2025年5月14日·1 分
なぜOLTPとOLAPのワークロードは1つのデータベースに同居すべきでないことが多いのか
トランザクション(OLTP)と分析(OLAP)を1つのデータベースで混在させるとアプリの遅延、コスト増、運用の複雑化を招く理由と、代替策(レプリカ、データウェアハウス、CDC/ELT)を解説します。
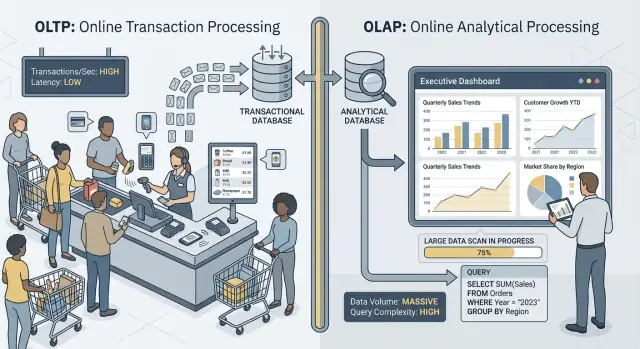
OLTP vs OLAP: 用語抜きの説明
人が「OLTP」や「OLAP」と言うとき、それはデータベースの使われ方が大きく異なる二つのパターンを指します。
OLTP: 事業を動かすデータベース
**OLTP(Online Transaction Processing)**は、常に速く正確である必要がある日々の操作を支えるワークロードです。イメージは「今この変更を保存する」。
典型的なOLTP作業は、注文の作成、在庫の更新、支払いの記録、顧客住所の変更など。これらは通常小さな単位(数行)、頻繁に発生し、数ミリ秒の応答が求められます。人や他のシステムが応答を待っているからです。
OLAP: 事業を説明するデータベース
**OLAP(Online Analytical Processing)**は、何が起きたか、なぜ起きたかを理解するためのワークロードです。イメージは「大量のデータを走査して要約する」。
典型的なOLAP作業は、ダッシュボード、トレンドレポート、コホート分析、予測、そして「過去18か月で地域と商品カテゴリごとの収益はどう変わったか?」のような“スライス&ダイス”な問いです。これらのクエリは多くの行を読み込み、重い集計を行い、秒(あるいは分)単位で実行されても「間違い」ではありません。
同じデータ、目的は別—要求も別
要点は簡単です:OLTPは高速で一貫した書き込みと小さな読み取りを最適化し、OLAPは大規模な読み取りと複雑な計算を最適化します。目的が異なれば、最適なデータベース設定、インデックス、ストレージの配置、スケーリング方法も異なります。
また、「rarely(めったにない)」であり「never(決してない)」ではないことにも注意してください。小規模でデータ量が控えめ、クエリが慎重に設計されているチームなら、しばらくの間ひとつのデータベースを共有することは可能です。後続のセクションでは何が最初に壊れるか、一般的な分離パターン、そして本番からレポーティングを切り離す方法を説明します。
クイック例
- チェックアウト(OLTP): 顧客が「支払う」をクリックすると、アプリは注文、支払いステータス、在庫更新を書き込みます。
- レポーティングダッシュボード(OLAP): マネージャーがダッシュボードを開き、何千(あるいは何百万)もの注文を集計してコンバージョン率や平均注文額、週次トレンドを表示します。
目的が違えば成功指標も違う
OLTPとOLAPはどちらも「SQLを使う」かもしれませんが、最適化する仕事が異なり、それは成功の定義にも現れます。
OLTP: 速度、同時実行、正確さ
OLTP(トランザクショナル)システムは日々のオペレーションを支えます:チェックアウト、アカウント更新、予約、サポートツール。優先順位は明確です:
- 小さな読み書きの高速応答(ミリ秒単位を想定)
- 多数の同時ユーザーでも遅くならないこと
- 正確性と一貫性(誤った残高や重複注文は重大な問題になる)
成功は通常、p95/p99のリクエスト時間、エラー率、ピーク時の同時実行での振る舞いで評価されます。
OLAP: 走査、集計、柔軟性
OLAP(分析)システムは「今四半期に何が変わったか?」や「新価格後にどのセグメントが離脱したか?」のような問いに答えます。これらのクエリはしばしば:
- 大量のデータを走査する
- SUM、COUNT、パーセンタイルなどの集計や結合を行う
- アナリストが探索や問いの絞り込みで頻繁にクエリを変える
成功はクエリスループット、インサイトまでの時間、チューニング無しで複雑なクエリを実行できる能力で測られます。
「すべてを1つで」にはトレードオフが生まれる
両方のワークロードを1つのデータベースに押し込むと、トランザクション向けに最適化された動作と、分析向けに最適化された動作の両方を同時に求めることになります。結果は妥協になることが多く:OLTPは予測できないレイテンシーを受け、OLAPは本番を保護するために制限され、どちらのチームも「どのクエリが許されるか」で揉めます。目的が違えば成功指標も別であるべきで、通常はシステムも別です。
リソース競合:分析がトランザクションを奪うとき
OLTP(アプリの日々のトランザクション)とOLAP(レポーティング・分析)が同じデータベースで動くと、有限なリソースを奪い合います。結果は単なる「レポートが遅い」ではなく、チェックアウトやログインの遅延、予測不能なアプリの不調になります。
CPUとメモリ:長時間クエリ対短時間クエリ
分析クエリは長時間で重いことが多く、巨大なテーブル間の結合、集計、ソート、グルーピングを行います。これらはCPUコアやハッシュ結合・ソートバッファのメモリを独占しがちです。
一方、トランザクションは小さくてレイテンシーに敏感です。CPUが飽和したりメモリ圧力で頻繁にページが追い出されると、短いクエリが長いクエリの後ろで待つことになります—実際に必要な処理は数ミリ秒でも待たされます。
ディスクI/O:大規模走査対多数の小さな読み書き
分析は大きなテーブルスキャンや順次読みを引き起こす一方、OLTPは多くの小さなランダム読みと継続的なインデックス/ログへの書き込みを行います。
両者を混在させると、ストレージサブシステムが互いに相容れないアクセスパターンをさばかなければなりません。OLTPに有効だったキャッシュが分析のスキャンで「洗い流され」、レポートのためにディスクが連続読みをしている間に書き込みレイテンシが急増することがあります。
コネクションプールの圧迫と待ち行列化
数人のアナリストが広範なクエリを走らせると、接続を数分占有することがあります。アプリが固定サイズのプールを使っている場合、リクエストは空き接続を待ってキュー化されます。そのキューイングは健全なシステムを「壊れているように」見せることがあり、平均レイテンシは大丈夫でもテールレイテンシ(p95/p99)が苦痛になります。
ユーザーが実際に気づくこと
外から見ると、これはタイムアウト、遅いチェックアウト、検索結果の遅延、あるいは一般的に不安定な挙動として現れます—しばしば「レポーティング時だけ」や「月末だけ」に起きます。アプリチームにはエラー、分析チームには遅いクエリ、根本問題は共有リソースの競合です。
データ配置とインデックスの要求は正反対を向く
OLTPとOLAPは単に「データベースの使い方が違う」だけでなく、望ましい物理設計が正反対になることがあります。両方を満たそうとすると、コストの高い妥協に落ち着くことが多いです。
OLTP: 高速な選択的ルックアップに最適化
トランザクションワークロードは、1件の注文を取得、1行の在庫を更新、特定ユーザーの最新20イベントを取得――のような短いクエリが中心です。
そのためOLTPスキーマは行指向ストレージと、主キーや外部キー、いくつかの重要なセカンダリインデックスのようなポイントルックアップに有利なインデックスを志向します。目標は書き込みの予測可能で低いレイテンシーです。
OLAP: 走査、グルーピング、要約に最適化
分析では多くの行と少数の列を読むことが多く、「週・地域ごとの収益」「キャンペーン別のコンバージョン率」「利幅での上位商品」といった集計が求められます。
OLAPはカラムナストレージ(必要な列だけ読むため)、パーティショニング(古いデータや無関係なデータを速くプルーニングするため)、事前集計(マテリアライズドビュー、ロールアップ、サマリーテーブル)が役立ちます。
「全部にインデックスを貼る」が裏目に出る理由
ダッシュボードを速くするためにインデックスを増やすのは一般的な反応ですが、追加のインデックスは書き込みコストを増やし、ストレージを圧迫し、vacuumやreindex、バックアップといった保守作業を遅くします。
クエリプランナーと統計のドリフト(平易にいうと)
データベースは統計(フィルタで何行がヒットするか、インデックスの選択性、データ分布)に基づいてクエリプランを選びます。OLTPはデータを常に変化させるため、分布がずれ、プランナーが昨日は良かったが今日は遅いプランを選ぶことがあります。
重いOLAPクエリが混ざると変動は大きくなり、「ベストプラン」の予測がつきにくくなり、あるワークロード向けのチューニングが他方を悪化させます。
ロック、MVCC、メンテナンスの副作用
データベースが「同時実行をサポートする」場合でも、重いレポートとライブトランザクションを混在させると微妙な遅延が発生し、説明しにくい顧客向けのスピニングになることがあります。
長時間クエリはやはりロックを生む
OLAP系のクエリは大量の行を走査し、複数テーブルを結合し、数秒〜数分走ることがあります。その間、スキーマオブジェクトに対するロックや一時構造へのソート/集計のためのリソースを保持することがあり、間接的にロック競合を増やします。
MVCC(マルチバージョン並行制御)により読み書きのブロックは緩和されますが、ホットなテーブルに対しては競合が完全に消えるわけではありません。
MVCCの隠れたコスト:クリーンアップが難しくなる
MVCCでは古い行バージョンが安全に削除できるまで残ります。長時間のレポートが古いスナップショットを開いたままにすると、クリーンアップが進まず:
- vacuum/ガベージコレクションが古いタプルをすぐに削除できない
- データ膨張/断片化が発生し、インデックス効率やキャッシュ効果が下がる
- 一部エンジンはより激しいバックグラウンド処理で対応し、そのI/OやCPUがトランザクションを圧迫する
結果として、レポーティングは即時の負荷を与えるだけでなく、時間経過でシステムを遅くします。
アイソレーションレベルはレイテンシーの変動を拡大する
分析ツールはより強い隔離レベルを要求することがあり(あるいは長いトランザクションを無自覚に走らせることがある)、高い隔離はロック待ちやエンジンが管理するバージョン量を増やします。OLTP側では、ほとんどの注文は速く処理されるが一部だけが急に滞る、という不規則なスパイクとして現れます。
実例:月末のレポートが注文処理を遅らせる
月末に財務が月次の「商品別収益」クエリを走らせると、注文や明細を月全体で走査します。クエリ実行中も新しい注文は受け付けられますが、vacuumが古いバージョンを回収できずインデックスが劣化します。結果として注文APIに時折タイムアウトが生じます—“ダウン”しているわけではなく、競合やクリーンアップのオーバーヘッドが静かにレイテンシーを押し上げているのです。
ワークロードのスパイクと予測不能なレイテンシー
OLTP/OLAP分離をプロトタイプ
構築前にKoder.aiのプランニングモードでサービス・テーブル・レポートの流れを設計
OLTPは予測可能性で生き残ります。チェックアウトやサポート操作が「概ね速い」ではユーザーは遅い瞬間に気づきます。対してOLAPはバースト的になることが多く、数本の重いクエリが長時間CPUやメモリ、I/Oを消費します。
スパイクは普通の業務で起きる
分析トラフィックは次のようなタイミングで集中しがちです:
- 朝のスタンドアップで多くの人が同じチャートを更新する
- 時間の切り替わりで定期レポートが一斉に走る
- 月末や四半期末のクローズ作業で長いスキャンや結合が起きる
一方、OLTPは一般により安定した負荷になります。両者が同一DBだと分析のスパイクがトランザクションの予測不能なレイテンシーに直結します。
制限やスケジューリングは助けになるが根本解決ではない
夜間にレポートを走らせる、同時実行を制限する、ステートメントタイムアウトやクエリコストキャップを設定する、といった対策は被害を減らします。これは本番でのレポーティングに有効なガードレールです。
しかし、これらは根本的な不一致を取り除くものではありません。OLAPクエリは大きなリソースを使って大きな問いに答える設計であり、OLTPは日中ずっと小さなリソースを必要とします。予期せぬダッシュボード更新やアドホッククエリが通ってしまえば、共有データベースは再び露呈します。
ノイジーネイバー問題
共有インフラでは、あるユーザーやジョブがキャッシュを独占したりディスクを飽和させたりCPUスケジューリングを圧迫したりしても、それ自体は「間違い」ではありません。OLTPはその巻き添えを食い、失敗はランダムな遅延として現れるため原因特定が難しくなります。
運用の複雑さ:バックアップ、セキュリティ、キャパシティ計画
OLTPとOLAPを混在させると性能の頭痛だけでなく日々の運用が複雑になります。データベースが「何でも入りのボックス」になり、あらゆる運用タスクが両方のワークロードのリスクを引き受けます。
バックアップ、リストア、災害復旧が遅くなる
分析テーブルは幅が広く急速に成長することが多く、そのボリュームがリカバリストーリーを変えます。
フルバックアップはより時間がかかり、ストレージを多く消費し、バックアップウィンドウを逃す可能性が高くなります。リストアはさらに深刻で、迅速に復旧する必要があるときにトランザクションデータだけでなく大規模な分析データまですべて戻すことになります。災害復旧テストも時間がかかるため頻度が下がり、望ましくない循環になります。
キャパシティ計画が難しくなる
トランザクションの成長は比較的予測可能です:顧客や注文の増加に伴って行数が増えます。一方で分析の成長は断続的です:新しいダッシュボード、保持ポリシーの変更、あるチームが「あと1年だけ生のイベントを残す」と決めるだけで増えます。
両者が混在すると、次のような疑問に答えにくくなります:
- 成長はプロダクト成功によるものか、それともレポートが履歴を増やしているだけか?
- トランザクション向けの高速ストレージが必要か、それとも安価な分析用ストレージが必要か?
その不確実性が過剰プロビジョニング(無駄なコスト)や過小プロビジョニング(突発的な障害)を招きます。
ガードレールを公平に適用するのが難しい
共有データベースでは一つの「無害な」クエリがインシデントに発展します。ステートメントタイムアウト、ワークロードクォータ、スケジュールされたレポートウィンドウ、ワークロード管理ルールなどのガードレールを導入しますが、これらは脆弱で変更が片方のグループを壊すことがあります。
セキュリティとアクセス制御がややこしくなる
アプリケーションは通常、狭い目的別の権限が必要です。アナリストは多くのテーブルに跨る広い読み取り権限を必要とすることがあり、両者を同一データベースに置くと「レポートを動かすために広い権限を与える」圧力が生じ、ミスの影響範囲が広がり、機密データにアクセスできる人が増えます。
スケーリングとコスト:結果的に二重に払うことになる
チームメイトを紹介して報酬を得る
紹介でチームメイトを招待し、新規ユーザーが参加するごとにクレジットを獲得
同じデータベースでOLTPとOLAPを動かそうとすると、初めは安く見えてもスケールするにつれてコストが跳ね上がります。問題は性能だけでなく、別々にスケールするべきワークロードを妥協して一緒にスケールせざるを得ない点です。
OLTPのスケーリングは書き込みが主因(かつ難しい)
トランザクショナルシステムは書き込みに制約されます:多数の小さな更新、厳しいレイテンシー、急増を受け止める必要があります。OLTPのスケールは垂直スケール(より大きなCPU、高速ディスク、より多くのメモリ)になることが多く、書き込み中心の負荷は簡単に水平分散できません。
垂直限界に達したらシャーディングなどの書き込みスケーリングが必要になり、エンジニアリングコストが増えます。
OLAPのスケーリングは計算リソースが主因(弾力的であることが多い)
分析ワークロードは長い走査や重い集計、高い読み取りスループットが必要です。多くのモダンな解析基盤は計算とストレージを分離し、クエリの計算力を独立して増やせます。
OLAPがOLTPデータベースを共有していると、分析だけを独立してスケールできず、データベース全体をスケールする必要があります—トランザクションが問題なくてもです。
隠れた請求書:分析のためにOLTPグレードの資源を買う
トランザクションを速く保つために余分なCPU、ハイエンドストレージ、大きなインスタンスを過剰に用意してしまいがちです。つまりOLAPの振る舞いを支えるためにOLTP向けの高コスト設備を買っている状態です。
分離すると、それぞれのシステムを仕事に合わせてサイズ決めできます:OLTPは低レイテンシーな書き込み向け、OLAPはバースト的な重い読み取り向け。結果的に「二つのシステム」になっても総コストは下がることが多いです。
OLTPとOLAPを分ける一般的なアーキテクチャ
多くのチームは、**トランザクションワークロード(OLTP)と分析ワークロード(OLAP)**を、単一DBに押し込むのではなく、読み取り指向の第二システムを追加して分離します。
パターン1:レポーティング用のリードレプリカ
最初の一歩としてリードレプリカ(フォロワー)を作り、BIツールはそこにクエリを投げます。
長所:アプリ変更が最小、慣れ親しんだSQL、セットアップが速い。
短所:同じエンジンとスキーマなので重いレポートがレプリカのCPU/I/Oを枯渇させることがあり、レプリケーション遅延で数分以上のズレが生じることもあります。結果、「なぜ本番と一致しない?」という混乱が起きやすいです。
適合:小規模チーム、控えめなデータ量、「数分遅れ」が許容できる場合、レポートクエリが管理されている場合。
パターン2:専用のデータウェアハウス/分析DB
OLTPは書き込みとポイント読み取りに最適化し、分析はスキャン、圧縮、集計に強いデータウェアハウスへ移します。
長所:OLTP性能が予測可能、ダッシュボードが速い、アナリストの同時実行性に強い、コストと性能のチューニングが明確になる。
短所:別システムを運用する必要があり、分析向けのデータモデル(多くはスター・スキーマ)を作る必要がある。
適合:データが増えている、多くの利害関係者がいる、複雑なレポーティングがある、または厳しいOLTPレイテンシー要求がある場合。
パターン3:CDCベースのパイプラインで分析へ流す
定期ETLの代わりに、OLTPログからCDC(変更データキャプチャ)でウェアハウスへストリームします(多くはELTと組み合わせ)。
長所:OLTPへの負荷を抑えつつ鮮度を高められ、増分処理や監査性が向上する。
短所:構成要素が増え、スキーマ変更を丁寧に扱う必要がある。
適合:データ量が大きい、鮮度要件が高い、データパイプラインを運用する準備があるチーム。
OLTPからOLAPへ安全にデータを渡す方法
トランザクションDBから分析システムへデータを移すのは「テーブルをコピーする」以上の話で、信頼できて本番に負荷をかけないパイプラインを作ることが目的です。
ETLとELT(平易版)
**ETL(Extract, Transform, Load)**はデータをウェアハウスに入れる前に整形します。ウェアハウスでの計算が高コストな場合や、格納データを厳格に管理したい場合に有効です。
**ELT(Extract, Load, Transform)**は生に近いデータをまずロードし、その後ウェアハウス内で変換します。設定が速く、要件変更に対応しやすいので、ソースの履歴を保持して後から変換を変えられる利点があります。
実践的ルール:ビジネスロジックが頻繁に変わるならELTで再作業を減らし、厳密にキュレートしたものだけを格納する必要があるならETLが向きます。
CDCの基本:重いクエリを避けて変更だけを拾う
**CDC(Change Data Capture)**はOLTPのログからinsert/update/deleteをストリームし、分析側へ送ります。大きなテーブルを繰り返し走査する代わりに、変化分だけ移せます。
可能にすること:
- 本番に大きな読みをかけずに近リアルタイムのレポーティング
- リプレイやバックフィルが容易になる
- 変更履歴の追跡(変更イベントを保存する場合)
データの鮮度:リアルタイム/準リアルタイム/日次
鮮度はビジネス判断であり、技術的コストがあります。
- リアルタイム(秒単位): オペレーショナルダッシュボード向けだが維持が最も難しい
- 準リアルタイム(分単位): 多くのケースで最適解—意思決定に十分で複雑さが抑えられる
- 日次バッチ: 最も簡単で安価。昨日のデータで十分な財務系レポート向け
利害関係者に「鮮度とは何か」のSLA(例:「データは15分以内に更新される」)を明確に伝えましょう。
サイレントな障害を防ぐデータ品質チェック
パイプラインは静かに壊れることが多いので、軽量なチェックを追加します:
- スキーマ変更: 新しい列や型変更がデータを切ってしまうことを検出
- 遅延到着イベント: 数時間後に来る注文や支払いに対するルックバックウィンドウ
- 重複除去: リトライやリプレイによる二重計上を防ぐための安定IDと冪等なロード
これらのガードによりOLAPの信頼性を保ちつつ、OLTPへの影響を避けられます。
同一データベースでの運用が許容される場合
ダッシュボードから本番環境を保護
ダッシュボードがチェックアウトを遅らせないように、明確なレポーティング境界を設定
OLTPとOLAPを一緒にしておくのが常に間違いというわけではありません。アプリが小さく、分析ニーズが狭く、分析が顧客に影響を与えないように厳しい境界を守れるなら一時的に合理的です。
成り立つ状況
軽量な分析と厳しいクエリ制限がある小さなアプリは単一DBでうまく回ることがあります。鍵は「軽量」が何を意味するか正直に定義すること:少数のダッシュボード、控えめな行数、クエリ実行時間と同時実行に上限を設けること。
定期レポートが少数であれば、マテリアライズドビューやサマリーテーブルで分析コストを下げられます。生トランザクションを走査する代わりに日次の集計を事前計算すれば、多くのクエリは短く予測可能になります。
遅延が許容できるならオフピークのレポート時間を設けることも有効です。重いジョブは夜間に走らせ、専用のレポーティングロールに限定された権限とリソース制限を与えます。
追加すべきガードレール
- ステートメントタイムアウトで暴走クエリを切る
- レポーティングユーザーの同時実行数を制限する
- 中核トランザクションのp95/p99をレポート実行と別に監視する
分離の合図(明確な警告サイン)
トランザクションレイテンシーの上昇、レポート実行時の定期的なインシデント、コネクションプールの枯渇、あるいは「ある1つのクエリが本番をダウンさせた」という話が出てきたら、安全圏を超えています。その時点でデータベースの分離(少なくともリードレプリカの利用)は最適化ではなく基本的な運用管理です。
実用的な移行チェックリスト:共有から分離へ
分析を本番データベースから切り離す作業は大改修というより、可視化、目標設定、段階的な移行の連続です。
1) 現状の実態を把握する
仮定ではなく証拠から始めます:
- 頻度とp95/p99レイテンシーで上位のOLTPエンドポイント/クエリを抽出(チェックアウト、ログイン、注文作成など)
- 実行時間、走査量、ビジネス重要度で上位のOLAPレポート/ダッシュボードを列挙
BIツールからのアドホックSQLやスケジュールジョブ、CSVエクスポートのような“隠れた”分析も含めます。
2) 目標を定義する:OLTPのSLOと分析の鮮度
最適化すべき目標を書き出します:
- OLTPのSLO:維持すべきp95/p99レイテンシー、エラー率、ピークスループット
- 分析の鮮度:どの程度の遅延が許容されるか(5分、1時間、翌日)、パイプラインが壊れたときの再構築時間
これにより「遅い」「問題だ」の議論を避け、適切なアーキテクチャを選べます。
3) 分離パスを選ぶ
目標を満たす最も単純なオプションを選びます:
- リードレプリカ: 読み取り多めのレポートへは最速の導入だがレプリカ遅延と負荷問題あり
- ウェアハウス: 大規模走査や多結合、長期履歴に最適
- CDCパイプライン(ETL/ELT): 本番を叩かずに近リアルタイム分析が必要な場合に最適
4) 安全に展開する(まず並行運用)
- 定義(タイムゾーン、返金、"アクティブユーザー"など)を検証し、数値の一致を確認
- 古いソースと新しいソースでダッシュボードを1サイクル並行稼働させる
- 最も問題のあるクエリから順にレポートごとに切り替える
- 利害関係者が新しいソースを信頼するまで本番直接の「報告用接続」をロックダウンする
5) 後戻りしないためのガードレールを追加
レプリカ遅延やパイプライン遅延、ダッシュボード実行時間、ウェアハウスの支出を監視します。クエリ予算(タイムアウト、同時実行制限)を設定し、鮮度が落ちたときや負荷が急増したときのプレイブックを用意します。
アプリを作る側への実用的メモ
初期段階で高速に動く場合、最大のリスクは分析がいつのまにかコアトランザクション経路に取り込まれてしまうことです(たとえば、ダッシュボードクエリが知らずに“本番クリティカル”になってしまう)。これを避ける一つの方法は、分離を前提に設計しておくことです—たとえ小さなリードレプリカから始めるにしても、アーキテクチャチェックリストに分離を組み込んでおきます。
Koder.aiのようなプラットフォームはここで役立ちます。Reactアプリ+Goサービス+PostgreSQLでOLTP側をプロトタイプし、計画段階でレポーティング/ウェアハウスの境界を設計できます。プロダクトが成長したらソースコードをエクスポートし、スキーマを進化させ、CDC/ELTコンポーネントを追加して「本番でのレポーティング」を恒常的習慣にしないようにできます。
よくある質問
OLTPとOLAPを簡単に説明すると?
**OLTP(オンライン・トランザクション処理)**は、受注作成、在庫更新、支払い記録など日々の操作を扱います。優先するのは低レイテンシー、高い同時実行性、正確性です。
**OLAP(オンライン分析処理)**は、ダッシュボードやトレンド、コホート分析のような大規模なスキャンや集計で答えを導きます。優先するのはスループット、柔軟なクエリ、集計の高速化であり、ミリ秒応答は必須ではありません。
なぜ同じデータベースで分析を動かすとトランザクション性能が落ちるのか?
ワークロードが同じリソースを奪い合うためです:
- CPUとメモリ: 大規模な集計や結合が短いトランザクションを圧迫します。
- ディスクI/O: 分析のスキャンがOLTPの小さなランダム読み書きやログ/インデックス書き込みを妨げます。
- キャッシュの追い出し: 大きなスキャンがホットなOLTPページを追い出して突然遅くなります。
- コネクションプールの圧迫: 数本の長時間BIクエリで接続が占有され、アプリのリクエストが待たされます。
結果として、コアなユーザー操作でのp95/p99レイテンシーが予測不能になります。
両方を速くするためにインデックスを増やせばよくない?
通常は難しいです。ダッシュボードを速くするためにインデックスを増やすと:
- 追加のインデックスが書き込みコストを増やす(insert/update/deleteがより多くの構造を更新する)
- インデックスがストレージを増やし、vacuumやreindex、バックアップなどの保守を遅くする
- あるレポート向けにチューニングすると他のクエリ(あるいはOLTPの書き込み)を悪化させることがある
分析用途には、パーティショニング、カラムナストレージ、事前集計の方が効果的なことが多いです。
MVCCと長時間クエリはどのように共有データベースを時間経過で遅くするのか?
MVCCは読み書きのブロッキングを避けますが、混在ワークロードを“無償”にするわけではありません。実務上の問題は:
- 長時間のレポートが古いスナップショットを保持し、古い行バージョンの削除を遅らせる
- クリーンアップの遅れがボリューム増(bloat)や断片化を招き、クエリやキャッシュ効率を低下させる
- バックグラウンドのクリーンアップや圧縮処理がCPUやI/Oを奪い、OLTPに影響を与える
目に見えるブロッキングがなくても、分析が長期的に性能を劣化させます。
OLTPとOLAPを分離すべきだと判断する警告サインは?
たとえば次のような兆候です:
- チェックアウト/ログイン/更新エンドポイントのp95/p99レイテンシーの上昇
- レポート実行時のタイムアウトやリトライ増加
- コネクションプール枯渇(アプリのリクエストが接続待ちになる)
- 月末や四半期末のレポートに連動するインシデント
ダッシュボード更新中にシステムが「ランダムに遅く」感じるなら、混在ワークロードの典型的な匂いです。
レポーティングにリードレプリカを使うのはいつ有効か?
リードレプリカは最初の一歩としてよく使われます:
- 利点: アプリの変更は最小限、慣れたSQL、導入が早い。書き込みを本番から隔離できる。
- 欠点: 重いレポートでレプリカのCPU/I/Oが枯渇することがある。レプリケーション遅延により数分遅れになる場合があり、指標の不一致が混乱を招く。
データ量が控えめで「数分遅れ」が許容される場合の橋渡しとして有効です。
リードレプリカの代わりに専用のデータウェアハウスを使うべき時は?
次のような場合にデータウェアハウスが適しています:
- 大規模なスキャン、結合、集計で高速性が必要
- 多数のアナリストが同時にクエリを実行する
- 長期保持をしたいがOLTPに負担をかけたくない
- チューニングとコストを明確に分けたい(OLTPはレイテンシー、OLAPはスループット)
通常は分析向けのデータモデル(スター/スノーフレーク)と、データをロードするためのパイプラインが必要です。
CDCとは何で、なぜ本番で重いETLを走らせるより良いことが多いのか?
**CDC(Change Data Capture)**はOLTPの変更(insert/update/delete)をログ等からストリームして分析側へ送ります。
利点:
- 大きなテーブルを再スキャンする代わりに変更だけを移動する
- ほぼリアルタイムの新鮮さを低負荷で実現できる
- リプレイやバックフィルがやりやすい
代償は、構成要素が増え、スキーマ変更や順序制御を慎重に扱う必要がある点です。
OLTPのデータをOLAPに移すとき、ETLとELTのどちらを選ぶべきか?
用途と要件次第です:
- ELT: 生データをまずロードし、ウェアハウス内で変換。定義変更に強く、再処理しやすい。迅速に立ち上げたい場合に向く。
- ETL: ロード前に変換し、キュレーテッドな結果だけを格納。保存内容を厳格に管理したい場合に向く。
実務では、まずELTで始めておき、重要な指標が固まってきたらガバナンスやキュレーションを追加する、という流れが多いです。
OLTPとOLAPを同じデータベースに置いておくのは許容されることがあるか?
はい、短期的には許容できます。ただし分析を本当に軽量に保ち、明確なガードレールを設ける必要があります:
- ステートメントタイムアウトで暴走クエリを切る
- レポーティングの同時実行数を制限する(別ロール/別プール)
- マテリアライズドビューやサマリーテーブルで事前集計を活用する
- 本番のp95/p99を別に監視する
レポート実行で定期的にレイテンシースパイクや接続枯渇が起きるようになったら、分離の時期です。