2025年8月30日·1 分
Nginx vs HAProxy:適切なリバースプロキシの選び方
Nginx と HAProxy のリバースプロキシ比較:性能、ロードバランシング、TLS、可観測性、セキュリティ、一般的な構成パターンから最適な選択を導くガイド。
Nginx と HAProxy のリバースプロキシ比較:性能、ロードバランシング、TLS、可観測性、セキュリティ、一般的な構成パターンから最適な選択を導くガイド。
リバースプロキシはアプリケーションの前に置かれ、クライアントのリクエストを最初に受け取るサーバーです。リクエストを適切なバックエンドサービス(アプリサーバー)へ転送し、応答をクライアントに返します。ユーザーはプロキシと話し、プロキシがアプリと話します。
フォワードプロキシは逆の働きをします:クライアント側の前に置かれ(例えば企業ネットワーク内)、発信リクエストをインターネットに転送し、制御やフィルタリング、匿名化を行います。
ロードバランサーはしばしばリバースプロキシとして実装されますが、特に「複数のバックエンドインスタンスにトラフィックを分配する」ことに焦点を当てています。Nginx や HAProxy を含む多くの製品はリバースプロキシとロードバランシングの両方を行えるため、用語が混同されることがあります。
多くの導入は以下の一つ以上の理由から始まります:
/api を API、/ を Web アプリに)。\n- バッファリングと接続管理:遅いクライアントやアップストリームのばらつきを平滑化し、アプリ側の接続オーバーヘッドを減らし、信頼性を向上させる。\n- 保護制御:リクエスト制限、基本的なフィルタリング、安全なデフォルトを実装してアプリ到達前に防御する。リバースプロキシは一般的に ウェブサイト、API、マイクロサービス のフロントに置かれます—エッジ(公開インターネット)でも、サービス間の内部でも。モダンなスタックでは、Ingress ゲートウェイ、ブルー/グリーンデプロイ、HA 構成のビルディングブロックとして使われます。
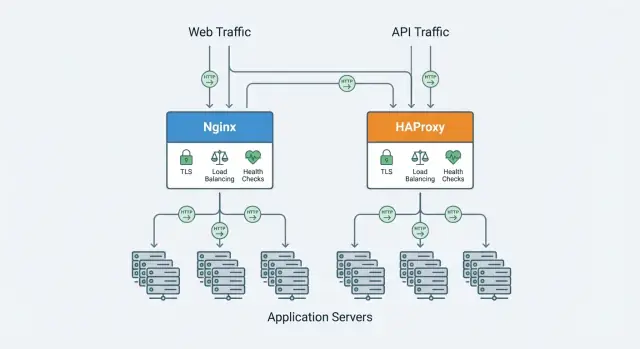
Nginx と HAProxy は重なる部分がありますが、重点が異なります。以下では 多数接続下の性能、ロードバランシングとヘルスチェック、プロトコル対応(HTTP/2、TCP)、TLS 機能、可観測性、そして 日常的な設定と運用 といった決定要因を比べます。
Nginx は ウェブサーバー として、また リバースプロキシ として広く使われています。多くのチームは公開サイトの配信で始め、後に TLS、ルーティング、スパイク緩和のためにアプリサーバーの前に置くようになります。
トラフィックが主に HTTP(S) で、1 つの「フロントドア」にいろいろ任せたい場合に Nginx は強みを発揮します。特に以下が得意です:
X-Forwarded-For、セキュリティヘッダー)コンテンツ配信とプロキシの両方をこなせるため、構成要素を少なくしたい小〜中規模の環境でよく選ばれます。
代表的な機能:
Nginx がよく選ばれる場面:
HTTP 処理が重要で、ウェブ配信とリバースプロキシを組み合わせたい場合、Nginx はデフォルトとしてよく選ばれます。
HAProxy(High Availability Proxy)は主に リバースプロキシ兼ロードバランサー として使われ、複数のアプリサーバーの前に置かれてトラフィックを受け、ルールを適用してヘルシーなバックエンドへ転送します。高い並列性の下でも応答時間を安定させることが求められる環境でよく使われます。
チームは通常、トラフィック管理のために HAProxy を導入します:リクエストを複数サーバーに分散し、障害時の可用性を保ち、トラフィックスパイクを緩和します。エッジ(north–south)や内部(east–west)両方で採用され、予測可能な振る舞いと接続制御が求められる場面で人気です。
HAProxy は多数の同時接続を効率的に扱うことで知られています。多くのクライアントが同時接続する(忙しい API、長寿命接続、チャット)ような場合にプロキシが応答し続けることが重要です。
またロードバランシング機能が充実しており、単純なラウンドロビン以上のアルゴリズムやルーティング戦略をサポートします。これにより:
ヘルスチェックも強力です。HAProxy は積極的なプローブでバックエンドの健全性を確認し、問題があるインスタンスを自動的にローテーションから外し、回復したら再投入します。これはダウンタイムを減らし「半壊」デプロイが全ユーザーに影響するのを防ぎます。
HAProxy は**レイヤー4(TCP)とレイヤー7(HTTP)**の両方で動作できます。
実務上の違い:L4 は単純で高速な TCP フォワードに向き、L7 は詳細なルーティングやリクエストロジックが必要な場合に強力です。
HAProxy は信頼性の高い高性能ロードバランシングと強力なヘルスチェックが重要な場合に選ばれます。例:API トラフィックを複数サーバーに分散、AZ 間フェイルオーバー、接続量や予測可能なトラフィック挙動が Web サーバ機能より優先されるケース。
性能比較で陥りがちなのは、単一の数値(例:「最大 RPS」)だけを見ることです。ユーザーが体感するのは平均ではなくテール(p95/p99)です。
プロキシはスループットを増やしても、負荷時に過度にキューイングするとテールレイテンシを悪化させることがあります。
アプリの「形」を考えてください:
ベンチマークを特定のパターンで取ってしまうと、別のパターンでの実運用結果は異なります。
バッファリングは、クライアントが遅い場合やバースト時にリクエスト/レスポンスを溜めてアプリに一定の速度で渡せるため助けになることがあります。
一方で ストリーミング を重視するワークロードでは余分なバッファがメモリ圧迫やテールレイテンシの悪化を招くため害になることがあります。
「最大 RPS」以上を計測しましょう:
p95 が急に上がる前にエラーが出ることがあるので、そこが飽和の初期警告です。
Nginx と HAProxy はどちらも複数インスタンスの前に置けますが、ロードバランシング機能の深さや標準機能は異なります。
ラウンドロビンはバックエンドが似ている(同一リソース、同等リクエストコスト)場合に十分に機能します。
**最少接続(least connections)**はリクエストの長さが変動するケース(ファイルダウンロード、長い API、WebSocket)で有効です。\n 重み付きはノードが均一でない場合(古いノードと新しいノードの混在、異なるインスタンスサイズ、段階的なトラフィック移行)に使います。
一般に、HAProxy はより多くのアルゴリズムと細かな制御を提供し、Nginx は一般的なケースをシンプルにカバーします(エディションやモジュールで拡張可)。
スティッキーはユーザーを同じバックエンドに固定します。
レガシーなサーバーサイドセッションがなければ、可能な限りスティッキーを避けるべきです。
アクティブヘルスチェックは定期的にバックエンドをプローブ(HTTP エンドポイント、TCP 接続、期待されるステータス)し、トラフィックが少ない状況でも障害を検出します。
パッシブヘルスチェックは実トラフィックに反応して、タイムアウトや接続エラー、異常なレスポンスでサーバーを不健全と判断します。軽量ですが検出まで時間がかかる場合があります。
HAProxy は 豊富なヘルスチェック制御(閾値、rise/fall カウント、詳細チェック)で知られ、Nginx もビルドやエディションによって堅実なチェック機能を提供します。
ローリングデプロイを行うときは:
どちらの場合も、短めのタイムアウトと明確な readiness ヘルスエンドポイントを組み合わせるとスムーズにトラフィック移行できます。
リバースプロキシはシステムのエッジに立つため、プロトコルや TLS の選択はブラウザ性能からサービス間通信の安全性まで影響します。
Nginx と HAProxy はどちらも TLS を「終端」できます:クライアントからの暗号化接続を受け復号し、アプリへは HTTP や再暗号化された TLS で転送します。
運用上は証明書管理が現実的な課題になります:
Nginx は TLS 終端をウェブサーバ機能と組み合わせることが多く、HAProxy は TLS をトラフィック管理レイヤーの一部として扱う場面が多いです。
HTTP/2 は複数リクエストを一つの接続で多重化することでブラウザのページロードを改善します。両ツールともクライアント向けに HTTP/2 をサポートします。
注意点:
非 HTTP トラフィック(データベース、SMTP、Redis、カスタムプロトコル)をルーティングする必要がある場合は TCP プロキシが必要です。HAProxy は高性能な TCP 負荷分散で広く使われます。Nginx も stream 機能で TCP をプロキシできますが、単純なパススルー用途で十分なことが多いです。
mTLS は双方を検証します:クライアントも証明書を提示します。サービス間通信やパートナー連携、ゼロトラスト設計で有効です。どちらのプロキシもエッジでクライアント証明書検証を強制できますし、内部でも mTLS を使って「信頼されたネットワーク」前提を減らす運用が行われます。
リバースプロキシはすべてのリクエストの中央にいるため、「何が起きたか」を答えるのに最適な場所です。良い可観測性は一貫したログ、少数の高シグナルなメトリクス、タイムアウトやゲートウェイエラーを繰り返しデバッグできるパターンを意味します。
本番では最低でも アクセスログ と エラーログ を有効にしてください。アクセスログにはアップストリームの時間を含め、遅延がプロキシ側かアプリ側かを判断できるようにします。
Nginx では $request_time、$upstream_response_time、$upstream_status のようなフィールドが一般的です。HAProxy では HTTP ログモードとキュー/接続/応答時間を取得して、「バックエンドの待ち時間」と「バックエンド自体の遅さ」を分離します。
ログはできれば構造化(JSON)にし、リクエスト ID(受信ヘッダー由来か生成)を付けてプロキシログとアプリログを相関できるようにしてください。
Prometheus 等に送る場合、次を一貫して出力してください:
Nginx は stub status や Prometheus エクスポーターを使うことが多く、HAProxy はビルトインの stats エンドポイントをエクスポーターが読む形が一般的です。
軽量な /health(プロセスが起動しているか)と /ready(依存先に到達できるか)エンドポイントを公開してください。オートスケールやデプロイ、ロードバランサのチェックに使います。
デバッグ時はプロキシのキュー/接続時間とアップストリーム応答時間を比較してください。キュー/接続が高いなら容量追加や負荷分散調整、アップストリーム時間が高いならアプリ/DB 側の改善に注力します。
リバースプロキシ運用はピーク性能だけでなく、チームが安全に変更を行えるかどうかが重要です。
Nginx の設定はディレクティブベースで階層的です。http → server → location のようなブロック構造はサイトやルートの考え方に合いやすく、習得が比較的直感的です。
HAProxy の設定は frontend(受け入れ)と backend(転送先)を定義し、ACL で接続するパイプライン的なモデルです。一度慣れるとトラフィックルールが明示的で予測可能に感じられます。
Nginx は通常ワーカーを再起動して古いワーカーを優雅にドレインすることで設定をリロードします。証明書更新や頻繁なルート更新に向いています。
HAProxy もシームレスリロードが可能ですが、運用上はより「アプライアンス」的に扱われ、厳格な変更管理やバージョン化された設定の運用、リロードコマンド周りの調整が行われることが多いです。
両者ともリロード前に設定チェックが可能です(CI/CD で必須)。実運用では設定を DRY に保つために生成することが多いです:
運用上の習慣として、プロキシ設定はコードとして扱い、レビュー・テストしてデプロイすることが重要です。
サービス数が増えると証明書やルーティングの散逸が最大の課題になります。対策:
多数のホストがあるなら、手作業編集ではなくサービスメタデータから設定を生成する方が現実的です。
複数のサービスを作り反復する場合、リバースプロキシは配信パイプラインの一部に過ぎません。アプリのスキャフォールディングや環境整合性、安全なロールアウトも必要です。
Koder.ai はチャットベースのワークフローで React アプリ、Go + PostgreSQL バックエンド、Flutter モバイルアプリを生成し、ソースコードのエクスポート、デプロイ/ホスティング、カスタムドメイン、スナップショットとロールバック をサポートします。これにより API + Web フロントエンドを素早くプロトタイプし、実トラフィックに基づいて Nginx か HAProxy かを判断できます。
リバースプロキシはあなたのアプリケーションの前に置かれるプロキシです。クライアントはプロキシに接続し、プロキシが適切なバックエンドサービスにリクエストを転送して応答を返します。
フォワードプロキシはクライアント側に置かれ、クライアントの発信リクエストをインターネット側に転送して制御します(企業ネットワークなどで一般的です)。
ロードバランサーは複数のバックエンドインスタンスへトラフィックを配分することに焦点を当てたコンポーネントです。多くのロードバランサーはリバースプロキシとして実装されるため、用語が重なります。
実務では、Nginx や HAProxy のようなツールを使って「リバースプロキシ + ロードバランシング」を同時に行うことが多いです。
制御ポイントを一箇所にしたい境界に置きます。
クライアントがバックエンドに直接触れないようにして、プロキシがポリシーと可観測性のチョークポイントになるようにするのがポイントです。
TLS 終端はプロキシが HTTPS を処理することを意味します:クライアントからの暗号化接続を受け取り復号し、内部では HTTP(または再暗号化した TLS)でバックエンドに転送します。
運用上は次を計画する必要があります:
あなたのプロキシがウェブの“フロントドア”でもある場合は Nginx が便利です:
HAProxy はトラフィック管理と高負荷下での予測可能性が重要な場合に適しています:
ラウンドロビンは同等バックエンドで均等に配るときの標準選択です。
**最少接続(least connections)**はリクエスト時間がばらつく負荷(ダウンロードや長い API 呼び出しなど)で有効です。\n 重み付きはバックエンドが均一でないとき(混在するインスタンスサイズや段階的マイグレーション)に使います。\n 状況に応じてこれらを選んでください。
セッション継続(スティッキー)はユーザーを同じバックエンドに誘導し続けます。
可能ならステートレス設計にしてスティッキーを避けるのがスケール性と回復性の面で有利です。
バッファリングはクライアントが遅い/バーストする場合にプロキシがリクエスト/レスポンスを平滑化するので役立ちます。
ただし ストリーミング系(SSE、WebSocket、大きなダウンロード) ではバッファが逆効果になり得ます。メモリ圧迫やテールレイテンシの悪化を招くので、その場合はバッファリング設定を明示的に見直してください。
まずプロキシ側の遅延とバックエンド側の遅延を分離して確認します。
よくある意味合い:
有用な指標:キュー時間/接続時間(proxy がバックエンドスロットを待っているか)、アップストリーム応答時間(バックエンドが遅いか)。対処はタイムアウト調整、バックエンド増強、ヘルスチェックや readiness エンドポイントの改善が多いです。