2025年12月13日·1 分
グラフィックス・スタートアップからAIの巨人へ:Nvidiaの歴史
1993年のグラフィックス・スタートアップから世界的なAI大手へ成長したNvidiaの歩みを、主要製品、ブレークスルー、リーダー、戦略的判断をたどって解説します。
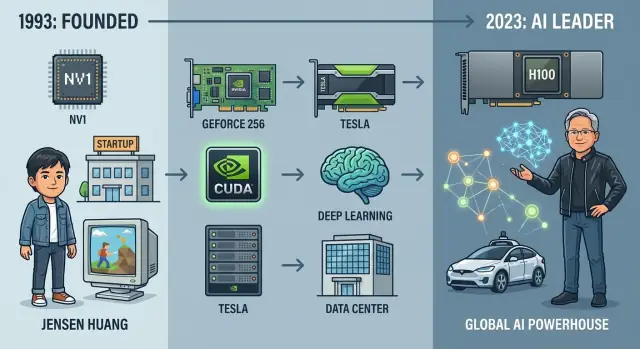
1993年のグラフィックス・スタートアップから世界的なAI大手へ成長したNvidiaの歩みを、主要製品、ブレークスルー、リーダー、戦略的判断をたどって解説します。
Nvidiaは、尋ねる人によって全く異なる理由で知られる名前になりました。PCゲーマーにとってはGeForceグラフィックスカードと滑らかなフレームレート。AI研究者にとっては、数か月ではなく数日で最先端モデルを学習させるGPU。投資家にとっては、AIブームの代理として扱われた史上有数の半導体企業の一つです。
しかしこれは必然ではありませんでした。1993年にNvidiaが創業したとき、それはニッチなアイデアに賭ける小さなスタートアップにすぎませんでした:グラフィックスチップがパーソナルコンピューティングを変えるという賭けです。30年以上で、同社はスクラップから始まったグラフィックスカードメーカーから、推奨システムや自動運転試作機、巨大な言語モデルまでを支える現代AIの中央的サプライヤーへと進化しました。
Nvidiaの歴史を理解することは、現代のAIハードウェアとそれを取り巻くビジネスモデルを理解する最も明確な方法の一つです。同社は次の複数の力の交差点に位置しています:
その過程でNvidiaは何度もハイリスクの賭けをしました:市場が明確でないうちにプログラム可能なGPUに賭け、深層学習のためのフルソフトウェアスタックを構築し、Mellanoxのような買収に何十億ドルも投じてデータセンターをより多く支配しようとしました。
この記事は1993年から今日までのNvidiaの歩みを追い、以下に焦点を当てます:
読者はテクノロジー、ビジネス、投資に興味がある人を想定しており、NvidiaがどのようにAIの巨人になったか、その先に何があり得るかを物語的に整理して説明します。
1993年、性格の異なる3人のエンジニアがシリコンバレーのDenny’sのテーブルを囲んでNvidiaを立ち上げました。ジェンセン・ファン(台湾系米国人のエンジニアでLSI Logic出身)は大きな野心と顧客・投資家に物語を語る才能を持ち込みました。クリス・マラホフスキーはSun Microsystems出身で高性能ワークステーションの経験が深く、カーティス・プリームはIBMやSun出身でハードとソフトの結合を設計するシステムアーキテクトでした。
当時のバレーはワークステーション、ミニコン、そして台頭するPCメーカーが中心でした。3Dグラフィックスは強力でしたが高価で、主にSGIのようなワークステーションベンダーがCAD、映画、科学可視化向けに提供していました。
創業者たちはここに隙間を見ました:その種のビジュアルコンピューティングをより安価なコンシューマPCに押し広げれば、市場はワークステーションのニッチよりはるかに大きくなるはずだと。
Nvidiaの創業アイデアは汎用半導体ではなく、マスマーケット向けのアクセラレーテッドグラフィックスでした。CPUがすべてを担当するのではなく、専用のグラフィックスプロセッサが3Dシーンの重い数学処理を担当するという考えです。
チームはこれに必要なこととして:
ジェンセンはSequoiaなどのベンチャーから初期資金を集めましたが、資金は豊富ではありませんでした。最初のチップNV1は野心的でしたが、当時主流になりつつあったDirectX標準と噛み合わず、販売は低迷し会社を危機に追い込みました。
NvidiaはNV3(RIVA 128)へ素早くピボットし、業界標準に合わせたアーキテクチャへ再設計してゲーム開発者やMicrosoftと緊密に連携することを学び、生き残りました。技術だけでは足りず、エコシステムの整合性が生死を分けるという教訓を得たのです。
創業当初からNvidiaはエンジニアの発言力が強く、タイム・トゥ・マーケットを存亡に関わるものとする文化を育みました。チームは高速に動き、設計を積極的に反復し、失敗する賭けも受け入れました。
資金制約は倹約を生み、オフィス家具の使い回し、長時間労働、少数の高能力エンジニアを採る方針などが定着しました。この初期文化—技術的深度、緊急性、慎重な支出—が後にPCグラフィックスを超えた大きな機会に取り組む際の強みとなりました。
1990年代中盤、PCグラフィックスは未成熟で断片化していました。多くのゲームはソフトウェアレンダリングに頼り、CPUが大部分の仕事をしていました。2Dアクセラレータや初期の3Dカード(3dfxのVoodooなど)は存在しましたが、3Dハードをプログラムする標準的な方法はありませんでした。Direct3DやOpenGLはまだ発展途上で、開発者は特定カード向けに最適化する必要がありました。
この混沌とした市場にNvidiaは参入しました。性能とプログラミングモデルをうまく組み合わせられる企業には大きな機会がありました。
1995年のNV1は2D、3D、オーディオ、さらにはセガサターンのゲームパッドサポートまで1枚でこなすという製品でした。技術的には二次曲面(quadratic surfaces)に注力し、業界が三角形ポリゴンで標準化していく流れと噛み合いませんでした。
DirectXとの不整合と限られたソフトウェアサポートで商業的には失敗しましたが、Nvidiaは重要な教訓を得ました:支配的なAPIに従い、3D性能に集中せよ。
Nvidiaは1997年のRIVA 128で立て直しました。三角形ベースとDirect3Dを受け入れ、高い3D性能を提供し、2Dと3Dを統合したカードを出しました。レビューで注目され、OEMがNvidiaを真剣なパートナーとして見るようになりました。
RIVA TNTとTNT2は画質、解像度、ドライバ改善で洗練されました。3dfxがまだ市場での認知を握っていましたが、Nvidiaは頻繁なドライバ更新とゲーム開発者への働きかけで差を縮めていきました。
1999年、NvidiaはGeForce 256を発表し「世界初のGPU(Graphics Processing Unit)」と称しました。これは単なるマーケティングではありません。GeForce 256はハードウェアによる変換とライティング(T&L)を統合し、ジオメトリ計算をCPUからGPUへオフロードしました。
この変化によりCPUはゲームロジックや物理演算に専念でき、GPUはより複雑な3Dシーンを処理できるようになりました。ゲームはより多くのポリゴン、より現実的なライティング、高解像度でスムーズに動作しました。
同時期にQuake IIIやUnreal TournamentのようなタイトルとWindows/DirectXの普及によってPCゲームは爆発的に成長しました。Nvidiaはこの成長に緊密に合わせ、DellやCompaqなどの主要OEMと設計採用を確保しました。これにより何百万台ものPCに標準でNvidiaが搭載されるようになりました。
「The Way It’s Meant to Be Played」といった共同マーケティングは、真剣なPCゲーマーのデフォルト選択としての位置づけを強化しました。
2000年代初頭までにNvidiaは最初の失敗から立ち直り、PCグラフィックスで支配的な地位を築き、後のGPUコンピューティング、ひいてはAI時代の土台を作りました。
創業時のGPUはほとんど固定機能のマシンでした。頂点とテクスチャを入力してピクセルを出力するハードワイヤードなパイプラインで、高速ながら柔軟性はほとんどありませんでした。
2000年代初頭、頂点シェーダやピクセル(フラグメント)シェーダといったプログラマブルシェーダが現れ、状況は変わりました。GeForce 3やその後の世代で、開発者がカスタム効果を書くための小さなプログラム単位がGPU上で動くようになったのです。
これらはまだグラフィックス向けでしたが、重要な考えが生まれました:GPUが様々な視覚効果にプログラム可能なら、より広い計算用途にもプログラムできるのではないかと。
GPGPU(General‑Purpose GPU computing)は当時際立って反主流の賭けでした。社内でも、トランジスタ予算やエンジニアリング時間、ソフトウェア努力をグラフィックス以外の用途に振るのは妥当かという疑問がありました。初期のGPGPU実験はフラグメントシェーダを流用するなどして苦労を伴いました。
Nvidiaの回答は2006年発表のCUDAでした:C/C++ライクなプログラミングモデル、ランタイム、ツールチェーンで、GPUを大規模並列コプロセッサとして使えるようにしました。三角形やピクセルではなく、スレッド、ブロック、グリッド、明示的なメモリ階層を公開したのです。
これは戦略的に大きなリスクで、コンパイラ、デバッガ、ライブラリ、ドキュメント、トレーニングなどプラットフォーム企業が行うようなソフトウェア投資が必要でした。
最初の採用は**高性能計算(HPC)**分野から来ました:
研究者は数週間かかっていたシミュレーションを数日あるいは数時間で実行できるようになり、場合によってはワークステーション一台でCPUクラスターの代替となりました。
CUDAは単にコードを高速化しただけでなく、Nvidiaハードウェアを中心とした開発者エコシステムを生みました。NvidiaはSDK、数学ライブラリ(cuBLAS、cuFFTなど)、大学プログラム、そして教育のためのカンファレンス(GTC)に投資しました。
CUDAに最適化されたアプリやライブラリが増えるほど、Nvidiaの“堀(moat)”は深まり、開発者はNvidiaをデフォルトのアクセラレータとして採用するようになりました。
2000年代中盤、Nvidiaのゲーミング事業は好調でしたが、ジェンセンらはコンシューマGPUに依存する限界を見ていました。同じ並列処理力は科学シミュレーションや金融、そして最終的にはAIも加速できるはずだと判断したのです。
NvidiaはGPUをワークステーションやサーバの汎用アクセラレータとして位置づけ始めました。プロ向けのQuadroシリーズは初期の一歩でしたが、本当の賭けはデータセンターへ直接進出することでした。
2007年、NvidiaはTesla製品ラインを導入しました。これはディスプレイ用途ではなく、HPCやサーバワークロード向けに設計されたGPUです。
Tesla ボードは倍精度性能、エラー訂正メモリ(ECC)、および高密度ラックでの電力効率を重視しました。これらはゲームフレームレートよりもデータセンターやスーパーコンピューティングサイトが求める特性です。
Oak Ridge国立研究所の「Titan」スーパーコンピュータのようなシステムは、CUDA対応GPUのクラスタが物理、気候モデル、分子動力学で大幅な高速化を実現できることを示しました。HPCでの信頼性は、後に企業やクラウド事業者を説得する際に重要な役割を果たしました。
Nvidiaは大学や研究機関との関係に多額を投じ、ハードウェアとCUDAツールを提供して種を撒きました。そこから生まれた研究者たちがのちに企業やスタートアップでGPU採用を推進しました。
同時にクラウドプロバイダがNvidia搭載インスタンスを提供し始め、GPUはクレジットカード一つで借りられるオンデマンド資源になりました。これは深層学習の普及に不可欠でした。
データセンターとプロフェッショナル市場の成長により、Nvidiaの収益基盤は広がり、ゲーム以外の第2の成長エンジンが育ち、後のAI支配の土台が形成されました。
転機は2012年、AlexNetというニューラルネットワークがImageNetで圧倒的な成果を示したときに訪れました。重要なのは、このネットワークが2台のNvidia GPU上で動いていたことです。巨大なニューラルネットをグラフィックスチップで学習させるというニッチな試みが、AIの未来に見え始めました。
深層ニューラルネットワークは数百万の重みと活性化に対して同一の演算(行列積や畳み込み)を大量に行います。GPUは何千もの単純な並列スレッドを回すために設計されており、この並列性はニューラルネットにほとんど完璧に適合しました。
ピクセルを描く代わりにニューロンを処理でき、CPUでは遅延する計算がGPUで数桁高速化され、何週間かかっていた学習が数日や数時間に短縮され、研究者は反復とスケールアップが容易になりました。
Nvidiaはこの研究の興味をプラットフォームに変えるために迅速に動きました。CUDAは既にGPUをプログラムする手段を与えていましたが、深層学習にはより高水準のツールが必要でした。
NvidiaはcuDNNというニューラルネット用最適化ライブラリを構築し、畳み込み、プーリング、活性化関数などのプリミティブを高速化しました。Caffe、Theano、Torch、そして後のTensorFlowやPyTorchはcuDNNを統合し、研究者が低レベルのチューニングなしにGPUの加速を得られるようになりました。
同時にNvidiaはハードの調整を続けました:混合精度サポートの追加、高帯域幅メモリ(HBM)、そしてVolta世代以降のTensor Coreなど、深層学習向けに特化した機能を導入しました。
Nvidiaはトロント大学やスタンフォード、Google、Facebook、DeepMindのような研究機関と緊密に連携しました。早期ハード提供やエンジニアリング支援を行い、AIワークロードが何を必要とするか直接学び取りました。
AIスーパーコンピューティングを利用しやすくするため、NvidiaはDGXシステムを導入しました。高性能GPU、速いインターコネクト、チューニング済みソフトを詰め込んだ事前統合型のAIサーバで、多くの研究所や企業が採用しました。
Tesla K80、P100、V100、そしてA100やH100といったGPUで、Nvidiaは単なる“ゲーム会社が計算もやる”存在から、最先端深層学習モデルの学習と提供を担うデフォルトエンジンへと変わっていきました。
NvidiaがAIで勝ったのは単に速いチップを売ったからではなく、ハード上でAIを構築・デプロイ・スケールしやすくするエンドツーエンドのプラットフォームを作ったからです。
基盤は2006年に導入されたCUDAです。CUDAはGPUを汎用アクセラレータとして扱えるようにし、C/C++やその上のPythonエコシステムを通じて扱えます。
CUDAの上には専門ライブラリとSDKが重なります:
このスタックにより、研究者やエンジニアは低レベルのGPUコードを書かなくても、Nvidiaの最適化ライブラリを呼び出すだけで性能を得られるようになりました。
CUDAツール、ドキュメント、トレーニングへの長年の投資は強力な堀を生みました。何百万行もの本番コード、学術プロジェクト、オープンソースフレームワークがNvidia GPU向けに最適化されているため、別アーキテクチャへ移行する際にはカーネルの書き換え、モデルの再検証、エンジニア再教育といったコストが発生します。
このスイッチングコストが開発者企業をNvidiaに縛り付ける大きな要因です。
Nvidiaはハイパースケールクラウドと緊密に協働し、HGXやDGXのリファレンスプラットフォーム、ドライバ、チューニング済みソフトを提供して顧客が短時間でGPUインスタンスを利用できるようにしました。
Nvidia AI Enterpriseスイート、NGCソフトカタログ、事前学習モデルは、オンプレミスでもクラウドでも企業がパイロットから本番へ移行するための道筋を提供します。
Nvidiaは垂直分野向けのソリューションも提供しています:
これらはGPU、SDK、リファレンスアプリ、パートナー統合を束ね、ほぼターンキーに近いソリューションを提供します。
ISV、クラウド、研究機関、SIなどをCUDA中心に育てることで、NvidiaはGPUをAIのデフォルトハードへと押し上げました。新たなフレームワークやスタートアップがCUDA最適化を行うたびに、より多くのユーザーを呼び込み、さらなる投資を正当化し、競合との差を広げる正のフィードバックループが働きます。
NvidiaのAI支配はGPUだけでなく、GPUを取り巻く戦略的賭けによっても支えられています。
2019年のMellanox買収は転換点でした。MellanoxはInfiniBandや高性能Ethernet、低レイテンシ・高スループットなインターコネクトの専門性を持っていました。
大規模なAIモデルのトレーニングは何千ものGPUを単一の論理コンピュータとして接続する必要があります。高速なネットワーキングがなければGPUはデータ待ちで遊んでしまいます。InfiniBand、RDMA、NVLink、NVSwitchのような技術は通信オーバーヘッドを減らし、大規模クラスタを効率的に拡張できるようにします。MellanoxによりNvidiaはそのファブリックを自前で整備できるようになりました。
2020年、NvidiaはArm買収を発表しました。目的は、広くライセンスされるCPUアーキテクチャとAIアクセラレーションを組み合わせ、モバイルや組込み、サーバへと影響力を広げることでした。
しかし米英EU中国の規制当局は反トラスト上の懸念を示し、Armが多くの競合に中立的にIPを供給する存在である点が問題視されました。長期の審査と反対によりNvidiaは2022年に買収を断念しました。それでもNvidiaは独自のGrace CPUを進め、ノード全体を形作る意図を示しました。
OmniverseはNvidiaをシミュレーションやデジタルツイン、3Dコラボレーションの領域へ拡張します。OpenUSDを中心にツールとデータをつなぎ、企業が工場や都市、ロボットを実運用前にシミュレートできるようにします。Omniverseは大きなGPU負荷を生むと同時に、開発者を囲い込むソフトウェアプラットフォームでもあります。
自動車分野ではDriveが中央集約型車載コンピューティング、自動運転、ADASを狙います。ハード、SDK、検証ツールを自動車メーカーやティア1向けに提供することで、長い製品サイクルと繰り返し収益を狙います。
エッジではJetsonがロボットやスマートカメラ、産業AIを支え、クラウドだけでは賄えない低レイテンシ推論を現場で提供します。
MellanoxやArm買収の試み、Omniverseや自動車・エッジへの拡大を通じ、Nvidiaは単なる「GPUベンダー」以上の存在へと変わりました。現在同社は:
これにより競合は単にチップを作るだけでなく、コンピュート、ネットワーク、ソフトウェア、領域特化ソリューションまでマッチさせる必要が生じ、Nvidiaは置き換えにくい存在になっています。
Nvidiaの台頭は強力な競合、厳しい規制、地政学的リスクを招き、戦略のあらゆる側面に影響を与えています。
AMDは依然として最も近い競合で、ゲーミングとデータセンターアクセラレータで直接対決します。AMDのMIシリーズはNvidiaのH100などをターゲットにしています。
Intelはサーバー向けのx86での優位、独自のディスクリートGPU、専用AIアクセラレータという複数の角度から攻めてきます。加えてGoogle(TPU)、Amazon(Trainium/Inferentia)、GraphcoreやCerebrasのようなスタートアップも独自チップで依存度を下げようとしています。
Nvidiaの防御は性能優位とソフトウェア(CUDA、cuDNN、TensorRT)によるロックインです。ただしハードだけでは十分でなく、移行コストが勝敗を分けます。
各国政府は先端GPUを戦略的資産として扱います。米国の輸出管理は高性能AIチップの中国向け出荷を制限し、Nvidiaは性能を落とした輸出適合版を出す必要があります。これにより大きな市場へのアクセスが制約され、高マージン需要の一部を失うリスクがあります。
規制当局はNvidiaの市場力にも注目しており、Arm買収の阻止が示すように統合や排他性に関する懸念は強いです。
Nvidiaはファブレス企業で、最先端プロセスはTSMCに大きく依存しています。台湾での自然災害や政治的緊張は供給能力に直接影響を与えます。
さらに先端パッケージ(CoWoSやHBM統合)の能力不足は供給ボトルネックを生み、需要急増に対応する柔軟性を低下させます。こうした条件下で技術リードを維持することは、エンジニアリングだけでなく地政学的・政策的な調整力も要求されます。
ジェンセンは創業CEOとしてハンズオンなエンジニアのように振る舞います。製品戦略に深く関わり、技術レビューやホワイトボードセッションに時間を割きます。
彼の公開プレゼンはショーマンシップと明快さを兼ね備え、レザージャケットのプレゼンは意図的に用いられるメタファーです。社内では直接的なフィードバックと高い期待、そして技術や市場の変化に対して不快でも決断する姿勢で知られています。
Nvidiaの文化は幾つかのテーマで構成されています:
この文化は長いリードタイムのハード設計と短いサイクルのソフト開発が共存し、ハード・ソフト・研究グループが密に協業することを要求します。
Nvidiaは数年先を見据えたプラットフォーム(新GPUアーキテクチャ、インターコネクト、CUDA等)に投資し続けつつ、四半期ごとの業績も管理します。
Nvidiaは開発者を主要顧客と見做し、CUDA、cuDNN、TensorRTなどに対して充実したドキュメント、サンプルコード、主要ラボやクラウド事業者への直接サポートを提供します。スタートアップ支援プログラムやリファレンス設計、共同マーケティングによりOEMやSIとの関係も強化しています。
成長につれて文化は変化しました:
それでも創業者主導の技術優先の文化を維持し、野心的な技術賭けを促進する環境を保とうとしています。
Nvidiaの財務的変遷は技術史と並んで劇的です:PCグラフィックスの小さなサプライヤーからAIブームの中心にいる数兆円(トリリオンドル)企業へと成長しました。
1999年のIPO以降、Nvidiaは長らく数十億ドル規模の評価にとどまり、主に景気循環性のあるPC/ゲーミング市場に依存していました。2010年代中盤にデータセンターとAIの収益が複利的に伸び始め、2017年ごろに時価総額は1000億ドルを超え、2021年には一時トリリオンドルクラブ入りしました。2024年もその水準で取引されることが多く、NvidiaはAIインフラの基盤的企業と評価されました。
歴史的にゲームGPUが中核でしたが、AIと加速コンピューティングの爆発的需要で構成比は逆転しました。
高級AIプラットフォームやネットワーキングはプレミアム価格と高い粗利を生み、データセンターの成長はNvidiaの収益性を劇的に改善しました。
AI需要は単なる製品ラインの追加ではなく、投資家がNvidiaを評価する方法を変えました。循環的なチップ企業としての評価から、インフラとソフトのプラットフォーム企業としてのプレミアム評価へと移行しました。
粗利はAIアクセラレータとプラットフォームソフトに支えられて70%超の領域に入り、固定費が売上ほど急増しないため追加的なマージンが非常に高くなりました。これがアナリストの予想を何度も上方修正させ、株価の再評価を引き起こしました。
Nvidiaの株価は劇的なラリーと深い下落を繰り返してきました。早期の2対1分割、2021年の4対1分割、2024年の10対1分割などで個別株価は調整され、長期保有者には大きなリターンをもたらしました。
一方で、PC需要の低迷、2008年の危機、仮想通貨マイニング崩壊、2022年のテック売りといった出来事で大きく落ち込む局面もあり、ボラティリティは高水準です。
成功にもかかわらずリスクは残ります:
一方で、加速化コンピューティングとAIがデータセンターやエンタープライズ、エッジで数十年にわたり標準化するとの見方が強ければ、Nvidiaのハード・ネットワーク・ソフトの組み合わせは高成長と高マージンを正当化し得ます。
Nvidiaの次章は、GPUを単にモデルを学習する道具から、生成AI、自治システム、シミュレートされた世界の基盤に変えることです。
当面の中心は生成AIです。Nvidiaはテキスト、画像、動画、コードといった主要モデルが自身のプラットフォームで学習、微調整、提供されることを目指します。より強力なデータセンターGPU、より高速なネットワーキング、企業がカスタムコパイロットやドメイン特化モデルを簡単に構築できるソフトウェアスタックが必要です。
クラウドを超え、自律システム(自動運転車、配達ロボ、工場のアーム、ドローン)に注力しています。同一のCUDA/AI/シミュレーションスタックを自動車(Drive)、ロボティクス(Isaac)、組み込み(Jetson)で再利用する狙いです。
デジタルツインはこれらを結びつけます。Omniverseと関連ツールにより企業は工場や都市、5Gネットワークを実働前にシミュレートでき、ハードウェア上の長期的なソフト・サービス収益を生むことを期待しています。
自動車、産業自動化、エッジコンピューティングは巨大な機会です。車は移動するデータセンターになり、工場はAI駆動化され、病院や小売はセンサーで満たされます。これらは低遅延推論、安全性重視のソフト、強い開発者エコシステムを必要とし、Nvidiaが多くの投資をする分野です。
しかしリスクもあります:
創業者やエンジニアにとって、Nvidiaの歴史はハードウェア、システムソフト、開発者ツールを所有することの力を示します。次の計算ボトルネックに早く賭けること、そしてそれをエコシステム戦略と結びつけることが重要です。
政策担当者にとっては、重要なコンピューティングプラットフォームが戦略インフラになり得ることの事例研究です。輸出管理、競争政策、オープンな代替への資金提供が、Nvidiaが引き続き支配的ゲートウェイであり続けるか、あるいは多様なエコシステムの一部となるかを決めるでしょう。
Nvidiaは、3Dグラフィックスが高価なワークステーションの領域から家庭用PCへ移る――という非常に具体的な仮説に基づいて創業されました。
この狭く深いフォーカスが、後のGPUコンピューティングやAIアクセラレーションへの基盤となりました。
CUDAはGPUを「グラフィックス専用」から汎用の並列計算プラットフォームに変えました。
主な効果は次の通りです。
深層学習のブレークスルー時点でCUDA周りのツール群と習熟が既に成熟していたため、Nvidiaは大きな先行優位を得ました。
MellanoxはNvidiaに大規模GPUクラスタをつなぐネットワーキング技術をもたらしました。
要するに、Mellanoxは単体の高速GPUを“スーパーコンピュータ級”にスケールさせるための重要なピースを提供しました。
現在のNvidiaの収益は長年の構成比が大きく変化しています。
特に高性能AIプラットフォームやネットワーク製品はプレミアム価格と高い粗利を生み、同社全体の利益率を押し上げました。
脅威は複合的です。
Nvidiaの防御は性能優位、CUDAを中心としたソフトウェア・エコシステム、統合システム提供です。ただし「十分に良い」代替が現れるとシェアや価格力は圧迫され得ます。
先端GPUは国家安全保障や戦略分野と見なされています。
結果として技術や市場戦略は政策や貿易ルールを強く意識したものになっています。
簡単に言えば、NvidiaのAIソフトウェアスタックは層状になっており、GPUの複雑さを上位で隠蔽します。
自動運転やロボティクスは、NvidiaのコアであるAIとシミュレーションの延長線上にあります。
自動車や産業顧客は長い製品サイクルと継続的なソフト収益をもたらすため、戦略的に重要です。
いくつかの教訓が得られます。
技術的洞察をエコシステム戦略と組み合わせることが重要です。
もしAIハードが従来のGPUと異なるアーキテクチャへ大きくシフトした場合、Nvidiaは迅速に対応する必要があります。
Nvidiaはハードアーキテクチャを進化させ、ソフトウェアを拡張して新しいハードを受け入れるか、システム/ネットワーク/垂直分野の専門性で価値を守るでしょう。歴史的に同社は適応能力を示してきましたが、大規模なアーキテクチャ変化は厳しい試練になります。
多くの開発者はPyTorchやTensorFlow経由でこれらライブラリを呼び出すため、低レベルのGPUコードを書く必要はあまりありません。