2025年9月02日·2 分
API における Protobuf と JSON:速度、サイズ、互換性
API 用の Protobuf と JSON を比較:ペイロードサイズ、速度、可読性、ツール、バージョニング、実製品でどちらが適するかを解説します。
Protobuf と JSON が何で、なぜ重要か
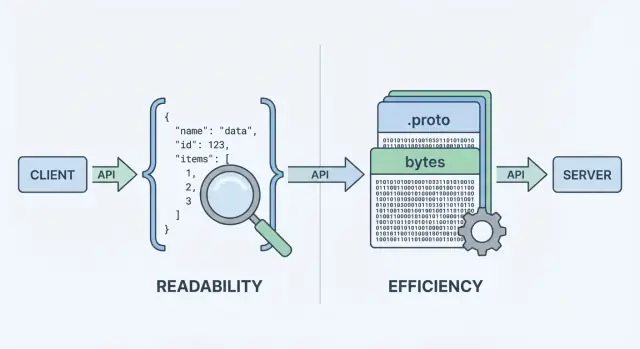
API がデータを送受信するとき、リクエスト/レスポンス本体で情報を表現するためのデータ形式が必要です。その形式はネットワークで送るためにシリアライズ(バイト列化)され、クライアントとサーバーでデシリアライズされて元のオブジェクトになります。
よく使われる選択肢の二つは JSON と Protocol Buffers(Protobuf) です。どちらも同じ業務データ(ユーザー、注文、タイムスタンプ、アイテムのリストなど)を表現できますが、パフォーマンス、ペイロードサイズ、開発ワークフローという点で異なるトレードオフをします。
JSON:人間が読めるテキスト
JSON(JavaScript Object Notation) はオブジェクトや配列のようなシンプルな構造からなるテキストベースの形式です。REST API ではログや確認がしやすく、curl やブラウザの DevTools といったツールで簡単に扱えるため広く使われています。
多くの言語でサポートが充実しており、レスポンスをそのまま見てすぐ理解できるのが大きな利点です。
Protobuf:スキーマを持つコンパクトなバイナリ
Protobuf は Google によって作られたバイナリシリアライズ形式です。テキストではなく、スキーマ(.proto ファイル)で定義されたコンパクトなバイナリ表現を送ります。スキーマはフィールド、型、そして数値タグを記述します。
バイナリかつスキーマ駆動であるため、Protobuf は一般に小さいペイロードを生成し、解析が速いことが多いです。大量のリクエストがある場合、モバイル回線やレイテンシに敏感なサービス(多くは gRPC と組み合わせられますがそれに限定されません)では重要になります。
同じデータ、異なるコスト
「何を送るか」と「どうエンコードするか」は切り離して考えるべきです。id、name、email を持つ “user” は JSON と Protobuf の両方で表現できます。違いは次のコストです:
- ペイロードサイズ(テキスト vs コンパクトバイナリ)
- シリアライズ/デシリアライズにかかる CPU 時間
- デバッグと可観測性(可読なログ vs バイナリ用ツール)
- 互換性と進化(任意の JSON 慣習 vs 明示的なスキーマ)
万人向けの正解はありません。公開 API ではアクセス性と柔軟性から JSON がデフォルトになりがちです。内部のサービス間通信や、パフォーマンス重視、厳格な契約が必要な場面では Protobuf が適していることが多いです。このガイドは制約に基づいて選ぶ助けになることを目指しています。
API データがどのようにシリアライズされ送信されるか
API がデータを返すとき、そのまま “オブジェクト” を送るわけにはいきません。まずバイト列に変換する必要があります。これが シリアライズ—データを送れる形にパッキングすることです。受け取り側はその逆を行い、バイト列を使えるデータ構造に戻します(デシリアライズ)。
サーバーからクライアントまでの簡単な流れ
典型的なリクエスト/レスポンスの流れは次の通りです:
- サーバーがレスポンスを組み立てる(メモリ上の型/オブジェクト)。
- シリアライザがそれをエンコードしてペイロードにする(JSON テキストか Protobuf バイナリ)。
- ペイロードは HTTP/1.1、HTTP/2、または HTTP/3 としてバイト列で送られる。
- クライアントがバイト列を受け取り、それを自分のメモリ上の型に デコードする。
エンコードの段がフォーマット選択が効いてくる部分です。JSON は { "id": 123, "name": "Ava" } のような可読テキストを生成します。Protobuf はツールがないと人間に意味のある形では見えないコンパクトなバイナリになります。
なぜ形式がパフォーマンスやワークフローを変えるのか
全てのレスポンスでパッキングとアンパッキングが必要なため、形式は次の点に影響します:
- 帯域(ペイロードサイズ): 小さいペイロードは転送コストを下げ、モバイルや高トラフィックで有利です。
- レイテンシ: 送るデータが少なければ応答が速くなり、エンコード/デコードが速ければ CPU 時間を削れます。
- 開発ワークフロー: JSON は DevTools やログで簡単に見ることができます。Protobuf は通常生成コードや専用のデコーダが必要です。
API スタイルが選択を後押しすることがある
API のスタイルは選択に影響します:
- REST スタイルの JSON API は、広くサポートされていて
curlでテストしやすく、ログや検査が簡単なので JSON が選ばれがちです。 - gRPC はデフォルトで Protobuf を前提に設計されています。HTTP/2 とコード生成の流れが Protobuf メッセージに合います。
JSON を gRPC で使う(トランスコーディング経由)ことも、単純な HTTP 上で Protobuf を使うことも可能ですが、フレームワークやゲートウェイ、クライアントライブラリ、デバッグ習慣といったスタックの既定の扱いやすさが日々の運用を左右します。
ペイロードサイズと速度:一般に得られるものと失うもの
「protobuf vs json」を比べるとき、多くはペイロードの大きさとエンコード/デコードにかかる時間を基準にします。結論は単純:JSON はテキストで冗長になりがち、Protobuf はバイナリでコンパクトになりがちです。
ペイロードサイズ:コンパクトなバイナリ vs 読みやすいテキスト
JSON はフィールド名を繰り返し、数値や真偽値をテキストで表現するため、ワイヤ上で送るバイト数が多くなる傾向があります。Protobuf はフィールド名を数値タグに置き換え、値を効率的にパックするため、特に大きなオブジェクト、繰り返しフィールド、深いネストで顕著に小さくなることが多いです。
ただし 圧縮は差を縮める ことがあります。gzip や brotli をかけると JSON の繰り返しキーはよく圧縮されるため、実運用でのサイズ差は小さくなることがあります。Protobuf も圧縮できますが、相対的なメリットは小さくなる傾向があります。
CPU コスト:テキストのパース vs バイナリのデコード
JSON パーサはトークン化と検証、文字列から数値への変換、エスケープ処理や Unicode 対応などを行う必要があります。Protobuf のデコードはより直接的で、タグを読み型に応じて値を読む流れです。多くのサービスで Protobuf は CPU 時間とガベージを減らし、負荷時のテールレイテンシを改善します。
ネットワークのインパクト:モバイルや高レイテンシ回線
モバイル回線や高レイテンシのリンクでは、少ないバイト数が速い転送と短い無線 ON 時間(バッテリー節約にも寄与)を意味します。しかしレスポンスがすでに小さい場合は、ハンドシェイクや TLS、サーバー処理が支配要因になるため形式の差が目立たないことがあります。
自分のシステムでベンチマークする方法
実際のペイロードで測定してください:
- 代表的なリクエスト/レスポンス(小さいもの、典型的なもの、最悪ケース)を選ぶ。
- 比較する指標:生のサイズ、圧縮後のサイズ(gzip/brotli)、エンコード/デコード時間、エンドツーエンドのレイテンシ。
- 実際の並列負荷で p50/p95/p99 を記録する。
こうすると「API シリアライゼーション」の議論があなたの API に合ったデータに基づく判断になります。
開発者体験:可読性、デバッグ、ログ
開発者体験では JSON がデフォルトで優位なことが多いです。JSON のリクエストやレスポンスはブラウザ DevTools、curl、Postman、リバースプロキシ、プレーンテキストログなどでほぼそのまま確認できます。問題が起きたとき、「実際に何を送ったか」はコピー&ペーストで再現できることが多いです。
Protobuf は異なります:コンパクトで厳格ですが人間には読みづらい。生の Protobuf バイトをログに残すと base64 や不可読バイナリになるため、ペイロードを理解するには対応する .proto スキーマとデコーダが必要です(protoc、言語別ツール、生成コードなど)。
実際のデバッグワークフロー
JSON なら問題再現が簡単:ログからペイロードを取り出し、シークレットを伏せて curl で再生すると最小のテストケースに近づけます。
Protobuf では通常:
- バイナリペイロードをキャプチャ(多くは base64 エンコード)し、
- 正しいスキーマバージョンでデコードし、
- 再エンコードしてリプレイする、
という手順になります。この追加ステップはチームに繰り返し可能なワークフローがあれば管理可能です。
Protobuf(と JSON)をデバッグしやすくするコツ
構造化ログは両形式で有効です。リクエスト ID、メソッド名、ユーザー/アカウント識別子、重要フィールドなどをログに残し、全文ではなくキー情報をログすることを推奨します。
Protobuf 向けには:
- デコードして不要情報を伏せた“デバッグ表示”(多くは JSON 表現)をバイナリの横にログする。
- ログに スキーマバージョンやメッセージタイプ を残し、どの
.protoを使ったか分かるようにする。 - オンコールで使える小さな内部スクリプト(「この base64 ペイロードを正しいスキーマでデコードする」)を用意する。
JSON については、差分やインシデントタイムラインを読みやすくするために 正規化された JSON(キー順序を安定化)をログすることを検討してください。
スキーマと型安全性:柔軟性 vs ガードレール
API は単にデータを運ぶだけでなく、意味を運びます。JSON と Protobuf の最大の違いは、その意味がどれだけ明確に定義・強制されるかです。
JSON:形が柔軟で解釈も柔軟
JSON はデフォルトでは “スキーマレス” です:任意のフィールドを送れますし、多くのクライアントは見た目が妥当であれば受け入れます。
この柔軟性は初期段階では便利ですがミスを隠しやすく、よくある落とし穴は:
- 不整合なフィールド名: あるレスポンスでは
userId、別ではuser_id、またはコードパスによってフィールドが欠ける。 - stringly-typed なデータ: 数値や真偽値、日付を文字列で送る(例:
"42"、"true"、"2025-12-23")。 - 曖昧な null の意味:
nullが “不明”、“設定されていない”、“意図的に空” のどれを意味するかが曖昧。
JSON Schema や OpenAPI などを導入できますが、JSON 自体は消費側に従わせる仕組みを強制しません。
Protobuf:.proto による明示的な契約
Protobuf は .proto ファイルでスキーマを必須にします。スキーマは:
- どのフィールドがあるか、
- その型(string、integer、enum、message など)、
- ワイヤ上で各フィールドを識別する番号、
を示します。
この契約は意図しない変更(例:整数を文字列に変える)を防ぐのに有効で、生成コードが特定の型を期待するため早期にエラーが出やすくなります。
実務で重要な型安全性の点
Protobuf では 数値は数値のまま、enum は既知の値に限定され、タイムスタンプはよく知られた型を使って扱うことが一般的です。proto3 では optional フィールドやラッパー型を使うことで「未設定」が既定値と区別できるため、あいまいさが減ります。
複数チームや多言語にまたがる API で正確な型と予測可能なパースが重要なら、Protobuf は有効なガードレールを提供します。
クライアントを壊さずにスキーマを進化させる
作ったものでクレジットを獲得
小さなデモを作り、結果共有やチーム招待でクレジットを獲得。
API は進化します:フィールドを追加したり振る舞いを変更したり古い部分を廃止したりします。目標はクライアントを驚かせずに契約を変えることです。
後方互換性と前方互換性(平易な説明)
- 後方互換性: 新しいサーバーが古いクライアントと通信できる。古いクライアントは理解できない部分を無視して動作を続けられる。
- 前方互換性: 新しいクライアントが古いサーバーと通信できる。新しいクライアントは欠けているフィールドを扱って既定値にフォールバックできる。
両方を目指すのが理想ですが、最低限後方互換性を保つことが一般的です。
Protobuf:フィールド番号が実体
Protobuf では各フィールドの 番号(例:email = 3)がワイヤ上の実体です。名前は主に人間と生成コードのためです。
そのため:
-
安全な変更(通常)
- 新しい未使用の番号でオプショナルなフィールドを追加する。
- enum に新しい値を追加する(既存の並びを壊さないよう注意)。
- フィールドを非推奨にして番号を予約しておく。
-
危険な変更(しばしば破壊的)
- 既存の番号を別の意味や型で再利用する。
- 互換性のない型変更(例:string → int)。
- フィールドを削除して番号を予約しない(将来的に再利用すると意味が壊れる)。
- 名前変更はワイヤ上は安全だが生成コードや下流の仮定を壊す可能性がある。
ベストプラクティス:古い番号や名前は reserved にし、変更履歴を残す。
JSON:慣習と運用の上に立つバージョニング
JSON は組み込みのスキーマがないため互換性はパターンと規律で決まります:
- 加法的変更(新しいフィールドを追加)を優先する。
- 未知のフィールドは無視し、欠けているフィールドは「妥当なデフォルト」を使うようにクライアントを実装する。
- 型を変えない(数値→文字列など)ようにする。必要なら新しいフィールド名を追加する。
廃止と明確なポリシー
フィールドを廃止する場合は早めにドキュメント化し、いつまでサポートするか、代替は何かを示してください。簡単なバージョニングポリシー(例:「加法的変更は破壊的でない。削除はメジャーバージョンの変更」)を公開して守ることが重要です。
プラットフォーム横断のツールとエコシステムサポート
JSON と Protobuf のどちらを選ぶかは、API をどこで動かすか、チームが何を維持したいかに大きく依存します。
ブラウザ vs サーバー:JSON の「既定値」優位
JSON は事実上ユニバーサルです:ブラウザもバックエンドも追加依存なしで解析できます。Web アプリでは fetch() + JSON.parse() がそのまま使え、プロキシや API ゲートウェイ、可観測性ツールも JSON を標準的に扱うことが多いです。
Protobuf をブラウザで使うことも可能ですがコストはゼロではありません。通常は Protobuf ライブラリや生成された JS/TS コードを追加し、バンドルサイズを管理し、ブラウザのツールで検査しづらくなる点を考慮する必要があります。
モバイルとバックエンド SDK:Protobuf の強み
iOS/Android や Go、Java、Kotlin、C#、Python といったバックエンド言語では Protobuf のサポートが成熟しています。Protobuf はプラットフォームごとにライブラリを使い、通常 .proto ファイルからコードを生成するワークフローを想定します。
コード生成がもたらす利点:
- 型付きモデルと enum、契約からの早期検出
- 高速なシリアライズライブラリとサービス間での一貫したデータ形状
同時にコストもあります:
- ビルド手順(CI でのコード生成、生成物の同期)
- リポジトリ/プロセスの複雑化(共有
.protoパッケージの公開、バージョンピン)
gRPC:整ったエコシステム、制約もある
Protobuf は gRPC と密接に結びついており、サービス定義、クライアントスタブ、ストリーミング、インターセプタなどを含む完全なツールチェーンが得られます。gRPC を検討しているなら Protobuf は自然な選択です。
従来の JSON REST API を作るなら、公開 API や簡易な連携の面で JSON のツール群(ブラウザ DevTools、curl によるデバッグ、汎用ゲートウェイ)がシンプルです。
早すぎず両方を試すプロトタイピング
API の表面をまだ模索中なら、両方を素早くプロトタイプしてから標準化するのが有効です。例えば、チームが Koder.ai のようなプラットフォームを使う場合、幅広い互換性のために JSON REST API を立ち上げつつ、内部では gRPC/Protobuf を使って効率化し、実際のペイロードをベンチマークしてどちらをデフォルトにするか決める、という選択ができます。Koder.ai はフルスタック生成やスナップショット/ロールバックをサポートするので、契約を素早く繰り返し検証できます。
運用面の適合性:キャッシュ、ゲートウェイ、可観測性
エンドポイントと進化を計画
実装コードを生成する前に、エンドポイント、フィールド、デフォルト、バージョニングルールを設計。
JSON と Protobuf の選択は単にサイズや速度だけでなく、キャッシュ層、ゲートウェイ、インシデント中に頼るツール群との親和性にも影響します。
キャッシュと CDN
ほとんどの HTTP キャッシュ(ブラウザキャッシュ、リバースプロキシ、CDN)は HTTP の意味論を最適化しており、特定の本文形式に依存しません。CDN はレスポンスがキャッシュ可能であれば 任意のバイト列をキャッシュできます。
とはいえ多くのチームはエッジで JSON を期待します。Protobuf でもキャッシュは機能しますが、注意点は:
- キャッシュキー(URL、クエリ、特に
Vary)の設計 Cache-Control、ETag、Last-Modifiedなどキャッシュ性ヘッダの明示- 複数フォーマットをサポートするときのキャッシュ断片化を避ける設計
コンテンツネゴシエーション(Content-Type と Accept)
JSON と Protobuf の両方をサポートする場合はコンテンツネゴシエーションを使いましょう:
- クライアントは
Accept: application/jsonまたはAccept: application/x-protobufを送る。 - サーバーはそれに合った
Content-Typeを返す。
キャッシュがこれを正しく扱うように Vary: Accept を設定してください。さもないとキャッシュが JSON レスポンスを Protobuf クライアントに返してしまうことがあります。
ゲートウェイ、プロキシ、可観測性ツール
API ゲートウェイ、WAF、リクエスト/レスポンス変換器、可観測性ツールは多くの場合 JSON ボディを前提にしています:
- リクエストバリデーションやスキーマチェック
- フィールド単位のログやマスキング
- ペイロードから派生するメトリクス
- ダッシュボードやトレースビューでのデバッグ
バイナリ Protobuf はツールが Protobuf を理解していないとこれらの機能を制限します。デコードステップを追加するオプションもありますが、運用コストが増えます。
混在環境への実務的ガイダンス
よくあるパターンは エッジで JSON、内部は Protobuf です:
- 公開 REST エンドポイント:互換性と運用性のために JSON
- 内部サービス間:効率化のために Protobuf(多くは gRPC)
これにより外部連携は簡単に保ちつつ、制御可能な内部通信で Protobuf の利点を活かせます。
セキュリティと信頼性の考慮点
JSON や Protobuf を選ぶことでデータのエンコード/パース方法が変わりますが、認証、暗号化、認可、サーバー側検証といった基本的なセキュリティ要件に取って代わるものではありません。高速なシリアライザがあっても、未検証の入力を受け付ける API を救うわけではありません。
形式選択はセキュリティ層ではない
Protobuf がバイナリで可読性が低いから安全だと考えるのは誤りです。攻撃者はペイロードが人間に読めるかどうかを気にしません。エンドポイントの脆弱性、認証の弱さ、検証の欠如が問題です。TLS、認可チェック、入力の検証、ロギングの安全性は形式に関係なく徹底してください。
攻撃面:ペイロード、パーサ、バリデーション
両形式は共通のリスクを持ちます:
- 過度に大きなペイロード: 大きな JSON ドキュメントや巨大な Protobuf メッセージはメモリ圧迫やパース遅延、DoS を引き起こす可能性があります。
- パーサのバグ: 全てのパーサはコードであり、脆弱性を持ちうるため、ライブラリの選択と更新が重要です。
- スキーマバリデーションのギャップ: JSON は柔軟なため想定外のフィールドや型を受け入れがちです。一方 Protobuf は型制約を持ちますが、業務ルール上の不正(負の数量、無効な状態など)は依然としてサーバー側で検査する必要があります。
信頼性:制限、タイムアウト、厳格さ
信頼性を保つには両形式で同様のガードレールを適用してください:
- 最大リクエストサイズ/メッセージサイズ を設定する(圧縮後のサイズも含めて考える)。
- タイムアウト と キャンセル を使い、低速クライアントや遅いパーサによる資源枯渇を防ぐ。
- 厳格なバリデーション を行い、ビジネス必須フィールドや値の範囲、enum の未知値を拒否する。
- ログ設計に注意する: JSON は確認が容易ですが、どちらの形式でも生のペイロードを不用意にログして機密情報を漏らさないようにする。
要するに「バイナリ vs テキスト」は主にパフォーマンスと使い勝手に関わる話であり、セキュリティと信頼性は明確な制限と依存関係管理、バリデーションで確保する必要があります。
JSON を選ぶべき時と Protobuf を選ぶべき時
どちらが「良い」かではなく、API が何を最適化すべきか(人間に優しい広い互換性か、効率性と厳格さか)で決めるべきです。
JSON がデフォルトで適している場面
JSON は互換性の広さとデバッグのしやすさが必要なときの安全なデフォルトです。典型的なシナリオ:
- クライアントがコントロールできない公開 API(パートナーやサードパーティ)
- ブラウザや Web クライアント(標準で JSON を扱える)
- 早期のプロダクト開発(手間が少なく素早く回せる)
- デバッグ重視のワークフロー(コピペで再現、読みやすいログ、
curlテスト) - 広くプロキシやゲートウェイにかける REST エンドポイント
Protobuf が有利な場面
Protobuf は可読性より効率と一貫性が重要な場面で有利です。典型的なシナリオ:
- 帯域やコストが重要な高スループット API
- 小さい呼び出しが多くチャッティなサービス群
- 両端を管理できる内部マイクロサービス
- gRPC ベースのシステム(Protobuf が自然で強力なツール群を得られる)
- モバイルやエッジ環境でペイロード削減がレイテンシ・バッテリーに効く場合
決定を絞るための質問
次の質問で選択を絞ってください:
- 誰が API を消費するか? 外部/公開クライアントが多ければ JSON 優位。
- 全クライアントとデプロイをコントロールできるか? できるなら Protobuf 採用が楽。
- パフォーマンスが実際のボトルネックか? 測定(p95 レイテンシ、CPU、転送コスト)。
- 厳格な型とスキーマ契約が重要か? Protobuf がガードレールを提供する。
- ツール群は成熟しているか? コード生成、CI、オンボーディングを考える。
悩む場合の現実的な妥協は「エッジは JSON、内部は Protobuf」です。
マイグレーション戦略:JSON と Protobuf の間を移行する方法
生成したコードを自分のものに
ソース全体をエクスポートして、API 契約と生成型をリポジトリで管理。
形式の移行は全体を書き換えることより、消費者へのリスクを下げることが主眼です。安全な移行は API を通電し続けたまま元に戻せることがポイントです。
1) 小さく始める:一つのエンドポイントか一つの内部サービス
リスクの低い領域(内部のサービス間呼び出しや読み取り専用のエンドポイント)を選んで、スキーマや生成クライアント、可観測性の変化を検証します。既存リソースに対して Protobuf 表現を追加し、JSON 形状はそのままにしておくのが現場で学ぶ早道です。
2) 並行運用(しばらく両方を走らせる)
外部 API では二刀流サポートが滑らかな移行になります:
Content-TypeとAcceptヘッダで形式を交渉する。- ツールで交渉が難しければ別エンドポイント(例:
/v2/...)を一時的に公開する。
この期間は両方を同じソースオブトゥルースから生成してドリフトを防いでください。
3) 形式変更を製品変更としてテストする
計画すべきは:
- 互換性テスト: 古いクライアント vs 新しいサーバー、新しいクライアント vs 古いサーバー。
- 契約テスト: 必須フィールドやデフォルト挙動、エラー挙動の検証。
- ベンチマーク: ペイロードサイズ、CPU、レイテンシ(圧縮・TLS を含む)。
4) スキーマを文書化し例を出す
.proto ファイル、フィールドコメント、具体的なリクエスト/レスポンス例(JSON と Protobuf 両方)を公開して、消費者が正しく解釈できるようにしてください。短い移行ガイドと変更履歴はサポート負荷を減らし採用を早めます。
実務的なベストプラクティスと簡単チェックリスト
形式選択は理念よりもトラフィック、クライアント、運用制約に基づくことが多いです。最も信頼できる道は測定し決定を文書化し、API 変更を退屈に(安定に)保つことです。
最適化の前に測定する
代表エンドポイントで小さな実験を実行してください。
追跡項目:
- ペイロードサイズ(中央値と p95)
- エンドツーエンドのレイテンシ
- シリアライズ/デシリアライズでの CPU とメモリ
- エラー率とタイムアウト
ステージングで本番に近いデータを使い、小さなトラフィックで本番でも検証してください。
スキーマと契約を予測可能に保つ
JSON Schema/OpenAPI や .proto を問わず:
- エンドポイントやフィールドで一貫した命名規則を使う。
- 明確なデフォルトを定義し文書化する。「欠けている」と「空」はクライアントを驚かせない。
- 加法的な変更を優先し、意味を変える変更は避ける。
- 廃止するフィールドは明示的に日付や移行ノートを付けてサポートを続ける。
開発者体験を第一に考える
Protobuf を選ぶ場合でも、ドキュメントは親切に:
- 例となるリクエスト/レスポンス(正例とエラー例)を載せる。
- よく使われる言語向けのコピペ可能なクライアント例を提供する。
- ログやツールでペイロードを確認する方法を文書化する。
ドキュメントや SDK ガイドには /docs や /blog のような相対パスでリンクし、料金や利用制限が形式選択に影響するなら /pricing を明示してください。
クイックチェックリスト
- 代表エンドポイントでペイロードサイズ+p95 レイテンシ+エラー率を測定した
- フィールド命名は一貫しており、デフォルト挙動を文書化している
- 加法的変更を優先し、廃止は日付と移行ノートを付けている
- ドキュメントに例があり、クライアントスニペットを用意している
- 選択した形式に対してログ/トレースが機能する可観測性計画がある
よくある質問
API における JSON と Protobuf の実務上の違いは何ですか?
JSON は読みやすく、ログ取りや一般的なツールでのテストが容易なテキスト形式です。Protobuf は .proto スキーマで定義されるコンパクトなバイナリ形式で、しばしばペイロードが小さくパースが速いという利点があります。
用途で選んでください:到達性とデバッグのしやすさ(JSON)か、効率性と厳格な契約(Protobuf)か。
リクエスト/レスポンスの流れで「シリアライズ」と「デシリアライズ」は何を意味しますか?
API はメモリ上のオブジェクトをそのまま送れないため、まずバイト列に変換する必要があります。シリアライズはサーバー側のオブジェクトをペイロード(JSON テキストや Protobuf バイナリ)にエンコードする処理、デシリアライズは受け取ったバイト列をオブジェクトに戻す処理です。
フォーマットの選択は帯域、遅延、エンコード/デコードにかかる CPU に影響します。
Protobuf は常に JSON よりもワイヤ上で小さいですか?
多くの場合は小さくなります。特に大きなネストや繰り返しフィールドがある場合、Protobuf はフィールド名を数値タグに置き換え効率的なバイナリ表現を使うため有利です。
ただし gzip や brotli を有効にすると JSON の繰り返しキーはよく圧縮されるため、実運用では差が縮むことがあります。生のサイズと圧縮後のサイズの両方を測定してください。
エンコード/デコードやレイテンシで Protobuf は JSON より速いですか?
なることが多いです。JSON パーサはテキストをトークン化しエスケープや Unicode を扱い、文字列から数値への変換などを行います。Protobuf は「タグ → 型付き値」を直接読むため、CPU 時間や割り当てを減らせることが多いです。
ただしレスポンスが非常に小さい場合は、TLS やネットワーク RTT、アプリ処理が遅延の支配要因になるため、シリアライズ差が目立たないことがあります。
なぜ Protobuf は JSON よりデバッグやログ取りが難しいのですか?
既定では難しいからです。JSON は人間が読めて DevTools、ログ、curl、Postman などで簡単に確認できます。Protobuf はバイナリなので生のペイロードをログに残すと base64 や不可読なバイナリになります。正しい .proto スキーマとデコーダがないと中身が見えません。
改善策としては、デコードして不要な情報を隠した “デバッグ表示”(多くは JSON)をバイナリと一緒にログする、スキーマバージョンをログに残す、小さなデコードスクリプトを用意する、などが有効です。
JSON と Protobuf のスキーマや型安全性はどう違いますか?
JSON はデフォルトではスキーマレスです。任意のオブジェクトを送れる反面、フィールド名の不整合、数値や日付を文字列で送る「stringly-typed」な問題、null の意味の曖昧さなどが起きやすいです。
一方 Protobuf は .proto ファイルで明示的にスキーマを定義します。型が強制され、enum やタイムスタンプの取り扱いが統一されやすく、複数言語間での挙動のずれを減らせます。
JSON と Protobuf でクライアントを壊さずにスキーマ進化させるには?
Protobuf では各フィールドに数値タグ(例: email = 3)が割り当てられており、ワイヤ上での識別はこのタグが行います。安全な変更は通常「新しい番号でオプショナルなフィールドを追加する」ことです。破壊的な変更には番号の再利用や型の互換性のない変更が含まれます。削除したフィールドの番号は reserved で確保するのがベストプラクティスです。
JSON は組み込みのスキーマを持たないため、互換性は運用ルールに依存します。一般に加法的な変更(フィールド追加)を推奨し、型変更は避け、既存フィールドの意味を変えない方針が安全です。
選択に影響するツールやプラットフォームの制約は何ですか?
環境によります。ブラウザや公開 API では JSON はほぼ無条件でサポートされツールも充実しています。モバイルやバックエンドでは Protobuf のライブラリやコード生成のサポートが成熟しており、gRPC を使うなら Protobuf が自然な選択です。
Protobuf はコード生成や CI、共有 .proto のバージョン管理など運用コストが増えるため、そのトレードオフも考慮してください。
Protobuf を選ぶとセキュリティや信頼性は向上しますか?
フォーマットを変えたからといってセキュリティや信頼性が自動的に向上するわけではありません。どちらの形式でも次のようなガードレールが必要です:最大リクエストサイズの制限、タイムアウトとキャンセル、業務ルールの厳格なバリデーション、機密情報を出さないログ設計。
Protobuf がバイナリだからといって安全という認識は誤りです。依然として TLS、認可、入力検証を徹底してください。