標準化します。
Connectが統合向けなら、Kafka Streamsは計算向けです。これをアプリに組み込んでストリームをリアルタイムに変換します—フィルタ、エンリッチ、ストリーム同士の結合、集計(例:「1分あたりの注文数」)など。
Streamsアプリはトピックから読み取りトピックへ書き戻すため、イベント駆動システムに自然に馴染み、インスタンスを増やすことでスケールできます。
複数チームがイベントを公開する場合、一貫性が重要です。スキーマ管理(多くはスキーマレジストリ経由)はイベントが持つべきフィールドとその進化方法を定義します。これにより、プロデューサーがフィールド名を変えてコンシューマーを壊すような事故を防げます。
Kafkaは運用上センシティブなので基本的な監視が不可欠です:
ほとんどのチームは管理UIやデプロイ自動化、トピック設定、アクセス制御ポリシー適用(参照:/blog/kafka-security-governance)を使います。
Kafkaはよく「耐久的ログ+コンシューマー」と表現されますが、現実にチームが気にするのは「各イベントを一度だけ処理できるか、障害時にどうなるか」です。Kafkaは構成要素を提供し、あなたがトレードオフを選びます。
**at-most-once(最大一度)**はイベントを失う可能性があるが重複は発生しない。これはコンシューマーが位置を先にコミットしてから作業中にクラッシュすると起きます。
**at-least-once(少なくとも一度)**はイベントを失わないが重複が起きる可能性がある(処理後にクラッシュし再処理される等)。これは最も一般的なデフォルトです。
**exactly-once(正確に一度)**は喪失も重複も避けることを目指します。Kafkaでは通常トランザクション対応のプロデューサーと互換性のある処理(多くはKafka Streams)を組み合わせて実現しますが、制約があり慎重な設定が必要です。
実務では多くのシステムがat-least-onceを受け入れ、次のような保護を追加します:
コンシューマーのオフセットはパーティション内の最後に処理したレコードの位置です。オフセットをコミットすることで「ここまで処理済み」と宣言します。コミットが早すぎると喪失のリスク、遅すぎると障害後の重複が増えます。
リトライは上限を設け可視化すべきです。一般的なパターン:
これにより1件の「毒メッセージ」がコンシューマーグループ全体をブロックするのを防ぎつつ、データは保存されます。
Kafkaは注文、支払い、ユーザー活動といったビジネスクリティカルなイベントを扱うことがあるため、セキュリティとガバナンスは設計段階から考えるべきです。
認証は「あなたは誰か?」を、認可は「何ができるか?」を答えます。KafkaではSASL(例:SCRAMやKerberos)で認証を行い、ACL(アクセス制御リスト)でトピック、コンシューマーグループ、クラスター単位の認可を強制するのが一般的です。
実務的なパターンは最小特権:プロデューサーは自分が書くトピックだけに書け、コンシューマーは必要なトピックだけを読めるようにします。これにより資格情報漏えい時の被害範囲を限定できます。
TLSはアプリ、ブローカー、ツール間で移動するデータを暗号化します。TLSがないと、内部ネットワーク上でもイベントが傍受される恐れがあります。TLSはブローカーの識別を検証して中間者攻撃も防ぎます。
複数チームがクラスタを共有する場合はガードレールが重要です。明確なトピック命名規約(例:<team>.<domain>.<event>.<version>)は所有権を明示し、ポリシー適用の助けになります。
命名規約と併せてクォータやACLテンプレートを用意して、あるノイジーなワークロードが他を圧迫しないようにし、新しいサービスが安全なデフォルトで開始できるようにします。
Kafkaをイベント履歴のシステムオブレコードとして扱うのは意図がある場合に限るべきです。イベントにPIIが含まれる場合はデータ最小化(完全なプロファイルではなくIDを送る)、フィールドレベルの暗号化、どのトピックが機密かを文書化することを検討してください。
保持設定は法務やビジネス要件に合わせるべきです。ポリシーが「30日後に削除」なら、6か月分を「念のため」保持してはいけません。定期的なレビューと監査で構成を整合させ続けましょう。
Apache Kafkaを運用するのは「インストールして放置」ではありません。多くのチームが依存する共有ユーティリティのように振る舞い、小さな失敗が下流に波及する可能性があります。
Kafkaのキャパシティは定期的に見直すべき算数の問題です。主なレバーはパーティション(並列性)、スループット(MB/sの入出力)、ストレージ成長(保持期間)です。
トラフィックが倍になれば、負荷をブローカーに分散するためにパーティションを増やし、保持のためのディスクを追加し、レプリケーションのための余裕を含めてネットワーク帯域を確保する必要が出てきます。実用的な習慣としてはピーク書き込み率を予測し、それに保持期間をかけてディスク成長を見積もり、予備を加えます。
サーバーを稼働させる以外にも次のようなルーチン作業があります:
コストはディスク、ネットワークの出力、ブローカー数/サイズにより決まります。マネージドKafkaは運用負荷を減らしアップグレードを簡素化できますが、セルフホストは熟練したオペレーターがいる場合に大規模で安くなることがあります。トレードオフは復旧時間とオンコール負担です。
チームは通常次を監視します:
良いダッシュボードとアラートはKafkaを“謎の箱”から理解可能なサービスに変えます。
Kafkaは大量のイベントを確実に移動し、一定期間保持し、複数のシステムが同じデータストリームに対して自分のペースで反応する必要があるときに適しています。バックフィル、監査、新サービスの再構築が必要な場合や、将来プロデューサー/コンシューマーが増える見込みがあるときに特に有用です。
Kafkaは次のような場合に輝きます:
ニーズがシンプルな場合、Kafkaは過剰になることがあります:
これらのケースではクラスタ設計、アップグレード、監視、オンコールといった運用オーバーヘッドが利益を上回る恐れがあります。
Kafkaはデータベース(記録のシステム)やキャッシュ(高速読み取り)、バッチETLツール(大規模な周期的変換)を置き換えるものではなく、補完するものとして使われます。
自問してください:
これらの多くに「はい」と答えられるなら、Kafkaは通常適切な選択です。
Kafkaは、多くのシステムが事実(注文作成、支払い承認、在庫変化)を発生させ、複数のシステムがそれらを消費してパイプライン、分析、リアクティブな機能を支える必要があるときに最も効果を発揮します。
最初は価値が高く範囲が狭いフローから始めます—例えば下流サービス(メール、詐欺チェック、フルフィルメント)のために「OrderPlaced」イベントを公開する、など。初日からKafkaを万能キューにしないこと。
次を明文化します:
初期スキーマはシンプルに保ち(タイムスタンプ、ID、明確なイベント名)、スキーマを最初から厳格に適用するか慎重に進化させるかを決めます。
Kafkaが成功するには誰かが次を所有する必要があります:
コンシューマーラグやブローカー健全性、スループット、エラー率の監視を早めに導入してください。プラットフォームチームがまだない場合はマネージド提供を使い、明確な制限を設けて始めるとよいでしょう。
あるシステムからイベントをプロデュースし、1か所で消費してループをエンドツーエンドで実証します。それから消費者数やパーティション、統合を増やしてください。
アイデアから動くイベント駆動サービスへ迅速に移るには、Koder.aiのようなツールがサポートになります(React UI、Goバックエンド、PostgreSQLなどの周辺アプリをプロトタイプ化)。チャット駆動のワークフローでプロデューサー/コンシューマーを追加しやすくし、内部ダッシュボードや軽量なトピック消費サービスの構築を加速します。プランニングモード、ソースコードエクスポート、デプロイ/ホスティング、スナップショットとロールバックの機能が特に便利です。
イベント駆動アプローチのマッピングについては /blog/event-driven-architecture を参照してください。コストと環境の見積もりは /pricing を確認してください。
Kafkaは耐久性のある追記型ログにイベントを保存する、分散型のイベントストリーミングプラットフォームです。
プロデューサーはイベントをトピックに書き込み、コンシューマーはそれを独立して読みます(多くの場合リアルタイム、あるいはあとで)。
複数のシステムが同じイベントストリームを必要とし、疎結合を求め、履歴を再処理する可能性があるときにKafkaを使います。
特に次の用途に有用です:
トピックはイベントの名前付きカテゴリ(例:ordersやpayments)。
パーティションはトピックを分割したスライスで、次を可能にします:
Kafkaは単一のパーティション内でのみ順序を保証します。
Kafkaはレコードのキー(例:order_id)を使って関連するイベントを一貫して同じパーティションにルーティングします。
実務上のルール:顧客や注文といったエンティティごとの厳密な順序が必要なら、そのエンティティを表すキーを選び、関連イベントが同一パーティションに入るようにします。
コンシューマーグループはトピックの処理を分担するコンシューマーの集合です。
グループ内では:
異なるアプリがそれぞれ全イベントを受け取りたい場合は、別々のコンシューマーグループを使います。
Kafkaはトピックごとのポリシーに基づいてディスク上にイベントを保持するため、コンシューマーはダウンから回復して追いついたり履歴を再処理できます。
一般的な保持方法:
高価値の監査ストリームは高ボリュームのテレメトリとは別に長めに設定できます。
ログ圧縮(log compaction)は各キーについて少なくとも最新のレコードを残し、古い上書きされたレコードを削除していきます。
「現在の状態」を扱うストリーム(設定やプロファイルなど)で、キーごとの最新値だけが重要な場合に、通常の保持より適しています。最新の状態の耐久的ソースを保持しつつ無制限の成長を抑えられます。
最もよく使われるエンドツーエンドのパターンは**少なくとも一度(at-least-once)**で、イベントは失われにくいが重複が発生する可能性があります。
安全に扱うために:
オフセットは各パーティションにおけるコンシューマーの「しおり」です。
オフセットを早くコミットしすぎるとクラッシュ時に作業を失う可能性があり、遅すぎると再処理で重複が増えます。
運用パターンとしては、再試行を限定してバックオフし、それでも失敗するレコードはデッドレター(死活)トピックに送ることで、1つの「毒データ」がコンシューマーグループ全体を停止させないようにします。
Kafka Connectはコネクタを使って外部データをKafkaに取り込み(ソース)たり、Kafkaから外部へ出力(シンク)したりする統合フレームワークです。カスタムコードを書かずにデータ移動を標準化できます。
Kafka Streamsはアプリ内でリアルタイムにストリームを変換・集計するためのライブラリです。トピックから読み取りトピックへ書き戻す処理に適しています。
実務上:Connectは統合用途、Streamsは計算用途に使います。