2025年6月13日·1 分
Palantirとエンタープライズソフトウェアの比較:統合、分析、展開
Palantirのデータ統合、運用アナリティクス、展開アプローチが従来のエンタープライズソフトとどう違うか、購買側にとって何を意味するかを解説します。
Palantirのデータ統合、運用アナリティクス、展開アプローチが従来のエンタープライズソフトとどう違うか、購買側にとって何を意味するかを解説します。
人々はしばしば「Palantir」をデータ駆動型運用を作る一連の製品や手法の略称として使います。比較を明確にするために、ここで実際に議論しているもの(とそうでないもの)を明示しておきます。
企業文脈で「Palantir」というと、通常次のいずれか(または複数)を指します:
以降では「Palantir風」を(1)強力なデータ統合、(2)チーム間の意味を揃えるセマンティック/オントロジーレイヤー、(3)クラウド、オンプレ、切断環境にまたがる展開パターン、という組み合わせとして表現します。
「従来のエンタープライズソフトウェア」は単一製品ではなく、組織が時間をかけて組み上げる典型的なスタックを指します。例えば:
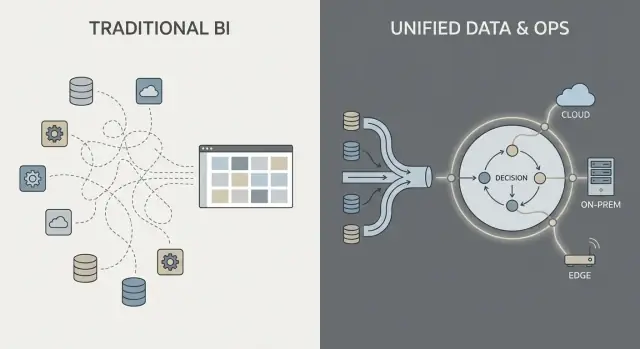
このアプローチでは、統合、分析、運用が別々のツールとチームによって扱われ、プロジェクトやガバナンスプロセスを通じて接続されることが多いです。
これはアプローチの比較であり、特定ベンダーの賛美ではありません。多くの組織は従来のスタックで成功していますし、別の組織はより統合されたプラットフォームモデルから利益を得ます。
実務的な問いは次のとおりです:速度、コントロール、そして分析が日々の業務にどれだけ直接結びつくか、という点でどんなトレードオフをしているか。
残りの記事は以下の3分野に焦点を当てます:
従来のエンタープライズソフトウェアにおけるデータ作業は、よくあるチェーンに従います:システム(ERP、CRM、ログ)からデータを引き、変換してウェアハウスやレイクにロードし、BIダッシュボードやいくつかの下流アプリを構築する、という流れです。
このパターンはうまく機能しますが、多くの場合、統合は脆い引き渡しの連続になります:あるチームが抽出スクリプトを管理し、別のチームがウェアハウスモデルを保守し、さらに別のチームがダッシュボード定義を持ち、業務チームはスプレッドシートを使って「実際の数字」を密かに再定義してしまうという具合です。
ETL/ELTでは変更が波及しやすいです。ソースシステムに新しいフィールドが加わるとパイプラインが壊れることがあります。「手早い修正」が別のパイプラインを生み、やがてメトリクスが重複して(例:「収益」が3か所に)誰が責任を持つのか分からなくなります。
ここではバッチ処理が一般的で、データは夜間に到着し、ダッシュボードは朝に更新されます。準リアルタイムも可能ですが、通常は別のストリーミングスタックとして独自のツールとオーナーが必要になります。
Palantir風のアプローチは、ソースを統合し、セマンティクス(定義、関係、ルール)を早期に適用してから、その同じキュレート済みデータを分析と運用ワークフローに公開することを目指します。
平たく言えば:各ダッシュボードやアプリが顧客、資産、事例、出荷の意味を個別に考え直すのではなく、その意味を1回定義して再利用するということです。これによりロジックの重複が減り、定義が変更されたときにどこにその定義があり誰が承認したかが分かるため、所有権が明確になります。
統合はしばしばコネクタの問題ではなく責任の所在で失敗します:
肝心なのは「システムXに接続できるか?」ではなく「誰がパイプライン、指標定義、そしてビジネス上の意味を継続的に所有するのか?」という問いです。
従来のエンタープライズソフトはしばしば「意味」を後回しにします:データはアプリ個別のスキーマで保存され、指標定義は個々のダッシュボード内にあり、チームは独自に「注文とは何か」「ケースが解決されたとはいつか」を管理してしまいます。その結果は見慣れたもので、異なる場所で異なる数値が出たり、調整会議が増えたり、異常が起きたときに誰が責任を取るのか不明瞭になります。
Palantir風のアプローチでは、セマンティックレイヤーは単なるレポート用の便宜ではありません。オントロジーは共有のビジネスモデルとして次を定義します:
これが分析と運用の「重心」になります:複数のデータソースが存在しても、共通のビジネスオブジェクトにマッピングされ一貫した定義が適用されます。
共有モデルはチームが各レポートやアプリで定義を再発明しなくなるため、数値の不整合を減らします。また、もし「オンタイム配送」がオントロジーの出荷イベントに基づいて定義されていれば、基となるデータやビジネスロジックの責任者が明確になります。
適切に設計されたオントロジーは単にダッシュボードをきれいにするだけでなく、日々の意思決定を速く、論争の少ないものにします。
BIダッシュボードや従来のレポーティングは主に振り返りとモニタリングを目的とします。たとえば「先週何が起きたか」「KPIに対して順調か」といった問いに答えます。セールスダッシュボード、月次のクローズレポート、経営のスコアカードは有用ですが、多くの場合そこで可視化が終わります。
オペレーショナルアナリティクスは異なります:分析がワークフロー内部に組み込まれ、具体的な次の一手を促す形で現場に介入します。
BI/レポーティングは一般に次を重視します:
これはガバナンスやパフォーマンス管理、説明責任に非常に有効です。
オペレーショナルアナリティクスは次を重視します:
具体例は「チャート」よりも文脈付きの作業キューに近いものになります:
最も重要な変化は、分析が特定のワークフローステップに結び付けられることです。BIダッシュボードは「遅延配送が増えている」と示すだけですが、オペレーショナルアナリティクスは「本日リスクのある37件の出荷とその原因、推奨される対応」を示し、その場で実行や割り当てができるようにします。
従来のエンタープライズ分析は多くの場合ダッシュボードで終わります:誰かが問題を見つけてCSVをエクスポートし、メールで報告し、別チームが後で「何かをする」。Palantir風のアプローチは分析をワークフローに直接埋め込み、このギャップを短くするよう設計されています。
ワークフロー中心のシステムは通常推奨を生成します(例:「これら12件の出荷を優先」「この3社のベンダーをフラグ」「72時間以内に保全をスケジュール」)が、明示的な承認を要します。承認ステップが重要な理由は:
これは特に規制された領域や重大な運用において重要です。「モデルが言ったから」だけでは正当化できないためです。
分析を別の“目的地”として扱うのではなく、インターフェースはインサイトをタスクへルーティングします:キューへ割り当て、承認要求、通知トリガー、ケースオープン、ワークオーダー作成など。重要なのは結果が同じシステム内で追跡されるため、アクションがリスクやコスト、遅延を実際に減らしたかどうかを測れることです。
ワークフロー中心の設計は通常役割ごとに体験を分けます:
成功の共通要素は、製品が意思決定権限と運用手順に合致していることです:誰が行動できるか、どの承認が必要か、「完了」とは何を意味するか。
ガバナンスは多くの分析プログラムが成功するか停滞するかの分岐点です。これは単なる“セキュリティ設定”ではなく、人々が数字を信頼し安全に共有し、実際の意思決定に使えるようにするための実務的ルールと証拠です。
ほとんどの企業はベンダーを問わず次のコア制御を必要とします:
これらは単なる官僚的手続きではなく、分析が運用に近づくときの“二つの真実”問題を防ぐ手段です。
従来のBI実装はしばしばレポート層でセキュリティを管理します:ユーザーは特定のダッシュボードを閲覧でき、管理者がそこで権限を管理します。分析が主に記述的である場合、これで十分なこともあります。
Palantir風のアプローチはセキュリティとガバナンスをパイプライン全体に通すことを目指します:生データの取り込みから、セマンティックレイヤー(オブジェクト、関係、定義)、モデル、そしてインサイトからトリガーされるアクションに至るまでです。目的は、運用上の意思決定(派遣、在庫解放、優先付けなど)が背後のデータと同じ制御を継承することです。
安全性と説明責任のために次の2つの原則が重要です:
例として、アナリストが指標定義を提案し、データスチュワードが承認し、運用がそれを使う――という流れが明確に記録されます。
堅牢なガバナンスはコンプライアンスチームだけのためのものではありません。ビジネスユーザーがリネージをクリックして定義を確認し、一貫した権限で安心して使えると、スプレッドシートの議論をやめて実際に行動するようになります。これが分析を「興味深いレポート」から「運用行動」に変える要因です。
ソフトウェアがどこで動くかはもう単なるITの詳細ではなく、データで何ができるか、どれだけ速く変えられるか、どれだけのリスクを受け入れるかを決めます。バイヤーは通常4つの展開パターンを評価します。
パブリッククラウド(AWS/Azure/GCP)は速度を最適化します:プロビジョニングが速く、マネージドサービスがインフラ作業を減らし、スケールが容易です。主要な検討点はデータ居住性(どのリージョンか、バックアップはどうか、サポートのアクセス)やオンプレシステムとの統合、クラウド接続を許容できるかどうかです。
プライベートクラウド(シングルテナントや顧客管理のKubernetes/VM)は、クラウド的な自動化を保ちながらネットワーク境界や監査要件をより厳格に管理したい場合に選ばれます。コンプライアンスの摩擦を減らせますが、パッチ適用、監視、アクセスレビューなど運用の規律が必要です。
オンプレ展開は依然として製造、エネルギー、高度に規制された分野で多く使われます。コアシステムとデータを施設外に出せない場合に適合しますが、運用上の負担(ハードウェアライフサイクル、容量計画、dev/test/prod間の一貫性維持)が増えます。組織がプラットフォームを信頼性高く運用できない場合、オンプレは価値実現を遅らせる可能性があります。
切断(エアギャップ)環境は特殊ケースです:防衛、重要インフラ、接続が制限されたサイトなど。ここでは展開モデルが厳格な更新制御をサポートする必要があります——署名済みアーティファクト、制御されたリリース昇格、隔離ネットワークでの反復可能なインストール。
ネットワーク制約はデータ移動にも影響します:継続的同期の代わりに段階的な転送やエクスポート/インポートのワークフローに頼ることが多いです。
実務では三角関係です:柔軟性(クラウド)、コントロール(オンプレ/エアギャップ)、変更の速さ(自動化+アップデート)。最適解は居住性ルール、ネットワークの現実、どれだけプラットフォーム運用を自社で担うかに依存します。
“Apollo風のデリバリ”は、基本的に高リスク環境向けの継続的デリバリです:改善を頻繁にデプロイ(週次、日次、場合によっては1日複数回)しつつ、運用を安定させます。
目的は「速く壊す」ことではなく「頻繁に変更しても何も壊さない」ことです。
大きな四半期リリースにまとめる代わりに、チームは小さく可逆な更新を行います。各更新はテストが容易で説明しやすく、問題があってもロールバックしやすいです。
オペレーショナルアナリティクスでは、“ソフトウェア”はUIだけでなくデータパイプライン、ビジネスロジック、現場が依存するワークフローを含むため、安全な更新プロセスが日常の一部になります。
従来の企業ソフトのアップグレードはプロジェクトのようになりがちです:長い計画期間、ダウンタイム調整、互換性懸念、再教育、一斉切り替え日。パッチが提供されても、多くの組織はリスクと労力が予測できないため更新を先延ばしにします。
Apollo風のツールは、アップグレードを例外ではなく日常業務にしようとします——大規模移行ではなくインフラの保守のように扱うのです。
現代のデプロイツールは、チームが隔離された環境で開発とテストを行い、同一のビルドを段階(dev → test → staging → production)で“昇格”させることを可能にします。この分離により、環境差分による直前の驚きを減らせます。
価値実現までの時間は、単に「どれだけ速くインストールできるか」ではなく、チームがどれだけ速く定義で合意し、散らかったデータを繋ぎ、インサイトを日常の意思決定に落とし込めるかにかかっています。
従来のエンタープライズソフトは設定重視です:定義済みのデータモデルとワークフローに自社を合わせます。
Palantir風のプラットフォームは通常、次の3つのモードを混ぜます:
柔軟性が約束されますが、何を作るのかと何を標準化するのかを明確にする必要があります。
早期の探索段階では、ワークフローアプリを素早くプロトタイプするのが実用的です。例えば、チームはKoder.ai(vibe-codingプラットフォーム)を使って、ワークフロー記述をチャット経由で動作するWebアプリに変え、planning mode、snapshots、rollbackを使って利害関係者と反復できます。Koder.aiはソースコードのエクスポートと一般的な本番スタック(WebはReact、バックエンドはGo + PostgreSQL、モバイルはFlutter)をサポートするため、PoV期間中に「インサイト→タスク→監査証跡」のUXと統合要件を検証する低摩擦な方法になり得ます。
多くの工数は次の4つに集約されます:
注目すべきは不明確な所有権(責任あるデータ/プロダクトオーナーがいない)、過度に多いカスタム定義(各チームが独自指標を作る)、およびパイロットから本番への道筋がないこと(デモはできたが運用化、サポート、ガバナンスができない)です。
良いパイロットは意図的に狭く設計します:1つのワークフローを選び、特定のユーザーを定義し、測定可能な成果にコミットします(例:対応時間を15%短縮、例外バックログを30%削減)。パイロットは同じデータ、セマンティクス、制御が次のユースケースにも適用できるように設計してください——最初からやり直す必要のない形で。
この記事では「Palantir」は、プラットフォーム型アプローチを指す略称として使っています。典型的には次の要素を含みます:Foundry(商用のデータ/運用プラットフォーム)、Gotham(パブリックセクター/防衛系での系譜)、およびApollo(多様な環境へ配布・運用するためのデリバリ/デプロイ基盤)。
「従来のエンタープライズソフトウェア」は、より一般的な“組み合わせて使う”スタックを指します:ERP/CRM+データウェアハウス/レイク+BI+ETL/ELT/iPaaSや統合ミドルウェア。これらは別々のチームによって所有され、プロジェクトやガバナンスプロセスを通じて連携することが多いです。
セマンティックレイヤーは、ビジネス上の意味を一度だけ定義して(たとえば「注文」「顧客」「オンタイム配送」など)、それを分析やワークフロー全体で再利用するための仕組みです。
オントロジーはこれをさらに進め、次のようなモデリングを行います:
実務上の利点は、ダッシュボードやアプリ、チーム間での定義の不整合が減り、定義変更時の責任所在が明確になることです。
従来のETL/ELTはしばしばリレーレースのようになります:ソース抽出 → 変換 → ウェアハウスモデル → ダッシュボード、と段階ごとに別の担当が関与します。
典型的な失敗パターンは:
Palantir風のパターンは意味(セマンティクス)を早期に標準化し、キュレートされたオブジェクトを再利用することで、重複ロジックを減らし変更管理を明確にします。
BIダッシュボードは主に**振り返りとモニタリング(observe and explain)**に向いています:KPIの監視、定期更新、事後の原因分析など。
一方、オペレーショナルアナリティクスは**その場での意思決定と実行(decide and do)**を目指します:
出力が「チャート」で終わるならそれはBI、出力が「次に何をすべきか、そしてその場で実行できること」ならオペレーショナルアナリティクスです。
ワークフロー中心のシステムは、インサイトと実行の間のギャップを短縮し、分析を実際の作業が行われる場所に埋め込みます。
実務では次のような置き換えになります:
目的は見た目を良くすることではなく、より速く、監査可能な意思決定を可能にすることです。
「人間が介在する(human-in-the-loop)」とは、システムが推奨を出せても人が明示的に承認・上書きすることを意味します。
これが重要な理由:
規制の厳しい分野や重大な判断が伴う運用では、無条件の自動化は受け入れられないため特に重要です。
ガバナンスは単なるログイン管理ではありません。信頼できる数字を作り、安全に共有し、実際の意思決定に使えるようにするための実務的ルールと証拠一式です。
少なくとも次をカバーする必要があります:
堅牢なガバナンスがあると、チームはスプレッドシートの中身で争う時間を減らし、インサイトに基づいて行動できるようになります。
展開先の選択は、速度、管理性、運用負荷に直接影響します:
展開は柔軟性(クラウド)、制御(オンプレ/エアギャップ)、変更の速さ(自動化+アップデート)のトレードオフです。居住性ルール、ネットワークの現実、どの程度プラットフォーム運用を自社で担うかで判断します。
“Apollo風のデリバリ”は、制約のある高リスク環境向けの継続的デリバリに相当します:頻度高く改善を出しつつ運用を安定させることが目的です。
ポイントは「速く壊す」ではなく「頻繁に動かしても壊さない」ことです。運用アナリティクスでは、ソフトウェアはUIだけでなくデータパイプライン、ビジネスロジック、現場のワークフローを含むため、安全なアップデートプロセスが日常業務の一部になります。
考えるべき項目:ロールバックの方法、パイプライン/モデル/オントロジー変更のバージョニング、環境昇格の承認フロー、カナリアリリースや機能フラグの可否、誰がいつ何をデプロイしたかの監査証跡など。
スケーラブルなPoV(Proof of Value)は範囲を狭く、運用に直結させるべきです。
実務的な構成例:
汎用的なダッシュボードをパイロット目標にしてしまうと、実運用への移行が困難になるので避けてください。