2025年12月28日·1 分
パフォーマンス調査のための Claude Code:測定に基づくワークフロー
Claude Code を使い、測定→仮説→最小限の変更→再測定という反復可能なループでパフォーマンス調査を行い、出荷前に検証する方法を解説します。
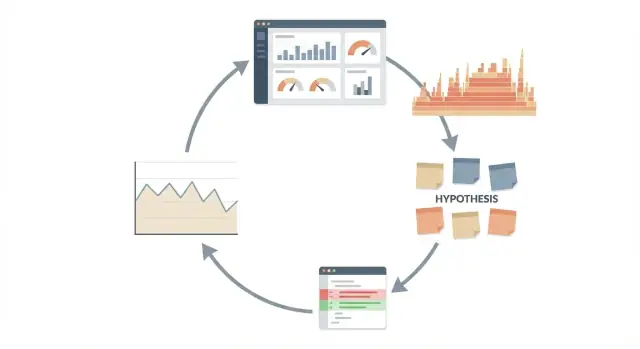
Claude Code を使い、測定→仮説→最小限の変更→再測定という反復可能なループでパフォーマンス調査を行い、出荷前に検証する方法を解説します。
パフォーマンスの不具合は推測を招きます。誰かがページが遅いと感じたり API がタイムアウトすると、真っ先に「コードを整理する」「キャッシュを追加する」「ループを書き直す」といった動きが出ます。しかし「遅く感じる」は指標ではなく、「きれい」は必ずしも速いことを意味しません。
測定がないと、チームは的外れな部分を何時間も直してしまいます。ホットパスはデータベースやネットワーク、あるいは予期せぬ単一の割り当てにあるかもしれませんが、チームはほとんど実行されないコードを磨いていることがあります。さらに悪いのは、賢そうに見える変更がパフォーマンスを悪化させる場合です:タイトなループでの追加ログ、メモリ圧力を高めるキャッシュ、ロック競合を生む並列処理など。
推測は挙動を壊すリスクも抱えます。速くするための変更が結果、エラーハンドリング、順序、リトライ動作を変えるかもしれません。正確性と速度を一緒に再確認しないと、ベンチマークでは「勝てても」バグを密かに出荷してしまいます。
パフォーマンスを議論ではなく実験として扱ってください。ループはシンプルで再現可能です:
多くの改善は控えめです:p95レイテンシを8%削る、ピークメモリを50MB減らす、データベースクエリを1つ減らすなど。それらは測定され、検証され、再現可能であれば意味があります。
これは一回きりの「速くして」依頼ではなく、ループとして回すと効果的です。ループは行動を証拠と監視できる数値に結びつけるので自分を正直に保ちます。
明確な手順:
各ステップは別の自己欺瞞からあなたを守ります。先に測定することで「本当の問題でないもの」を直すのを防げます。文書化された仮説は同時に五つのことを変えて、どれが効いたかを推測するのを止めます。最小限の変更は挙動を壊すリスクや新しいボトルネックを作るリスクを下げます。再測定はウォームキャッシュによるプラセボ的改善や回帰を暴きます。
「完了」は感覚ではなく結果です:目標指標が正しい方向に動き、明白な回帰(エラー、高いメモリ、悪化したp95、周辺エンドポイントの遅延)がないことが確認できたら終わりです。
いつ止めるかを知ることもワークフローの一部です。改善が平坦化したとき、指標がユーザーにとって十分に良いとき、または次のアイデアが大規模なリファクタを要し見返りが小さいときに止めます。パフォーマンス作業には常に機会コストがあるので、ループは効果が出るところに時間を使う助けになります。
五つの指標を同時に測ると何が改善したかわかりません。今回の調査では一つの主要指標を選び、他は補助のシグナルとして扱ってください。ユーザー向けの問題では多くの場合その指標はレイテンシです。バッチ処理ならスループット、CPU時間、メモリ使用量、あるいは1実行あたりのクラウドコストが指標になります。
シナリオを具体的にします。"APIが遅い"は曖昧すぎます。"通常のカート3点での POST /checkout"は測定可能です。入力を安定させて数値に意味を持たせてください。
コードを触る前にベースラインと環境の詳細を書き留めます:データセットサイズ、マシン種別、ビルドモード、機能フラグ、同時実行、ウォームアップ。これがアンカー(基準)です。これがないと、どの変更も進歩に見えてしまいます。
レイテンシでは平均だけでなくパーセンタイルに依存してください。p50は典型的な体験を示し、p95/p99はユーザーが不満を持つ尾を露呈します。p50が改善してp99が悪化することはあり得ます。
「意味のある改善」を事前に決めておくとノイズで祝わなくて済みます:
これらのルールがあれば、ゴールポストを動かさずにアイデアを試せます。
信頼できる最も簡単なシグナルから始めます。リクエスト周りの単一のタイミングで本当に問題があるか、どれくらい大きいかがわかることが多く、深いプロファイリングは「なぜ遅いか」を説明する必要が出てから使えば十分です。
良い証拠は通常、複数のソースの組み合わせから得られます:
問いが「遅くなっているか、どれだけか?」ならシンプルな指標を使い、問いが「時間がどこに行っているか?」ならプロファイリングを使ってください。deploy後にp95が倍になったなら、まずタイミングとログで回帰を確認して範囲を定めます。タイミングで遅延の大半がアプリコード内にあるなら、CPUプロファイラやフレームグラフで増えた正確な関数を指し示せます。
計測は安全に行ってください。デバッグに必要な情報を集めつつユーザーデータは集め過ぎないようにします。集計(期間、カウント、サイズ)を優先し、識別子はデフォルトでマスキングします。
ノイズは現実です。複数サンプルを取りアウトライヤーを記録してください。同じリクエストを10〜30回実行し、1回のベストランではなく中央値とp95を記録します。
変更後に再現できるように、正確なテスト手順(環境、データセット、エンドポイント、リクエストボディサイズ、同時実行数、結果の取り方)を書き留めておきます。
まず名前の付く症状から始めます:"トラフィックピーク時にp95が220msから900msに跳ね上がる"、"CPUが2コアで95%に張り付く"、"メモリが時間あたり200MB増える"など。"遅く感じる"のような曖昧な症状はランダムな変更に繋がります。
次に測定を元に疑わしい領域を特定します。フレームグラフが大半の時間をJSONエンコードに示すかもしれませんし、トレースが遅い呼び出し経路を示すかもしれません。全体のコストの多くを説明する最小の領域(関数1つ、SQLクエリ1つ、外部呼び出し1つ)を選びます。
良い仮説は1文で、検証可能で、予測が結びついています。助けを求めるときは「ツールにすべてを速くしてくれ」と頼むのではなく、アイデアを検証する手順を求めてください。
次の形式を使ってください:
例:"プロファイルがSerializeResponseにCPUの38%を示しているので、リクエストごとに新しいバッファを割り当てていることがCPUスパイクの原因だ。バッファを再利用すれば、同じ負荷でp95レイテンシが約10〜20%低下し、CPU使用率は約15%下がるはずだ。"
変更前に代替案を2〜3個書いておくと自分に厳しくできます。遅い原因は上流の依存、ロック競合、キャッシュミス率の変化、ロールアウトでペイロードが増えたことなどかもしれません。
2〜3の代替説明を書いて、その中で証拠が最も支持するものを選びます。もし変更が指標を動かさなければ、次の仮説へ進めます。
Claudeは注意深いアナリストのように扱うとパフォーマンス作業で最も有用です。あくまで測定に結びついた提案を行い、各ステップが反証可能であることを確認してください。
曖昧な説明ではなく、実際の入力(小さく焦点を絞った証拠)を渡します:プロファイルの要約、遅いリクエスト周辺のログ数行、クエリプラン、特定のコードパスなど。必ず「変更前」の数値(p95、CPU時間、DB時間)を含めてベースラインを知らせます。
データが示唆することと示唆しないことを説明させ、競合する説明を強制してください。便利なプロンプトの終わりにはこう付けます:"2〜3の仮説を出し、それぞれを反証するテストを書け。" こうすれば最初に妥当に見える筋書きに固執するのを防げます。
何かを変更する前に、主要仮説を検証できる最小の実験を求めてください。素早く可逆なもの:関数周りにタイマーを1つ追加する、プロファイラフラグを1つ有効にする、EXPLAINで1回クエリを実行する、などです。
出力を厳密な構造にしたければ、次を要求してください:
もし具体的な指標、場所、期待結果を出せないなら、それはまた推測に戻っているという合図です。
証拠と仮説があるなら、「全部きれいにする」衝動を抑えてください。パフォーマンス作業は小さく元に戻せる変更の方が信頼しやすいです。
1度に1つだけ変えます。クエリを調整し、キャッシュを追加し、ループをリファクタを同じコミットでやると何が効いたかわかりません。単一変数の変更なら次の測定が意味を持ちます。
コードを触る前に、期待する変化を数値で書いておきます。例:"p95を420msから300ms未満に下げ、DB時間を約100ms削る"。目標を外したら仮説が弱かったか不完全だったと速く学べます。
可逆性を保つ方法:
「最小限」は「取るに足らない」を意味しません。フォーカスされた改善:高コストな関数結果を1つキャッシュする、タイトなループの繰り返し割り当てを1つ除去する、あるいは不要な処理をあるリクエストで止める、などです。
疑わしいボトルネック周辺に軽いタイミングを入れて、何が動いたかを見られるようにします。呼び出し前後にタイムスタンプを1つ入れるだけ(ログかメトリクスとして)で、変更が本当に遅い箇所に効いたか確認できます。
変更後はベースラインと同じシナリオを正確に再実行します:同じ入力、同じ環境、同じ負荷形状。キャッシュやウォームアップが必要ならそれを明示しないと偶然の改善を見つけてしまいます。
同じ指標と同じパーセンタイルで結果を比較します。平均値は痛みを隠すので、p95/p99、スループット、CPU時間を見ます。数回繰り返して数値が収束するか確認します。
祝う前に、ヘッドラインの数値に出ない回帰をチェックします:
その後、証拠に基づいて判断します。改善が実在し回帰がなければ採用します。結果が混在しているかノイジーならロールバックして新しい仮説を立てるか、変更をさらに隔離します。
Koder.aiのようなプラットフォームで作業しているなら、実験前にスナップショットを取っておくことでロールバックがワンステップになり、大胆なアイデアを安全に試しやすくなります。
最後に学んだことを短く書き残します:ベースライン、変更点、新しい数値、結論。これが次のラウンドで同じ行き止まりを繰り返さない助けになります。
パフォーマンス作業が横道にそれるのは、測定したものと変更したものの関連を失うときです。証拠の連鎖を保ち、何が良くなったか/悪くなったかを自信を持って言えるようにしてください。
よくある失敗:
小さな例:エンドポイントが遅く見えるのでシリアライザを調整したら小さいデータセットで速くなったように見えた。しかし本番のp99は悪化し続けた。原因はDBがボトルネックのままで、変更がペイロードを増やしてしまったためです。
Claude Codeに修正案を出させるときは短く絞って使ってください。既に集めた証拠に合う1〜2の最小変更を求め、パッチを受け入れる前に必ず再測定計画を要求してください。
テストがあいまいだと速度の主張は崩れます。祝う前に、何をどう測ったか、どう測ったか、何を変えたかを説明できるようにしてください。
始めに1つの指標を決め、ベースラインの結果を書き留めます。数値を変えうる要素(マシン、CPU負荷、データセットサイズ、ビルドモード、機能フラグ、キャッシュ状態、同時実行)を含めること。明日再現できないセットアップならベースラインはないのと同じです。
チェックリスト:
数値が良くなったら短い回帰チェックを行います:出力の正確性、エラー率、タイムアウトを確認し、メモリ増加、CPUスパイク、起動遅延、DB負荷増加といった副作用を観察します。p95が良くてもメモリが倍増するならトレードオフとして間違っています。
チームが GET /orders は開発環境では問題ないが、ステージングで中程度の負荷になると遅くなると報告しました。ユーザーはタイムアウトを訴えますが平均レイテンシは「まあまあ」に見える、これは典型的な落とし穴です。
まずベースラインを設定します。同じデータセット・同じ同時実行・同じ期間の負荷テストで記録した結果:
証拠を集めると、エンドポイントは注文を取得するメインクエリを実行した後、注文ごとに関連アイテムをループで取りに行っていることがわかりました。JSONレスポンスは大きいですが、DB時間が支配的です。
これを仮説リストに変えます:
最も強い証拠に一致する最小の変更を求めます:注文IDでキーをまとめて一度にアイテムを取得する(または遅いクエリプランがフルスキャンを示すなら欠けているインデックスを追加する)。可逆でフォーカスしたコミットにします。
同じ負荷テストで再測定した結果:
判断:明確な勝ちなので修正を出荷し、残るギャップとCPUスパイクに次のサイクルで取り組みます(DBはもはや主要制約ではない)。
改善が早くなる最も簡単な方法は、各ランを小さな再現可能な実験として扱うことです。一貫したプロセスにすれば、結果は信頼しやすく、比較や共有が楽になります。
簡単な1ページテンプレート:
これらのノートの置き場所を決めて消えないようにしてください。共有場所は完璧なツールよりも重要です:サービス横のリポジトリ、チームドキュメント、チケットノートなど。誰かが数ヶ月後に「キャッシュ変更後のp95スパイク」を見つけられることが重要です。
安全な実験を習慣化してください。スナップショットと簡単なロールバックで大胆なアイデアを恐れず試せます。Koder.aiで開発しているなら、Planning Modeは計測計画を書き、仮説を定義し、変更範囲を狭めてからタイトな差分を生成して再測定する流れに便利です。
ペースを決めてください。インシデントを待つ必要はありません。新しいクエリやエンドポイント、大きなペイロード、依存関係アップグレードの後に10分程度のベースラインチェックを加えるだけで、後で1日の推測作業を節約できます。
まず苦情に合った一つの数値から始めます。通常は特定のエンドポイントと入力に対するp95レイテンシです。同じ条件(データサイズ、同時実行数、キャッシュの温度)でベースラインを記録し、1つだけ変更して再測定してください。
ベースラインが再現できないなら、まだ測定をしていない — 推測しているだけです。
有用なベースラインには次が含まれます:
コードに手を加える前に書き留めて、ゴールポストを動かさないことが大切です。
パーセンタイルは平均より利用者体験をよく表します。p50は「典型値」ですが、ユーザーは遅い尾(tail)について文句を言います。それがp95/p99です。
p50が改善してもp99が悪化すれば、平均は良く見えても体感は遅くなります。
「遅いか?」と「どれくらい?」を知りたいときはシンプルなタイミング/ログを使いましょう。「時間がどこに消えているか」を知りたいときにプロファイリングを使います。
実用的な流れは:リクエストタイミングで回帰を確認し、遅延が実際にあり範囲が定まってからプロファイラを回します。
主要指標を一つに絞り、他はガードレールとして扱います。よくあるセットは:
これで一つのグラフだけ勝って他で失敗している、という誤魔化しを防げます。
証拠と予測に結びついた一文で書きます:
証拠と期待する指標変化が書けないなら、その仮説は検証可能とは言えません。
小さく、フォーカスされた、元に戻せる変更にしましょう:
小さな差分なら次の測定が意味を持ち、挙動を壊すリスクを下げられます。
ベースラインと同じシナリオ(入力、環境、負荷形状)を再実行します。キャッシュやウォームアップが関係するならそれを明示してください(例:「最初はコールド、次の5回はウォーム」)。
平均値だけで判断せず、p95/p99やスループット、CPU時間を同じように比較します。結果が不安定ならサンプルを増やすか元に戻して仮説を練り直しましょう。
また、次の点を必ずチェックします:
計測と変更のつながりを失うと時間を無駄にします。証拠の鎖を保って、何が良くなったか/悪くなったかを自信を持って説明できるようにしてください。
よくある失敗例:
Claude Codeを使うときは提案を短く絞り、証拠に合った1〜2の最小変更だけ出すようにしましょう。必ず再測定計画を求めてください。
テストがあいまいだと速度主張は崩れます。祝う前に、何をどう測ったか、どう変えたかを説明できるようにしましょう。
チェックリスト:
数値が良くなったら、正確性、エラー率、タイムアウト、メモリやDB負荷などの副作用を素早く確認してください。
次のような手順で段階的に調査します:
例の結果:
各ランを小さな実験として扱い、再現可能にするのが最速で上達する方法です。プロセスが一貫していれば、結果の信頼度が上がり比較や共有がしやすくなります。
1ページの簡単なテンプレートが役に立ちます:
これらのノートを見つけやすい場所に置いてください。サービス横のリポジトリフォルダ、チームのドキュメント、チケットノートなど、ツールは何でも構いません。重要なのは発見可能性です。
スナップショットと簡単なロールバックを習慣にし、大胆なアイデアを恐れず試せるようにしましょう。Koder.aiを使っている場合は、Planning Modeで計測計画と仮説を書き、変更範囲を狭めてから差分を生成し、再測定する流れが便利です。
判断:DBが主要な制約でなくなったので、この修正は採用し、残るギャップは次のサイクルでCPUや他の要因に焦点を当てます。
定期的にチェックを入れる習慣も大切です。新しいクエリやエンドポイント、大きなペイロード、依存関係のアップグレードの後に10分程度のベースライン確認をするだけで、後で1日の推測作業を防げることが多いです。