2025年12月04日·1 分
メールを構造化ワークフローに置き換えるWebアプリを作る
メールスレッドを構造化ワークフローに置き換えるWebアプリの設計と構築方法。所有権、承認、ステータス追跡、監査トレイルを備えた運用改善の手順を解説します。
メールスレッドを構造化ワークフローに置き換えるWebアプリの設計と構築方法。所有権、承認、ステータス追跡、監査トレイルを備えた運用改善の手順を解説します。
メールは会話には優れていますが、運用を回す仕組みとしては不向きです。「全員返信」に頼る瞬間、チャットツールに対してデータベースやタスク管理、監査ログの役割を求めていることになりますが、どれについても保証はありません。
多くのチームが同じ場所で痛みを感じます:
構造化ワークフローはメールスレッドをレコードとステップに置き換えます:
成功を運用上の指標で定義します:応答時間の短縮、エラーや手戻りの減少、可視性の向上、監査可能性の強化など。
すべてを一度にやろうとしないでください。大量のメールを生み繰り返し発生するプロセスから始めましょう――購買承認、アクセス要求、コンテンツレビュー、顧客エスカレーションなど。1つのワークフローを成功させると信頼が生まれ、拡張時に再利用できるパターンができます。
最初のワークフローアプリは「メールをどこでも直す」必要はありません。スレッドより構造化が明確に有利な1つの運用プロセスを選び、日常の摩擦を取り除く小規模なアプリにします。
すでに繰り返しパターンがあり、複数のハンドオフと可視性の必要がある作業を探します。一般的な初勝利の例:
1日に「これ、どこ?」という質問が複数回出るなら良いサインです。
声の大きいステークホルダーだけが勝つのを防ぐためにシンプルな採点表を作ります(例:1–5で評価):
理想的な最初の選択は通常、高ボリューム+高痛みで中程度の複雑さです。
MVPの境界を決め、素早くローンチして信頼を得ます。まだやらないこと(高度なレポーティング、すべてのエッジケース、複数ツールを跨いだ自動化)を明確にします。MVPはコアのハッピーパスといくつかの共通例外をカバーすべきです。
選んだプロセスについて次の1段落を書きます:
これにより開発が集中し、ワークフローアプリが機能しているかを証明できます。
誰も書き下していないプロセスを「近代化」しようとすると自動化は失敗しがちです。ワークフロービルダーを開く前に、1週間かけて実際にメールでどのように作業が流れているかを書き出します。
短いインタビューでリクエスター(依頼する人)、承認者、オペレーター(作業を行う人)、管理者(アクセスや記録、ポリシーを扱う人)に話を聞きます。
「直近の3つのメールスレッドを見せてください」と実例を求めてください。常に求められる情報、議論になる点、失われる情報のパターンを探します。
プロセスをタイムラインとして書き、各ステップで次を記録します:
ここで隠れた作業が見つかります:『いつもSamに転送している、彼がベンダー連絡先を知っているから』や『24時間異議がなければ承認と見なす』といった非公式ルールは、アプリでは明示化しないと壊れます。
メールや添付から必要なフィールド(氏名、日付、金額、場所、ID、スクリーンショット、契約条項)を一覧化し、やり取りを引き起こす例外(情報不足、不明確な所有権、急ぎ、承認後の変更、重複、reply-allの混乱)を記録します。
最後に以下をマークします:
このマップがビルドのチェックリストとなり、新しいワークフローアプリが別のUIで同じ混乱を再現しないようにします。
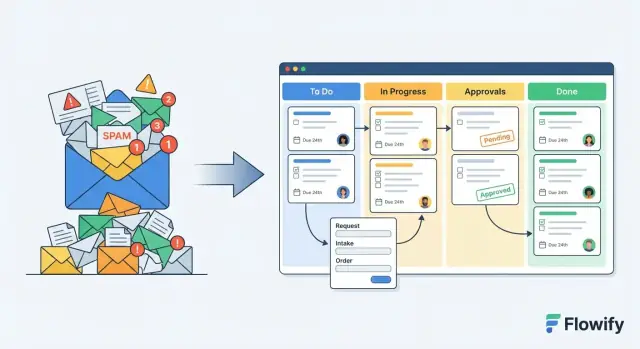
メールスレッドは決定、ファイル、ステータス更新を長い流れに混ぜ込みます。ワークフローアプリはそれを検索・ルーティング・監査できるレコードに変えることで機能します。
ほとんどのメールベースの運用は少数のビルディングブロックで表現できます:
最初のバージョンではルーティングと完了に必要なものだけを必須にし、それ以外は任意にします。
ルール:フィールドがルーティング、検証、レポーティングに使われないなら必須にしない。短いフォームは入力完了率を上げ、やり取りを減らします。
初日から次の退屈だが重要なフィールドを入れます:
これらがステータストラッキング、SLAレポート、監査トレイルを支えます。
典型的なパターンは1つのRequest → 多数のTasksとApprovalsです。承認はステップ(例:Finance approval)に属し、以下を記録すべきです:
権限設計はロール+リクエスト所有権に基づくことが多く、元々メールを受け取った人に依存しないようにします。
ワークフローアプリの成否は、誰がリクエストを見ても次に何が起きるかを即座に理解できるかにかかっています。その明確さは少数の状態、明示的な遷移ルール、いくつかの想定済み例外パスから生まれます。
初日から細かいニュアンスをモデル化しないでください。シンプルなベースラインで多くの運用リクエストをカバーできます:
“Draft”は作成者だけの作業中。“Submitted”はプロセスの所有に移ったことを示す。“In Review”は処理中、“Approved/Rejected”は意思決定を示す。“Completed”は作業が完了したことを確認します。
状態間の各矢印に所有者とルールを設けます。例:
UIでは許可されたアクションをボタンとして表示し、その他は非表示/無効化してステータスドリフトや裏ルート承認を防ぎます。
SLAターゲットを使うのは有効です(通常はSubmittedまたはIn Reviewから決定まで)。保存するもの:
メールベースのプロセスは例外に依存しているため、アプリにも安全な脱出口が必要です:
例外が稀でないなら、それをファーストクラスの状態に昇格させましょう。“ただメッセージして”にはしないでください。
ワークフローアプリは、人が数秒で作業を進められるときに機能します。目的は派手なUIではなく、「検索→スクロール→全員返信」の習慣を明確なアクションと信頼できる確認場所に置き換える少数の画面です。
予測可能なUIパターンを用意し、ワークフロー全体で再利用します:
これらがしっかりしていれば、最初のバージョンでは多くのチームが追加画面を必要としません。
各リクエスト詳細ページは即座に次の2つに答えるべきです:
実用的なUI要素:目立つステータスバッジ、上部の「Assigned to」フィールド、主要アクションボタン(Approve、Request changes、Complete、Send to Finance)。副次的な操作(フィールド編集、ウォッチャー追加、関連レコード)はメインフローから外してためらいを減らします。
メールベースの運用はほぼ同じ要求が繰り返されます。テンプレートは再入力をなくし、「忘れたかも?」問題を解消します。
テンプレートに含められるもの:
時間がたつとテンプレートは組織の実際の運用を明らかにし、ポリシーの洗練やワンオフの削減に役立ちます。
アプリとメールで会話が分断すると単一の真実の源が失われます。リクエスト詳細ページを正典のタイムラインと扱ってください:
これにより、新しい人がリクエストを開けば、何が求められたか、何が決まったか、次に何が必要かを受信箱を探ることなく理解できます。
メールが運用に失敗するのは、全ての更新を放送扱いするからです。ワークフローアプリはその逆を目指すべきです:意味のあるときに、必要な人だけに、次のアクションが分かる形で通知する。
実際のワークフロー瞬間に対応する小さな通知イベントを定義します:
ルール:誰かがアクションを取れない、またはコンプライアンスのために認識する必要がないなら通知すべきではありません。
アプリ内通知(ベルアイコン、Assigned to meリスト、キュー表示)をデフォルトにし、メールは配信チャネルとして残します。ユーザーコントロールの例:
これで割り込みを減らしつつ、緊急の作業を隠しません。
それぞれの通知に含めるべき情報:
/requests/123)通知が「何が起きたか、なぜ私か、次に何をするか」を一目で答えられない場合、それは別のメールスレッドに変わってしまいます。
メールは誰でも転送・コピー・検索できるので"シンプル"に見えますが、ワークフローアプリでは同じ可用性を与えつつ無秩序にならないようにする必要があります。権限は後回しではなくプロダクト設計の一部と考えてください。
小さなロールセットから始め、ワークフロー全体で一貫させます:
ロールは人々が理解しやすいアクション("承認する","実行する")に結びつけ、チームごとの職位に依存しないようにします。
誰が表示、編集、承認、エクスポート、管理できるかを明確に決めます。実用的なパターン:
添付ファイルはしばしば機密を含むため、レコードだけでなくファイル単位で権限を適用してください。
監査トレイルは以下を捕捉すべきです:
ログは検索可能で改ざんが明らかになる形にし、閲覧は管理者に限定するなどの運用を検討します。
リクエスト、コメント、ファイルをどのくらい保持するか、“削除”が意味すること、リーガルホールド対応の必要性を早期に決めます。バックアップや統合バックアップにまたがって約束を守れるか注意してください("すべて即時削除"のような約束は慎重に)。
ワークフローアプリはメールスレッドを置き換えますが、人々に同じ情報を5か所再入力させるべきではありません。統合が「便利な内部ツール」を実際に信頼されるシステムに変えます。
識別、スケジューリング、作業位置を担うツールとまず統合します:
小さなセットのインバウンド(外部が通知)とアウトバウンドwebhook(アプリが他を通知)を計画します。重要なイベントに絞る:レコード作成、ステータス変更、割当変更、承認結果。
ステータス変更をトリガーとして扱います。例えばレコードが“Approved”になったら自動的に:
これにより人手の中継が減り、メールのリレーのような状況を避けられます。
統合は失敗します:権限が切れる、APIがレート制限される、ベンダーに障害が起きる。手動入力とその後の突合せをサポートし、「手動で追加」といったフラグを残して信頼性を保てるようにします。
最初のワークフローアプリは、どれだけ早く使えるものを出せるかと、人々が依存するようになったときに安全に動くかで成功が決まります。
決定ルール:プラットフォームの制限がどこにあるか明確でないならローコードで始め、制限が致命的とわかっているならビルドかハイブリッドを選びます。
メール駆動の運用を素早くワークフローアプリに置き換えたいなら、Koder.aiのようなvibe-codingプラットフォームは実務的な選択肢です。チャットでプロセスを記述し、フォーム/キュー/ステートを反復して出し、空のリポジトリから始めずに動くアプリを出せます。Reactフロントエンド、Goバックエンド、PostgreSQLのようなモダンスタックに基づくシステムは、前述のアーキテクチャに自然にマップし、必要になればソースコードをエクスポートできます。
計画モード、スナップショットとロールバック、組み込みのデプロイ/ホスティングなどの機能は、実運用中にワークフローを変えるリスクを下げます。厳格な要件がある組織向けに、グローバルなAWSホスティングやリージョン別実行のサポートがあるとデータ居住性や国境を跨ぐデータ転送の制約に対応しやすくなります。
信頼できるワークフローアプリは大抵4つの部分からなります:
失敗を前提に設計します:
早期に期待値を設定します:ほとんどのページは約1–2秒で読み込まれ、主要アクション(提出・承認)は即時感を持つべきです。ピーク利用(例:午前9時に50人)がどれくらいかを見積もり、基本的な監視(レイテンシ、エラー率、ジョブキューのバックログ)を計装します。監視は“あると良いもの”ではなく、メールがフォールバックでなくなった後に信頼を維持するために必要です。
ワークフローアプリは機能として"ローンチ"するだけではなく、メールの習慣を置き換える必要があります。良い導入計画は全部を出すことではなく、人々が操作依頼をメールで送らなくなるのを助けることに集中します。
1チームと1ワークフローを選び(例:購買承認、顧客例外、内部リクエスト)、初週に全ユーザーをサポートできる範囲にします。成功指標を事前に定義:
パイロットは2–4週間実施し、目的は完璧さではなく実際のボリュームをさばけることを検証することです。
すべての古いメールスレッドを一斉移行するのは避けます。まずはアクティブなリクエストを移行してチームに即時価値を提供します。
履歴データが監査や報告で重要なら選択的に移行:直近30–90日分、ハイバリュー/ハイリスクカテゴリ、監査に必要な記録など。その他はメールアーカイブに残しておき、時間や必要性に応じてインポートします。
人が実際に使うトレーニングを用意します:
トレーニングはタスクベースにし、メールでしていたことが具体的に何で置き換わるかを示します。
新しい経路がワンクリックで行けると定着が進みます:
時間が経てばアプリがデフォルトの受付になり、メールは通知チャネルに留まります。
ワークフローアプリの立ち上げはスタート地点です。勢いを保ち価値を証明するには、何が変わったかを測り、現場の声を聞き、リスクの低い小さな改善を続けます。
アプリのレコードから一貫して取れる少数の指標を選びます(逸話ではなく定量データ)。一般的で高信頼の選択肢:
可能なら、メール駆動の作業の過去数週間のベースラインを取り、ローンチ後と比較します。週次のスナップショットでも十分です。
数値は何が変わったかを示し、フィードバックはなぜ変わったかを説明します。アプリ内の軽いプロンプトや短いフォームで集めます:
フィードバックは可能ならレコードに紐づけておくと実行可能になります。
ワークフローの変更は業務を壊す可能性があるため保護が必要です:
最初のワークフローが安定したら、ボリューム、リスク、痛みに基づき次の候補を選びます。同じパターン(明確な受付、ステータス、所有権、レポーティング)を再利用すると、各ワークフローが馴染みやすく採用が続きます。
(公開ビルドしているなら、何を作ったかを公開シリーズにして導入を加速するのも有効です。Koder.aiのようなプラットフォームは作成した内容についてのコンテンツでクレジットが得られたり、紹介でコストを相殺できたりする仕組みを提供する場合があります。)
メールのスレッドは、オペレーションに必要な保証(明確な所有権、構造化されたフィールド、一貫したステータス、信頼できる監査ログ)を提供しません。ワークフローアプリは各リクエストをレコードとして扱い、必須データ、明示的なステップ、現在の担当者を可視化することで、作業が受信箱で止まるのを防ぎます。
スレッドをレコード+ステップに置き換えることです:
結果として、やり取りが減り、実行が予測しやすくなります。
日々の摩擦を生む高頻度なプロセスを1〜2個選びます。強い候補は、購買承認、オンボーディング、アクセス要求、コンテンツ承認、エスカレーションなどです。
簡単なテスト:人々が「これ、今どこまで?」と1日に複数回聞くなら、ワークフローの対象に向いています。
以下で各プロセスを簡易採点します(1–5など):
通常の良い最初の選択は、で、を持つものです。
MVPはハッピーパスといくつかの一般的な例外をカバーする範囲に限定します。高度なレポーティング、稀なエッジケース、複数ツール間の自動化などは後回しに。
「完了」の定義は測定可能に:
こうした基準があれば素早くローンチして信頼を得やすくなります。
チェンジの自動化やアプリ設計に失敗しないために、まず1週間かけて実際のメールでのワークフローをマップします。目標は「あるべき姿」ではなく「本当に動いている流れ」を把握することです。
このマップがビルド時のチェックリストになり、新UIで同じ混乱を再現するのを防ぎます。
いくつかのコアエンティティから始めます:
小さく明確な状態遷移とルール、いくつかの例外経路があれば、誰が次に何をすべきかが一目でわかります。
基本の状態機械例:
各遷移には「誰が」「どんな条件で」実行できるかを定義します(例:Draft→Submittedはリクエスターのみ)。UIでは許可された操作をボタンで表示し、それ以外は非表示/無効化して「ステータスドリフト」を防ぎます。
また、遅延に対するSLA目標や期限、再作業/キャンセル/エスカレーションのための例外パスも初期から計画しておきます。
まずは4つの画面があれば多くの運用ニーズを満たせます:
リクエスト詳細ページは「誰が今担当か」と「次に何をするか」が即わかる設計に。ステータスバッジ、Assigned toフィールド、主要アクションボタン(Approve、Request changes、Completeなど)を目立たせ、二次的な操作はメインフローから外します。
CCで全員に流す代わりに、実際のワークフローイベントに基づくアラートだけを送ります。重要なのは「誰に」「なぜ」「次に何をすべきか」が一目でわかること。
通知イベント例:Submitted(キューに到着)、Assigned(担当者通知)、Needs changes(リクエスターへ修正依頼)、Approved(決定通知)、Overdue(まず担当者、次に管理者へエスカレーション)。
デフォルトはアプリ内通知にし、メールは配信チャネルの一つとしてオプションで提供します。各通知は必ず深いリンク(例:/requests/123)、レコードID/名前、ステータス、受信理由、主要アクションを含めてください。
役割ベースでシンプルに定義します(Requester、Approver、Operator、Admin)と、役割に基づく操作権限をプロダクト設計の一部として扱います。
最小権限の原則を適用し、たとえば:
監査ログにはステータス変更(from/to)、承認/却下と理由、主要フィールドの編集(old/new)、ファイルアクセス/ダウンロードを記録し、検索可能かつ改ざんがわかる形にします。保存期間やリーガルホールドの要件も早めに決めておきます。
コピペを減らす統合から始めます:
イベント駆動設計を念頭に置き、重要イベント(レコード作成、ステータス変更、割当変更、承認結果)でwebhookやAPIを叩く小さな契約を作ります。統合が失敗したときのために「手動入力(手動追加)」のフォールバックとフラグを用意しておくことも重要です。
3つの導入パターンがあります:
プラットフォームの限界が不明瞭ならローコードで始め、明らかに制限が許容できないならビルド/ハイブリッドを選ぶのが現実的です。
例えば、Koder.ai のようなvibe-codingプラットフォームは、チャットでプロセスを説明しながらフォーム/キュー/ステートを反復して作り、素早く動くWebアプリを出せるため、メール駆動の運用を短期間で置き換える実務的な選択肢になり得ます。ソースエクスポートやデプロイ機能、リージョン別ホスティングなども用意されていれば、要件に合わせて柔軟に対応できます。
シンプルで壊れにくいアーキテクチャの基本要素:
信頼性の基本(最初から計画すべき):リトライ、冪等性、エラーハンドリング+デッドレターキュー、バックアップと復元テスト。
パフォーマンスと監視も早期に設定:ページ読み込み1–2秒、主要アクションは即時感、ピーク利用想定(例:9時に50人)に対する監視(レイテンシ、エラー率、ジョブキューのバックログ)を用意します。
ワークフローは習慣を置き換えるものなので、ローンチよりも導入計画が重要です。
タイトなパイロットで始める:1チーム・1ワークフローを2–4週間実施し、成功指標を事前に定義(リクエストから完了までの時間、やり取り回数、アプリ経由提出率、再作業率など)。
必要なものだけ移行する:進行中のリクエストを優先して移行。履歴データは直近30–90日分や監査に必要なものを選んで移す。
短時間で学べるトレーニング:10分のウォークスルーと1ページのチートシート(提出方法、ステータス確認、エスカレーション)を用意。
「ワークフローに送る」習慣化:フォームへのワンリンク配置、テンプレートや内部ドキュメントへのリンク、メールで来た依頼にはワークフローリンクを一度返信して以降は移行するなど、デフォルト経路を作ります。
ローンチは始まりにすぎません。成果を示し続け、ユーザーの声を取り込みながら小さなリリースで改善していきます。
追うべき指標例(アプリの記録から一貫して取れるもの):
早期に入れるべき必須項目:安定したID(例:REQ-1042)、CreatedAt/UpdatedAt、CreatedBy、CurrentOwner。これらがトレーサビリティ/SLA/監査を支えます。
定量データに加え、アプリ内で軽いフィードバックを集める(何が遅いか、何が混乱するか、何が足りないか)と良いです。変更はワークフローのバージョン管理、限定パイロットでのテスト、短いチェンジログで安全に展開します。
最初のワークフローが安定したら、次の候補をボリューム、リスク、痛みで選び、同じパターン(明確な受付、ステータス、所有権、レポーティング)を再利用して拡大していきます。