2025年11月03日·1 分
マルチテナントSaaSパターン:分離、スケール、AI設計
マルチテナントSaaSの一般的なパターン、テナント分離のトレードオフ、スケーリング戦略を解説。AI生成アーキテクチャが設計・レビューをどう速めるかも紹介します。
マルチテナントとは(専門用語を除いて)
マルチテナントとは、1つのソフトウェア製品が同じ稼働中のシステムから複数の顧客(テナント)にサービスを提供することを指します。各テナントは「自分専用のアプリがある」と感じますが、裏ではウェブサーバ、コードベース、そしてしばしばデータベースなどのインフラを共有しています。
役立つメタファーはマンションです。各住戸は鍵付きで(データや設定)、エレベーターや配管、管理チーム(アプリの計算、ストレージ、運用)は共有します。
なぜチームはマルチテナントを選ぶのか
多くのチームがマルチテナントSaaSを選ぶのはトレンドだからではなく、効率的だからです:
- 顧客あたりのコスト削減: 共有インフラは、顧客ごとにフルスタックを立ち上げるより通常安価です。
- 運用が簡単: 監視、パッチ、セキュリティを1つのプラットフォームで行える(数百の小さなデプロイを管理する代わりに)。
- 迅速な提供: 改善は全員に同時に届けられ、顧客間での「バージョンドリフト」を避けられます。
失敗しやすい箇所
代表的な失敗モードはセキュリティとパフォーマンスです。
セキュリティ面では、テナント境界があらゆる場所で強制されていないと、バグでデータが流出する可能性があります。こうした漏洩は大抵派手な「ハック」ではなく、フィルタの抜け、権限チェックの誤設定、テナントコンテキストなしで動くバックグラウンドジョブなど日常的なミスで起きます。
パフォーマンス面では、共有リソースにより1つの利用の激しいテナントが他を遅くすることがあります。この「ノイジーネイバー」効果は、遅いクエリ、バーストするワークロード、ある顧客がAPI容量を過剰に消費する状況などで現れます。
この記事で扱うパターンの概要
この記事では、リスク管理のためにチームが使う構成要素を取り上げます:データ分離(DB/スキーマ/行)、テナントに配慮したアイデンティティと権限、ノイジーネイバー対策、そしてスケーリングや変更管理の運用パターンです。
核心のトレードオフ:分離 vs 効率
マルチテナンシーは、「どれだけを共有し、どれだけをテナントごとに専有するか」のスペクトラム上の選択です。以下のアーキテクチャパターンは、その線上の異なる点を表します。
共有リソースと専用リソース:基本のスペクトラム
一方の端では、テナントはほぼすべてを共有します:同じアプリインスタンス、同じデータベース、同じキュー、同じキャッシュ――論理的に tenant_id 等で分離します。これは通常、容量をプールできるため最も安価で運用が簡単です。
反対側の端では、テナントごとに「スライス」を割り当てます:別のデータベース、別のコンピュート、場合によっては別デプロイまで。安全性や制御は向上しますが、運用コストと複雑さも増します。
なぜ分離とコストが逆方向に働くのか
分離は、あるテナントが他のデータにアクセスしたりパフォーマンス予算を使い切ったりする可能性を減らします。また、特定の監査やコンプライアンス要件を満たしやすくなります。
効率は、アイドル容量を多数のテナントで償却できるときに向上します。共有インフラはサーバ数を減らし、より単純なデプロイパイプラインで動き、個別の最悪ケースではなく総合的な需要に基づいてスケールできます。
よくある意思決定要因
適切な位置は哲学的なものではなく、制約で決まります:
- SLAと顧客期待: 厳格な稼働率やレイテンシ目標はより分離を促します。
- コンプライアンスとデータ居住要件: 専用ストレージや専用環境を強制することがあります。
- 成長段階: 初期プロダクトは速く動くため共有で始め、後で大口顧客向けに専用化することが多いです。
- 運用成熟度: 分離が増えると監視、パッチ適用、マイグレーションの対象が増えます。
パターン選びの簡単な考え方
2つの質問を自分に投げかけてください:
-
あるテナントが誤動作または侵害されたときの被害範囲(blast radius)はどれくらいか?
-
その被害範囲を小さくするためのビジネスコストはどれくらいか?
被害範囲を極小にする必要があれば、より専用のコンポーネントを選びます。コストとスピードが重要なら、より共有して、強力なアクセス制御、レート制限、テナントごとの監視に投資して安全性を確保します。
マルチテナントモデルの俯瞰
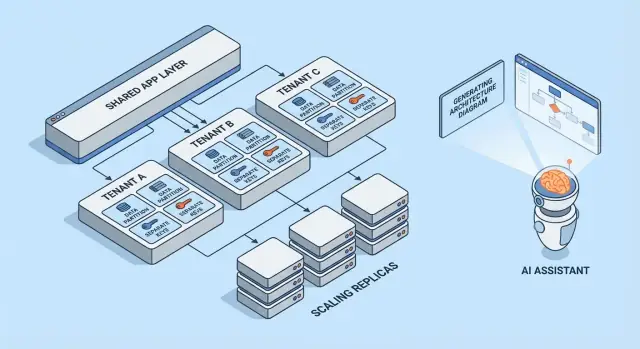
マルチテナンシーは一つのアーキテクチャではなく、顧客間でインフラをどのように共有(あるいは分離)するかの複数の方法です。最良のモデルは、求められる分離レベル、想定テナント数、チームが扱える運用負荷によって決まります。
1) シングルテナント(専用)— 基準となるモデル
各顧客が自分専用のアプリスタック(少なくとも隔離されたランタイムとDB)を持つモデルです。セキュリティとパフォーマンスの面で考えやすい一方、テナントあたりのコストが高く、運用の拡張が遅くなることが多いです。
2) 共有アプリ + 共有DB — コスト最小だが注意が必要
全テナントが同じアプリと同じデータベースで動作します。コストは最小になることが多いですが、クエリ、キャッシュ、バックグラウンドジョブ、分析エクスポートなど、すべての箇所でテナントコンテキストを厳密に管理する必要があります。単一のミスがテナント間のデータ漏洩を招きうる点に注意してください。
3) 共有アプリ + テナント別DB — 分離強化だが運用増
アプリは共有しつつ、各テナントが独自のデータベース(あるいはDBインスタンス)を持つモデルです。インシデント時の被害範囲が小さく、テナント単位のバックアップや復元がしやすく、コンプライアンス対応が簡単になる利点があります。代わりにデータベースをプロビジョニング、監視、マイグレーション、確保する運用負荷が増えます。
4) 大口テナント向けのハイブリッドモデル
多くのSaaSは混合アプローチを採用します:大多数は共有インフラに置き、大口や規制の厳しいテナントには専用DBや専用コンピュートを提供します。実用的な最終形であることが多いですが、誰が対象か、費用はどうなるか、アップグレードはどうロールアウトするかなど、明確なルールが必要です。
各モデルの内部での分離技術を深掘りしたい場合は、/blog/data-isolation-patterns を参照してください。
データ分離パターン(DB、スキーマ、行)
データ分離は単純な問いに答えます:「ある顧客が他の顧客のデータを見たり影響を与えたりできるか?」 共通のパターンは3つで、それぞれセキュリティと運用面で異なる影響を持ちます。
行レベル分離(共有テーブル + tenant_id)
すべてのテナントが同じテーブルを共有し、各行に tenant_id カラムが含まれるモデルです。インフラを最小化でき、レポーティングや分析が簡単なので、小〜中規模のテナントには最も効率的です。
リスクは明白です:どんなクエリでも tenant_id フィルタを忘れるとデータが漏れる可能性があります。たった1つの管理用エンドポイントやバックグラウンドジョブが弱点になり得ます。緩和策は:
- 共有のデータアクセス層でテナントフィルタを強制する(開発者が手動でフィルタを書く必要を減らす)
- 利用可能ならデータベース機能(行レベルセキュリティ:RLSなど)を使う
- テナント間アクセスを意図的に試す自動化テストを追加する
- よく使われるアクセスパス向けにインデックスを張る(多くは
(tenant_id, created_at)や(tenant_id, id)など)
スキーマごとのテナント(同一DB内でスキーマ分離)
各テナントに独自のスキーマを割り当てます(例:tenant_123.users, tenant_456.users)。行レベル共有と比べて分離が強く、テナントのエクスポートやチューニングが容易になります。
トレードオフは運用負荷です。マイグレーションは多くのスキーマに対して実行する必要があり、失敗時の影響は複雑になります:9,900テナントは成功して100テナントで詰まる、という状況があり得ます。ここでは監視とツールが重要で、マイグレーションプロセスに明確なリトライと報告の仕組みが必要です。
データベースごとのテナント(テナントごとに別DB)
各テナントが別々のデータベースを持つモデルです。分離は強力で、アクセス境界が明確になり、あるテナントの重いクエリが別テナントに影響を与えにくくなり、単一テナントのバックアップ/復元も容易です。
欠点はコストとスケーリングです:管理すべきデータベースが増え、コネクションプールが増え、アップグレードやマイグレーション作業が増えます。多くのチームは大口や規制の厳しいテナントにこのモデルを割り当て、小規模テナントは共有を維持します。
テナント成長に合わせたシャーディングと配置戦略
実際のシステムはこれらを混ぜます。よくある経路は、初期成長は行レベル分離で始め、大きくなったテナントをスキーマやDBへ「昇格」させることです。
シャーディングは配置層を追加します:どのテナントをどのDBクラスタに置くか(リージョン、サイズ階層、ハッシュによる)を決めます。重要なのはテナント配置を明示的かつ変更可能にすること――テナントを移動できるようにして、アプリを書き換えずにシャードを追加してスケールできるようにします。
アイデンティティ、アクセス、テナントコンテキスト
マルチテナンシーは意外と普通のミスで失敗します:フィルタの抜け、テナントを跨いで共有されたキャッシュオブジェクト、あるいはリクエストが誰のためかを“忘れる”管理機能など。解決策は大きな単一のセキュリティ機能ではなく、リクエストの最初のバイトから最後のDBクエリまで一貫したテナントコンテキストを持つことです。
テナント識別("誰か"を知る方法)
多くのSaaSは1つの主要識別子を決め、それ以外を便利機能として扱います:
- サブドメイン:
acme.yourapp.comはユーザーにとって分かりやすく、テナントブランド体験に合います。 - ヘッダ: APIクライアントや内部サービス向け(ただし認証されたものでなければならない)。
- トークンのクレーム: サインされたJWT(またはセッション)に
tenant_idを含めると改ざんが難しくなります。
1つの真実のソースを選び、ログにも記録してください。複数の信号(サブドメイン + トークン)をサポートする場合は優先順位を定義し、あいまいなリクエストは拒否します。
リクエストスコーピング(すべてのクエリをテナント内に保つ方法)
良いルールは:一度 tenant_id を解決したら、下流はその値を単一の場所(リクエストコンテキスト)から読むことで再導出しないことです。
一般的なガードレール:
- ミドルウェアが
tenant_idをリクエストコンテキストに付ける - データアクセスヘルパーが
tenant_idを必須パラメータにする - データベース側で(行レベルポリシー等)強制して、ミスが失敗(fail closed)するようにする
handleRequest(req):
tenantId = resolveTenant(req) // subdomain/header/token
req.context.tenantId = tenantId
return next(req)
認可の基本(テナント内の役割)
認証(ユーザーが誰か)と認可(何ができるか)は分離してください。
典型的なSaaSロールは Owner / Admin / Member / Read-only ですが、重要なのはスコープです:あるユーザーがテナントAではAdminで、テナントBではMemberということがあり得ます。権限はグローバルではなくテナント毎に保存してください。
テナント間漏洩を防ぐ(テストとガードレール)
テナント間アクセスはトップクラスのインシデントとして扱い、事前に防止します:
- Tenant A として認証した状態で Tenant B のデータを読もうとする自動テストを追加する
- テナントフィルタの抜けを出荷しにくくする(リンタ、クエリビルダ、必須のテナントパラメータ)
- トークンとサブドメインのテナント不一致など、疑わしいパターンをログとアラートで監視する
より深い運用チェックリストが欲しければ、/security にこれらのルールをエンジニアリングランブックとして紐付け、コードと一緒にバージョン管理してください。
データベース以外の分離
マルチテナンシーを素早くプロトタイプ
React、Go、PostgreSQLのスケルトンを生成して早期にテナントスコープをテスト。
データベース分離は全体の半分に過ぎません。実際のマルチテナントインシデントの多くは、アプリ周辺の共有配管(キャッシュ、キュー、ストレージ)で発生します。これらのレイヤーは高速で便利ですが、誤ってグローバルにしてしまいやすいです。
共有キャッシュ:キー衝突とデータ漏洩の防止
複数のテナントがRedisやMemcachedを共有する場合の基本ルールは単純:テナント非対応のキーを保存しないこと。
実務的なパターンは、すべてのキーを安定したテナント識別子でプレフィックスすること(メールドメインや表示名ではなくIDを使う)。例: t:{tenant_id}:user:{user_id}。これにより:
- 内部IDが同じであってもテナント間の衝突を防げる
- サポートインシデントやマイグレーション時に接頭辞で一括無効化しやすくなる
また、グローバル共有して良いもの(公開されるフラグ、静的メタデータ等)を明確にし、ドキュメント化してください。意図せぬグローバル化はテナント間露出の一般的な原因です。
テナント対応のレート制限とクォータ
データが分離されていても、テナントは共有コンピュートに影響を与える可能性があります。エッジでテナント対応の制限を入れましょう:
- APIごとのテナント単位のレートリミット(さらにテナント内ユーザー単位も)
- エクスポート、レポート生成、AI呼び出しなど高コスト操作のクォータ
制限は可視化(レスポンスヘッダ、UI通知)しておくと、顧客はスロットリングがポリシーであってシステム不安定ではないと理解できます。
バックグラウンドジョブ:キューをテナントごとに分離
単一共有キューは一つの重いテナントにワーカー時間を独占される恐れがあります。
よく使われる対策:
- プラン別にキューを分ける(例:
free,pro,enterprise) - テナントIDをハッシュしてN個のバケットに分けるパーティションキュー
- 各テナントに公正なスライスを与えるテナント対応スケジューリング
ジョブペイロードとログにテナントコンテキストを必ず渡して、誤テナント副作用を避けてください。
ファイル/オブジェクトストレージ:パス、ポリシー、キーの分離
S3/GCSスタイルのストレージでは、分離は通常パスとポリシーで行います:
- テナントごとのバケット(強い分離、運用負荷増)
- 共有バケットにテナントプレフィックス(簡便だがIAMと署名URLに注意)
どちらを選ぶにせよ、アップロード/ダウンロード時にはUIだけでなく毎回テナント所有を検証してください。
ノイジーネイバーと公平なリソース利用の対処
マルチテナントシステムはインフラを共有するため、あるテナントが意図せず(あるいは意図的に)過剰に資源を消費すると他が影響を受けます。これがノイジーネイバー問題です。
ノイジーネイバーの現れ方
例として、年次データをCSVにエクスポートする機能で、テナントAが9:00に20件のエクスポートをスケジュールすると、CPUやDB I/Oが飽和し、テナントBの通常の画面表示がタイムアウトする――Bは何も特別なことをしていないのに、という状況が想像できます。
リソース制御:制限、クォータ、ワークロード整形
防止策は明確なリソース境界から始まります:
- レート制限(1秒あたりのリクエスト数)をテナントとエンドポイントごとに設定して高コストAPIの乱用を防ぐ
- クォータ(日次・月次)をエクスポート、メール、AI呼び出し、バックグラウンドジョブなどに設ける
- ワークロード整形: エクスポートやインポートのような重いタスクは、テナントごとの同時実行数制限と優先度ルールのあるキューに投入する
実践的なパターンは対話的トラフィックとバッチ作業を分離することです:ユーザー向けのリクエストは高速レーンに置き、その他を制御されたキューに押し込む。
テナントごとのサーキットブレーカーとバルクヘッド
閾値を越えたテナントに対して安全弁をつけます:
- サーキットブレーカー: エラー率、レイテンシ、キュー深度が閾値を越えたときに高コスト操作を一時拒否または延期する
- バルクヘッド: 共有プール(DBコネクション、ワーカースレッド、キャッシュ)を分離して、あるテナントがグローバル容量を枯渇させられないようにする
適切にやれば、テナントAは自分のエクスポート速度を落とすだけでテナントBをダウンさせることはありません。
テナントを専用キャパシティへ移すタイミング
テナントを専用リソースへ移すのは、共有前提を継続的に超えると判断されたときです:持続的に高いスループット、予測できないスパイク、重要なビジネスイベントに紐づく負荷、厳格なコンプライアンス要件、あるいはカスタムチューニングが必要な場合など。簡単なルールは:他のテナントを守るために支払顧客を恒常的に制限する必要があるなら、恒久的なスロットリングではなく専用キャパシティ(または上位プラン)に移すべき、ということです。
マルチテナントSaaSで機能するスケーリングパターン
SaaSプロトタイプをデプロイ
共有準備ができたらホスティングとデプロイでプロトタイプを公開。
マルチテナントのスケーリングは「サーバを増やす」ことよりも、あるテナントの成長が他に驚きを与えないようにすることです。良いパターンはスケールを予測可能、測定可能、そして可逆にします。
ステートレスサービスの水平スケーリング
まずWeb/API層をステートレスにします:セッションは共有キャッシュに保存するかトークンベース認証を使い、アップロードはオブジェクトストレージへ、長時間実行はバックグラウンドジョブへ移します。ローカルのメモリやディスクに依存しなくなれば、ロードバランサー背後にインスタンスを追加して水平にスケールできます。
実用的なヒント:テナントコンテキストはエッジで保持し(サブドメインやヘッダ由来)、全てのリクエストハンドラに渡してください。ステートレスはテナントを無視することではなく、スティッキーサーバなしでテナントを意識することを意味します。
テナントごとのホットスポット:発見と平滑化
多くのスケーリング問題は「一部のテナントが異なる」ことに由来します。以下のようなホットスポットを監視してください:
- ある単一テナントが異常に大きなトラフィックを生成
- 非常に大規模なデータセットを持つ少数のテナント
- バッチ的な使用(月末レポート、夜間インポート)
平滑化の戦術は、テナント単位のレート制限、キューを使った取り込み、テナント専用の読み取りキャッシュ経路、重いテナントを別ワーカープールにシャードするなどです。
読み取りレプリカ、パーティショニング、非同期ワークロード
読み取り重視のワークロード(ダッシュボード、検索、分析)には読み取りレプリカを利用し、書き込みはプライマリに留めます。パーティショニング(テナント別、時間別、またはその組合せ)はインデックスを小さくし、クエリを高速にします。エクスポート、MLスコアリング、Webhookのような重いタスクは非同期ジョブにして冪等性を保ち、リトライで負荷が倍増しないようにします。
キャパシティプランニングの指標と簡単な閾値
指標はシンプルかつテナント対応にします:p95レイテンシ、エラー率、キュー深度、DB CPU、テナント別リクエスト率など。明快な閾値(例:「キュー深度 > N が10分続く」や「p95 > X ms」)を設定し、自動スケールや一時的なテナント制限をトリガーして、他テナントが影響を受ける前に対処します。
テナント単位の可観測性と運用
マルチテナントシステムは通常、まず全体にではなく個別のテナントやプラン層で壊れます。ログやダッシュボードで「どのテナントが影響を受けているか」を数秒で答えられないと、オンコールは推理に多くの時間を取られます。
テナント対応のログ、メトリクス、トレース
テナントコンテキストを一貫してテレメトリに含めることから始めます:
- ログ: 各リクエストとバックグラウンドジョブに
tenant_id,request_id, 安定したactor_id(ユーザー/サービス)を含める - メトリクス: カウンタとレイテンシヒストグラムをテナント階層(例:
tier=basic|premium)と主要エンドポイントで分解して出力する - トレース: トレース属性としてテナントコンテキストを伝播し、遅いトレースを特定テナントに絞ってDBやキャッシュ、外部呼び出しでどこに時間がかかっているかを見る
カードinality(固有値の数)を管理することが重要です:すべてのテナントに対して個別メトリクスを出すとコストが高くなります。よくある妥協は、デフォルトでは階層別メトリクスにし、必要なときにテナント単位でドリルダウンすること(例:「トラフィック上位20テナント」や「SLO違反中のテナント」だけをサンプリングしてトレースする)です。
テレメトリにおける機密データ漏洩の回避
テレメトリはデータの輸出経路です。プロダクションデータと同様に扱ってください。
コンテンツよりIDを優先:名前やメール、トークン、クエリペイロードではなく customer_id=123 のようにログを残す。ロガー/SDKレイヤでのマスキングやブロックリスト(Authorizationヘッダ、APIキーなど)を用意し、サポートのためのデバッグペイロードは共有ログではなくアクセス制御された別システムに保存する。
テナント階層ごとのSLO(過剰な約束をしない)
実際に強制できるSLOを定義してください。プレミアムテナントにはより厳しいレイテンシ/エラー予算を与えられるかもしれませんが、それはレート制限、ワークロード分離、優先キューなどのコントロールがある場合に限ります。階層別のSLOをターゲットとして公開し、階層ごとと上位顧客の一部で追跡します。
オンコール用ランブック:マルチテナントでよくあるインシデント
ランブックは「影響を受けるテナントを特定する」ことから始め、次に最速で隔離するアクションを示すべきです:
- ノイジーネイバー: 当該テナントをスロットル、重いジョブを停止、または低優先度キューに移す
- DBホットスポット/暴走クエリ: クエリタイムアウトを有効化、テナント別の上位クエリを調査、インデックス追加やエンドポイント制限を検討
- テナントコンテキストバグ(データ混在): 直ちに機能フラグやエンドポイントを無効化し、アクセススコープを検証
- バックグラウンドジョブの詰まり: テナント別キューをドレイン、同時実行を制限し、冪等性を担保してリプレイする
運用上の目標は単純です:テナント単位で検出し、テナント単位で封じ、全員に影響を及ぼさずに復旧すること。
デプロイ、マイグレーション、テナント別リリース
マルチテナントSaaSは出荷のリズムを変えます。あなたは「アプリ」をデプロイしているのではなく、多くの顧客が依存する共有ランタイムと共有データパスをデプロイしています。目標は全テナントで同時に大規模なアップグレードを強制せずに新機能を提供することです。
ローリングデプロイと低ダウンタイムマイグレーション
混在バージョンを短期間許容するデプロイ(ブルー/グリーン、カナリア、ローリング)を優先してください。それはデータベース変更が段階的である場合にのみ成り立ちます。
実用的なルールは 拡張 → マイグレート → 収縮 です:
- 拡張(expand): 既存コードを壊さずに新しいカラム/テーブル/インデックスを追加する
- マイグレート(migrate): バックフィルをバッチ(しばしばテナント単位)で実行して検証する
- 収縮(contract): すべてのアプリインスタンスが古いフィールドを参照しなくなってから不要なフィールドを削除する
ホットテーブルのバックフィルは段階的に行い(スロットリングを入れる)、そうしないとマイグレーション中に自らノイジーネイバー事象を作り出すことになります。
テナント単位のフィーチャーフラグで安全にローアウト
テナント単位のフィーチャーフラグを使うと、コードはグローバルにデプロイしつつ挙動を選択的に有効化できます。
これにより:
- 一部テナントでの早期アクセスプログラムが可能
- 問題が起きたテナントだけで機能を無効にして即ロールバックできる
- デプロイを分岐させずにA/B実験ができる
フラグシステムは監査可能であるべきです:誰がいつどのテナントで有効にしたかを記録してください。
バージョニングと下位互換性の期待値
一部のテナントが設定や統合、利用パターンで遅れを取ることを前提に設計してください。APIやイベントは明確にバージョン管理し、新しいプロデューサが古いコンシューマを壊さないようにします。
内部で設定すべき一般的な期待事項:
- 新リリースはマイグレーション期間中、古い形と新しい形の両方を読み取れること
- 廃止は公表タイムラインを伴う(内部メモと顧客向けメールテンプレートを用意)
テナント固有の設定管理
テナント設定はプロダクトの一部として扱ってください:検証、デフォルト、変更履歴が必要です。
設定はコードから分離して保存し(理想的にはランタイムシークレットからも分離)、設定が無効な場合のセーフモードフォールバックをサポートします。/settings/tenants のような軽量な内部ページは、インシデント対応や段階的リリース時に何時間も節約します。
AI生成アーキテクチャが助けること(と限界)
テナントルーティングを設定
スタックを再構築せずにサブドメインやカスタムドメインでテナントルーティングをテスト。
AIはマルチテナントSaaSの初期アーキテクション検討を高速化できますが、エンジニアリング判断、テスト、セキュリティレビューの代替にはなりません。高品質なブレインストーミングパートナーとして扱い、出力はドラフトと見なしてすべての前提を検証してください。
AI生成アーキテクチャがすべきこと・すべきでないこと
AIは選択肢を生成し、典型的な失敗モード(どこでテナントコンテキストが失われるか、共有リソースがどこで驚きを生むか)を指摘するのに有用です。しかし、モデルの決定、コンプライアンスの保証、性能の検証はできません。実際のトラフィックやチームの強み、レガシー統合のエッジケースはAIには見えません。
重要な入力:要件、制約、リスク、成長見込み
出力の品質は入力に依存します。役立つ入力は:
- 現在と12–24ヶ月後のテナント数、テナントごとの予想データ量
- 分離要件(契約上、規制上、顧客期待)
- 予算と運用キャパシティ(オンコール成熟度、SREサポート、ツール)
- レイテンシ目標、ピーク使用パターン、テナントごとのバースト性
- リスク許容度:あるテナントが他に影響したら何が起きるか?
トレードオフを示すパターン提案にAIを使う
AIに2〜4案(例:データベースごと/スキーマごと/行レベル分離)を出させ、コスト、運用複雑さ、被害範囲、マイグレーション工数、スケーリング限界といったトレードオフを明確にまとめさせてください。AIはチームが設計上の質問に変えられる「落とし穴」を列挙するのが得意です。
ドラフトアーキテクチャから実働プロトタイプへ速く移したければ、Koder.ai のようなvibe-codingプラットフォームはチャットからReactフロントエンドとGo + PostgreSQLバックエンドのスケルトンを生成して、テナントコンテキスト伝播、レート制限、マイグレーションワークフローを早期検証するのに役立ちます。プランニングモードやスナップショット/ロールバック機能はマルチテナントデータモデルを反復する際に特に有効です。
AIで脅威モデルやチェックリストを生成する
AIは脅威モデル(エントリポイント、信頼境界、テナントコンテキスト伝播、よくあるミス)やPR用のレビューチェックリスト、ランブックをドラフトするのに有用です。必ず実際のセキュリティ専門家と自チームのインシデント履歴で検証してください。
チーム向け実践チェックリスト
マルチテナントのアプローチ選択は「ベストプラクティス」ではなくフィット感です:データの感度、成長速度、運用複雑さをどれだけ負担できるか。
30分ワークショップで使えるステップバイステップチェックリスト
-
データ: テナント間で共有されるデータは何か?絶対に同居してはいけないデータは?
-
アイデンティティ: テナントIDはどこにあるか(招待リンク、ドメイン、SSOクレーム)?各リクエストでテナントコンテキストはどう確立するか?
-
分離: デフォルトの分離レベル(行/スキーマ/DB)を決め、例外(例:エンタープライズ顧客)を特定する。
-
スケーリング: 最初に予想されるスケーリング圧力は何か(ストレージ、読み取りトラフィック、バックグラウンドジョブ、分析)?それを解決する最も単純なパターンは何か?
エンジニアとセキュリティレビュワーに確認すべき質問
- 開発者がフィルタを忘れた場合、交差テナントアクセスをどう防ぐか?
- テナントごとの監査(誰がいつ何をしたか)のストーリーは?
- テナントごとのデータ削除と保持はどう扱うか?
- 悪いマイグレーションや暴走クエリの被害範囲は?
- テナントごとにスロットル、レート制限、リソース予算は設定できるか?
深い設計が必要なレッドフラッグ
- 「テナントチェックは後で追加する」は危険なサイン
- すべてを見られる共有管理ツール(厳格な制御がない)
- テナント別バックアップ/復元やインシデント対応の計画がない
- テナントごとの公平性がない単一キュー/ワーカープール
推奨される次のアクションのサンプル要約
推奨: 行レベル分離 + 厳格なテナントコンテキスト強制を最初のデフォルトにし、テナントごとのスロットルを追加、ハイリスクテナントのためにスキーマ/DB分離へのアップグレード経路を定義する。
次のアクション(2週間): テナント境界の脅威モデリング、1つのエンドポイントでの強制プロトタイプ作成、ステージングコピーでのマイグレーションリハーサルを行う。展開ガイダンスは /blog/tenant-release-strategies を参照。