2025年11月13日·1 分
スケーリングと柔軟性を解決するためにNoSQLデータベースが生まれた経緯
なぜNoSQLデータベースが登場したのかを解説します:ウェブのスケール、柔軟なデータ要件、リレーショナルシステムの限界、主要なモデルとトレードオフ。
なぜNoSQLデータベースが登場したのかを解説します:ウェブのスケール、柔軟なデータ要件、リレーショナルシステムの限界、主要なモデルとトレードオフ。
NoSQLは、多くのチームが自分たちのアプリケーションが必要とするものと、従来のリレーショナルデータベース(SQLデータベース)が最適化されているものとの間に不一致を感じ始めたときに登場しました。SQLが「失敗した」わけではありませんが、ウェブ規模では一部のチームが異なる目標を優先するようになりました。
まず、スケールです。消費者向けの人気アプリはトラフィックの急増、恒常的な書き込み、膨大なユーザー生成データに直面しました。これらのワークロードに対して「より大きなサーバーを買う」ことは高価で導入に時間がかかり、結局管理可能な最大マシンに制約されるようになりました。
次に、変化です。プロダクトの機能は急速に進化し、背後のデータが固定のテーブル群にきれいに収まらないことが増えました。ユーザープロファイルへの属性追加、複数イベントタイプの保存、異なるソースからの半構造化JSONの取り込みは、繰り返しのスキーママイグレーションやチーム間の調整を意味しました。
リレーショナルデータベースは構造の強制や正規化されたテーブルを横断する複雑なクエリに優れています。しかし、高スケールのワークロードではこれらの強みが活かしにくくなることがありました:
結果として、一部のチームは特定の保証や機能を犠牲にして、より単純なスケーリングや早いイテレーションを得られるシステムを求めました。
NoSQLは単一のデータベースや設計ではありません。水平スケーリング(ノードの追加)、柔軟なデータモデル、特定のアプリケーションニーズに調整されたアクセスパターンなどを重視するシステム群をまとめる総称です。
NoSQLは決してSQLの普遍的な置き換えを意図したものではありません。得られるのはスケーラビリティやスキーマの柔軟性であり、その代わりに弱い一貫性の許容、アドホックなクエリの減少、アプリ側でのデータモデリング責任の増加といったトレードオフを受け入れる必要があります。
長年、遅いデータベースに対する標準的な答えはシンプルでした:より大きなサーバーを買う。CPU、RAM、ディスクを増やし、同じスキーマと運用モデルを保つ。この「スケールアップ」アプローチは機能しました—ただし実用上の限界にぶつかるまで。
ハイエンドマシンはすぐに高価になり、価格対性能比はやがて悪化します。アップグレードは大きな、まれな予算承認とデータ移行のためのメンテナンスウィンドウを必要とすることが多い。たとえ高価なハードウェアを買えたとしても、単一サーバーには限界があります:一つのメモリバス、一つのストレージサブシステム、書き込み負荷を受けるプライマリノードが一つです。
プロダクトが成長するにつれて、データベースは断続的なピークではなく常時の読み書きプレッシャーに直面しました。トラフィックは24/7化し、特定の機能が不均一なアクセスパターンを生みました。ごく少数の頻繁にアクセスされる行やパーティションがトラフィックを支配し、ホットテーブル(またはホットキー)となって他を引きずり下ろすことがありました。
運用上のボトルネックは一般的になりました:
多くのアプリは単に一拠点で高速であればよい、というわけではなく複数リージョンでの可用性が必要でした。一つの「メイン」データベースを一地域に置くと、遠隔地のユーザーはレイテンシで不利になり、障害の影響が致命的になります。課題は「より大きな箱をどう買うか」から「データベースを多数のマシンとロケーションでどう運用するか」へと変わりました。
リレーショナルデータベースはデータ形が安定している場合に光ります。しかし多くのモダンプロダクトは留まらず進化します。テーブルスキーマは意図的に厳格で、各行は同じ列・型・制約に従います。その予測可能性は価値があります—しかし迅速に反復する場面では問題になります。
実務では、頻繁なスキーマ変更は高コストです。些細な更新でもマイグレーション、バックフィル、インデックス更新、古いコードパスとの互換性計画を必要とするかもしれません。大規模テーブルではカラム追加や型変更でさえ時間を要する作業になり、運用リスクを伴います。
その摩擦のためにチームは変更を遅らせたり、ワークアラウンドを蓄積したり、テキストフィールドに雑にblobを入れたりします—いずれも迅速なイテレーションには好ましくありません。
多くのアプリデータは自然に半構造化されています:入れ子オブジェクト、オプショナルなフィールド、時間とともに進化する属性。
例えば「ユーザープロファイル」は最初は名前とメールだけだったが、徐々にプリファレンス、連携アカウント、配送先、通知設定、実験用フラグなどが増えていきます。すべてのユーザーがすべてのフィールドを持っているわけではないし、新しいフィールドは段階的に追加されます。ドキュメント型モデルは不均一で入れ子状の形をそのまま保存でき、すべてのレコードを同一テンプレートに押し込む必要がありません。
柔軟性は特定のデータ形で複雑なジョインの必要性も減らします。ある画面が合成オブジェクト(注文とアイテム、配送情報、ステータス履歴)を必要とするとき、リレーショナル設計では複数テーブルとジョインが必要になり、ORM層がその複雑さを隠そうとしますが摩擦を生むことが多いです。
NoSQLの選択肢は、読み書きパターンに近い形でデータをモデル化しやすくし、チームがより早く変更を出せるようにしました。
単にウェブアプリが大きくなっただけでなく、その形が変わりました。予測可能な社内ユーザー数に対して営業時間だけ稼働するシステムではなく、世界中の何百万ものユーザーに24時間サービスを提供し、ローンチやニュース、ソーシャルシェアで突発的なスパイクが発生するようになりました。
常時稼働の期待が高まり、ダウンタイムが見過ごされない問題になりました。同時にチームはより速く機能を出すことを求められ、多くの場合「最終的な」データモデルが何か分からないうちに出荷する必要がありました。
対応のために、単一データベースサーバーをスケールアップするだけでは不十分になりました。扱うトラフィックが多いほど、段階的に容量を増やしたくなります—ノードを追加して負荷を分散し、障害を隔離する。これによりアーキテクチャは一台の「メイン」ボックスではなくマシンのフリートへと向かい、チームがデータベースに期待するものも変わりました:整合性だけでなく高い同時実行時の予測可能なパフォーマンスと、システムの一部が不健全なときでも優雅に振る舞うこと。
“NoSQL”が主流になる前から、多くのチームはウェブスケールの現実に合わせてシステムを曲げていました:
これらの手法は機能しましたが、複雑さをアプリケーションコードに移し、キャッシュの無効化、重複データの整合性保持、「提供準備完了」のレコードを作るパイプライン構築といった負担が増えました。
これらのパターンが標準化するにつれて、データベースはデータをマシン間で配布する、部分的な障害に耐える、高い書き込み量を扱う、進化するデータをきれいに表現する、といったことをサポートする必要が出てきました。NoSQLデータベースは、一般的なウェブスケール戦略をファーストクラス化することで、回避策を常に手作業でやる必要を減らしました。
データが一台のマシンにあるとき、ルールは単純に感じられます:単一の真実があり、すべての読み書きは即座にチェックできます。しかしデータをサーバ間(多くはリージョン間)に広げると、メッセージの遅延、ノード障害、システムの一部が一時的に通信を停止する、といった現実が現れます。
分散データベースは調整ができないときにどう振る舞うかを決めなければなりません。アプリを「稼働」させ続けるためにリクエストを返し続け(結果は少し古くなるかもしれない)、あるいはレプリカが合意するまでいくつかの操作を拒否して(ユーザーからはダウンタイムに見える)正しさを保つか。
これらはルータ障害、過負荷なネットワーク、ローリングデプロイ、ファイアウォールの誤設定、クロスリージョンのレプリケーション遅延時に発生します。
CAP定理は同時に望ましい三つの性質の略語です:
重要なのは「いつも二つを選べ、ということではなくネットワーク分断が起きたときに一貫性と可用性のどちらを選ぶかを決めなければならない」という点です。ウェブ規模のシステムでは分断は避けられないと考えるのが普通です。
アプリが二つのリージョンで動いていると想像してください。光ファイバーの切断やルーティングの問題で同期できなくなります。\n
さまざまなNoSQLシステム(あるいは同一システムの異なる設定)は、ユーザー体験の障害時の振る舞い、正確性の保証、運用の単純さ、回復時の挙動など、何を重視するかで異なる妥協を行います。
スケールアウト(水平スケーリング)とは、より大きなサーバーを買うのではなく、より多くのマシン(ノード)を追加してキャパシティを増やすことです。多くのチームにとって、これは金銭的・運用上の転換でした:安価なノードを段階的に追加でき、障害は想定され、成長はリスクの高い“大きな箱”の移行を必要としませんでした。
多数のノードを有効活用するには、NoSQLシステムはシャーディング(パーティショニング)に頼ります。全データを一台が扱うのではなく、データをパーティションに分けてノードに配布します。
単純な例としてキー(user_id)でパーティションする場合:
読み書きが分散してホットスポットを減らし、ノードを追加することでスループットを増やせます。パーティションキーは設計上の決定で、クエリパターンに合わせて選ばないと一つのシャードに過度に負荷が集中します。
レプリケーションは同じデータの複数コピーを異なるノードで保持することです。これにより:
レプリケーションはラックやリージョンにまたがってデータを広げられるため局所障害に耐えられます。
シャーディングとレプリケーションは継続的な運用作業を招きます。データが増えたりノードが変わったりすると、システムはリバランス(パーティションの移動)を行う必要があります。これがうまく扱われないと遅延スパイクや負荷の偏り、一時的な容量不足を引き起こします。
これは核心的なトレードオフです:安価なスケーリング(多数ノード)を得る代わりに、分散、監視、障害処理の複雑さが増します。
データを分散すると、同時更新、ネットワーク遅延、ノード間の通信断などが発生する際に「正しい」とは何かを定義する必要があります。
強い一貫性では、一度書き込みが確認されると全てのリーダーが直ちにそれを見るべきです。これは多くの人がリレーショナルデータベースに期待する「単一の真実」に近い挙動です。
課題は調整です:ノード間で厳密な保証を提供するには複数メッセージのやり取り、十分な応答を待つこと、途中での失敗処理が必要になります。ノードが離れていたり負荷が高いほど、書き込みごとにレイテンシが増す可能性があります。
最終一貫性はその保証を緩めます:書き込み後に異なるノードが一時的に異なる答えを返すことがあり得ますが、時間が経てばシステムは収束します。
例:
多くのユーザー体験では、この一時的な不一致は許容可能で、システムが高速かつ可用であることを重視します。
二つのレプリカがほぼ同時に更新を受け入れると競合が生じます。データベースはマージルールを持つ必要があります。
一般的な手法:
金銭取引、在庫の上限、ユニークユーザー名、権限周りなど、「一瞬の二つの真実」が実害を生む領域では強い一貫性が価値に見合うことが多いです。
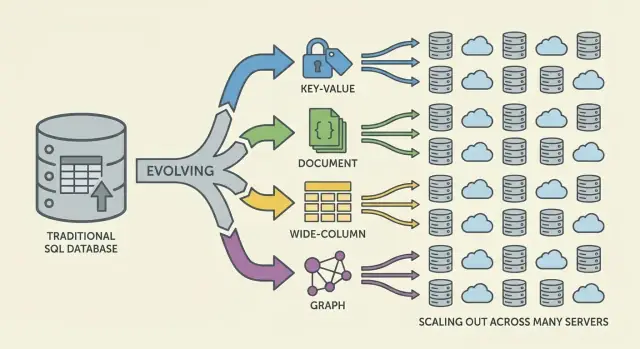
NoSQLはスケール、レイテンシ、データ形に関するさまざまなトレードオフをするモデル群です。ファミリーを理解すると何が速くて何がつらいかを予測しやすくなります。
キー・バリューは値をユニークなキーに紐づけて保存する、巨大な分散ハッシュマップのようなものです。アクセスパターンが通常「キーで取得/キーで設定」なので非常に高速かつ水平スケーラブルになり得ます。
セッション、キャッシュ、フィーチャーフラグなどIDが既に分かっているケースに最適ですが、複数フィールドでのフィルタやアドホッククエリには向きません。
ドキュメントデータベースはコレクションにグループ化されたJSONライクなドキュメントを保存します。各ドキュメントは若干異なる構造を持てるため、プロダクトの進化に伴うスキーマの柔軟性をサポートします。
ドキュメント全体の読み書きや内部フィールドでのクエリに最適化されていますが、リレーションのモデリングは難しくなりがちで、ジョインが限定される(あるいはサポートされない)ことがあります。
ワイドカラムデータベース(Bigtableに触発された)は、行キーごとに多数のカラムがあり、行ごとにカラムが異なり得る構造を持ちます。膨大な書き込みレートと分散ストレージに強く、時系列やイベント、ログワークロードに向きます。
効率的にクエリするにはプライマリキーやクラスタリングルールに基づいた慎重な設計が求められ、任意のフィルタでの検索には向かないことが多いです。
グラフデータベースは関係(エッジ)をファーストクラスのデータとして扱います。テーブルを何度もジョインする代わりにエッジをたどるクエリが自然かつ高速に実行できます(不正検知、推薦、依存関係の解析など)。
リレーショナルは正規化を促します:データを多くのテーブルに分け、クエリ時にジョインで再構成します。多くのNoSQLシステムは最も重要なアクセスパターンに合わせて設計することを求め、しばしば重複を代償にしてレイテンシを予測可能に保ちます。
分散データベースではジョインが複数パーティションやマシンからデータを引く必要があり、ネットワーク往復や調整、予測不能な遅延を招きます。デノーマライズ(関連データを一緒に保存)するとラウンドトリップを減らし、読み取りを「ローカル」に保つことが増えます。
実用上の結果として、orders レコード内に同じ顧客名を保存することがあり得ます。これは「最新20件の注文」をコアクエリとして高速化するためです。
多くのNoSQLは限定的なジョインしかサポートしない(または全くしない)ため、アプリケーションがより多くの責任を負います:
このためNoSQLのモデリングはしばしば「我々はどの画面をロードする必要があるか?」と「高速にしなければならないトップクエリは何か?」から始まります。
セカンダリインデックスは新しいクエリ(例:「メールでユーザーを見つける」)を可能にしますが、無料ではありません。分散システムでは各書き込みが複数のインデックス構造を更新する可能性があり、次のようなコストが発生します:
user_profile_summary レコードを保つNoSQLは「すべてにおいて優れている」から採用されたわけではありません。ウェブスケールのプレッシャー下でチームがある種の利便性を犠牲にしてまでスピード、スケール、柔軟性を得られると判断したからです。
設計としてのスケールアウト。 多くのNoSQLはマシンを追加する実務を現実的にし、シャーディングやレプリケーションがコア機能になりました。
スキーマの柔軟性。 ドキュメントやキー・バリューのシステムは、フィールド変更を厳格なテーブル定義に通さずにアプリを進化させられることが多く、週単位で要件が変わる場合の摩擦を減らしました。
高可用性パターン。 ノードやリージョンにわたる複製により、ハードウェア障害やメンテナンス中のサービス継続が容易になりました。
データの複製とデノーマライズ。 ジョインを避けるためにデータを重複させると、読み取り性能は向上しますがストレージが増え、更新をあちこちで行う複雑さが生まれます。
一貫性の驚き。 最終一貫性は多くの場合許容できますが、許容できない場面ではユーザーが古いデータを見たりエッジケースで混乱したりします。アプリ側で不整合を扱う設計が必要です。
分析が難しくなることがある。 一部のNoSQLストアは運用読み書きに優れますが、アドホックなクエリや複雑な集計はSQL優先のシステムより扱いにくいことがあります。
初期のNoSQL導入はデータベース機能からエンジニアリングの規律へと努力をシフトさせることが多かった:レプリケーション監視、パーティション管理、コンパクションの運用、バックアップ/リストア計画、障害シナリオのロードテストなど。運用成熟度の高いチームが恩恵を受けやすい分野です。
ワークロードの現実に基づいて選ぶべきです:期待するレイテンシ、ピークスループット、主要なクエリパターン、古い読み取りに対する許容度、復旧要件(RPO/RTO)。「正しい」NoSQLの選択は機能リストではなく、アプリケーションがどう失敗し、どうスケールし、どう問い合わせられるかに合うものです。
NoSQLの選択はブランドや流行から始めるべきではなく、アプリケーションの要件、成長の仕方、ユーザーにとっての「正しさ」が何を意味するかから始めるべきです。
データストアを選ぶ前に次を明確にしてください:
アクセスパターンが明確でないなら、どの選択も当てずっぽうになりがちです—特にNoSQLはモデリングが読み書きパターンに強く影響されます。
実用的なシグナル:コアの真実(注文、決済、在庫)が常に正確である必要があるなら、それはSQLや他の強一貫性ストアに置くべきです。一方で高スループットのコンテンツ、セッション、キャッシュ、アクティビティフィード、柔軟なユーザー生成データにはNoSQLが適することが多いです。
多くのチームは複数のストアを用途に応じて使い分けて成功しています:例として、トランザクションはSQL、プロファイルやコンテンツはドキュメント、セッションはキー・バリューといった具合です。目的は複雑化そのものではなく、各ワークロードをきれいに扱うツールを当てることです。
開発ワークフローも重要です。アーキテクチャ(SQL vs NoSQL vs ハイブリッド)を実験しているなら、API、データモデル、UIのワーキングプロトタイプを素早く立ち上げられるとリスクが下がります。Koder.ai のようなプラットフォームはチャットからフルスタックアプリを生成して、ReactフロントエンドとGo + PostgreSQLバックエンドの雛形を用意するなど、実験を安全に高速に行う手段を提供します。後から特定ワークロードにNoSQLを導入しても、強いSQLの“真実の系”を保ちつつプロトタイピングやスナップショット、ロールバックができると実験がより安全になります。
どの選択をしても、実証してください:
これらをテストできないなら、データベース選択は理論上のままで、本番環境が実際のテストを代行することになります。
NoSQLは主に二つのプレッシャーに応えるために登場しました:
SQLが「悪い」わけではなく、異なるワークロードが異なるトレードオフを優先するようになった、というのが要点です。
従来の「スケールアップ」アプローチには実用的な限界がありました:
NoSQLは「より大きな箱を買う」代わりにノードを追加するスケールアウトを重視しました。
リレーショナルスキーマは安定時には優れていますが、頻繁な変更にはコストがかかります。大きなテーブルでは「単純な」変更でも:
ドキュメント型のモデルは、オプションのフィールドや入れ子構造を許容することでこの摩擦を減らします。
必ずしもそうではありません。多くのSQLデータベースはスケールアウト可能ですが、運用面で複雑さ(シャーディング、シャード間結合、分散トランザクションなど)が増します。
NoSQLは分割(パーティショニング)や複製を最初から組み込み、特定のアクセスパターンに対して予測可能に動くよう最適化していることが多い、という点が違いです。
分散データベースでは結合が複数パーティションやマシンをまたぐ可能性があり、ネットワーク往復や調整が増えるため、遅延が不安定になります。そこでデータを読みやすい形で一緒に保存する(デノーマライズ)ことが一般的です。
例:orders レコード内に顧客名を保持して「最新20件の注文」を単一の高速読み取りで返せるようにする。
代償は「更新の複雑さ」で、アプリ側やパイプラインで一貫性を保つ必要があります。
分散環境でネットワーク分断が起きたとき、データベースはどう振る舞うかを決めなければなりません:
CAPは「分断が起きたとき、一貫性と可用性のどちらを選ぶか」を示す指針です。
強い一貫性は、書き込みが確認されたら全てのリーダーが直ちにその書き込みを見ることを保証します。分散ではこれが高い調整コスト(複数メッセージや待ち時間)を招きます。
最終一貫性は書き込み後に一時的にレプリカ間で差異が生じる可能性を許容し、時間が経てば収束するというモデルです。フィードやカウンターなど、短時間の不整合が許容されるケースで有効です。
競合は、異なるレプリカがほぼ同時に更新を受け入れたときに発生します。一般的な解決法には:
どの方式を選ぶかは、そのデータで中間の更新を失っても問題ないか次第です。
簡単な選び方ガイド:
支配的なアクセスパターンに合わせて選ぶのが正解です。
まず要件から始め、テストで検証します:
多くの実運用システムはハイブリッドです:決済や在庫などはSQLに置き、高頻度のコンテンツやセッション、プロファイルなどはNoSQLを使う、といった分担が有効です。