2025年7月10日·1 分
メールとWebhookのためのシンプルなバックグラウンドジョブキューのパターン
重いツールを使わずに、再試行、バックオフ、デッドレター処理を備えたメール送信、レポート実行、Webhook配信のためのシンプルなバックグラウンドジョブキューパターンを学ぶ。
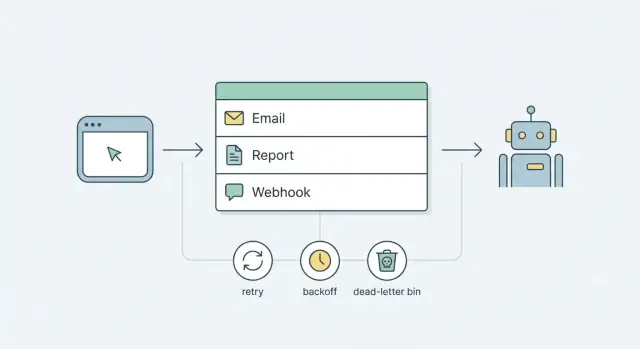
なぜバックグラウンドジョブが必要か(そして問題が急速に複雑になる理由)
1〜2秒以上かかる処理はユーザーリクエスト内で走らせるべきではありません。メール送信、レポート生成、Webhook配信はネットワークやサードパーティサービス、遅いクエリに依存しており、時々止まったり失敗したり予想以上に時間がかかったりします。
その処理をユーザーが待っている間に行うと、すぐに目に見えて問題になります。ページが固まり、"保存"ボタンのインジケーターが回り、リクエストがタイムアウトします。リトライが誤った場所で起きることもあります。ユーザーがリロードしたり、ロードバランサが再試行したり、フロントエンドが再送したりして、重複したメールやWebhook、競合するレポート実行が発生します。
バックグラウンドジョブはこれを解決します:リクエストを小さく予測可能に保ち、アクションを受け付けて後でやる仕事を記録し、すぐに応答します。ジョブはリクエスト外で、あなたが管理するルールに従って実行されます。
難しいのは信頼性です。仕事をリクエストパスの外に出しても、次のような問いに答えなければなりません:
- メールプロバイダが3分間落ちたら?
- Webhook先が500を返すかタイムアウトしたら?
- ジョブが二回実行されたら?
- ユーザーが文句を言う前に詰まったジョブをどう検知する?
多くのチームは"重いインフラ"を導入して対応します:メッセージブローカー、別のワーカーフリート、ダッシュボード、アラート、プレイブック。必要なときには便利ですが、新しい構成要素と新たな障害モードを増やします。
より良い出発点はもっとシンプルです:既にある部品で信頼できるジョブを作ること。多くのプロダクトでは、データベースベースのキューと小さなワーカープロセスで十分です。明確なリトライとバックオフ戦略、繰り返し失敗するジョブ向けのデッドレターパターンを追加すれば、複雑なプラットフォームに最初からコミットすることなく予測可能な振る舞いが得られます。
たとえKoder.aiのようなチャット駆動ツールで素早く作っている場合でも、この分離は重要です。ユーザーには素早い応答を返し、遅く失敗しやすい作業は安全にバックグラウンドで終わらせるべきです。
キューとは簡単に言うと何か
キューは作業の待ち行列です。ユーザーリクエスト中に遅い・信頼できない作業(メール送信、レポート作成、Webhook呼び出し)を行う代わりに、小さなレコードをキューに入れて素早く返します。後で別のプロセスがそのレコードを取り出して仕事をします。
よく出てくる用語:
- ジョブ:"ユーザー123にウェルカムメールを送る"のような1単位の仕事。
- ワーカー:ジョブを引き出して実行するコード。
- 試行(attempt):ジョブを1回実行すること。
- スケジュール:ジョブをいつ実行するか(今か後か)。
- キュー:ワーカーに取られるまでジョブが待つ場所。
最も単純なフローは次の通りです:
-
エンキュー:アプリがジョブレコード(タイプ、ペイロード、実行時間)を保存する。
-
クレーム:ワーカーが次の利用可能なジョブを見つけて一意に"ロック"する。
-
実行:ワーカーがタスクを実行する(送信、生成、配信)。
-
終了:完了としてマークするか、失敗を記録して次回実行時刻を設定する。
ジョブ量が控えめでデータベースが既にあるなら、データベースベースのキューで十分なことが多いです。理解しやすくデバッグもしやすく、メールジョブ処理やWebhook配信の信頼性など一般的なニーズに合います。
ストリーミングプラットフォームは非常に高いスループットや多数の独立消費者、多くのシステムにまたがる巨大なイベント履歴のリプレイが必要なときに意味を持ちます。何十ものサービスで毎時何百万イベントを扱うようになればKafkaのようなツールが助けになります。それまでは、データベーステーブル+ワーカーループで多くの現実世界のキューはカバーできます。
各ジョブで最低限追跡すべきデータ
データベースキューは、各ジョブレコードが「何をするか」「次にいつ試すか」「前回何が起きたか」に素早く答えられると秩序が保たれます。これを正しくすると運用は退屈になります(それが目標です)。
ペイロードに保存すべきもの(保存すべきでないもの)
仕事に必要な最小の入力を保存し、レンダリング済みの出力全体は保存しないでください。良いペイロードはIDといくつかのパラメータです。例:{ "user_id": 42, "template": "welcome" }。
大きなBlob(フルHTMLメール、大きなレポートデータ、巨大なWebhookボディ)は避けてください。データベースが急速に肥大化し、デバッグが難しくなります。ジョブが大きなドキュメントを必要とするなら、代わりに参照を保存してください:report_id、export_id、またはファイルキー。ワーカーが実行時にフルデータを取得します。
投資に見合うフィールド
最低限、次を用意してください:
- job_type + payload:
job_typeでハンドラを選び(send_email, generate_report, deliver_webhook など)、payloadはIDやオプション等の小さな入力を持ちます。 - status:明示的に(例:
queued,running,succeeded,failed,dead)。 - 試行追跡:
attempt_countとmax_attempts(明らかに動かないならリトライを止めるため)。 - 時間フィールド:
created_atとnext_run_at(実行可能になる時間)。started_atとfinished_atを追加すると遅いジョブの可視性が上がります。 - 冪等性 + 最終エラー:
idempotency_keyで二重効果を防ぎ、last_errorで失敗理由をログ以外で確認できます。
冪等性は難しそうに聞こえますが、考え方は単純です:同じジョブが二回走っても、2回目は危険なことをしないようにすること。例えばWebhook配信ジョブは webhook:order:123:event:paid のような冪等キーを使えば、リトライがタイムアウトと重なって同じイベントを二度配信することを防げます。
また初期段階でいくつかの基本的な数値も取得しておくと便利です。大きなダッシュボードは不要で、列挙クエリで「キューにあるジョブ数」「失敗しているジョブ数」「最古のキューの年齢」くらいが分かれば十分です。
ステップバイステップ:今日作れるシンプルなデータベースキュー
既にデータベースがあるなら、新しいインフラを追加せずにバックグラウンドキューを始められます。ジョブは行(rows)で、ワーカーは期限の来た行を取り続けて仕事をするプロセスです。
1) jobsテーブルを作る
テーブルは小さくシンプルに保ちましょう。後で実行・リトライ・デバッグできるだけのフィールドを入れます。
CREATE TABLE jobs (
id bigserial PRIMARY KEY,
job_type text NOT NULL,
payload jsonb NOT NULL,
status text NOT NULL DEFAULT 'queued', -- queued, running, done, failed
attempts int NOT NULL DEFAULT 0,
next_run_at timestamptz NOT NULL DEFAULT now(),
locked_at timestamptz,
locked_by text,
last_error text,
created_at timestamptz NOT NULL DEFAULT now(),
updated_at timestamptz NOT NULL DEFAULT now()
);
CREATE INDEX jobs_due_idx ON jobs (status, next_run_at);
Postgresを使っているなら、jsonbは { "user_id":123,"template":"welcome" } のようなジョブデータ保存に実用的です(Goバックエンドで一般的)。
2) 安全にエンキューする(特にユーザーアクションの場合)
ユーザーアクションがジョブをトリガーするなら、可能なら主要な変更と同じデータベーストランザクションでジョブ行を書き込んでください。そうすれば主要な書き込み直後にクラッシュしても「ユーザーは作られたのにジョブがない」状態を防げます。
例:ユーザー登録時にユーザーロウと send_welcome_email ジョブを1つのトランザクションで挿入する。
3) スケールできるワーカーループを走らせる
ワーカーは次のサイクルを繰り返します:期限の来たジョブを1つ見つけてクレームし、処理し、完了にするかリトライをスケジュールします。
具体的には:
status='queued'かつnext_run_at <= now()のジョブを1つ選ぶ- 原子的にクレームする(Postgresでは
SELECT ... FOR UPDATE SKIP LOCKEDが一般的) status='running',locked_at=now(),locked_by='worker-1'をセットする- ジョブを処理する
- 完了としてマークする(例:
done/succeeded)、あるいはlast_errorを記録して次の試行をスケジュールする
複数のワーカーが同時に動けます。クレームステップが二重取得を防ぎます。
4) シャットダウン時の破壊を避ける
シャットダウン時は新しいジョブを取るのを止め、現在の処理を終えてから終了してください。プロセスが途中で死んだ場合は、一定時間 running のままのジョブを定期的な「リーパー」が再キューできるルールを設けます。
Koder.aiで構築する場合でも、このデータベースキューパターンはメール、レポート、Webhookのデフォルトとして堅実です。
混乱を招かないリトライとバックオフ
キューとワーカーをデプロイする
アプリとワーカーを一緒にデプロイし、負荷の増加に合わせて安全に反復します。
リトライは現実世界の乱雑さの中でキューを落ち着かせます。明確なルールがないと、リトライは騒がしいループになり、ユーザーをスパムし、APIを叩き過ぎ、本当のバグを隠してしまいます。
まず何をリトライし、何を速やかに失敗扱いにするか決めてください。
一時的な問題はリトライ:ネットワークタイムアウト、502/503、レート制限、短時間のDB接続障害など。
ジョブが成功しない明らかな原因がある場合は速やかに失敗させる:メールアドレスがない、Webhookに無効なペイロードを送っている(400)、削除されたアカウントに対するレポート要求など。
バックオフは試行間の待ち時間です。線形バックオフ(5秒、10秒、15秒)は単純ですが、依然としてトラフィックの波を作る可能性があります。指数バックオフ(5s、10s、20s、40s)は負荷を拡散しやすく、Webhookやサードパーティに対して通常安全です。ジッター(少しのランダム遅延)を入れて、障害後に千のジョブが同じ秒に再試行しないようにします。
実運用でうまく振る舞うルール:
- 一時的なエラー(タイムアウト、429、5xx)のみリトライする
- ジッター付きの指数バックオフを使う
- 試行回数に上限を設けて、それ以上は失敗としてマークする
- 試行ごとにタイムアウトを設定してワーカーがハングするのを防ぐ
- 全てのジョブを冪等にする(リトライで重複が起きないように)
最大試行回数はダメージを制限するためのものです。多くのチームでは5〜8回が十分です。それ以上はリトライを止めてジョブをレビュー用(デッドレター)に移します。
タイムアウトは"ゾンビ"ジョブを防ぎます。メールは1試行あたり10〜20秒、Webhookは受け手が落ちている可能性があるため5〜10秒程度の短めの制限が一般的です。レポート生成は数分を許容することがありますが、それでもハードカットオフを設けるべきです。
Koder.aiでこれを組むなら、should_retry、next_run_at、冪等キーを主要フィールドとして扱ってください。こうした小さな詳細が問題発生時にシステムを静かに保ちます。
デッドレター処理とシンプルな運用
デッドレター状態は、リトライを続けるのが安全でも有用でもないときにジョブを移す場所です。これにより失敗が可視化され、検索や対応が可能になります。
デッドレタージョブに保存すべきこと
何が起きたか理解して再実行できる情報を保存します。ただしシークレットには注意してください。
保存例:
- ジョブ入力(ペイロード)は元のまま、ジョブタイプとバージョンも
- 最後のエラーメッセージと短いスタックトレース(スタックがなければエラーコード)
- 試行回数、最初の実行時間、最後の実行時間、次回実行予定(スケジュールがあれば)
- ワーカー識別(サービス名、ホスト)とログ用の相関ID
- デッドレター理由(タイムアウト、バリデーションエラー、ベンダーからの4xxなど)
ペイロードにトークンや個人データが含まれる場合は、保存前にマスクまたは暗号化してください。
シンプルなトリアージワークフロー
ジョブがデッドレターになると、素早く判断します:再試行するか、修正するか、無視するか。
- 再試行:外部障害やタイムアウト向け
- 修正:欠損データ(メールがない、間違ったWebhook URL)やコードのバグ向け
- 無視:稀ですがジョブがもはや関連性を失っている場合(例:顧客がアカウントを削除した)
無視する場合は理由を記録して、ジョブが消えたように見えないようにします。
手動で再キューする場合は、古いジョブを不変のままにして新しいジョブを作るのが安全です。デッドレタージョブに誰がいつ何のために再キューしたかを記録し、新しいIDで新しいコピーをエンキューしてください。
アラートとしては、デッドレター数の急増、同じエラーが多くのジョブで繰り返される、長く放置されたキューがクレームされていない、などのシグナルを監視してください。
Koder.aiを使っている場合は、スナップショットとロールバックが役に立ちます。悪いリリースで失敗が急増したら素早く元に戻して調査できます。
最後に、ベンダー障害用の安全弁を設けてください。プロバイダごとの送信レートを制限し、サーキットブレーカーを使って、Webhookエンドポイントがひどく失敗しているときは短時間新しい試行を止め、相手(と自分)を叩きすぎないようにします。
メール、レポート、Webhook向けのパターン
リトライを正しく動作させる
指数バックオフ、ジッター、最大試行回数を手作業でゼロから作らずに実装します。
各ジョブタイプに「何が成功か」「何をリトライするか」「二度起きてはいけないことは何か」を明確に定義するとキューはうまく機能します。
メール
ほとんどのメール失敗は一時的です:プロバイダのタイムアウト、レート制限、短い障害など。これらはバックオフ付きでリトライします。重複送信が最大のリスクなのでメールジョブは冪等にしてください。user_id + template + event_id のような安定した重複除去キーを保存し、そのキーが既に送信済みなら送らないようにします。
テンプレート名とバージョン(またはレンダリング済み件名/本文のハッシュ)を保存しておくと、ジョブを再実行する際に「同じ内容を再送するか最新テンプレートで再生成するか」を選べます。プロバイダがメッセージIDを返したら保存しておくとサポート時に追跡できます。
レポート レポートは別の失敗パターンを持ちます。数分かかることがあり、ページネーションで止まったり、すべてを一度に処理してメモリ不足に陥ったりします。作業を小さく分割してください。一般的なパターンは、1つの"report request"ジョブが多くの"page"(または"chunk")ジョブを作り、それぞれがデータのスライスを処理する方法です。
結果はユーザーに待たせず後でダウンロードできる形で保存してください。データベースのテーブルに report_run_id でキーを付けるか、ファイル参照+メタデータ(status、row count、created_at)にしておきます。進捗フィールドを追加するとUIが"処理中"と"準備完了"を正しく表示できます。
Webhook Webhookは配信の信頼性が最重要で、速度ではありません。各リクエストに署名(例えば共有シークレットでHMAC)し、タイムスタンプを含めてリプレイ防止を行ってください。受け手が将来成功する可能性がある場合のみリトライします。
簡単なルール:
- タイムアウトと5xxに対してバックオフ+最大試行回数でリトライする
- ほとんどの4xxは恒久的な失敗と見なしてリトライを止める
- 最後のステータスコードと短いレスポンスボディをデバッグ用に記録する
- 冪等キーを使って受け手が重複を安全に無視できるようにする
- ペイロードサイズに上限を設け、実際に送ったものをログに残す
順序と優先度
ほとんどのジョブは厳密な順序を必要としません。順序が必要な場合は通常キーごと(ユーザー、請求書、Webhookエンドポイント)です。group_key を追加して、キーごとに同時実行を1つに制限してください。
優先度については、緊急の仕事と遅い仕事を分けてください。大きなレポートのバックログがパスワードリセットメールを遅らせないようにします。
例:購入後には (1) 注文確認メール、(2) パートナーへのWebhook、(3) レポート更新ジョブ をエンキューします。メールは速いリトライ、Webhookは長めのバックオフ、レポートは低優先度で後に実行する、といった具合です。
現実的な例:サインアップフロー+Webhook+夜間レポート
ユーザーがサインアップすると3つのことが起きるべきですが、どれもサインアップページを遅くしてはいけません:ウェルカムメール送信、CRMへの通知Webhook、夜間のアクティビティレポートへの追加。
サインアップ時にキューに入るもの
ユーザーレコード作成直後に3つのジョブ行をDBキューに書きます。各行はタイプ、ペイロード(例:user_id)、ステータス、試行回数、next_run_atを持ちます。
典型的なライフサイクル:
queued: 作成されワーカーを待っているrunning: ワーカーがクレームしたsucceeded: 完了、追加作業なしfailed: 失敗し後で再試行予定または上限に達したdead: 失敗が多すぎて人手の確認が必要
ウェルカムメールジョブには welcome_email:user:123 のような冪等キーを含めます。送信前に完了済みの冪等キーのテーブルをチェックするか一意制約を使ってください。クラッシュでジョブが二度実行されても、2回目はキーを見て送信をスキップします。二重ウェルカムメールは発生しません。
失敗とその回復
CRMのWebhookエンドポイントがダウンすると、そのWebhookジョブはタイムアウトで失敗します。ワーカーはバックオフ(例えば1分、5分、30分、2時間)+小さなジッターで次回実行をスケジュールします。
最大試行回数に達するとジョブは dead になります。ユーザーはサインアップされ、ウェルカムメールも受け取り、夜間レポートジョブも通常通り実行されます。詰まるのはCRM通知だけで、それが可視化されます。
翌朝、サポートやオンコールは長時間ログを漁らなくても対処できます:
- タイプ(例:
webhook.crm)でデッドジョブをフィルタ - 最後のエラーメッセージを読み、ペイロードが正しいか確認
- CRMが復旧していることを確認
- ジョブを再キューする(
dead→queued、試行回数をリセット)か、一時的にその送信先を無効化する
Koder.aiのようなプラットフォームでアプリを作る場合でも同じパターンが当てはまります:ユーザーフローを速く保ち、副作用はジョブに押し込み、失敗を簡単に点検・再実行できるようにしてください。
キューを不安定にするよくある間違い
サイドエフェクトをジョブに変える
Planning Modeを使って、メール・Webhook・レポートを信頼できるバックグラウンドジョブにマッピングします。
キューを壊す最速の方法は、それを"オプション"として扱うことです。チームは最初に「今回はリクエスト内でメールを送れば簡単だ」と始めがちです。それが広がりパスワードリセット、レシート、Webhook、レポートエクスポートなどに及びます。アプリが遅くなり、タイムアウトが増え、サードパーティの小さな障害がそのままあなたの障害になります。
別の罠は冪等性をスキップすることです。ジョブが二度実行され得るなら、二回実行しても二重の結果を生まないようにしなければなりません。冪等性を無視するとリトライが重複メールや重複イベントを生みます。
三つ目は可視性の欠如です。失敗をサポートチケットでしか知り得ないなら、キューは既にユーザーに害を及ぼしています。ステータス別のジョブ数や検索可能な last_error を出せるだけで大幅に助かります。
注意すべき信頼性キラー
簡単なキューでも早期に出る問題:
- 失敗時にすぐに再試行する(プロバイダが落ちているときに自分たちでトラフィックスパイクを作る)
- 遅いジョブと緊急ジョブを混ぜる(10分かかるレポートが確認メールをブロックする)
- エラーを永遠に一時的扱いにする(決して成功しないジョブがループし続ける)
- ペイロードバージョンの管理をしない(ジョブ形状が変わると古いジョブが失敗し始める)
- レート制限を無視する(キューがプロバイダをフラッドしてしまう)
バックオフは自己作成した障害を防ぎます。1分、5分、30分、2時間の基本スケジュールでも失敗を安全にできます。最大試行回数を設定して、壊れたジョブが止まり可視化されるようにしてください。
Koder.aiのようなプラットフォームで構築するなら、これらの基本を機能と一緒に最初から出荷する方が、後で掃除するより楽です。
迅速なチェックリストと次のステップ
追加ツールを入れる前に基礎が固まっているか確認してください。データベースベースのキューは、各ジョブが取りやすく、リトライしやすく、検査しやすければ十分に機能します。
簡単な信頼性チェックリスト:
- すべてのジョブに:id, type, payload, status, attempts, max_attempts, run_at/next_run_at, last_error
- ワーカーはジョブを安全にクレームし(1ワーカーが1ジョブ)、クラッシュ後に回復できる(ロックタイムアウト+リーパー)
- 各ジョブに明確なタイムアウトを設け、詰まった作業が無限に続かないようにする
- リトライは上限があり、遅延は増加(バックオフ)してサンダーストームを避ける
- デッドレター状態(またはテーブル)と、ジョブを再実行/破棄する明確な方法を用意する
次に、最初の3つのジョブタイプを選び、それぞれのルールを書き出してください。例:パスワードリセットメール(速いリトライ、短い最大試行回数)、夜間レポート(試行回数は少なめ、タイムアウト長め)、Webhook配信(多めのリトライ、長いバックオフ、恒久的な4xxで停止)。
データベースキューが限界になるのはいつか迷ったら、次のようなシグナルを見てください:多くのワーカーによる行レベルの争奪、複数ジョブタイプにまたがる厳密な順序の要件、1イベントが何千ものジョブをファンアウトする、異なるチームが別々のワーカーを所有していてクロスサービスで消費する必要がある、など。
素早いプロトタイプを作りたいなら、Koder.ai(koder.ai)のPlanning Modeでフローをスケッチして、jobsテーブルとワーカーループを生成し、スナップショットとロールバックで繰り返し改善してからデプロイできます。
よくある質問
いつリクエスト内で処理するのではなくバックグラウンドジョブに移すべきですか?
もしタスクが1〜2秒以上かかる、またはネットワーク呼び出し(メールプロバイダ、Webhookエンドポイント、遅いクエリ)に依存するなら、バックグラウンドジョブに移してください。
ユーザーのリクエストは、入力検証、主要データの書き込み、ジョブのエンキュー、そして素早いレスポンスに集中させるのが良いです。
データベースベースのキューで十分ですか、それともメッセージブローカーが必要ですか?
次のような場合はまずデータベースベースのキューから始めましょう:
- PostgreSQLを既に使っていて、処理量が穏やかである
- デバッグしやすい最も単純な方法が欲しい
- エンキューと処理を1つのサービスが担当している
非常に高いスループットや多くの独立したコンシューマ、サービス間でのイベント履歴のリプレイが必要になったら、メッセージブローカーやストリーミングツールを検討してください。
各ジョブレコードにはどんなフィールドを持たせるべきですか?
「何をするか」「次にいつ試すか」「前回何が起きたか」に答えられる基本を追跡してください。
実用的な最小セット:
ジョブペイロードには何を入れ、何を避けるべきですか?
出力(大きなレンダリング済みHTMLなど)を丸ごと保存するのではなく、入力を保存してください。
良いペイロードの例:IDや小さなオプション(例:user_id, template, report_id)
避けるもの:レンダリング済みのHTMLメール、大きなレポートデータのバイナリ、巨大なWebhookボディ。ジョブが大きなデータを必要とするなら、report_run_idやファイルキーのような参照を保存し、ワーカーが実行時に実データを取得するようにしてください。
複数のワーカーはどうやって同じジョブを取り合わないようにしますか?
重要なのは原子性のある「取得(claim)」ステップです。そうすれば二つのワーカーが同じジョブを取ることを防げます。
Postgresの一般的な方法:
- 期限が来た行をロック付きで選択(多くは
FOR UPDATE SKIP LOCKED) - すぐに
runningにしてlocked_at/locked_byをセットする
これでワーカーは水平にスケールしても同一行の二重処理を避けられます。
重複メールや重複Webhook配信をどう防ぐべきですか?
ジョブが二度実行されることを前提にして安全にする必要があります(クラッシュ、タイムアウト、リトライが原因で発生します)。簡単な方法:
welcome_email:user:123のようなidempotency_keyを追加する- 完了したキーの一意制約や別テーブルでの記録を使う
- 再度実行されたらキーを検出して送信/配信をスキップする
これはメールやWebhookでの重複を防ぐために特に重要です。
どんなリトライとバックオフ戦略を最初に使うべきですか?
分かりやすく平凡なデフォルトポリシーを使ってください:
- 一時的な失敗(タイムアウト、429、5xx)のみリトライする
- ジッター付きの指数バックオフを使う
- 試行回数に上限を設ける(一般的に5〜8回)
- 各試行にタイムアウトを設け、ワーカーがハングしないようにする
恒久的なエラー(欠落したメールアドレス、無効なペイロード、ほとんどの4xxレスポンス)では速やかに失敗扱いにしてください。
デッドレタージョブとは何で、いつ使うべきですか?
デッドレターは「リトライを止めて可視化する」場所です。以下の場合に使います:
max_attemptsを超えたとき- エラーが明らかに恒久的なとき
- リトライすると害が出るとき(スパムや重複Webhookなど)
保存しておくべき情報例:
- ジョブタイプ、ペイロード(必要ならマスク)
- 試行回数とタイムスタンプ
- と(Webhookなら)最後のステータスコード
クラッシュ後に`running`のままになったジョブはどう扱うべきですか?
「ランニングのまま放置される」ジョブには二つのルールを適用します:
- 各試行にタイムアウトを設ける(作業を無期限に続けさせない)
- 定期的なリーパーが
runningのまま閾値を超えたジョブを検出して再キューするか失敗にする
これでワーカークラッシュから自動的に回復できます。
優先度や順序(レポートが重要なメールを遅らせないようにする)をどう扱えばよいですか?
遅い仕事が重要なメールをブロックしないように分離してください:
- パスワードリセットや確認メールのような緊急ジョブは高優先度キューへ
- 大きなレポートは低優先度キューへ
順序が重要な場合は通常「キーごと」に限定されます(ユーザーごと、請求書ごと、Webhookエンドポイントごと)。group_key を追加して、キーごとに同時実行を1つに制限すると局所的な順序を守れます。