2025年7月15日·1 分
使用量ベース課金の実装:メータリングと照合作業
使用量ベースの課金の実装:何を計測するか、どこで合計を算出するか、請求前にバグを捕まえる照合チェックの作り方。
使用量ベースの課金の実装:何を計測するか、どこで合計を算出するか、請求前にバグを捕まえる照合チェックの作り方。
使用量課金は、請求書の数字が製品が実際に提供した内容と一致しなくなると壊れます。最初は小さな差(いくつかのAPIコールが抜けている)でも、やがて返金、クレーム、そしてダッシュボードを信頼しなくなる財務チームに発展します。
原因は大抵予測可能です。サービスがクラッシュして使用量を報告できなかった、キューが落ちていた、クライアントがオフラインだったためにイベントが抜けることがあります。リトライやワーカーの再処理、インポートジョブの再実行でイベントが二重に数えられることもあります。時間は独自の問題を生みます:サーバ間のクロックずれ、タイムゾーン、夏時間、遅延到着イベントが誤った請求期間に入ることです。
簡単な例:AI生成ごとに課金するチャット製品が、リクエスト開始時と完了時の2つのイベントを出すことがあります。開始イベントで請求すると失敗分にも課金してしまう可能性があります。完了イベントで請求すると、最終コールバックが届かなければ使用を見逃します。両方で請求すれば二重請求になります。
複数の人が同じ数字を信頼する必要があります:
目標は単に正確な合計だけではありません。説明可能な請求書と速い紛争処理が重要です。行項目を生イベントに遡って検証できないなら、1回の障害で請求が推測になり、そこでバグが重大なインシデントになります。
まず一つの簡単な質問から始めてください:正確には何に対して料金を請求するのか?単位とルールを1分で説明できないなら、システムは推測するようになり、顧客が気づきます。
メーターごとに主要な請求単位を1つ選びます。一般的な選択肢はAPIコール、リクエスト、トークン、計算分数、GB保存、転送GB、席数などです。可能でなければ混合単位(「アクティブユーザ分」など)は避けてください。監査や説明が難しくなります。
使用の境界を定義します。使用がいつ始まりいつ終わるかを具体的に:トライアル中は超過分も課金するのか、それとも上限まで無料か?猶予期間を設けるなら、その期間の使用は後で請求するのか、免除するのか?プラン変更は混乱が起きやすい場所です。按分するのか、許容量を即リセットするのか、次の請求サイクルで適用するのかを決めます。
丸めや最小単位は暗黙にせず書き残してください。例えば:最小秒・分・1,000トークン単位で切り上げる、日次最低料金を適用する、1MBの最小課金インクリメントを課すなど。小さなルールが「なぜ請求された?」の大きなチケットを生みます。
早めに決めておくべきルール:
例:あるチームがProプランから月の途中でアップグレードした場合、アップグレードで許容量をリセットすると同じ月に2つ分の無料許容量を得ることになります。リセットしなければアップグレードで不利になったと感じるかもしれません。どちらの選択も正当になり得ますが、一貫性があり文書化され、テスト可能でなければなりません。
課金対象となるイベントを決め、それをデータとして書き残してください。イベントだけから「何が起きたか」の物語を再生できないなら、紛争時に推測することになります。
「使用が発生した」だけでなく、顧客の支払いに影響するイベントも追跡する必要があります。
ほとんどの請求バグは文脈不足から来ます。面倒なフィールドを今取り込み、サポート・財務・エンジニアが後で問いに答えられるようにしてください。
サポート向けのメタデータも効果的です:リクエストIDやトレースID、リージョン、アプリバージョン、適用された価格ルールのバージョン。顧客が「2:03 PMに二重請求された」と言ったときに、それらのフィールドで何が起きたかを証明し、安全に元に戻し、再発を防げます。
第一のルールは簡単:作業が実際に起きたことを本当に知っているシステムから請求イベントを出すこと。多くの場合、それはブラウザやモバイルではなくサーバ側です。
クライアント側カウンタは簡単に偽造でき、失われやすいです。ユーザーはリクエストをブロックしたり、再生したり、古いコードを実行したりできます。悪意がなくてもモバイルアプリはクラッシュし、時計はずれ、リトライが発生します。クライアント信号を読む必要がある場合は、それをヒントと見なして請求の根拠にしないでください。
実用的なアプローチは、永続化された記録を残すなど不可逆なポイントで使用量を発行することです。信頼できる発行ポイントの例:
オフラインのモバイルは主な例外です。例えば Flutter アプリが接続なしで動作する必要がある場合、ローカルで使用を記録して後でアップロードすることがあります。ガードレールを追加してください:ユニークなイベントID、デバイスID、単調増加のシーケンス番号を含め、サーバ側で検証(アカウント状態、プラン上限、重複ID、不可能なタイムスタンプ)を行います。アプリが再接続したとき、サーバは冪等にイベントを受け入れ、リトライで二重課金されないようにします。
イベントのタイミングはユーザーが期待する見え方に依存します。APIコールのようにダッシュボードで使用量をリアルタイムに見る必要があるならリアルタイムが適切です。数分ごとの準リアルタイムで十分な場合も多く、コストも安く済みます。バッチは高ボリューム信号(ストレージスキャン等)に向きますが遅延を明示し、遅延データが過去の請求を黙って変更しないよう同じ原則を適用してください。
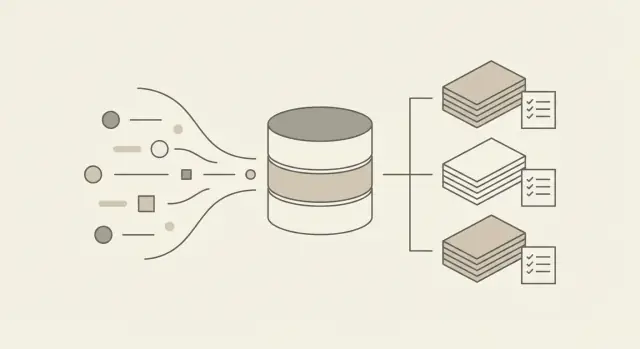
後で役立つために冗長に感じる2つを用意してください:不変の生イベント(何が起きたか)と導出された合計(請求するもの)。生イベントがソース・オブ・トゥルースで、集計は請求やダッシュボード用に使います。
合計は一般的に二つの場所で計算できます。データベース内(SQLジョブ、マテリアライズドテーブル、スケジュールクエリ)で行うと運用は単純でデータに近いままです。専用の集約サービス(イベントを読みロールアップを書く小さなワーカー)はバージョン管理、テスト、スケールがしやすく、製品横断で一貫したルールを強制できます。
生イベントはバグ、返金、紛争から守ります。集計は遅い請求や高価なクエリから守ります。集計だけを保存すると、一つの誤ったルールで履歴が永久に壊れます。
実用的な構成:
集計ウィンドウを明示してください。請求のタイムゾーンを決め(顧客ごと、または全員UTCなど)、それを厳守します。「日」の境界はタイムゾーンで変わり、顧客は使用が日をまたいで移ると気づきます。
遅延や順序の入れ替わったイベントは普通に起きます(モバイルのオフライン、リトライ、キュー遅延)。遅延イベントが届いたからといって過去の請求書を黙って書き換えないでください。締めて凍結するルールを使い、請求期間が既に請求済みなら次の請求で調整として扱います。
例:APIコールを月次で課金するなら、ダッシュボード用に時間ごとのロールアップ、アラート用に日次ロールアップ、請求向けに月次の凍結合計を作れます。200件が2日遅れて到着したら記録はしますが、過去月の請求書を書き換えずに次月で+200の調整として請求します。
動く使用量パイプラインは大抵データフローと強いガードレールの組み合わせです。順序を正しくすれば、後で価格を変えても手作業で全部を再処理する必要がなくなります。
イベントが到着したら、それをすぐに検証して正規化します。必須フィールドをチェックし、単位変換(バイト→GB、秒→分)を行い、タイムスタンプを明確なルールに合わせて制限します(イベント時刻か受信時刻か)。無効なら理由つきでRejectedとして保存し、黙って捨てないでください。
正規化後は追記のみの考え方を保ち、履歴を直接「修正」しないでください。生イベントがソース・オブ・トゥルースです。
多くの製品に有効なフロー:
その後、請求書バージョンを凍結します。「凍結」とは次の問いに答えられる監査トレイルを保持することです:どの生イベント、どのデデュープルール、どの集計コードバージョン、どの価格ルールがこれらの行項目を生成したか。後で価格を変えたりバグを直したら、新しい請求書改訂を作成し、黙って上書きしないでください。
二重請求と使用漏れは通常同じ根本問題から来ます:イベントが新規か重複か失われたかを判断できないこと。これは巧妙な課金ロジックというより、イベントのID管理と検証を厳格にする問題です。
冪等キーは第一の防衛線です。実世界のアクションに対して安定したキーを生成してください。良いキーは決定論的で、請求単位ごとに一意です。例えば:tenant_id + billable_action + source_record_id + time_bucket(時間ベースの単位の場合はタイムバケットを使う)。最初の耐久書き込み(受信DBやイベントログ)で一意制約を課し、重複が入り込めないようにします。
リトライやタイムアウトは普通に起きるので、それを想定して設計します。クライアントは504の後に同じイベントを再送するかもしれません。方針は:リピートを受け入れるが二度数えないこと。受信を冪等にし、保存されたイベントから集計してください。
検証は「不可能な使用」が合計を壊すのを防ぎます。受信時と集計時の両方で検証を行ってください。
使用漏れは検出が最も難しいため、取り込みエラーを一級データとして扱ってください。失敗したイベントは成功イベントと同じフィールドを持つ別テーブルに保存し、エラー理由とリトライ回数を含めます。
照合チェックは「多く請求した」「使用を見逃した」を顧客より先に捕まえる地味なガードレールです。
まずは同じ時間窓を二箇所で照合します:生イベントと集計。固定ウィンドウ(例:昨日のUTC)を選び、件数、合計、ユニークIDを比較します。小さな違いは起こります(遅延イベント、リトライ)が、それらは既知のルールで説明できるべきです。
次に、請求した額と価格適用後の合計を照合します。請求書は価格が適用された使用スナップショットから再現可能であるべきです:正確な使用合計、正確な価格ルール、通貨、丸めのルール。もし後で再計算すると請求書が変わるなら、それは請求書ではなく推測です。
日次のサニティチェックは「間違った計算」ではない問題を早く見つけます:
問題を見つけたらバックフィルプロセスが必要です。バックフィルは意図的に行い、記録してください。何が変わったか、どの窓、どの顧客、誰がトリガーしたか、理由を残します。調整は会計エントリとして扱い、黙って編集しないでください。
シンプルな紛争ワークフローがサポートを落ち着かせます。顧客が料金に疑問を持ったら、生イベントから同じスナップショットと価格バージョンで請求書を再現できるべきです。これにより漠然としたクレームが修正可能なバグになります。
ほとんどの請求火災は複雑な数学ではなく、小さな仮定が引き起こします。月末、アップグレード後、リトライストーム時など最悪のタイミングで壊れます。注意深くいることは、時間・識別・ルールについて一つの真実を選び、それを曲げないことに尽きます。
以下は成熟チームでも繰り返し現れる問題です:
例:顧客が20日にアップグレードし、イベントプロセッサがタイムアウト後に1日のデータを再試行したとします。冪等キーとルールのバージョン管理がなければ、19日のデータが重複して入り、1〜19日分が新レートで二重に価格付けされる可能性があります。
ここでは簡単な例を示します。顧客 Acme Co を、3つのメーター(APIコール、ストレージ(GB日)、プレミアム機能実行)で請求します。
アプリが1日に出すイベントの例(1月5日)。後で物語を再構築しやすくするフィールドに注目してください:event_id、customer_id、occurred_at、meter、quantity、冪等キー。
{"event_id":"evt_1001","customer_id":"cust_acme","occurred_at":"2026-01-05T09:12:03Z","meter":"api_calls","quantity":1,"idempotency_key":"req_7f2"}
{"event_id":"evt_1002","customer_id":"cust_acme","occurred_at":"2026-01-05T09:12:03Z","meter":"api_calls","quantity":1,"idempotency_key":"req_7f2"}
{"event_id":"evt_1003","customer_id":"cust_acme","occurred_at":"2026-01-05T10:00:00Z","meter":"storage_gb_days","quantity":42.0,"idempotency_key":"daily_storage_2026-01-05"}
{"event_id":"evt_1004","customer_id":"cust_acme","occurred_at":"2026-01-05T15:40:10Z","meter":"premium_runs","quantity":3,"idempotency_key":"run_batch_991"}
月末に集計ジョブが customer_id、meter、請求期間で生イベントをグループ化します。1月の合計は月全体の合計です:APIコールは1,240,500、ストレージGB日が1,310.0、プレミアム実行が68でした。
さて、2月2日に遅延イベントが届き、1月31日に属するものだったとします。occurred_at(受信時刻ではなく)で集計しているので1月の合計が変わります。あなたは次のいずれかをするでしょう:(a)次の請求書に + 調整行を生成する、または(b)ポリシーが許せば1月を再発行する。
照合でここにバグが見つかります:evt_1001 と evt_1002 は同じ idempotency_key(req_7f2)を共有しています。チェックは「1つのリクエストに対して二つの請求イベント」をフラグし、請求前に一つを重複としてマークします。
サポートは素直に説明できます:「同じAPIリクエストがリトライにより二度報告されました。重複イベントを削除して請求は1回分になっています。修正された合計を反映する調整が請求書に含まれています。」
請求をオンにする前に、使用量システムを小さな財務台帳として扱ってください。同じ生データを再生して同じ合計が得られないなら、夜中に「不可能な」請求を追うことになります。
このチェックリストを最終ゲートとして使ってください:
実用的なテスト:一人の顧客を選び、過去7日分の生イベントをクリーンなDBにリプレイして使用量と請求書を生成します。本番と結果が違うなら、あなたは数学の問題ではなく決定性(再現性)の問題を抱えています。
最初のリリースはパイロットのように扱ってください。一つの請求単位(例:「APIコール」や「GB保存」)と一つの照合レポートを選び、想定した請求額と実際の請求額を比較します。それが1サイクル安定するまで次の単位を追加しないでください。
サポートと財務が初日から成功するように、内部用のページを用意して両サイドを見せてください:生イベントと最終的に請求書に載る計算済み合計。顧客が「なぜ請求された?」と聞いたら、数分で答えられる単一画面を用意するのが理想です。
実際にお金を請求する前に、現実をリプレイしてください。ステージングデータで1ヶ月分の使用をシミュレートし、集計を実行して請求書を生成し、少数のアカウントを手動カウントした期待値と比較します。低使用、スパイク、安定パターンの顧客を数社選び、生イベント、日次集計、請求書行の合計が一致するか検証します。
メータリングサービス自体を構築しているなら、Koder.ai (koder.ai) のようなvibe-codingプラットフォームは内部管理UIとGo + PostgreSQLバックエンドのプロトタイプを素早く作る手段になり、ロジックが安定したらソースコードをエクスポートできます。
請求ルールを変更するときは、リスクを減らすリリース手順を取ってください:
使用量課金が壊れるのは、請求書の合計が製品が実際に提供した内容と一致しないときです。
一般的な原因:
対処は「より良い計算」ではなく、イベントを信頼できる形で取り込み、重複を排除し、説明可能にすることです。
メーターごとに一つの明確な単位を選び、それを一文で定義してください(例:「1回の成功したAPIリクエスト」や「1件のAI生成完了」)。
その後、顧客と揉めやすいルールを文書化します:
単位とルールを短く説明できないなら、その設計は後で監査やサポートで苦労します。
消費のみでなく、支払いに影響するイベントも追跡してください。
最低限:
これにより、プラン変更や修正が起きても請求を再現できます。
後で「なぜ請求されたか」を説明できる文脈を取り込みます:
occurred_at のUTCタイムスタンプ と 受信時タイムスタンプサポート向けの追加情報(リクエスト/トレースID、リージョン、アプリバージョン、適用された価格ルールのバージョン)は、紛争対応を大幅に速めます。
作業が実際に起きたことを知っているシステム(多くはバックエンド)からイベントを発行してください。ブラウザやモバイルからだけだと偽装や紛失が起きやすいです。
信頼できる発行ポイントの例:
オフラインのモバイルだけは例外で、ローカルに蓄積して後でアップロードする場合は冪等ID、デバイスID、単調増加のシーケンス番号などのガードレールを追加し、サーバ側で検証してください。
両方必要です:
集計をDB内(SQLやマテリアライズドテーブル)で行うか、専用の集約サービスで行うかは運用性とバージョン管理の好みに依存しますが、両層を保持することを推奨します。生イベントだけだと遅く、高コストになるし、集計だけだと一度の誤りで履歴が壊れます。
重複請求を防ぐには、イベントが新規か重複か紛失かを判断できる仕組みが必要です。
基本は冪等キーです。実世界のアクションに対して決定論的で一意なキーを生成してください(例:tenant_id + billable_action + source_record_id + time_bucket)。最初の永続書き込みで一意制約を掛け、重複が入らないようにします。
リトライは普通に起きるので、受け取りとカウントを分離します:受信は冪等に行い、カウントは保存されたイベントから集計します。受信時と集計時の両方で検証を行い、負の数量や単位の不整合など「不可能な使用」を防ぎます。
明確なポリシーを決めて自動化してください。
実用的なデフォルト:
occurred_at(イベント時刻)で集計し、受信時刻では集計しないこれで過去請求が裏で変わって顧客を驚かせることを避けられます。
毎日、小さくて地味なチェックを実行してください。それが高額なバグを早期に捕まえます。
有用な照合:
差分は遅延やデデュープなど既知ルールで説明できるべきで、謎の差分はまずいサインです。
請求を説明できるように紙芝居(トレース)を用意してください。
サポートはチケットで次のことを短時間で答えられるべきです:
これで紛争は迅速に処理できます。