2025年6月02日·2 分
クロスチームのコミュニケーションリクエストを管理するWebアプリを作る
責任者、ステータス、SLAを明確にした上で、クロスチームのコミュニケーションリクエストを収集・ルーティング・追跡するWebアプリを計画、設計、構築する方法を学びます。
問題と範囲を定義する
何かを作る前に、何を直したいのか具体的にしましょう。「クロスチームのコミュニケーション」は、短いSlackメッセージから製品ローンチの告知まで幅があります。範囲が曖昧だと、アプリはゴミ箱化するか、誰も使わなくなります。
ここでの「コミュニケーションリクエスト」とは何か?
覚えやすい短い定義と、いくつかの例・非例を書きましょう。典型的なリクエストの種類には次が含まれます:
- カスタマー向け告知(メンテナンス、ポリシー変更)
- デリケートなケースのサポート返信承認
- リリースノートや変更履歴
- セールス支援のアップデート(新価格、ポジショニング)
- 経営層やリーガルのレビューが必要な声明
また、含めないこと(例:場当たり的なブレインストーミング、単なるFYI、いきなりの「電話出られる?」)も文書化してください。はっきりした境界があれば、システムが単なる受信箱になるのを防げます。
誰が関わり、どんな役割を果たすか?
リクエストに関わるチームとそれぞれの責任をリストアップしましょう:
- Requester(依頼者):要件を提出し、コンテキストや資産を提供する
- Approver(承認者):優先度、リスク、コンプライアンス、メッセージングを確認する
- Executor(実行者):コンテンツを作成・公開する
- Reviewer(レビュアー):最終チェック(正確性、トーン、ブランド)を行う
もし役割がリクエストタイプによって変わる(例:法務は特定トピックのみ)なら今のうちに捉えておきましょう—後のルーティングルール設計に役立ちます。
成功をどう測るか?
いくつか測定可能な成果を選びます。例:
- チャットでの「進捗ある?」の問い合わせが減る
- 提出から公開までのターンアラウンドが速くなる
- リクエストの見落としや重複が減る
最後に、今日の課題を平易な言葉で書き出してください:所有権が不明、情報不足、直前の依頼、DMに隠れたリクエストなど。これがベースラインとなり、変更の正当化資料になります。
ワークフローとユーザーストーリーをマップする
構築前に、リクエストが「助けが必要」から「完了」までどう動くか、関係者で整合しておきます。単純なワークフローマップは不注意な複雑化を防ぎ、ハンドオフが壊れやすい場所を浮き彫りにします。
ユーザーストーリー(具体的に)
使えるスターターストーリーを五つ挙げます(適宜調整してください):
- 依頼者として、短いブリーフを提出し、誰が担当か と いつ締め切りか をすぐに確認したい。
- トリアージ担当として、リクエストをすばやく検証し、1回の確認質問で済ませるか、理由を添えて却下できる。
- 承認者として、リクエストをレビューし、承認/却下を行い、記録に残るコメントを残したい。
- スケジューラ/パブリッシャーとして、承認済みの仕事をカレンダーに載せ、衝突を検出し、公開日を確定したい。
- ステークホルダーとして、チャットで追いかけることなくステータスと更新を追跡したい。
リクエストのライフサイクルをマップする
クロスチームのコミュニケーションリクエスト管理では、一般的に次のライフサイクルです:
submit → triage → approve → schedule → publish → close
各ステップについて次を書き出します:
- 開始条件(何が揃っているべきか)
- 所有者(人または役割)
- 期待される成果(「完了」の定義)
- 許可される出口(前進、編集のため差し戻し、却下)
設定可能な決定と固定すべき決定
設定可能にするもの:チーム、カテゴリ、優先度、カテゴリごとのインテーク質問。 最初は固定にしておくもの:コアステータスと**「クローズ」の定義**。初期に設定項目が多すぎると報告やトレーニングが大変になります。
注意して設計すべき高リスクのステップ
失敗しやすい点に注意:承認の停滞、チャネル間のスケジュール衝突、監査記録と厳密な所有権が必要なコンプライアンス/法務レビュー。これらのリスクはワークフロールールやステータストランジションに直接反映させます。
インテークフォームを設計する(最初に適切な情報を集める)
リクエストアプリが機能するのは、インテークフォームが一貫して使えるブリーフを拾えるときだけです。目的はすべてを聞くことではなく、チームが何日も追いかける必要がない正しい情報を得ることです。
最小限の実用的なブリーフから始める
最初の画面は簡潔に。最低限収集すべき項目:
- リクエストタイトル(1文の要約)
- 説明(何を必要としているか、なぜか)
- 対象(誰に配信するか)
- チャネル(メール、アプリ内、ソーシャル、プレス等)
- 希望日(いつ出す必要があるか)
- 添付(草案、クリエイティブ、スクリーンショット、法務メモ)
各フィールドの下に短いヘルパーテキストを入れてください(例:「対象例:'All US customers on Pro plan'」)。こうしたマイクロ例は長いガイドラインよりも往々にして誤解を減らします。
手戻りを防ぐ役立つフィールドを追加する
基本が安定したら、優先度や調整を楽にするための項目を加えます:
- 優先度(Low/Medium/Highなど)
- ビジネスインパクト(これが未実施だと何が変わるか)
- リンク(PRD、Jira、分析、ブランドドキュメント)
- ステークホルダー(承認者と通知対象)
- 言語/地域(ローカライズや地域ルールがある場合)
条件付き質問で短くかつ網羅的に保つ
条件ロジックでフォームを軽く保ちます。例:
- チャネル = Press の場合は スポークスパーソン、禁輸日、メディアリストを尋ねる
- 対象に顧客が含まれる 場合はセグメンテーション基準とサポート準備状況を尋ねる
煩わしくない程度に完全性を検証する
明確なバリデーションルールを使いましょう:必須フィールド、過去日付不可、High優先度では添付必須、説明文の文字数最小値など。
却下する場合は、具体的な指示(例:「ターゲット対象とソースチケットのリンクを追加してください」)を返して、依頼者が期待される基準を学べるようにします。
ステータス、所有権、明確なルールを作る
アプリが信頼されるには、全員がステータスを信用できる必要があります。つまりアプリが単一の真実の源であり、会話やDM、メールに隠れた「実際のステータス」があってはいけません。
シンプルで共通のステータスセットを定義する
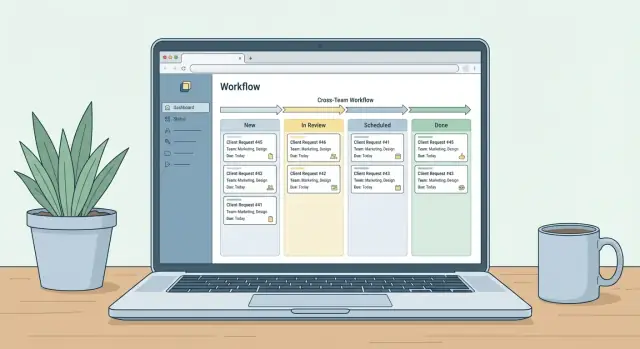
ステータスは少なく、曖昧さがなく、行動に結びつくものにします。実用的なデフォルトセットは:
- New — 提出されトリアージ待ち
- Needs Info — 依頼者の情報提供待ち
- In Review — 実現可能性・優先度・ポリシーの評価中
- Approved — 承認済みで計画可能
- Scheduled — 日付またはスプリントに割り当て済み
- Done — 納品・クローズ
- Rejected — 理由を記録して却下
各ステータスが「次に何が起きるか、誰が誰を待っているか」に答えるようにします。
ステップごとに所有者を割り当てる(漂わないように)
各ステータスには明確な“所有者”役割を付与します:
- トリアージ担当(通常はローテーションのオンコール)が New を迅速に処理
- 承認者 が In Review 中のGo/No-Goを判断
- 担当者(Assignee) が Approved/Scheduled 以降の納品を担当
所有者の明確化で、全員が「関与しているが誰も責任を持たない」という失敗を防げます。
ステータスが混乱しないルールを書く
アプリ内に軽量のルールを組み込みます:
- 誰がリクエストを移動できるか(例:New からの移動はトリアージのみ、Approved/Rejected は承認者のみ)
- いつ再オープンできるか(例:Done からは14日以内のみ再オープン可能、理由必須)
- 移行ごとの要件(例:Scheduled に移すには日付必須、Rejected にするには理由必須)
これらでレポート精度が上がり、不要なやり取りが減り、チーム間のハンドオフが予測可能になります。
データモデルと主要フィールドを計画する
明確なデータモデルは、新しいチームやリクエストタイプ、承認ステップが増えても柔軟に対応します。チームごとに新しいスキーマを作るより、少数のコアテーブルで多様なワークフローを支えられるように目指しましょう。
コアテーブル(シンプルに始める)
最低限計画すべきもの:
- Users: 名前、メール、役割、アクティブフラグ
- Teams: チーム名、デフォルトSLAポリシー、ルーティングルール
- Requests: チケット本体(下記詳細)
- Comments: リクエストに紐づくスレッド型の議論
- Attachments: ファイルやリンク、アップローダーとタイムスタンプ
- StatusHistory: すべてのステータス変更(可能なら所有者変更も)
この構成でチーム間のハンドオフをサポートし、現状のみを持つ設計よりレポーティングが格段に楽になります。
Request レコードの主要フィールド
Requests テーブルにはルーティングと説明責任の基本を入れます:
- requesting_team および/または requester_user
- category(キャンペーン、告知、プレス、法務レビュー等)
- priority(影響/緊急度)
- due_date(依頼者が必要とする日)
- sla_target_at(SLAポリシーに基づく計算済みの締切)
- current_status
- current_owner_user(または owner team + assignee)
加えてサマリー/タイトル、説明、要求チャネル(メール、Slack、イントラ等)、必要資産を考慮してください。
タグと検索で現場のフィルタリングを実用化する
tags(多対多)と searchable_text フィールド(またはインデックス化された列)を追加して、チームがキューを素早くフィルタできるようにします(例:「product-launch」や「executive-urgent」)。
監査性は必須
監査要件は最初から考慮してください:
- created_at / updated_at / closed_at タイムスタンプを保存
- StatusHistory に誰がいつ何を変更したかを残す
- 重要フィールド(ステータス、所有者、期日)の過去値を保持
「なぜ遅れたのか?」と聞かれたときに、チャットログを掘り返すことなく明確に答えられるようにします。
主要画面とナビゲーションを設計する
生成前に計画を立てる
最初の画面生成前にステータス、所有ルール、SLAを設計
見やすいナビゲーションは装飾ではなく、「どこで確認するか?」の混乱を防ぐための仕組みです。画面はリクエスト作業で人々が自然に取る役割に合わせ、各ビューは次にするべきアクションに集中させます。
依頼者ビュー(提出と追跡)
依頼者体験は荷物追跡のように:明確で落ち着いていて常に最新であるべきです。提出後は単一のリクエストページにステータス、所有者、目標日、次の期待されるステップを表示します。
簡単にできること:
- リクエストを提出して資産を添付する
- 時系列の進捗(シンプルなタイムライン)を見る
- Needs Info に速やかにコメントやファイルで対応する
- 追跡のためにメール+アプリ内で更新を受け取る
トリアージビュー(キューと判断)
ここはコントロールルームです。デフォルトはチーム、カテゴリ、ステータス、優先度でフィルタ可能なキューダッシュボードとし、バルクアクションを用意します。
含めるもの:
- 優先順のキューと「滞留時間」表示
- すばやい割り当てと再割り当て
- 重複検出(タイトル+依頼者+リンクでマッチ)
- 各リクエストを開かずに優先度や期日を操作できる
実行者ビュー(実作業)
実行者には個人の作業負荷画面が必要:「自分のもの、次にやるべきもの、危険に晒されているもの」。締切、依存関係、資産チェックリストを表示して往復を減らします。
管理者ビュー(設定を壊さずに構成)
管理者はチーム、カテゴリ、権限、SLAを一か所で管理できるべきです。高度なオプションはワンクリックで開けるようにし、セーフデフォルトを提供します。
一貫したナビゲーションを保つ
左ナビ(または上部タブ)を使い、役割ベースの領域にマップします:Requests, Queue, My Work, Reports, Settings。複数役割を持つユーザーには関連セクションを全部表示しつつ、最初のランディングは役割に適した画面にします(例:トリアージ担当はQueue着地)。
権限、セキュリティ、監査性
権限は単なるIT要件ではなく、情報漏えいを防ぎつつリクエストを止めないための仕組みです。まずはシンプルに始め、実際のニーズに応じて締めていきます。
役割ベースのアクセス(予測可能に)
少数の役割を定義し、UIで明示します:
- Requester: 提出、自己のリクエスト閲覧、質問への回答、ステータス確認
- Team member(実行担当): 自チームのキュー閲覧、コメント、変更要求、ステータス更新
- Approver: 特定ステップの承認/却下が可能
- Admin: テンプレート、フィールド、チーム、権限ルールを管理
最初は“特例”を避け、誰かに追加アクセスが必要なら役割変更として扱ってください。
機密リクエストを遅延させずに保護する
デフォルトはチームベースの可視性:リクエストは依頼者と割り当てられたチームに見えるようにします。加えて二つのオプション:
- プライベートフィールド(例:予算、社員情報)は特定役割のみ閲覧可
- 制限リクエスト は指定グループのみフルレコードにアクセス可能
大多数は協調作業のままにし、例外のみ制限します。
ゲストの扱いを決める(必要なら)
外部レビュアーや臨時ステークホルダーが必要な場合は一つのモデルを選んでください:
- 期限付きの閲覧リンク(最終草案の共有向け)
- アカウント必須(承認、コメント、トレーサビリティが必要な場合に適)
両方混在も可能ですが、それぞれいつ使うかを文書化しておきます。
監査性:説明責任を自動化する
重要アクションに対してタイムスタンプと実行者をログします:ステータス変更、重要フィールドの編集、承認/却下、最終公開の確認など。監査トレイルはエクスポートしやすく、チームが履歴をすぐ信頼できるよう可視化してください。
騒音を生まない通知とリマインダー
ロックインを防ぐ
スタックを所有する準備ができたらソースコードをエクスポートして制御を保つ
通知はリクエストを前に進めるためのものであり、2つ目の受信箱を作るためのものではありません。目標は単純:正しい人に、正しいタイミングで、次に何をすべきか明確に伝えること。
キーとなるワークフローイベントだけ通知する
まずはアクションを直接促す短いイベントセットから始めます:
- Submitted(依頼者への確認 + 「次に何が起きるか」)
- Assigned(所有者にコンテキスト+リンク)
- Needs Info(依頼者に具体的な質問と期日)
- Approved/declined(依頼者+必要なら下流チームに通知)
- Due soon と overdue(所有者+任意でマネージャーにエスカレーション)
アクションを促さないイベントはアクティビティログに残し、通知は控えましょう。
1〜2チャネルに絞って運用を整える
更新をあちこちに流すのは避けます。多くのチームは主要チャネル1つ(多くはメール)+実働者向けのリアルタイムチャネル(Slack/Teams)で成功しています。
実用ルール:自分が担当する作業にはリアルタイムメッセージ、可視性や記録用にはメールを使う。アプリ内通知は人々が日常的にツールを使うようになってから有効です。
ノイズを減らすリマインダールール
リマインダーは予測可能かつ設定可能に:
- 「Needs Info」や「あなたの対応待ち」項目のデイリーまたは週2回のダイジェスト
- サイレント時間帯(営業時間外は通知を送らず翌朝に送る)
- 明確なしきい値後にのみエスカレーション(例:48時間超過)
更新を行動につなげるテンプレートを使う
テンプレートでメッセージを一貫して読めるものにします。各通知には:
- リクエストタイトル+ID
- 現在のステータスと所有者
- 何が変わったか
- 明確なCTAリンク(例:「情報を追加する」「レビューする」「完了にする」)
こうすると各通知が進展に感じられ、ノイズではなくなります。
SLA、期日、スケジューリング
期日が守られない原因は多くの場合期待の不明瞭さにあります:「どのくらい時間がかかるか?」「いつまでに?」。ワークフローに時間を組み込み、可視化し、一貫性を持たせましょう。
リクエストタイプごとにSLAを定義する
作業に見合ったサービス水準を設定します。例:
- 告知:5営業日
- ニュースレター項目:3営業日
- 経営層コミュニケーション:10営業日
SLAをフィールド駆動にすると、依頼者がタイプを選んだ瞬間に期待リードタイムと最短公開可能日を表示できます。
目標日を自動計算する
手計算は避けます。2つの日付を保存します:
- 希望公開日(依頼者の希望)
- 目標完了日(チームがコミットする日)
目標日はリクエストタイプのリードタイム(営業日換算)や必要なステップ(承認など)を使って自動計算します。公開日が変更されたら即座に目標日を更新し、依頼者の希望日が最短実施可能日より早い場合は「タイトなスケジュール」をフラグします。
衝突を防ぐスケジューリング
キューだけでは衝突は見えません。公開日とチャネル(メール、イントラ、ソーシャル等)でグルーピングしたシンプルなカレンダー/スケジュールビューを追加して、特定日に送信が集中していないか事前に確認・調整できるようにします。
遅延の理由を記録する
遅れが発生したら一つの「遅延理由」を記録します:依頼者待ち、承認待ち、キャパシティ、スコープ変更など。これが積み重なると、見逃しを修正可能なパターンに変えられます。
MVPを作り、実用的な技術アプローチを選ぶ
最速で価値を出すには、臨機応変なチャットやスプレッドシートを置き換える小さく使えるMVPを出すことです。すべての例外を解こうとしないこと。
実際に使ってもらえるMVPの目標
完全なリクエストライフサイクルを支える最小限の機能を目指します:
- 必要項目を収集するインテークフォーム(タイプ、対象、締切、優先度、添付)
- 共有キュー(一か所で「待ち」が見える)
- ワークフローに沿ったシンプルなステータス(例:New → In Review → Approved → Scheduled → Done、サイドパスとして Needs Info、Rejected)
- コメントと@メンションでの確認
- 基本的な通知(依頼者への確認、所有者への割当、ステータス変更)
これらをうまく実装できれば、やり取りは減り即座に単一の真実の源となります。
チームに合ったスタックを選ぶ(欲張らない)
スキル、スピード要件、ガバナンスに合ったアプローチを選んでください:
- ローコード(最速):フォーム+承認+簡単なダッシュボードに向く
- 社内ツールプラットフォーム:認証アプリ、テーブル、フィルタ、管理パネルに強い
- フルスタック構築:カスタム統合、複雑な権限、重い自動化が必要な場合に適す
フルスタックでも早くプロトタイプを作りたい場合は、構造化されたチャットベースの仕様から動く社内アプリを作れるプラットフォーム(例:Koder.ai)のような選択肢で加速できます。プロトタイプを早く出してステークホルダーと反復し、最終的にソースコードをエクスポートして自社ポリシーでデプロイする道も残せます。
検索とフィルタは早めに実装する
50~100件でも、チームはチーム、ステータス、期日、優先度でキューを切り分けたくなります。初日からフィルタを入れて、ツールがスクロール地獄にならないようにしましょう。
データが綺麗になってから分析を追加する
ワークフローが安定してからレポーティングを重ねます:スループット、サイクルタイム、バックログサイズ、SLA達成率など。チームが同じステータスと期日ルールを継続的に使うようになると、より正確なインサイトが得られます。
ローンチ、導入、イテレーション計画
公開日の集中を防ぐ
チャンネルの衝突を発見し直前の競合を避けるためにスケジュールビューを追加
アプリが機能するのは、人々が実際に使い続けた時です。最初のリリースを学習フェーズと捉え、本格展開ではなく新しい「真実の源」を定着させ、実際の挙動に基づいてワークフローを調整しましょう。
小さなパイロットで始める
1〜2チーム、1〜2リクエストカテゴリでパイロットを始めます。頻繁にハンドオフが発生するチームで、プロセスを強化できるマネージャーがいると良いです。ボリュームは管理できる範囲にして、問題対応と信頼構築を迅速に行えるようにします。
パイロット中は旧プロセスを並行運用するのは最小限に。更新がチャットやメールで続く限り、アプリはデフォルトになりません。
軽量なガイドラインを公開する
誰が何を送るべきか(何を送らないか)、必要なリードタイム(例:「標準は72時間」)、更新はどこで行うか(アプリ、DMではない)を短くまとめてください。チームハブにピン留めし、アプリからリンクを張ります(例:/help/requests)。短くして読まれるようにすること。
アクション可能なフィードバックループを作る
依頼者と担当者から週次でフィードバックを集めます。具体的に聞くのは、欠けているフィールド、混乱するステータス、通知スパム等です。実際のリクエストを確認して、人が躊躇した、放棄した、ワークフローを迂回した箇所を洗い出します。
習慣を壊さずに改善する
フォーム項目、SLA、権限を実使用に基づいて小さく予測可能な変更で迭代します。変更は一か所で、"何が変わったか/なぜ変えたか" を明記して告知してください。安定性が定着を生み、頻繁な手直しは採用を損ないます。
定着を測る指標:アプリ経由で提出されたリクエスト比率(外部で処理されたものと比較)、サイクルタイム、手戻り率。これらを元に次の優先順位を決めます。
結果を測り、継続的に改善する
リクエスト管理アプリのローンチは終わりではなく、フィードバックループの始まりです。測定をしないと、ツールはブラックボックス化してチームがステータスを信用しなくなり、結局サイドメッセージに戻ります。
実際に使われるダッシュボードから始める
日々の問いに答える小さなビューを作ります:
- Open requests(現在キューにあるもの)
- Overdue(期日やSLAを過ぎたもの)
- Upcoming(まもなく期日が来るもの)
- Workload by team/owner(ボトルネックや不均衡を発見する)
これらは見てすぐ分かるようにし、10秒で理解できないダッシュボードは誰も見ません。
毎月の指標レビューと意思決定
30〜45分で代表者を集める月次会議を決め、短く安定した指標セットをレビューします(例:
- 初回応答までの平均時間
- 完了までの平均時間
- SLA達成率
- 再オープン率
- リクエスト数の内訳)
会議の終わりには具体的な決定を出します:SLAの調整、インテーク質問の明確化、ステータスの改良、所有権ルールの変更など。変更は簡単なチェンジログで記録してください。
軽量なタクソノミーを維持する
タクソノミーは小さく保てば役に立ちます。カテゴリは少数、オプションでタグを使う設計を目指し、何百ものタイプを作って policing が必要になる事態は避けましょう。
エビデンスに基づいた機能拡張を計画する
基本が安定したら、手作業を減らす改善を優先します:
- 繰り返しリクエストのテンプレート
- 統合(チャット、メール、カレンダー、チケット)
- ポリシー駆動の承認(必要な場合のみ)
- 他ツールから作成・レポート可能なAPI
意見ではなく、利用実績と指標で次に作るものを決めてください。