2025年4月04日·1 分
内部ツールの信頼性トラッキング用ウェブアプリの作り方
内部ツールの信頼性(SLI/SLO、インシデントワークフロー、ダッシュボード、アラート、レポート)を追跡するウェブアプリを設計・構築する方法を学びます。
内部ツールの信頼性(SLI/SLO、インシデントワークフロー、ダッシュボード、アラート、レポート)を追跡するウェブアプリを設計・構築する方法を学びます。
メトリクスやダッシュボードを選ぶ前に、アプリが何を担い、何を担わないかを決めてください。スコープが明確でないと、誰も信用しない“何でもありのオプスポータル”になってしまいます。
まずアプリでカバーする内部ツール(例:チケット、給与、CRM連携、データパイプライン)と、それらを所有/依存するチームを列挙します。境界を明確にしてください:例えば「顧客向けウェブサイト」は範囲外にして「内部管理コンソール」は範囲内、など。
組織によって「信頼性」の使い方は違います。作業定義を平易な言葉で書き出しましょう。通常は以下の混合です:
チーム間で合意が得られないと、異なる基準の比較になってしまいます。
以下のような主要成果を1〜3つ選びます:
これらが後で何を測り、どう表示するかの指針になります。
誰がアプリを使い、どんな判断をするのかを列挙します:インシデントを調査するエンジニア、エスカレーションするサポート、傾向を見るマネージャ、ステータスを必要とするステークホルダーなど。用語、権限、各ビューの詳細度はこれで決まります。
信頼性トラッキングは「良い」の定義に皆が合意しているときにだけ機能します。まず似た用語を区別しましょう。
**SLI(Service Level Indicator)**は測定値です:「リクエストの何%が成功したか?」や「ページの読み込みにどれだけ時間がかかったか?」など。
**SLO(Service Level Objective)**はその測定に対する目標です:「30日で99.9%成功」など。
SLA(Service Level Agreement)は結果に対する約束で、通常は外部向け(クレジットやペナルティ)。内部ツールでは、契約的な重さを避けつつ期待を揃えるためにSLOを設定することが多いです。
ツール間で比較しやすく説明も簡単に保ちます。実用的なベースラインは:
「このメトリクスは何を判断させるか?」に答えられるまで追加しないでください。
ローリングウィンドウを使ってスコアカードを常に更新します:
アプリはメトリクスを行動につなげるべきです。重大度(例:Sev1–Sev3)と明確なトリガーを定義してください:
これらの定義によりアラート、インシデントのタイムライン、エラーバジェット追跡がチーム間で一貫します。
信頼性トラッキングは、その背後にあるデータの信頼性が高いほど価値があります。取り込みパイプラインを作る前に、どのシグナルを“真実”として扱うかをマップし、それがどの質問に答えるのかを書き出してください(可用性、レイテンシ、エラー、デプロイ影響、インシデント対応など)。
ほとんどのチームは以下の組み合わせで基本をカバーできます:
どのシステムを権威あるものとするか明示してください。例えば「稼働SLIは合成プローブのみをソースとする」など。
ユースケースに応じて更新頻度を決めます:ダッシュボードは1–5分ごと、スコアカードは毎時/日次で計算することが多いです。
ツール/サービス、環境(prod/stage)、オーナーの一貫したIDを作ってください。命名ルールに早く合意しておかないと “Payments-API”、“payments_api”、“payments” が別々の存在になってしまいます。
何をどれだけ保持するか計画します(例:生イベントは30–90日、日次集計は12–24ヶ月)。機密ペイロードは取り込まないで、信頼性分析に必要なメタデータ(タイムスタンプ、ステータスコード、レイテンシバケット、インシデントタグ)だけを保存するようにしてください。
スキーマは次の2つを簡単にするべきです:日常の質問に答えること(「このツールは健全か?」)とインシデント時に何が起きたか再構築すること(「いつ症状が始まり、誰が何を変更し、どのアラートが発生したか?」)。まずはコアエンティティを小さく始め、関係性を明示してください。
実用的なベースラインは:
この構造はダッシュボード(tool → 現在のステータス → 最近のインシデント)やドリルダウン(incident → events → 関連するチェックとメトリクス)をサポートします。
説明責任と履歴が必要な箇所には監査フィールドを追加します:
created_by, created_at, updated_atstatus と ステータス変更の追跡(Eventテーブルか専用の履歴テーブルで)最後にフィルタと報告のために柔軟なタグを含めてください(例:team、criticality、system、compliance)。tool_tagsジョインテーブル(tool_id、key、value)は一貫したタグ管理と集計を容易にします。
信頼性トラッキングは「地味であること」が美徳です:運用が簡単で、変更しやすく、サポートしやすいこと。チームがメンテナンスできるスタックが通常は最良です。
チームがよく知るメインストリームなウェブフレームワークを選んでください—Node/Express、Django、Rails はどれも堅実です。優先すべきは:
内部システム(SSO、チケッティング、チャット)との統合が多いなら、そのエコシステムでの実装が楽になります。
初期を加速したければ、Koder.ai のようなvibe-codingプラットフォームは実用的な出発点になり得ます:エンティティ(tools、checks、SLOs、incidents)、ワークフロー(alert → incident → postmortem)、ダッシュボードをチャットで記述し、動作するウェブアプリのスキャフォールドを素早く生成できます。Koder.ai は一般にフロントエンドに React、バックエンドに Go + PostgreSQL をターゲットにするため、多くのチームが好む「地味で保守しやすい」デフォルトスタックに適合し、後で完全に手動のパイプラインに移すためにソースコードをエクスポートできます。
ほとんどの内部信頼性アプリでは PostgreSQL がデフォルトで適切です:リレーショナルな集計、時系列クエリ、監査に強いです。
必要に応じて次を追加します:
選択肢:
どちらを選ぶにせよ、dev/staging/prod を標準化し、CI/CDでデプロイを自動化してください。変更が信頼性の数値を静かに変えないようにします。プラットフォーム型(Koder.ai含む)を使う場合は、環境分離、デプロイ/ホスティング、スナップショットによる高速ロールバックのような機能があると安全に反復できます。
環境変数、シークレット、機能フラグを一か所にドキュメント化します。ローカルでの実行方法と、取り込みが止まったとき/キューが詰まったとき/DBが限界に達したときの最小限のランブックを用意してください。/docs に短いページを置くだけで十分なことが多いです。
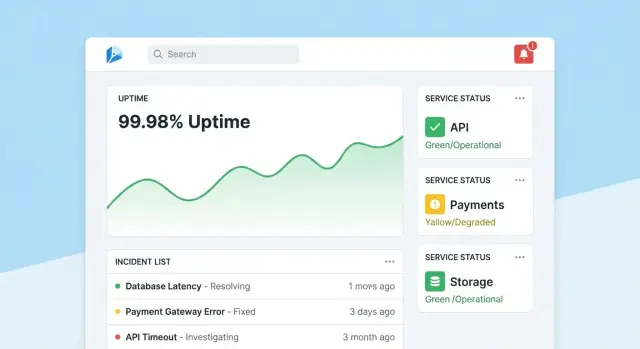
信頼性トラッキングアプリが成功するのは「数秒で2つの質問に答えられる」時です:「大丈夫か?」と「次に何をするか?」。概要 → 特定ツール → 特定インシデントへの明確なナビゲーションで画面を設計してください。
ホームはコンパクトなコマンドセンターにします。まず全体の健全性サマリ(SLOを満たすツール数、アクティブインシデント、現在の最大リスク)を示し、最近のインシデントとアラートをステータスバッジ付きで表示します。
デフォルトビューは落ち着かせること:注意が必要なものだけをハイライトし、各タイルから影響を受けたツールやインシデントへ直接ドリルダウンできるようにします。
各ツールページは「このツールは十分に信頼できるか?」と「なぜ/なぜ違うのか?」に答えるべきです。含める項目:
チャートは非専門家向けに設計します:単位のラベル、SLO閾値のマーク、ツールチップによる小さな説明を付けて、密な技術的コントロールは避けます。
インシデントページは生きた記録です。タイムライン(アラート発生、認識、緩和などの自動キャプチャイベント)、人的アップデート、影響範囲、取られた対策を含めます。
更新は簡単に公開できるようにしてください:1つのテキストボックス、定義済みステータス(Investigating/Identified/Monitoring/Resolved)、オプションの内部ノート。インシデント終了時に「ポストモーテムを開始」するとタイムラインの事実で事前入力されると便利です。
管理者向けにはツール、チェック、SLO目標、オーナーを管理するシンプルな画面を用意します。正確性を最優先に:妥当なデフォルト、バリデーション、報告に影響する変更時の警告を出します。人々が数値を信用するように「最終編集」トレイルを表示してください。
信頼性データは人々がそれを信用して初めて役に立ちます。すべての変更を身元に結びつけ、高影響な編集を制限し、振り返り時に参照できる明確な履歴を保持してください。
内部ツールならSSO(SAML)やOAuth/OIDCをIdP(Okta、Azure AD、Google Workspace)経由で使うのが標準です。これによりパスワード管理が減り、オンボード/オフボードが自動化されます。
実践的な注意点:
まずはシンプルなロールを用意し、必要になったら細かくします:
信頼性の結果や報告を変えうるアクションは保護します:
SLO、チェック、インシデントフィールドのすべての編集をログに残します:
監査ログは検索可能にし、関連する詳細ページ(例:インシデントページ)から見られるようにします。レビューを事実に基づいて行えるようになり、ポストモーテム時のやり取りが減ります。
監視はアプリの「センサー層」です:実際の挙動を信頼できるデータに変換します。内部ツールでは、合成チェックが最も速い道になることが多いです(何を「健康」とみなすかをコントロールできるため)。
多くの内部アプリをカバーする小さなチェックタイプをまず用意します:
検証は決定的に(deterministic)保ってください。コンテンツが変化するために失敗する可能性がある検証を作るとノイズになり信頼が失われます。
各チェック実行で以下を捕捉します:
データは時系列イベント(チェック実行ごとに1行)として保存するか、集計インターバル(例:1分ごとのロールアップ)として保存します。イベントデータはデバッグに有用で、ロールアップは高速ダッシュボードに適します。多くのチームは両方を採用します:生イベントは7–30日保存、ロールアップは長期保存。
欠測結果を自動的に“ダウン”としないでください。次のようなケースに対して**unknown(不明)**状態を追加します:
これにより稼働率の過大評価を防ぎ、監視ギャップ自体を運用の課題として可視化できます。
チェックはバックグラウンドワーカー(cronライクなスケジューリング、キュー)で固定間隔(重要なツールなら30–60秒ごと)に実行します。タイムアウト、バックオフ付きリトライ、同時実行の上限を組み込み、チェッカーが内部サービスを過負荷にしないようにしてください。すべての実行結果を保存(失敗も含む)して、稼働監視ダッシュボードで現在のステータスと信頼できる履歴を示せるようにします。
アラートは信頼性トラッキングを行動につなげます。目標は単純:適切な人に、適切なコンテキストで、適切なタイミングで通知する—ただし全員を氾濫させないこと。
まずSLI/SLOに直接マップするアラートルールを定義します。実務的なパターンは2つ:
各ルールには「何のSLOに影響するか」「評価ウィンドウ」「想定重大度」の“なぜ”を保存してください。
チームが普段いるチャネル(メール、Slack、Microsoft Teams)に通知を送ります。各メッセージには:
生データのダンプは避け、短い「次のステップ」(例:「最近のデプロイを確認」や「ログを開く」)を示してください。
実装事項:
内部ツールでも人々は制御を必要とします。アラート/インシデントページに手動エスカレーションボタンを追加し、利用可能ならPagerDuty/Opsgenie相当との統合、または少なくともアプリ内で設定可能なローテーションリストを用意してください。
インシデント管理は「アラートを見た」から「協調して対応する」までをつなぎます。人々がツール間を飛び回らずにシグナルからコーディネーションに移れるようこれをアプリに組み込みます。
アラート、サービスページ、稼働チャートから直接インシデントを作成できるようにします。主要フィールド(サービス、環境、アラート源、初回観測時刻)を事前入力し、ユニークなインシデントIDを割り当てます。
デフォルトのフィールドは軽量に保つ:重大度、影響範囲(内部チーム)、現在のオーナー、トリガー元アラートへのリンクなど。
実際のチーム運用に合わせたシンプルなライフサイクルを使います:
各ステータス変更は誰がいつ行ったかを記録します。タイムライン更新(短いタイムスタンプ付きノート)、添付ファイル、ランブックやチケットへのリンク(例:/runbooks/payments-retries、/tickets/INC-1234)をサポートしてください。これが「何が起き、何をしたか」のスレッドになります。
ポストモーテムは素早く開始でき、レビューが一貫するようにします。テンプレートに以下を用意:
アクションアイテムをインシデントに紐づけて進捗を追跡し、期限超過はチームのダッシュボードで目立たせます。学習レビューをサポートする場合は「個人の責任追及を避ける」モードでシステム/プロセスの変更に焦点を当てられるようにします。
レポーティングは信頼性トラッキングを意思決定に変える部分です。オペレータ向けのダッシュボードと、リーダーが改善状況を理解するためのスコアカードを用意します。
ツールごと(オプションでチーム別)に一貫したビューを作り、次の質問に素早く答えられるようにします:
可能な箇所には軽い文脈を追加:「SLO未達は2件のデプロイが原因」や「主要ダウンは依存先Xから」など。レポートを完全なインシデントレビューにしないよう注意します。
リーダーは「全部」ではなく要点を見たいことが多いです。チーム、ツール重要度(Tier 0–3)、時間ウィンドウでフィルタできるようにしてください。同じツールが複数の集計に現れる(プラットフォームチームが所有、ファイナンスが依存)ことを想定してください。
外部共有用に週次/月次サマリを提供します:
ナラティブは一貫性を保ちます(「前期間から何が変わったか?」「どこが予算超過か?」)。必要ならステークホルダー向けの短いガイドへのリンクを付けます(例:/blog/sli-slo-basics)。
信頼性トラッカーはすぐに“真実のソース”になります。プロダクションシステムとして扱い、デフォルトで安全に、データ汚染に強く、障害時に復旧しやすいようにしてください。
すべてのエンドポイントをロックダウンします(「内部限定」も含めて)。
認証情報をコードやログに置かないでください。シークレットマネージャに保存し、定期的にローテーションします。ウェブアプリには最小権限のDBアクセスを与え、読み取り専用/書き込み専用ロールを分け、必要なテーブルのみアクセス可能にします。可能なら短時間有効な認証情報を使います。ブラウザ↔アプリ、アプリ↔DB間はTLSで暗号化します。
信頼できるイベントが前提です。サーバー側でタイムスタンプ(タイムゾーン/クロックずれ)、必須フィールド、冪等キーによる重複排除をチェックします。取り込みエラーはデッドレターキューや“隔離”テーブルで追跡し、壊れたイベントがダッシュボードを汚染しないようにします。
データベースマイグレーションを自動化し、ロールバックのテストを行います。バックアップをスケジュールし、定期的に復元テストを実施し、最小限の災害復旧計画(誰、何、どのくらいの時間)を文書化します。
最後に、信頼性アプリ自身を信頼できるものにします:ヘルスチェック、キュー遅延やDBレイテンシの基本的な監視を追加し、取り込みがゼロに沈んだときにアラートを出してください。
信頼性トラッキングアプリは、人々がそれを信頼して実際に使うときに成功します。最初のリリースを“ビッグバン”ではなく学習ループとして扱ってください。
広く使われていて明確なオーナーがいる内部ツールを2–3個選びます。小さなチェックセット(例:ホームページの可用性、ログイン成功、主要APIエンドポイント)を実装し、「稼働しているか?もし違うなら何が変わり誰が担当か?」に答えるダッシュボードを公開します。
パイロットは可視化しつつ限定的に:1チームか少数のパワーユーザーでフローを検証します。
最初の1–2週間で次を積極的に集めます:
フィードバックは具体的なバックログ項目に変えます。チャートごとの「このメトリクスに問題を報告する」ボタンは最速の洞察を浮き上がらせます。
機能は段階的に付け加えます:まずチャット通知、次にインシデントツールとの自動チケット作成、その次にCI/CDからのデプロイマーカー。各統合は手作業を減らすか診断時間を短縮するものでない限り複雑さを増すだけです。
プロトタイプを素早く作るなら、Koder.ai の planning モードで初期スコープ(エンティティ、ロール、ワークフロー)をマッピングしてから最初のビルドを生成する方法が便利です。スナップショットとロールバックができるため、チームが定義を洗練する中で安全にダッシュボードと取り込みを反復できます。
より多くのチームに展開する前に、ダッシュボード週次アクティブユーザー数、検知までの時間短縮、重複アラートの削減、一貫したSLOレビューなどの成功指標を定義します。/blog/reliability-tracking-roadmap に軽いロードマップを公開し、ツール単位でオーナーとトレーニングセッションを明確にして拡大してください。
まずはスコープ(どのツールと環境を含めるか)と、信頼性の作業定義(可用性、レイテンシ、エラー)を定義してください。次に改善したい主要な1〜3つの成果(例:検知の高速化、報告の明確化)を決め、最初の画面を「大丈夫か?」「次に何をするか?」という主要な意思決定に合わせて設計します。
SLIは測定項目です(例:成功リクエストの割合、p95レイテンシ)。
SLOはその測定に対する目標です(例:30日で99.9%)。
SLAは結果に対する正式な約束(通常は外部向け)で、違反時のペナルティなどが伴います。内部ツールでは、SLOで期待を揃えつつ、SLAのような契約上の重さは避けるのが一般的です。
ツール間で比較可能かつ説明しやすい小さなベースラインを使います:
そのメトリクスがどんな意思決定(アラート、優先順位付け、キャパシティ対策など)につながるか説明できる場合にのみ追加してください。
ローリングウィンドウでスコアカードを常に更新します:
組織がどのようにパフォーマンスをレビューするかに合わせてウィンドウを選ぶと数字が直感的に使われます。
ユーザー影響と継続時間に基づく明確なシビリティトリガーを定義します。例えば:
これらをアプリ内に書き残しておくと、アラート、インシデントタイムライン、レポートの一貫性が保てます。
各質問の“真実のソース”をマッピングします:
例:「稼働SLIはプローブのみをソースとする」と明記しないと、どの数値が正しいかで議論になります。
ポーリング可能なAPIやチケットAPIにはpullを使い、デプロイやアラートのような高頻度/リアルタイムイベントにはpush(webhook)を使います。多くの場合、ダッシュボードは1〜5分ごとに更新し、スコアカードは毎時/日次で計算します。
一般的に必要なエンティティは:
すべての高影響な変更を 誰が/いつ/何を(変更前/変更後)/どこから(UI/API/自動化) の形で記録します。ロールベースのアクセスはシンプルに始めて、必要になれば細かくします:
この組み合わせが、信頼できる数値を守るための基本になります。
欠測結果を自動で“ダウン”と見なさず、**unknown(不明)**という別の状態を用意してください。欠測の原因例:
“unknown”を可視化することで、稼働率の過大評価や監視ギャップを特定できます。
関係性を明確にしておく(tool → checks → metrics、incident → events)と「一覧 → 詳細」クエリが単純になります。