2025年9月21日·2 分
アプリでインスタントなサーバーサイド検索を実現する Meilisearch
Meilisearch をバックエンドに追加して、高速で誤字許容つきの検索を実現する方法:セットアップ、インデックス化、ランキング、フィルタ、セキュリティ、スケーリングの基本を解説。
Meilisearch をバックエンドに追加して、高速で誤字許容つきの検索を実現する方法:セットアップ、インデックス化、ランキング、フィルタ、セキュリティ、スケーリングの基本を解説。
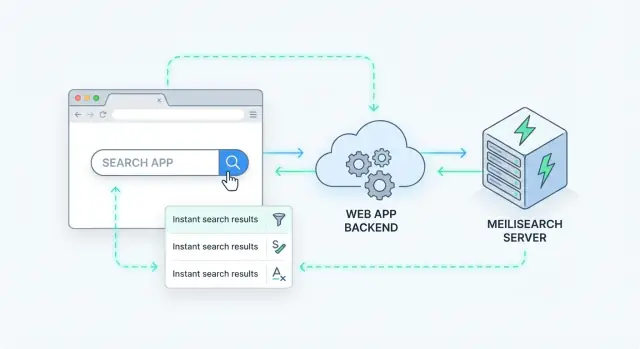
サーバーサイド検索とは、クエリがブラウザ内ではなくサーバー(または専用の検索サービス)で処理されることを指します。アプリは検索リクエストを送り、サーバーがインデックス上で実行してランク付けされた結果を返します。
データセットがクライアントに送れないほど大きい場合、プラットフォーム間で一貫した関連性が必要な場合、あるいはアクセス制御が必須な(例えば内部ツールでユーザーごとに見えるものを制限したい)場合に重要です。分析、ログ、予測可能なパフォーマンスが必要なときも、サーバーサイド検索がデフォルトの選択になります。
人々は検索エンジン自体を意識しません—体験で評価します。良い「インスタント」検索体験は通常、次を意味します:
これらのどれかが欠けると、ユーザーは別のクエリを試したり、過度にスクロールしたり、検索を放棄したりします。
この記事は Meilisearch を使ってその体験を作るための実践的なウォークスルーです。安全なセットアップ、インデックス化と同期方法、関連性とランキングルールのチューニング、フィルタ/ソート/ファセットの追加、そして検索がアプリの成長に伴って高速であり続けるためのセキュリティとスケーリングについて扱います。
Meilisearch は次の用途に適しています:
目標は一貫して:即時性があり、正確で信頼できる結果を提供すること—検索を大規模なエンジニアリング課題にしないこと。
Meilisearch はアプリの横で動かす検索エンジンです。ドキュメント(製品、記事、ユーザー、サポートチケットなど)を渡すと、検索が速くなるように最適化されたインデックスを構築します。バックエンド(またはフロントエンド)はシンプルな HTTP API を通じて Meilisearch にクエリを送り、ミリ秒単位でランク付けされた結果を受け取ります。
Meilisearch は現代の検索に期待される機能にフォーカスしています:
短いクエリや曖昧な入力でも、レスポンシブで寛容に感じられるように設計されています。
Meilisearch はプライマリデータベースの代替ではありません。書き込み、トランザクション、制約はデータベースが担当します。Meilisearch は、検索・フィルタ・表示に必要なフィールドのコピーを保持します。
良い心構えは:データベースは格納と更新、Meilisearch は素早く見つける、です。
Meilisearch は非常に高速になり得ますが、実際の速度は次の実務的要因に依存します:
小〜中規模のデータセットなら単一マシンで十分なことが多いです。インデックスが大きくなったら、何をインデックス化するかや更新方法を慎重に設計する必要があります—後半で触れます。
何もインストールする前に、実際に何を検索するのかを決めてください。インデックスとドキュメントがユーザーのブラウズの仕方に合って初めて Meilisearch は「インスタント」に感じられます。
検索対象となるエンティティ(通常は products, articles, users, help docs, locations など)を列挙しましょう。多くのアプリでは エンティティタイプごとに1インデックス(例:products、articles)が最も整然とします。これによりランキングルールとフィルタが予測可能になります。
UX が単一のボックスで複数タイプを横断検索する場合は、別々のインデックスを保持してバックエンドで結果をマージするか、後で専用の「global」インデックスを作成する方が良いでしょう。フィールドやフィルタが本当に揃っていない限り、すべてを一つのインデックスに押し込むべきではありません。
各ドキュメントには安定した識別子(プライマリキー)が必要です。次の条件を満たすものを選んでください:
id, sku, slug)ドキュメント形状は可能なら フラットなフィールド を優先してください。フラットな構造はフィルタやソートが容易です。ネストは著者オブジェクトのように緊密で不変のバンドルを表す場合に許容されますが、リレーショナルスキーマをそのまま深くネストするのは避けてください—検索ドキュメントは 読み取り最適化 されるべきで、データベース形状である必要はありません。
実務的には各フィールドに役割を付けましょう:
「念のため」フィールドをインデックスして後で結果がノイズだらけになったり、フィルタが遅くなる典型的なミスを避けられます。
「言語」はデータの中で複数の意味を持ちます:
lang: "en" がある)早期に、言語ごとに別インデックスにするか(単純で予測可能)、単一インデックスに言語フィールドを持たせるか(インデックス数は少ないがロジックが増える)を決めてください。ユーザーが一度に一言語で検索するか、翻訳の保存方法によって最適解は変わります。
Meilisearch の実行自体は簡単ですが、「デフォルトで安全」にするには、どこにデプロイするか、データをどう永続化するか、マスターキーをどう扱うかを意図的に決める必要があります。
ストレージ: Meilisearch はインデックスをディスクに書きます。データディレクトリは永続的で信頼できるストレージに置き、エフェメラルなコンテナストレージは避けてください。大きなテキストフィールドや多数の属性でインデックスは急速に増えますので容量計画をしてください。
メモリ: 検索応答を保つために十分な RAM を割り当ててください。スワップが発生するとパフォーマンスが悪化します。
バックアップ: Meilisearch のデータディレクトリをバックアップするか、ストレージレイヤのスナップショットを利用してください。復元テストを少なくとも一度は行ってください。復元できないバックアップはただのファイルです。
監視: CPU、RAM、ディスク使用率、ディスク I/O を監視してください。プロセスのヘルスやログエラーも監視し、サービス停止やディスク残量不足などは最低限アラートするようにします。
ローカル開発以外では必ず マスターキー を設定して実行してください。キーハンドリングはシークレットマネージャや暗号化された環境変数ストアに保管し、Git に入れたり平文の .env をコミットしたりしないでください。
例(Docker):
docker run -d --name meilisearch \
-p 7700:7700 \
-v meili_data:/meili_data \
-e MEILI_MASTER_KEY="$(openssl rand -hex 32)" \
getmeili/meilisearch:latest
またネットワークルールも検討してください:プライベートインターフェースにバインドする、あるいは受信を制限してバックエンドだけが Meilisearch に到達できるようにします。
curl -s http://localhost:7700/version
Meilisearch のインデックス登録は非同期です:ドキュメントを送ると Meilisearch はタスクをキューに入れ、そのタスクが成功した後に初めてドキュメントが検索可能になります。インデックス処理はジョブシステムとして扱い、単一リクエストで完了すると考えないでください。
id)curl -X POST 'http://localhost:7700/indexes/products/documents?primaryKey=id' \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer YOUR_WRITE_KEY' \
--data-binary @products.json
taskUid が含まれます。succeeded(または failed)になるまでポーリングします。curl -X GET 'http://localhost:7700/tasks/123' \
-H 'Authorization: Bearer YOUR_WRITE_KEY'
curl -X GET 'http://localhost:7700/indexes/products/stats' \
-H 'Authorization: Bearer YOUR_WRITE_KEY'
件数が合わないときは推測せず、まずタスクのエラーディテールを確認してください。
バッチ処理はタスクを予測可能で再現可能に保つことが目的です。
addDocuments は upsert のように振る舞います:同じプライマリキーのドキュメントは更新され、無ければ挿入されます。通常の更新にはこれを使ってください。
次のような場合は フルリインデックス を検討します:
削除は明示的に deleteDocument(s) を呼び出してください。さもないと古いレコードが残ります。
インデックス処理は再試行可能にすべきです。鍵は 安定したドキュメント id です。
taskUid をバッチ/ジョブ id と一緒に保存し、タスク状態に基づいてリトライを行うと良いです。本番データの前に、実際のフィールドに合わせた小さなデータセット(200–500 件)をインデックスしてください。例:products セットに id, name, description, category, brand, price, inStock, createdAt を含めると、タスクフロー、件数、更新/削除動作を大きなインポートを待たずに検証できます。
検索の「関連性」とは単純に「何が先に出てくるか、そしてなぜか」です。Meilisearch は独自のスコアリングシステムを作らなくても調整可能にしてくれます。
Meilisearch の設定で重要なのは主に二つです:
searchableAttributes:ユーザーがクエリを入力したときに検索対象とするフィールド(例:title, summary, tags)。順序が重要で、前にあるフィールドほど重要と扱われます。displayedAttributes:レスポンスで返すフィールド。プライバシーやペイロードサイズに影響します—表示しないフィールドは返されません。実務的な初期設定は、信号の強い少数のフィールド(title、主要テキスト)を検索対象にし、表示フィールドは UI が必要とするものだけに絞ることです。
Meilisearch は ランキングルール(タイブレーカーのパイプライン)に従って一致ドキュメントをソートします。概念的には次の順で優先します:
内部を細かく覚える必要はなく、主に「どのフィールドを重視するか」と「いつカスタムソートを適用するか」を選べば十分です。
目標:タイトル一致を優先したい。 title を先頭に置きます:
{
"searchableAttributes": ["title", "subtitle", "description", "tags"]
}
目標:新しいコンテンツを先に表示したい。 ソートルールを追加し、クエリ時にソートを指定する(またはカスタムランキングを設定する):
{
"sortableAttributes": ["publishedAt"],
"rankingRules": ["sort", "typo", "words", "proximity", "attribute", "exactness"]
}
そしてリクエスト時に:
{ "q": "release notes", "sort": ["publishedAt:desc"] }
目標:人気アイテムを上げたい。 popularity を sortable にして、適宜それでソートします。
ユーザーが実際に入力する 5–10 のクエリを選び、変更 前 の上位結果を保存し、変更 後 と比較します。
例:
"apple" → Apple Watch band, Pineapple slicer, Apple iPhone case"apple" → Apple iPhone case, Apple Watch band, Pineapple slicer“変更後” の方がユーザー意図に合うならその設定を採用してください。副作用がある場合は一度に一つずつ(属性の順序→ソート設定)変えて原因を追いやすくしてください。
良い検索ボックスは単に「単語を入れて一致を得る」だけではありません。人は結果を絞りたがり(「在庫のある商品だけ」)、並べ替えたがります(「最も安い順」)。Meilisearch ではこれを filters、sorting、facets で実現できます。
フィルタ は結果セットに適用するルールです。ファセット はユーザーがそのルールを作るのを助ける UI(チェックボックスや件数表示)です。
非技術的例:
ユーザーは「running」と検索してから category = Shoes と status = in_stock で絞り込むかもしれません。ファセットは “Shoes (128)”, “Jackets (42)” のような件数を見せて、何があるか理解させます。
Meilisearch ではフィルタやソートで使うフィールドを明示的に許可する必要があります。
category, status, brand, price, created_at, tenant_id など。price, rating, created_at, popularity など。このリストは狭く保ってください。すべてを filterable/sortable にするとインデックスサイズが増え、更新が遅くなることがあります。
たとえ 50,000 件のマッチがあっても、ユーザーが見るのは最初のページだけです。小さいページサイズ(通常 20–50 件)を使い、limit を適切に設定して、offset(または新しいページング機能)でページングしてください。ページ深度の最大値をアプリで制限して、重い「ページ400」リクエストを防ぎましょう。
サーバーサイド検索を追加するクリーンな方法は、Meilisearch をあなたの API の背後にある専用データサービスとして扱うことです。アプリは検索リクエストを受け、Meilisearch にクエリして結果を整形して返します。
多くのチームが次のようなフローを採用します:
GET /api/search?q=wireless+headphones&limit=20)。このパターンにより Meilisearch を置き換えやすくし、フロントエンドがインデックス内部に依存するのを防げます。
もし新規アプリを構築中でこのパターンを素早く実装したいなら、React UI、Go バックエンド、PostgreSQL を足がかりに Meilisearch を /api/search の背後に置くようなスキャフォールドを提供するプラットフォーム(例:Koder.ai)の活用を検討してもよいでしょう。
Meilisearch はクライアントサイドクエリもサポートしますが、バックエンド経由の方が通常は安全です:
公開データで制限付きキーを使う場合はクライアントクエリでも動きますが、ユーザー固有の可視性ルールがある場合は検索をサーバー経由にしてください。
検索トラフィックには繰り返しが多い(例:"iphone case", "return policy")。API 層でキャッシュを入れると効果的です:
検索を公開エンドポイントとして扱ってください:
limit の最大値やクエリ長の上限を設ける。Meilisearch はビジネス上の機密データを高速に返せるため、データベース同様にロックダウンし、呼び出し元ごとに見せて良いものだけを返すように扱ってください。
Meilisearch にはすべてを行える master key があり、インデックスの作成/削除や設定更新、読み書きが可能です。これはサーバー側にのみ保管してください。
アプリ向けには 限られたアクションとインデックスだけ許可する API キー を発行します。一般的なパターン:
最小権限により、キーが漏れてもデータ削除や他インデックスの読み取りができないようにします。
複数の顧客(テナント)を扱う場合、主に二つの選択肢があります:
1) テナントごとに1インデックス。
単純で考えやすく、クロステナントアクセスのリスクが低い反面、インデックス管理が増えます。設定変更は一貫して適用する必要があります。
2) 共有インデックス + tenantId フィルタ。
各ドキュメントに tenantId を持たせ、すべての検索に tenantId = "t_123" のようなフィルタを必須にします。スコープ付きキーを使えばフィルタを取り除けなくするなどの工夫が可能です。この方法は適切に実装するとスケールしやすいですが、各リクエストで必ずフィルタが適用されることを保証する必要があります。
検索自体が正しくても、返してはいけないフィールド(メール、内部メモ、原価など)が漏れる可能性があります。返却可能な属性を制御してください:
「最悪のケース」テストを一度やってください:一般的な語で検索して、プライベートなフィールドが表示されないことを確認します。
クライアント側にキーを置くべきか迷う場合は「置かない」をデフォルトにし、検索はサーバー経由にしてください。
Meilisearch は次の二つのワークロードを意識すれば速さを保てます:インデックス(書き込み)と検索クエリ(読み取り)。多くの「なぜ遅いのかわからない」事象はこれらが CPU、RAM、ディスクを奪い合っているだけです。
インデックス負荷:大きなバッチをインポートする、頻繁な更新がある、多数の searchable フィールドを追加する、などでスパイクが発生します。インデックスはバックグラウンドタスクですが CPU とディスク帯域を消費します。タスクキューが伸びると検索が遅く感じられることがあります。
クエリ負荷:トラフィックの増加だけでなく、機能(多くのフィルタ、ファセット、広い結果セット、誤字許容の度合い)でも増えます。
ディスク I/O:地味な原因ですが重要です。遅いディスクや共有ボリュームのノイジーネイバーは「インスタント」を「いつかそのうち」に変えます。NVMe/SSD が本番環境の基準です。
まずはシンプルなサイズ見積もりから:インデックスをホットに保つのに十分な RAM とピーク QPS を処理できる CPU を割り当てます。次に責務を分けていきます:
少数の信号を追ってください:
バックアップは日常的に行うものです。Meilisearch の snapshot 機能をスケジュールで使い、スナップショットをオフボックスに保存し、定期的に復元テストを行ってください。アップグレード時はリリースノートを読み、ステージング環境で検証し、バージョン変更がインデックス動作に影響するなら再インデックスに要する時間を見積もって計画してください。
もし既に環境のスナップショットとロールバックをアプリプラットフォームで使っているなら(例:Koder.ai の snapshots/rollback ワークフロー)、検索のローアウトも同じ規律に合わせてください:変更前にスナップショット、ヘルスチェックの検証、既知の良い状態への迅速な復帰経路を確保する。
クリーンな統合ができていても、検索の問題はよくあるパターンに落ち着きます。良い点は:Meilisearch はタスク、ログ、決定的な設定を通じて十分な可視性を提供しており、体系的にデバッグすれば素早く直せることです。
filterableAttributes に追加されていない、あるいはドキュメント側の形状が予期と違う(文字列 vs 配列 vs ネスト)場合。sortableAttributes/rankingRules の不足した調整が原因のことが多い。まず最後の変更が Meilisearch に正常に適用されたかを確認します。
filter、次に sort、次に facets。説明できない結果がある場合は、一時的に設定を削ぎ落としてください:同義語を外す、ランキングルールの変更を減らす、小さなデータセット(50 件程度)で再現すると複雑な関連性問題はずっと発見しやすくなります。
your_index_v2 を並行して構築し、設定を適用し、プロダクションクエリのサンプルを流して検証する。filterableAttributes と sortableAttributes が UI 要件と一致していることを確認する。関連ガイド: /blog(検索の信頼性、インデックス化パターン、プロダクションローアウトのヒント)
サーバー側で検索クエリを実行し、ブラウザではなくバックエンド(または専用の検索サービス)で処理することを指します。以下の場合に適しています:
ユーザーが即座に気づくのは主に次の4点です:
これらのどれかが欠けると、ユーザーは別のクエリを試したり、スクロールを増やしたり、検索を諦めます。
Meilisearch は 検索用のインデックス として扱い、ソースオブトゥルースは引き続きデータベースです。書き込み、トランザクション、制約はデータベースで管理し、Meilisearch には検索や表出に必要なフィールドのコピーを置きます。
便利な精神モデル:
一般的には エンティティごとに1つのインデックス(例:products、articles)が推奨です。これにより:
“すべてを検索する” UX が必要なら、複数のインデックスをクエリしてバックエンドで結果をマージするか、後で専用のグローバルインデックスを作るとよいでしょう。
次の条件を満たすプライマリキーを選んでください:
id、sku、slug)安定した ID を使うと再試行が安全になります(アップサートとして扱われ、重複が起きない)。
各フィールドの役割を明確に分類してください:
これにより過剰なインデックス化を避け、ノイズの多い結果や重いインデックスを防げます。
インデックス登録は非同期です。ドキュメントをアップロードするとタスクが作成され、そのタスクが成功するまで検索に現れません。
信頼できるフロー:
taskUid をポーリングして succeeded か failed を待つ結果が古いように見えたら、まずタスクの状態を確認してください。
大きな単一アップロードよりも多くの小さめのバッチが扱いやすいです。実務上の目安:
小さなバッチはリトライやデバッグが容易で、タイムアウトのリスクも下がります。
即効性の高い2つのレバーは:
publishedAt、price、popularity などで並び替えるかどうか実践的には、5〜10 の実ユーザーのクエリで「変更前の上位結果」を保存し、設定を1つ変えて「変更後」と比較します。
フィルタ/ソートが機能しない主な原因は設定漏れです:
filterableAttributes に登録する必要がありますsortableAttributes に登録する必要がありますまたドキュメントのフィールド形状(string/array/nested object)が期待と違うと失敗します。設定やタスク状態、インデックス内の実際のフィールド値を確認してください。