2025年6月10日·1 分
キャッシュ層は負荷を削減する — しかし隠れた複雑さを生む
キャッシュ層はレイテンシとバックエンドの負荷を削減する一方で、障害モードや運用コスト、整合性の問題を増やします。一般的な層、リスク、複雑さを管理する方法を解説します。
キャッシュ層はレイテンシとバックエンドの負荷を削減する一方で、障害モードや運用コスト、整合性の問題を増やします。一般的な層、リスク、複雑さを管理する方法を解説します。
キャッシュは必要な場所の近くにデータのコピーを置くことで、リクエストをより速く、コアシステムへの往復を減らして応答できます。得られる効果は通常、速度(低レイテンシ)、コスト(高価なDB読み取りやアップストリーム呼び出しの削減)、安定性(オリジンサービスがトラフィックのスパイクを耐えられる)という組み合わせです。
キャッシュがリクエストに応答できれば、あなたの“オリジン”(アプリサーバ、データベース、サードパーティAPI)はより少ない仕事で済みます。その削減効果は劇的になり得ます:クエリが減り、CPUサイクルが減り、ネットワークホップが減り、タイムアウトの機会も減ります。
キャッシュはバーストを平滑化するのにも役立ちます。平均負荷で設計されたシステムがピーク時を即座にスケールせずに乗り切る手助けになります。
キャッシュは作業を“無くす”わけではなく、それを設計と運用側に“移す”だけです。次のような新しい問いが発生します:
各キャッシュ層は設定、監視、エッジケースを継承します。99%のリクエストを速くするキャッシュでも残り1%で痛いインシデントを起こし得ます:同期的な失効、ユーザーごとの不一致、オリジンへの突然の集中などです。
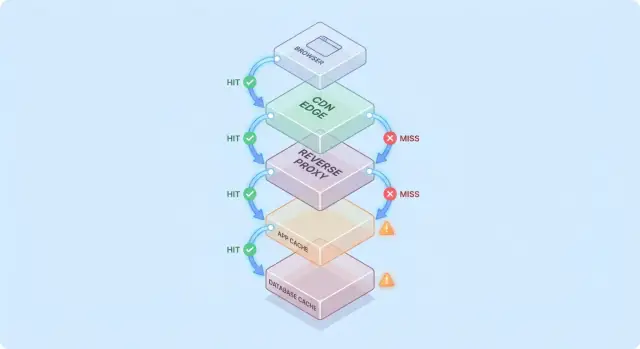
単一のキャッシュは一つのストア(例:アプリ横のインメモリ)。キャッシュ層はリクエスト経路上のチェックポイント(CDN、ブラウザキャッシュ、アプリキャッシュ、DBキャッシュ)で、それぞれが独自のルールと障害モードを持ちます。
この記事は複数層が導入する実務的な複雑さ(正しさ、無効化、運用)に焦点を当てます(低レベルなキャッシュアルゴリズムやベンダー固有のチューニングは扱いません)。
リクエストが「既に持っているかもしれない」チェックポイントのスタックを通ると想像すると、キャッシュを考えやすくなります。
一般的な経路は次のようになります:
各ホップでシステムはキャッシュされた応答(ヒット)を返すか、次の層に転送する(ミス)かのどちらかになります。より早い段階でヒットすればするほど、深い層の負荷を避けられます。
ヒットはダッシュボードを良く見せます。ミスは複雑さを露呈します:実際の仕事(アプリロジック、DBクエリ)を引き起こし、キャッシュのルックアップ、シリアライズ、キャッシュ書き込みなどのオーバーヘッドを増やします。
有用なモデルはこうです:すべてのミスはキャッシュのコストを二重に支払う—元の仕事に加えてキャッシュ周りの処理も必要になる、ということです。
キャッシュを追加してもボトルネックを完全に消すことは稀で、しばしば移動します:
製品ページがCDNで5分、アプリがRedisで30分キャッシュされているとします。
価格が変わると、CDNはすぐに更新されるかもしれませんがRedisが古い価格を返し続けることがあります。どの層が応答したかで“真実”が変わる——キャッシュ層が負荷を削る一方で複雑さを増す理由の初歩的な例です。
キャッシュは一つの機能ではなく、複数の場所(スタック)でデータを保存して再利用する手段です。各層は負荷を下げますが、新鮮さ、無効化、可視性に関して異なるルールを持ちます。
ブラウザは画像、スクリプト、CSS、場合によってはHTTPヘッダ(Cache-ControlやETag)に基づいてAPI応答をキャッシュします。これにより繰り返しのダウンロードが完全に無くなることがあり、パフォーマンスとCDN/オリジンのトラフィック削減に非常に有効です。
注意点:クライアント側に一度キャッシュされると再検証タイミングを完全に制御できません。ユーザーによっては古い資産を長く保持したり、突然キャッシュを消去したりします。そこで app.3f2c.js のようなバージョン化されたURLが一般的な対策です。
CDNはユーザーの近くでコンテンツをキャッシュします。静的ファイル、公開ページ、画像、ドキュメント、レート制限されたAPI等の「概ね安定した」応答に向いています。
CDNはバリエーション(クッキー、ヘッダ、地域、デバイス)を注意深く扱えば半静的なHTMLもキャッシュできます。誤ったバリエーション設定は誤ったユーザーに誤ったコンテンツを配る原因になります。
NGINXやVarnishのようなリバースプロキシはアプリの前に置かれ、完全な応答をキャッシュできます。オリジン保護、予測可能なエビクション、トラフィックスパイク時の迅速な防御として有効です。
グローバル分散はCDNほどではないが、アプリのルートやヘッダに合わせた細かな調整がしやすい点が利点です。
この層はオブジェクトや計算結果、コストの高い呼び出し(例:user profile by idや地域ごとの価格ルール)をターゲットにします。ビジネスロジックに合わせられる柔軟性が利点です。
同時に、キー設計、TTL選択、無効化ロジックやサイズ・フェイルオーバーなど運用面の決定事項も増えます。
多くのDBはページ、インデックス、クエリプランを自動的にキャッシュします。中には結果キャッシュをサポートするものもあり、アプリコードを変えずに繰り返しクエリを速くできます。
ただしこれは“おまけ”と考えるべきで、不規則なクエリパターンの下では予測性が低く、書き込みやロック、競合のコストを除去するものではありません。
キャッシュは繰り返し発生する高コストのバックエンド処理を安価なルックアップに変えられるときに最大の効果を発揮します。鍵はリクエストが十分に似ていて、十分に安定しているワークロードにキャッシュを合わせることです。
読み取りが書き込みより圧倒的に多い場合、キャッシュはDBやアプリの作業の大部分を取り除けます。製品ページ、公開プロファイル、ヘルプ記事、同じパラメータで頻繁に要求される検索やフィルタ結果などが該当します。
またPDF生成、画像リサイズ、テンプレートレンダリング、集計といった“高コスト”処理にも効果的で、短いTTLでも忙しい期間の繰り返し計算を潰せます。
トラフィックが不均一なとき、キャッシュは特に効きます。マーケティングメールやニュース、SNS投稿で突然多くのユーザーが同じ数URLに来る場合、CDNやエッジキャッシュがそのサージの大部分を吸収できます。
これによりレスポンスが速くなるだけでなく、オートスケールの振動、DB接続枯渇、バックプレッシャやレート制限の猶予を生むことができます。
バックエンドがユーザーから遠い(物理的に遠い、あるいは依存が遅い)場合、キャッシュは負荷と体感スローネスの両方を下げます。CDNがユーザー近くから応答すれば長距離の往復を避けられます。
内部キャッシュも、リモートDBやサードパーティAPIといった高レイテンシなストアの呼び出し回数を減らしてコンカレンシーの圧力や尾部レイテンシを改善します。
応答が強くパーソナライズされる場合(ユーザー固有のデータ、機密アカウント情報)や基データが絶えず変わる場合(ライブダッシュボード、頻繁に更新される在庫)、ヒット率は低く、無効化コストが上がり、負荷削減効果は限定的です。
実務的なルール:多くのユーザーが同じものを短い期間で要求し、それが有効であり続ける場合にキャッシュは価値が高い。そうでなければ新たな層は複雑さを増すだけです。
データが変化するとキャッシュは複雑になります。信頼できなくなる時点を決め、すべてのキャッシュ層にどう伝えるかを決めるのが難しい作業です。
TTLは協調を要さないので魅力的ですが、「正しい」TTLは使い方次第です。製品価格に5分のTTLを設定すると、価格変更後に古い価格が表示されるユーザーが出て法的・サポート上の問題になるかもしれません。一方5秒にすると負荷削減効果は薄れます。同一レスポンス内で項目ごとに更新頻度が異なる場合、単一TTLは妥協を強います。
イベント駆動は、真実が変わったときにイベントを発行して影響するキーをすべてパージ/更新します。正確ですが以下の作業が必要です:
このマッピングが難所であり、無ければ複数キーにまたがる不整合が生じます(例:/users/123 と「上位寄稿者リスト」など)。
Cache-aside(アプリがDB読み書きしキャッシュを埋める)は一般的だが無効化はアプリ側の責任。
Write-through(キャッシュとDBに同時に書く)は古さリスクを下げるがレイテンシと障害対処が複雑に。
Write-back(まずキャッシュに書き後でフラッシュ)は高速だが正当性と回復が非常に難しい。
stale-while-revalidate は背景で更新しながら少し古いデータを返します。スパイクを平滑化してオリジンを保護しますが、製品意思決定でもあり「速くてほぼ最新」を「常に最新」に優先する選択です。
キャッシュは「正しさ」の意味を変えます。キャッシュが無ければユーザーは通常データベース上の最新コミットを見ますが、キャッシュがあると少し遅れて表示されたり、画面間で不一致が生じたりすることがあります。
強整合性は“書き込み直後の読み取り”を目指します。ユーザーが住所を更新したら次の表示で新住所がどこでも見えるべき、という直感的な要件です。しかしこれを保証するには多くの場合、書き込み時に複数のキャッシュを即座にパージ/更新する必要があり高コストです。
最終的整合性は短時間の古さを許容します。ビュー数のような低影響コンテンツでは許容されますが、金銭や権限に関わる領域では許されません。
よくある落とし穴は書き込みとキャッシュ再構築が同時に起きることです。
この場合、DBは正しいがキャッシュはTTLの間古いデータを保持することになります。
複数層があるとシステムの一部が別の値を返すことがあります:
UIは混在し、「システムが壊れている」とユーザーに映ります。
バージョニングは曖昧さを減らします:
user:123:v7)は書き込みでバージョンを進めることで安全に次へ移行でき、完璧な削除を要求しません。重要なのは「古いデータが悪いか?」ではなく「どこで悪いか?」です。
各機能に対して明確な古さの予算(秒/分/時間)を設定し、ユーザー期待と合わせます。検索結果は1分遅れても許容されることがあるが、口座残高やアクセス制御は即時性を要求します。これにより「キャッシュ正しさ」はテスト・監視可能なプロダクト要件になります。
キャッシュは「うまくいっているときは素晴らしいが、ある瞬間にすべて壊れる」ような障害を招きやすいです。これはキャッシュがトラフィックパターンを集中させるため、小さな変化が大きな影響を与えるからです。
デプロイ、オートスケール、キャッシュフラッシュの後はキャッシュが空に近くなることがあります。次のトラフィックで多くのリクエストがDBや上流APIに直撃します。
特にトラフィックが急増する状況ではキャッシュがウォームする時間が足りず、デプロイがピークに重なると意図せず負荷試験を作ることになります。
多くのユーザーが同時に同じアイテムを要求すると、期限切れの瞬間にオリジンが圧倒されます。一般的な緩和策は前述のシングルフライト、ロック、ジッター付与、stale-while-revalidate です。
あるキーが圧倒的に人気になると(ホームページペイロード、トレンド商品、グローバル設定)、一部のキャッシュノードやバックエンドパスだけが集中して負荷を受けます。対策は大きな「グローバル」キーを細分化する、シャーディングを導入する、あるいはCDNなど別層に移すことです。
キャッシュ障害はキャッシュが無い状態より悪いことがあります。事前に選択してください:
どれを選ぶにせよ、レートリミットとサーキットブレーカーでキャッシュ障害がオリジン障害に発展しないようにするのが重要です。
キャッシュはオリジンの負荷を減らしますが、日々運用するコンポーネント数を増やします。マネージドであっても計画、チューニング、インシデント対応が必要です。
新たなキャッシュ層は多くの場合クラスタ(または新しい階層)を意味し、容量制限やポリシーがあります。メモリサイズ、エビクションポリシー、プレッシャー下の振る舞いを決めないと、サイズ不足でヒット率が下がり、オリジンに負荷が戻ります。
キャッシュは一か所に留まりません。CDN、アプリキャッシュ、DBキャッシュが異なる解釈をすることがあります。
小さな不一致は累積します:
時間が経つと「なぜこのリクエストがキャッシュされているのか?」を調べるのが考古学的作業になります。
重要キーのウォーミング、デプロイ後のパージ/再検証、ノード追加/削除時のリシャーディング、完全フラッシュ後の手順の演習など、キャッシュは定期的な作業を生みます。
古いデータや突然の遅延をユーザーが報告したら、疑うべきはCDN、キャッシュクラスタ、アプリキャッシュクライアント、オリジンと多岐にわたります。デバッグは層ごとのヒット率、エビクションスパイク、タイムアウトをチェックし、バイパス、パージ、スケールのいずれかを判断する必要があります。
キャッシュはバックエンド作業を減らしユーザー体感の速度を上げるときのみ成功です。複数層のどれがリクエストを返したかを答えられる観測性が必要です。
高いヒット率は良い指標のように見えますが、遅いキャッシュ読取やチェーンが隠れていることがあります。層ごとに以下を追いましょう:
ヒット率が上がっても総レイテンシが改善しないなら、キャッシュが遅い、過度に直列化されている、またはペイロードが大きすぎる可能性があります。
分散トレーシングはリクエストがエッジ、アプリキャッシュ、DBのどれで処理されたかを示すべきです。cache.layer=cdn|app|db と cache.result=hit|miss|stale のようなタグを加えてトレースをフィルタし、ヒット経路とミス経路を比較できるようにします。
ログにキャッシュキーを記録する際はユーザーID、メール、トークン、クエリ付きのフルURLなどを直接書かないでください。正規化やハッシュ、短いプレフィックスを使います。
異常なミス率スパイク、ミス時のレイテンシ急増、同一キーへの多数同時ミス(スタンピード指標)をアラート対象にします。ダッシュボードはエッジ、アプリ、DBのビューとエンドツーエンドのパネルを分けて監視します。
キャッシュは高速に同じ答えを繰り返しますが、誤った相手に誤った答えを繰り返す危険もあります。キャッシュ関連のセキュリティ事故は静かに起きることが多く、見た目は高速で正常に見えてもデータが漏れていることがあります。
共通の誤りは個人化された/機密のコンテンツ(アカウント詳細、請求書、サポートチケット、管理画面)が共有キャッシュに入ることです。これはCDN、リバースプロキシ、アプリキャッシュのいずれでも起こり得ます。
微妙な漏洩としては Set-Cookie を含む応答をキャッシュしてしまい、別ユーザーに同じ応答を返してしまうケースがあります。
よくあるバグはユーザーA向けのHTML/JSONをキャッシュしてしまい、キャッシュキーがユーザー文脈を含んでいないために後でユーザーBへ提供してしまうことです。マルチテナントではテナント識別子をキーに含める必要があります。
経験則:応答が認証、ロール、地域、価格帯、機能フラグ、テナントに依存する場合、キャッシュキーかバイパスロジックがその依存を反映しているべきです。
HTTPキャッシュ動作はヘッダに大きく依存します:
Cache-Control: 必要な場合は private / no-store を使い誤って保存されるのを防ぐVary: 応答が変わるリクエストヘッダごとに分離する(例:Authorization, Accept-Language)Set-Cookie: 公共キャッシュでは保存すべきでない強いシグナルPII、健康/財務データ、法的文書などリスク・コンプライアンスが高い場合は Cache-Control: no-store を優先し、共有キャッシュには入れないでください。混在ページでは非機密部分のみをキャッシュし、個人化データは共有キャッシュから排除します。
キャッシュ層はオリジン負荷を下げるが、しばしば“ただの無料の性能”ではありません。新しいキャッシュは投資です:低レイテンシと少ないバックエンド作業を買う代わりに費用、工数、正当性の表面積を増やします。
**追加インフラ費用 vs オリジンコスト削減。**CDNは出口帯域やDB読み取りを減らすが、CDNリクエストやストレージ、場合によっては無効化コールに対して課金されます。アプリキャッシュ(Redis/Memcached)はクラスタ管理コストやオンコール負担を増やします。削減効果はDBレプリカ数の削減、小さなインスタンスタイプ、スケールの遅延などで現れることがあります。
**レイテンシの改善 vs 新鮮さのコスト。**すべてのキャッシュは「どれだけ古さを許容するか」を要求します。厳密な新鮮さは無効化配管を増やしミスを増やします。許容される古さは演じる価値とユーザー信頼を天秤にかける必要があります。
**エンジニア時間:機能速度 vs 信頼性作業。**新しい層は追加のコードパス、テスト、スタンピードやホットキー、部分的無効化といった新たなインシデントクラスを生みます。初期導入だけでなく継続的な運用コストを見積もってください。
広範囲に展開する前に限定的なトライアルを実施してください:
新しいキャッシュ層を追加するのは次を満たすときだけ:
キャッシュはオーナーと明確なルール、そして安全にオフにできる手段を持ったプロダクトとして扱うと効果が出やすいです。
一度に一つずつ層を追加(例:まずCDNかアプリキャッシュのどちらか)し、担当チーム/担当者を明確にします。
所有者は次を持っているべきです:
多くのキャッシュバグは実は“キー設計のバグ”です。ドキュメント化された命名規約を使い、レスポンスを変える入力(テナント/ユーザー範囲、ロケール、デバイスカテゴリ、関連する機能フラグ)をキーに含めます。
明示的なキーのバージョニング(例:product:v3:...)を導入すると、何百万のエントリを削除しようとする代わりにバージョンを上げて安全に移行できます。
すべてを完璧に最新に保とうとすると書き込み経路に複雑さが波及します。
代わりに、エンドポイントごとに「受容可能な古さ」を決め、それを次で具現化します:
キャッシュは遅くなる、間違う、あるいは落ちると想定して設計します。
タイムアウトとサーキットブレーカーを使い、キャッシュ呼び出しがリクエストパス全体を阻害しないようにします。キャッシュが失敗したらオリジンへフォールバックする際にもレート制限をかけてください。
キャッシュはカナリアや割合ロールアウトで出し、ルート毎やヘッダでバイパスできるスイッチを用意します。
ランブックを文書化します:パージ方法、キーのバージョン上げ方、一時的にキャッシュを無効化する手順、どこで指標を確認するか。オンコールが素早く動けるよう、内部ランブックページからリンクしておきます。
キャッシュはヘッダ、アプリロジック、データモデル、ロールバック計画にまたがるため変更が停滞しがちです。完全なリクエスト経路を制御された環境でプロトタイプすると反復コストが下がります。
例えば Koder.ai のようなプラットフォームを使えば、チャット駆動のワークフローで現実的なアプリスタック(Reactフロント、Goバックエンド、PostgreSQL、モバイルクライアント)を素早く立ち上げ、TTL、キー設計、stale-while-revalidate といったキャッシング決定をエンドツーエンドで試せます。planning mode は実装前に期待されるキャッシング挙動を文書化し、スナップショット/ロールバック 機能はキャッシュ設定や無効化ロジックの実験を安全にします。準備ができればソースをエクスポートしたりカスタムドメインでデプロイして実運用に近い負荷で試験できます。
こうしたプラットフォームは本番向けの観測性を置き換えるものではなく、キャッシュ設計の反復を早める補助ツールとして使い、正当性要件とロールバック手順を明示しておくことが重要です。
キャッシュは、繰り返し発生するリクエストに対してオリジン(アプリサーバ、データベース、サードパーティAPI)へ到達せずに応答を返すことで負荷を下げます。大きな効果が出るのは主に:
また、リクエストパスの早い段階(ブラウザ/CDN)でヒットすると、より深い層への負荷を多く削減できます。
単一のキャッシュは(例えばアプリ横のインメモリキャッシュのように)一つのストアを指します。一方で「キャッシュ層」はリクエスト経路のチェックポイントを指します(ブラウザキャッシュ、CDN、リバースプロキシ、アプリキャッシュ、DBキャッシュなど)。
複数の層を重ねるとオリジン全体の負荷をより広く減らせますが、その分ルールや障害モード、データ不整合の原因も増えます。
ミスは“実際の仕事”を引き起こすため、キャッシュヒットに比べて複雑さが増します。ミス時には通常:
これらすべてのコストを支払うため、ミスは「キャッシュがない場合」より遅く感じられることもあり、キャッシュ設計と高いヒット率が重要になります。
TTL(Time-to-Live)は協調を必要としない単一の数値で扱いやすいですが、「正しいTTL」は用途によって異なります。TTLが長すぎるとデータが古くなり問題になるし、短すぎると負荷削減効果が薄れます。
実務的には、フィーチャーごとにユーザー影響を基準にTTLを設定します(例:ドキュメントは数分、残高や価格は数秒〜無効)。運用でのヒット/ミスやインシデントデータをもとに見直すのが現実的です。
ソースの真実が更新されたときに、該当するキャッシュキーをパージ/更新するイベントを発行するやり方です。正確性は高いですが、次のような運用作業が増えます:
このマッピングが難しく、保証できない場合はTTL+再検証などの限定的な古さ許容の方が現実的です。
レースコンディションの例として:
この結果、DB自体は正しいがキャッシュがTTL分古いデータを保持してしまう、という事態が起きます。
スタンピード(thundering herd)は多くのユーザーが同時に同一キーを再構築しに来る現象で、オリジンを圧倒します。代表的な対策:
運用上これらを組み合わせると効果的です。
事前にフォールバック動作を決めておくことが重要です:
加えて、タイムアウト、サーキットブレーカー、レートリミットを導入して、キャッシュ障害がオリジン障害に連鎖しないようにします。
結果を説明する指標に集中してください。単にヒット率が高いだけでは不十分です:
トレースでは cache.layer と cache.result のタグを付け、ヒット経路とミス経路を比較できるようにします。
パーソナライズされた機密情報が共有キャッシュに保存されてしまうことが最も多いリスクです(CDN、リバースプロキシ、アプリキャッシュ等)。また、Set-Cookie を含む応答を誤って公開キャッシュに入れると別ユーザーに配信される危険があります。
防止策:
Cache-Control: no-store または private を使うVary ヘッダを正しく設定する(例:Authorization, Accept-Language)Set-Cookie のある応答を公開キャッシュに入れないコンプライアンスや高リスク領域ではキャッシュを避けるのが安全です。