2025年5月06日·1 分
キャッシュ・セッション・高速ルックアップのためのキー・バリュー・ストア
キー・バリューストアがキャッシュ、ユーザーセッション、瞬時のルックアップをどう支えるかを解説します。TTL、エヴィクション、スケーリングの選択肢と実務上のトレードオフも紹介。
キー・バリューストアがキャッシュ、ユーザーセッション、瞬時のルックアップをどう支えるかを解説します。TTL、エヴィクション、スケーリングの選択肢と実務上のトレードオフも紹介。
キー・バリューストアの主目的はシンプルです:エンドユーザーの待ち時間を減らし、プライマリデータベースへの負荷を下げること。同じ高コストなクエリを繰り返したり同じ結果を再計算する代わりに、アプリは事前に計算した値を一回の予測可能なステップで取得できます。
キー・バリューストアは「このキーが与えられたら値を返す」という一つの操作に最適化されています。その狭い焦点により、非常に短いクリティカルパスが実現します。
多くのシステムでは、ルックアップは次のように処理されます:
結果として、低く一貫した応答時間が得られ、キャッシュ、セッションストレージ、その他の高速ルックアップに最適です。
よくチューニングされたDBでも、クエリのパース、プラン作成、インデックス読み取り、同時実行の調整が必要です。何千ものリクエストが同じ「トップ商品」リストを求めると、その繰り返し作業は大きな負荷になります。
キー・バリューキャッシュはその繰り返し読み取りトラフィックをDBからシフトします。DBは書き込み、複雑な結合、レポーティング、整合性が重要な読み取りに時間を割けるようになります。
速度は無料ではありません。キー・バリューストアは通常、リッチな問い合わせ(フィルタ、結合)を犠牲にし、永続性や整合性の保証も設定により異なります。
データを明確なキー(例:user:123、cart:abc)で名付けられ、素早く取り出したい場合に輝きます。一方で「Xを満たすすべてのアイテムを探す」ような頻繁な検索が必要なら、リレーショナルやドキュメントDBを一次ストアにする方が良いことが多いです。
キー・バリューストアは最も単純な種類のデータベースです:値(あるデータ)を一意のキー(ラベル)に保存し、後でそのキーを与えて値を取得します。
キーは正確に繰り返せる識別子、値は返したいものです。
キーは通常短い文字列(user:1234 や session:9f2a...)です。値は小さなカウンタや大きなJSONブロブまで様々です。
キー・バリューストアは「このキーの値をくれ」というクエリに作られています。内部的には多くがハッシュテーブルに似た構造を使い、キーを高速に見つけられる位置に変換します。
だからよく 定数時間のルックアップ(O(1))という言葉を聞きます:性能は総レコード数よりも行うリクエスト数に依存します。衝突やメモリ制限は影響しますが、典型的なキャッシュ/セッション用途では非常に速いです。
ホットデータは頻繁に要求される情報の小さな部分です(人気ページ、アクティブなセッション、レート制限カウンタなど)。ホットデータを特にインメモリのキー・バリューストアに置くと、遅いDBクエリを回避でき、負荷時の応答時間が予測可能になります。
キャッシュとは、元のソースよりも速く到達できる場所に頻繁に必要なデータのコピーを置くことです。キー・バリューストアはキーで一度のルックアップで値を返せるため、数ミリ秒で応答することが多く、キャッシュ先として一般的です。
同じ問いが何度も繰り返される場合にキャッシュは強力です:人気ページ、繰り返し行われる検索、頻繁なAPI呼び出し、高コストな計算など。主要DBが遅い場合や、リクエスト毎に料金が発生するサードパーティAPIのような場面でも役立ちます。
読み取りが多く、即時一貫性が不要な結果が良い候補です:
シンプルなルール:必要なら再生成できる出力をキャッシュする。常に一貫性が必要なデータ(銀行残高など)は避ける。
キャッシュが無ければ、ページ表示ごとに複数のDBクエリやAPI呼び出しが発生する可能性があります。キャッシュを使えば、多くのリクエストをキー・バリューストアでさばき、キャッシュミス時だけプライマリDBやAPIにフォールバックします。これによりクエリ数が下がり、接続競合が減り、トラフィック急増時の信頼性が向上します。
キャッシュは鮮度と速度をトレードします。キャッシュされた値が速やかに更新されなければユーザーは古い情報を見ることになり、分散システムでは短時間で異なるリクエストが異なるバージョンを読むことがあります。
これらは適切なTTLの選択、多少古くても許容できるデータの区別、キャッシュミスやリフレッシュ遅延を許容する設計で管理します。
キャッシュパターンはアプリがキャッシュに関与する読み書きの定型的ワークフローです。適切なパターンは、基になるデータの更新頻度や許容できる古さによって決まります。ツール(Redis、Memcached等)よりもパターン選定の方が重要です。
キャッシュアサイドではアプリがキャッシュを明示的に操作します:
適合例:読み取りが多く変更が少ないデータ(商品ページ、設定、公開プロフィール)。またデフォルトとして安全で、キャッシュが空でもDBから応答できるためフォールバックが容易です。
Read-through はミス時にキャッシュ層がDBから読み込む方式で、アプリコードはシンプルになりますがキャッシュ層にローダー統合が必要です。
Write-through は書き込みを同期的にキャッシュとDBに行います。読み取りは速く一貫しますが書き込みは遅くなります。
適合例:書き込みが少なく、より一貫した読み取りが望まれるデータ(ユーザー設定、機能フラグ)に向きます。
Write-back はアプリがまずキャッシュに書き、キャッシュが後で(バッチ等で)DBにフラッシュする方式です。
利点:非常に速い書き込みとDB負荷の低減。\nリスク:キャッシュノードがフラッシュ前に故障するとデータ喪失が発生する可能性があるため、損失を許容できる場合か強力な耐久化機構がある場合のみ使用します。
データがほとんど変わらないなら、適切なTTLを付けたキャッシュアサイドで十分です。頻繁に変わり、古い読み取りが問題になるなら write-through(または非常に短いTTL+明示的無効化)を検討します。書き込みが非常に多く一部の損失を許容できるなら write-behind が有効な場合があります。
キャッシュデータを「十分に新鮮」に保つには、各キーの失効戦略を選ぶことが重要です。目標は完璧な正確さではなく、驚きを避けつつ速度の恩恵を得ることです。
TTL(time to live)はキーが消えるまたは利用不可になる時間を設定します。短いTTLは古さを減らしますがミスが増えバックエンド負荷を上げます。長いTTLはヒット率を上げますが古い値を返すリスクが高まります。
TTLの実用的な決め方:
TTLは受動的です。データが変更されたと分かっている場合は能動的に無効化する方がよい:古いキーを削除するか新しい値を書き込みます。
例:ユーザーがメールを更新したら user:123:profile を削除するか、キャッシュ内の値を即更新します。能動的無効化は古さの窓を減らしますが、アプリが確実にキャッシュ更新を行う必要があります。
古いキーを削除する代わりにキー名にバージョンを含めます(例:product:987:v42)。商品が変わったらバージョンを上げて v43 を使い始めます。古いバージョンは自然に期限切れになります。これにより、一方のサーバーが削除する間に別のサーバーが書き込むような競合を避けられます。
ホットキーが失効して多数のリクエストが同時に再構築する状況は避けるべきです。
一般的対策は:
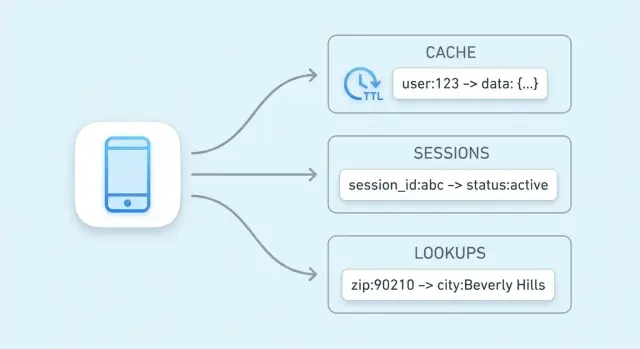
セッションデータはブラウザやモバイルクライアントを識別するためにサーバ側で保持する小さな情報束です。最低限、セッションID(またはトークン)をサーバ側状態に紐付けます。製品によってはユーザー状態(ログインフラグ、ロール、CSRFノンス)やカート内容などの一時的データを含むこともあります。
セッションの読み書きは単純:トークンでルックアップし、値を取得し、更新し、失効を設定する。TTLを使えば非アクティブなセッションを自動的に消せるため、保管がすっきりし、トークン漏洩時のリスクも低くできます。
よくあるフロー:
明確でスコープされたキーを使い、値は小さく保ちます:
sess:<token> や sess:v2:<token>(バージョン付けは将来の変更に便利)。\n- ユーザースコープ: 必要なら user_sess:<userId> -> <token> のようなインデックスを持ち、「ユーザーあたり一つの有効セッション」を強制したりユーザー単位での撤回に使う。\n- サイズ制限: 全プロフィールをセッションに詰め込まない。必要最低限だけにし、大きなデータはDBに置いて参照する。ログアウト時はセッションキーと関連インデックス(例:user_sess:<userId>)を削除します。ローテーション(ログイン後や権限変更後、定期的に推奨)では新しいトークンを作り新しいセッションを書いてから古いキーを削除します。これにより盗難されたトークンが有効な窓を狭められます。
キャッシュが最も一般的な用途ですが、高速な読み取りが求められる小さな状態を保持するためにもキー・バリューストアはよく使われます。これらは“ソース・オブ・トゥルースに隣接する”データで、ほぼ毎リクエストで素早くチェックされるものです。
認可チェックはしばしばクリティカルパス上にあり、各API呼び出しで「このユーザーはこれをして良いか?」を答える必要があります。リレーショナルDBから毎回取り出すと遅延や負荷が増えることがあります。
キー・バリューストアにはコンパクトな認可データを入れて高速ルックアップできます:
perm:user:123 → 権限コードのリスト/セット\n- entitlement:org:45 → 有効なプラン機能読み取りが多く更新が比較的少ないモデルに有効です。権限が変わったら小さなキー集合を更新または無効化して次のリクエストに反映させます。
機能フラグは小さく頻繁に読まれる値で、多数のサービスで素早く一貫して利用できる必要があります。
典型的な保存例:
flag:new-checkout → true/false\n- config:tax:region:EU → JSON ブロブやバージョン付き設定キー・バリューストアは読み取りがシンプルで予測可能かつ高速なため適しています。バージョン付け(例:config:v27:...)でロールアウトやロールバックを安全に行えます。
レート制限はユーザー、APIキー、IPごとのカウンタに帰着することが多いです。キー・バリューストアの原子操作を使えば多くの同時リクエストでも安全にインクリメントできます。
例:
rl:user:123:minute → リクエストごとに増やし、60秒で失効\n- rl:ip:203.0.113.10:second → 短いウィンドウのバースト制御各カウンタにTTLを付ければ、制限は自動的にリセットされます。ログやバックグラウンドジョブが不要な実用的な基盤です。
支払いなど「確実に一度だけ」という操作は、タイムアウトやクライアント再送、メッセージの再配信で重複実行されるリスクがあります。
キー・バリューストアに冪等キーを記録することで防げます:
idem:pay:order_789:clientKey_abc → 結果やステータスを保存最初のリクエストで処理し結果をTTL付きで保存しておき、以降の再送では保存した結果を返して二重実行を避けます。TTLは成長を防ぎつつ現実的な再試行ウィンドウをカバーします。
これらは古典的な意味での「キャッシュ」ではなく、速度と原子性が必要な調整プリミティブです。
「キー・バリューストア」が必ずしも「文字列 in / 文字列 out」を意味するわけではありません。多くのシステムはよりリッチなデータ構造を提供し、アプリ側のロジックを減らして直接ストア内でモデル化できます。
ハッシュ(マップ)は複数の関連属性を一つの「もの」に持たせたいときに有効です。user:123:name、user:123:plan、user:123:last_seen のように多数のキーを作る代わりに user:123 の下にフィールドを持てます。
これによりキーの増加を抑え、必要なフィールドのみ取得・変更できるためプロフィールや設定に便利です。
セットは「Xがグループに入っているか?」という問いに向きます:
ソート済みセットはスコアによる順序付けを提供し、リーダーボードや「上位N」リスト、時間や人気ランキングに向きます。ビュー数やタイムスタンプをスコアにして上位を素早く読めます。
同時実行の問題は小さな機能でよく発生します:カウンタ、割当、ワンタイム操作、レート制限など。アプリが「読む→+1→書く」を行うと更新を失うことがあります。
原子操作はこれをストア内部で不可分の一歩として行います:
原子インクリメントを使えばロックや追加のサーバ間調整が不要になります。結果として競合が減り、コードが単純になり、負荷時でも挙動が予測可能になります。特にレート制限や利用量上限のように"ほぼ正しい"が顧客に影響するケースで重要です。
本番トラフィックをさばく段階になると「速くする」は多くの場合「広げる」を意味します:読み書きを複数ノードに分散し、障害時にも予測可能に保つことです。
複製(Replication) は同じデータを複数コピーで保持します。
シャーディング(Sharding) はキー空間をノード間で分割します。
多くの導入ではシャードごとに複製を付ける組み合わせが使われます:スループット向上のためにシャーディング、可用性のために各シャードにレプリカを置く。
高可用性はノード障害が起きてもキャッシュ/セッション層が応答を続けることを意味します。
クライアント側ルーティング ではアプリやライブラリがどのノードがキーを持つか計算します(コンシステントハッシュによく使われる)。非常に速い反面、トポロジー変更をクライアントが学習する必要があります。
サーバ側ルーティング ではプロキシやクラスタエンドポイントに送信し、そこが適切なノードへ転送します。クライアントは単純になりますが一つ余分なホップが入ります。
メモリを上から計画します:
キー・バリューストアはホットデータをメモリに保ち高速にするため非常に"即時"に感じられますが、その速度にはコストがあります:性能、耐久性、整合性のどれを優先するかという選択です。事前にこれらのトレードオフを理解しておくと後で辛い目に遭いません。
多くのキー・バリューストアは異なる永続化モードで動作します:
データの用途に合わせてモードを選んでください:キャッシュは損失を許容でき、セッションはより注意が必要です。
分散構成では最終的整合性が生じうることに注意してください。特にフェイルオーバーやレプリケーション遅延時に古い値を読むことがあります。複数ノードからの確認を要求するなど強い整合性を選ぶとアノマリーは減りますが、レイテンシは増え、ネットワーク問題時に可用性が下がる可能性があります。
キャッシュは満杯になります。エヴィクションポリシーは何を削除するかを決めます:最小最近使用(LRU)、最小頻度使用(LFU)、ランダム、あるいは"削除しない"(満杯で書き込み失敗)など。どちらを許容するか(キャッシュミス増加か書き込み失敗か)を選ぶ必要があります。
障害は起きると仮定してください。典型的なフォールバック:
これらの挙動を意図的に設計するとユーザーにとって信頼できるシステムになります。
キー・バリューストアはアプリの"ホットパス"にあることが多く、セッションやユーザー識別子などの機密情報を保持し得るため敏感であり、メモリ中心のためコストもかかります。基本を早めに整えると事故を防げます。
まずネットワーク境界を明確に:ストアをプライベートなサブネット/VPCに置き、実際に必要なアプリサービスだけが接続できるようにします。
製品が対応するなら認証を使い、最小権限の原則に従ってアプリ用、管理用、自動化用に別々の資格情報を用意し、シークレットをローテーションします。共有の"root"トークンは避けるべきです。
可能なら TLS 等で通信の暗号化を行い、ホストやゾーンを越えるトラフィックでは必須です。永続ストレージの暗号化はマネージドサービスや展開に依存しますが、対応しているならバックアップの暗号化も確認してください。
少数の指標でキャッシュが助けているか害しているかが分かります:
急激な変化に対するアラートを設定し、敏感な値はログに残さないよう注意してください。
大きな要因は:
コスト削減の実用的レバーは値サイズを減らし現実的なTTLを設定して、ストアがアクティブに使うものだけを保持することです。
まずキー命名を標準化して、キャッシュやセッションキーが予測可能で検索可能、運用で一括操作しやすくします。app:env:feature:id のような単純な慣例(例:shop:prod:cart:USER123)は衝突を避けデバッグを速くします。
出荷前にTTL戦略を定めましょう。どのデータを短期間(秒/分)で失効させるか、どれを長め(時間)にするか、何を全くキャッシュしないかを決めます。DB行をキャッシュするなら基データの変化頻度にTTLを合わせます。
各キャッシュアイテムタイプに対する無効化計画を書き出します:
product:v3:123)で全無効化を簡単にする。初日から追跡する成功指標を選びます:
またエヴィクション数とメモリ使用量を監視してキャッシュサイズが適切か確認します。
値が大きすぎるとネットワーク時間とメモリ圧力が増すため、小さなプリコンピュート断片を好みます。TTLを付け忘れると古いデータやメモリリークに繋がります。また無制限なキー増加(例:検索クエリを永遠にキャッシュ)がよくある失敗です。ユーザー固有のデータを共有キー下に置かないよう注意してください。
選択肢を評価するなら、ローカルのプロセス内キャッシュと分散キャッシュを比較し、一貫性がどこで重要かを決めてください。実装や運用ガイダンスは /docs を参照し、容量や価格見積もりが必要なら /pricing をご覧ください。
新製品を作る、あるいは既存をモダナイズする場合、キャッシュとセッションストレージを最初から設計の主要要素として扱うと有利です。Koder.ai では多くのチームがエンドツーエンドのアプリ(WebはReact、サービスはGo+PostgreSQL、必要であればモバイルはFlutter)をプロトタイプして、cache-aside、TTL、レート制限カウンタなどで性能を磨きます。プランニングモード、スナップショット、ロールバック機能はキャッシュキー設計や無効化戦略を安全に試すのに役立ち、準備ができたらソースコードをエクスポートして自分のパイプラインで実行できます。
キー・バリューストアは一つの操作に最適化されています:与えられたキーに対して値を返すこと。この単純な焦点により、インメモリのインデックスやハッシュによる直接アクセスなど、クエリ計画のオーバーヘッドが少ない高速な経路が使えます。
また、人気のあるページや共通APIレスポンスなどの繰り返し読み取りを主要DBからオフロードすることで、システム全体の速度向上にも寄与します。
キーは正確に繰り返せる一意の識別子(多くの場合 user:123 や sess:<token> のような文字列)です。値はカウンタのような小さなものから JSON ブロブのような大きなデータまで何でもあり得ます。
良いキーは安定していて、スコープが明確で、予測可能であり、これがキャッシュやセッション、ルックアップの運用やデバッグを容易にします。
頻繁に読み出され、失っても再生成できる結果をキャッシュしてください。
よくある例:
正確に最新である必要があるデータ(例:残高など)は、強い無効化戦略が無い限りキャッシュ対象から外すべきです。
キャッシュアサイド(遅延読み込み)は一般的なデフォルトです:
key を読む。キャッシュが空でもデータベースから応答できるため、優雅に劣化します。
Read-through はミス時にキャッシュ層自体がDBから読み込む方式で、アプリ側の読み取り実装が簡潔になります(ただしキャッシュ層の統合が必要)。
Write-through は書き込みをキャッシュとDBに同期的に行う方式で、読み取りは一貫して速くなりますが書き込みレイテンシは高くなります。
運用の複雑さ(read-through)や書き込み遅延(write-through)を許容できるかで選びます。
TTL(有効期限)はキーが自動で失効する時間を決めます。短いTTLは鮮度を保ちますがミス率とバックエンド負荷を上げ、長いTTLはヒット率を上げますが古い値を返すリスクが高まります。
実用的な指針:
データが確実に変わったと分かる場合は、TTLに頼らず能動的に削除・更新する方がよいです。
キャッシュスタンピードはホットキーが失効したときに多くのリクエストが同時に再構築を始める現象です。
一般的な対策:
これらでDBや外部APIへの急増を抑えられます。
セッションはトークンでサーバー側状態を参照する小さな情報の束で、読み書きが簡単でTTLを適用しやすいためキー・バリューストアと相性が良いです。
ベストプラクティス:
sess:<token> のようなスコープ付きキーを使う(sess:v2:<token> のようなバージョン付けはマイグレーションに便利)。多くのキー・バリューストアはアトミック増分をサポートしており、同時実行があっても安全にカウンタを扱えます。
典型的なパターン:
rl:user:123:minute → リクエストごとにインクリメント、キーは60秒で失効カウンタにTTLを設定すれば、バックグラウンドジョブ無しで制限のリセットが実現できます。閾値を超えたらスロットルや拒否を行います。
採用前に理解すべきトレードオフ:
障害時の挙動も設計し、必要ならキャッシュをバイパスしてDBから読む、古い値を返す、あるいは重要操作は失敗させる(fail closed)などを検討してください。