2025年8月07日·1 分
Noam ShazeerとLLMを支えるTransformerアーキテクチャ
Noam Shazeerが共著者の一人であるTransformerとは何か、セルフアテンションやマルチヘッド、位置エンコーディングなどの要素がなぜLLMの基盤になったのかをわかりやすく解説します。
Noam Shazeerが共著者の一人であるTransformerとは何か、セルフアテンションやマルチヘッド、位置エンコーディングなどの要素がなぜLLMの基盤になったのかをわかりやすく解説します。
Transformerは、順序や文脈が重要な系列(文、コード、検索クエリの列など)をコンピュータに理解させるための方法です。従来のように一度に1トークンずつ読み進めて脆弱な記憶を持ち運ぶ代わりに、Transformerは系列全体を見渡して各部分を解釈する際に何に注目すべきかを判断します。
この単純な転換が大きな意味を持ちました。現代の大規模言語モデル(LLM)がコンテキストを保持し、指示に従い、首尾一貫した段落を書き、以前の関数や変数を参照するコードを生成できる主な理由の一つです。
チャットボット、要約機能、意味検索、コーディングアシスタントを使ったことがあるなら、Transformerベースのシステムとやり取りしている可能性が高いです。同じ基本的な設計が支えている例は:
セルフアテンション、マルチヘッドアテンション、位置エンコーディング、基本的なTransformerブロックの仕組みを分解し、この設計がモデルの大型化に伴ってなぜうまくスケールするのかを説明します。
また同じコアアイデアを保持しつつ、高速化やコスト削減、長いコンテキスト対応のために調整された現代的な派生も触れます。
これは高レベルのツアーで、平易な説明と最小限の数式に留めます。目的は直感を養うこと:各パーツが何をするか、なぜ一緒に機能するのか、そしてそれが実際のプロダクト機能にどう結びつくかを理解することです。
Noam Shazeerは、2017年の論文*“Attention Is All You Need”*の共著者の一人として知られるAI研究者/エンジニアです。この論文はTransformerアーキテクチャを紹介し、その後多くの現代的なLLMの基盤になりました。Shazeerの仕事はチーム全体の成果の一部であり、TransformerはGoogleの研究者グループによって生み出されたことに帰属するのが重要です。
Transformer以前は、多くのNLPシステムが逐次的にテキストを処理する再帰モデルに依存していました。Transformerの提案は、アテンションを主要メカニズムとして用いることで、再帰を使わずに系列を効果的にモデル化できることを示しました。
この転換は、訓練の並列化が容易になる(多くのトークンを同時に処理できる)という点で重要であり、モデルやデータセットのスケールアップを実用的にしました。
Shazeerの貢献は他の著者と同様、学術的ベンチマークの枠に留まりませんでした。Transformerは再利用可能なモジュールとなり、コンポーネントを差し替えたり、サイズを変えたり、タスクに合わせてチューニングしたり、後に大規模に事前学習したりすることが可能になりました。
多くのブレイクスルーがこうして広がります:論文が一般的なレシピを提示し、エンジニアが洗練し、企業が実運用化し、最終的に言語機能を作る上でのデフォルト選択肢になるのです。
ShazeerがTransformer論文の主要な共同著者であったと言うのは正確です。しかし、彼を単独の発明者として扱うのは不適切です。影響力は集合的な設計によるものであり、その後コミュニティが上に構築した多くの改良も重要です。
Transformer以前は、多くの系列問題(翻訳、音声、テキスト生成)が再帰ニューラルネットワーク(RNN)やその改良であるLSTM(長短期記憶)によって支配されていました。基本的な考え方は簡単:テキストを一度に1トークンずつ読み、走る“メモリ”(隠れ状態)を保持して次を予測します。
RNNは文を鎖のように処理します。各ステップで現在の単語と前の隠れ状態に基づいて隠れ状態を更新します。LSTMはゲートを導入して何を保持し、忘れ、出力するかを決められるようにし、有用な信号をより長く保持できるようにしました。
実際には逐次メモリにはボトルネックがあります:文が長くなるほど多くの情報を単一の状態に押し込む必要があるからです。LSTMでも、遠く離れた単語からの信号は薄れたり上書きされたりします。
そのため、代名詞と対応する名詞を文のかなり前から結びつけるなどの関係を確実に学ぶのが難しくなっていました。
RNNやLSTMは時間に沿って完全に並列化できないため訓練が遅いという問題もあります。同じ文内ではステップ50がステップ49に依存し、という具合に逐次計算が必要です。
大きなモデルや大量のデータ、迅速な実験を望むとき、この逐次計算は深刻な制約になります。
研究者たちは、学習中に厳密に左から右へ進むことなく単語同士を関連付ける設計を必要としていました—長距離関係を直接モデル化し、現代のハードウェアをより活用できる方法です。この圧力が『Attention Is All You Need』で導入されたアテンション優先のアプローチの舞台を整えました。
アテンションは、モデルが「今この単語を理解するためにどの単語を見ればいいか?」と尋ねる方法です。逐次的に単語を読みメモリに頼る代わりに、必要なときに文の最も関連する部分を覗きに行けます。
役立つメンタルモデルは、文の中で小さな検索エンジンが動いているイメージです。
モデルは現在位置のクエリを作り、全位置のキーと比較して、バリューのブレンドを取り出します。
これらの比較は関連度スコアを生みます:どれだけ関連しているかの粗い信号です。モデルはそれをアテンション重みに変換し、重みの合計が1になるようにします。
ある単語が非常に関連していれば大きな重みを得ますし、複数の単語が重要なら注目は分散します。
「Maria told Jenna that she would call later.」という文を取ると、sheを解釈するために「Maria」や「Jenna」の候補を振り返るべきです。アテンションは文脈に最も合う名前に高い重みを割り当てます。
また「The keys to the cabinet are missing.」では、アテンションは“are”を近い“cabinet”ではなく“keys”と結び付ける手助けをします。これが主な利点です:距離があっても意味を直接結び付けられます。
セルフアテンションは、系列中の各トークンがその同じ系列の他のトークンを見て「今何が重要か」を決められるという考え方です。古い再帰モデルのように厳密に左から右へ処理するのではなく、Transformerは任意の位置から手がかりを集めます。
例えば「I poured the water into the cup because it was empty.」という文では、「it」は“cup”に結び付くべきです。セルフアテンションでは“it”のトークンが“cup”や“empty”に高い重要度を割り当て、無関係な語には低い重みを与えます。
セルフアテンションの後、各トークンはもはや単独ではありません。ほかのトークンからの情報を重み付きで混ぜたコンテキスト対応の表現になります。各トークンがその位置に特化した文全体の要約を作るようなイメージです。
実際には“cup”の表現が“poured”、“water”、“empty”からの信号を内包し、“empty”はそれが何を説明しているかの情報を引き込めます。
各トークンは系列全体に対するアテンションを同時に計算できるため、訓練は逐次的に前のトークンの処理を待つ必要がありません。この並列処理が、Transformerが大規模データで効率的に学習し、巨大なモデルにスケールする主要な理由です。
セルフアテンションは離れた部分を直接結び付けるため、代名詞の照応、段落をまたぐトピックの追跡、以前の詳細に依存する指示の処理などが容易になります。
単一のアテンションは強力ですが、それだけでは一つのカメラアングルで会話を見ているようなものです。文は同時に複数の関係を含むことが多く、誰が何をしたか、代名詞が何を指すか、語調を決める語、全体のトピックなどを同時に追う必要があります。
「The trophy didn’t fit in the suitcase because it was too small」のような文では、文法・意味・現実世界の常識といった複数の手がかりを同時に追う必要があります。一つのアテンションビューは最も近い名詞に注目してしまうかもしれませんが、別のビューは動詞句を使って“it”の参照先を判断するかもしれません。
マルチヘッドアテンションは並列に複数のアテンション計算を実行します。各“ヘッド”は異なるレンズで文を解析するよう奨励され、実際にはヘッドが局所構文、長距離リンク、照応、トピック信号などに特化することがあります。
各ヘッドが出した洞察を単に一つ選ぶのではなく、**連結(concatenate)**してから学習された線形層でメインの埋め込み空間に投影します。複数の部分的なメモをまとめて次の層が使えるきれいな要約にするイメージです。これにより多様な関係を同時に捉えられます。
セルフアテンションは関係性の検出に優れますが、それだけでは「どちらが先か」を知りません。単語をシャッフルすると、そのまま同等に扱ってしまうことがあります。位置エンコーディングは「自分は系列の何番目か」という情報をトークン表現に注入して、この問題を解決します。
基本的な考え方は単純です:各トークンの埋め込みに位置信号を組み合わせてからTransformerブロックに入れます。この位置信号は「1番目」「2番目」のようにトークンにタグを付ける追加特徴とみなせます。
一般的なアプローチには:
位置の選択は長文モデリングに大きく影響します。長い入力ではモデルが言語だけでなく「どこを見ればよいか」を学んでいます。相対や回転スタイルは遠く離れたトークン同士を比較しやすく、コンテキストが増えてもパターンを保ちやすいのに対し、ある種の絶対方式は訓練ウィンドウを超えると性能が劣化しやすいことがあります。
実務では位置エンコーディングは目立たない設計判断ですが、LLMが2,000トークンで鋭く、100,000トークンでも一貫するかどうかを左右することがあります。
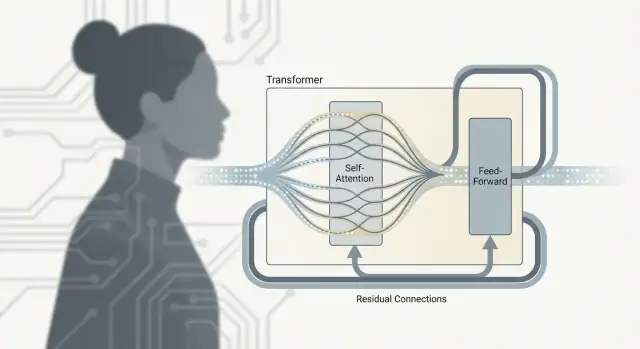
Transformerは単に「アテンション」ではありません。本当の仕事は繰り返し使われる単位(Transformerブロック)の中で起こり、そこではトークン間で情報を混ぜ、その後それを洗練します。多数のブロックを積むことで大規模言語モデルの能力が生まれます。
セルフアテンションは通信ステップです:各トークンが他から文脈を集めます。
フィードフォワードネットワーク(FFN、別名MLP)は思考ステップです:更新された各トークン表現に対して同じ小さなニューラルネットワークを独立に適用します。
平易に言えば、FFNは集めた文脈を変換・整形し、構文パターン、事実、文体などのより豊かな特徴を各トークンに作らせます。
二つの部分は別の仕事をするため交互に置かれます:
このパターンを繰り返すことで、通信→計算→通信→計算、と段階的に高次の意味が構築されます。
各サブレイヤー(アテンションやFFN)は残差接続で包まれます:入力が出力に加えられます。これは深いモデルの訓練を助け、勾配が“スキーレーン”を通って流れるため、個々の層が小さな調整を行いやすくします。
レイヤー正規化は多層を経る間に活性化が大きくなりすぎたり小さくなりすぎたりするのを防ぎます。音量を一定に保つようなもので、後続層が信号であふれたり枯渇したりしないようにし、特にLLM規模での訓練を滑らかにします。
元のTransformerは翻訳のために作られ、入力(フランス語)を別の系列(英語)に変換する仕事は自然に二つの役割に分かれます:入力をよく読むことと出力を流暢に書くこと。
エンコーダ–デコーダでは、エンコーダが入力全体を一度に処理して豊かな表現を作り、デコーダは出力を一トークンずつ生成します。デコーダは自身の過去トークンだけでなくエンコーダ出力へのクロスアテンションも使ってソーステキストに立脚します。
これは翻訳、要約、特定のパッセージに基づく質問応答のように、入力に厳密に条件付けする必要がある場合に非常に有効です。
現代の多くのLLMはデコーダ専用です。彼らは単純で強力なタスク、すなわち次のトークンを予測することを学習します。
そのためにマスクされた(因果的)セルフアテンションを使い、各位置が未来のトークンにアクセスできないようにして左から右への生成が一貫するようにします。
これは大規模テキストコーパスでの訓練が素直で、生成ユースケースに直接一致し、データと計算資源と共に効率的にスケールするため、LLMで主流になりました。
エンコーダのみのTransformer(BERTスタイル)はテキストを双方向に読みますがテキストを生成しません。分類、検索、埋め込みなど、テキストを理解することが主な用途に向いています。
Transformerは与えられたテキストや計算資源、モデルサイズを増やすと比較的予測可能に性能が向上する点で非常にスケールしやすいことが分かりました。
大きな理由は構造の単純さです。Transformerは繰り返し使えるブロック(セルフアテンション+小さなFFN+正規化)で構成され、これらのブロックは百万語でも兆語でも同様に振る舞います。
以前の系列モデル(RNNなど)はトークンを一つずつ処理する必要があり、並列化の余地が限られていました。Transformerは訓練時に系列内のすべてのトークンを並列に処理できるため、GPU/TPUや大規模分散環境と非常に相性が良く、現代のLLM訓練に適しています。
コンテキストウィンドウはモデルが一度に「見られる」テキストの塊です(プロンプトや会話履歴、ドキュメント等)。ウィンドウが大きいほど、より多くの文書や会話履歴、制約を含めて参照でき、以前の詳細に依存する質問に答えやすくなります。
しかしコンテキストは無料ではありません。
セルフアテンションはトークン同士を比較するため、系列が長くなると比較の数は急速に増えます(概ね系列長の二乗に比例)。
そのため非常に長いコンテキストウィンドウはメモリと計算で高コストになり、多くの現代的な努力はアテンションをより効率化することに集中しています。
大規模に訓練されたTransformerは単一の狭いタスクだけで改善するのではなく、要約、翻訳、執筆、コーディング、推論など幅広く柔軟な能力を示し始めます。これは同じ一般的な学習機構が多様な大規模データに適用されるためです。
元のTransformer設計は依然として基準点ですが、多くの実運用LLMは「Transformerプラス」といえる、コアブロック(アテンション+MLP)を保持しつつ速度、安定性、コンテキスト長を改善する小さな実用的修正を加えたものです。
多くの改良はモデルの定義を変えるというより、訓練や実行をより良くするためのものです:
これらは通常モデルの「Transformerらしさ」を変えるものではなく洗練させる変更です。
数千トークンから数万〜数十万トークンへ拡張するには、スパースアテンション(選ばれたトークンだけに注意を向ける)や効率的アテンション変種(近似や再構成で計算を削る)に頼ることが多いです。
トレードオフは通常、精度、メモリ、エンジニアリングの複雑さの組合せになります。
MoEモデルは複数の「専門家」サブネットワークを持ち、各トークンはその一部だけを通るようにルーティングされます。概念的にはより大きな脳を持ちつつ、毎回全部を起動しない、という形です。
これによりパラメータ数に対してトークンあたりの計算を下げられますが、ルーティングや専門家のバランシング、サービングなどシステムの複雑性が増します。
新しいTransformer派生を謳うモデルを見るときは:
ほとんどの改良は実際に効果がありますが、タダではありません。
セルフアテンションやスケーリングのようなTransformerの考え方は魅力的ですが、プロダクトチームにとっては主にトレードオフとして感じられます:どれだけのテキストを入れられるか、どれだけ速く応答が返るか、1リクエストあたりのコストはどれくらいか。
コンテキスト長: 長いコンテキストはより多くのドキュメントや会話履歴、指示を含められますが、トークンコストが増え応答が遅くなる可能性があります。もし機能が「30ページを読んで答える」ならコンテキスト長を優先してください。
レイテンシ: ユーザー向けチャットやコパイロット体験は応答時間が命です。ストリーミング出力は有効ですが、モデル選択、リージョン、バッチ処理も影響します。
コスト: 価格は通常トークン(入力+出力)単位です。10%良いモデルが常に最適とは限らず、コストが2–5倍になることもあります。どの品質が支払う価値があるかを比較してください。
品質: 用途に応じて定義してください:事実性、指示追従、トーン、ツール利用、コードの質など。一般的なベンチマークではなく、実際のドメイン例で評価しましょう。
もし主に検索、重複排除、クラスタリング、推薦、類似検索が目的なら、埋め込み(エンコーダ型モデル)が通常は安価で高速かつ安定しています。生成は最終ステップ(要約、説明、草案作成)にだけ使い、まずは検索で関連部分を取り出すのが賢明です。
詳しい内訳についてはチームに技術説明(例えば /blog/embeddings-vs-generation)を共有してください。
Transformerの能力を製品に落とし込む際、難しいのは多くの場合アーキテクチャ自体よりも周辺のワークフローです:プロンプトの反復、グラウンディング、評価、安全なデプロイなど。
実用的なルートの一つは vibe-coding のようなプラットフォーム(例:Koder.ai)を使ってプロトタイプし、LLMを活用した機能を迅速に出荷することです。チャットでWebアプリ、バックエンドエンドポイント、データモデルを記述し、計画モードで反復し、ソースコードをエクスポートしたりホスティングやカスタムドメイン、スナップショットによるロールバックでデプロイしたりできます。これは特に検索、埋め込み、ツール呼び出しループを試すときに、同じ足場を何度も作り直さずに素早く試行錯誤するのに有用です。
Transformerは、同じ入力内のすべてのトークン同士の関係を扱うためにセルフアテンションを使う、系列データ向けのニューラルネットワークアーキテクチャです。
RNNやLSTMのように情報を一つずつ運ぶ代わりに、入力全体のどこに「注目」すべきかを決めてコンテキストを構築します。これにより長距離の依存関係の理解が向上し、訓練も並列化しやすくなります。
RNNやLSTMはテキストを一度に1トークンずつ処理するため、訓練の並列化が難しく、長距離依存のボトルネックが生じます。
Transformerはアテンションで遠くのトークン同士を直接結びつけ、訓練時に多くのトークン間のやり取りを並列に計算できるため、データと計算量を増やしても拡張しやすくなりました。
アテンションは「このトークンを理解するために、今どのトークンを見ればよいか?」に答える仕組みです。
小さな文内検索のように考えると分かりやすく、
これらを使って関連度に応じた重み付きのブレンドを出力します。
セルフアテンションは、同じ系列内のトークン同士が互いに注目し合うことを指します。
これにより代名詞の参照解決(「it」が何を指すか)や、節をまたぐ主語と動詞の関係など、離れた部分同士の依存関係を単一の再帰的な“メモリ”に通すことなく解決できます。
マルチヘッドアテンションは複数並列でアテンション計算を行い、それぞれが異なるパターンに特化できます。
実務では、あるヘッドが構文的な局所関係に注目し、別のヘッドが長距離の関連付けや代名詞参照に注目するといった使われ方をします。各ヘッドの出力を連結して線形変換することで、多様な関係を同時に表現できます。
セルフアテンションだけでは単語の順序情報が失われかねません—語順をシャッフルしても同じように見える可能性があります。
そこで位置エンコーディングで「私は系列の何番目か」をトークン表現に注入し、例えば「notの直後に来る単語が重要」や「主語は通常動詞より前にある」といった順序に関するパターンを学べるようにします。
一般的な手法にはサイン波の固定方式、学習可能な絶対位置、距離を強調する相対位置や回転(rotary)スタイルの手法があります。
典型的なTransformerブロックは以下を組み合わせます:
これらを何層も積むことで、より高度な特徴や汎用的な振る舞いが得られます。
元の論文でのTransformerはエンコーダ–デコーダ構成でした。
一方、多くの現代LLMはデコーダのみ(次トークン予測)で、因果的(マスクされた)セルフアテンションを用いて左から右へ生成します。エンコーダのみのモデルは主に分類や検索、埋め込み作成で使われます。
Noam Shazeerは2017年の論文「Attention Is All You Need」の共著者の一人で、Transformerの開発における主要な貢献者の一人です。
ただしアーキテクチャ自体はGoogleの研究チームによる共同作業で生まれたものであり、後続の多くの改良や実装によって実運用に適した形になっていきました。従って彼を重要な共同著者として評価するのは正確ですが、単独の発明者とするのは正確ではありません。
標準的なセルフアテンションは系列長の二乗に比例して計算量とメモリが増えるため、長い入力は高コストになります。
実務的な対処法としては:
これらの選択は、遅延、トークン料金、精度などの妥協を伴います。