2025年8月13日·1 分
分散システムの概念:KleppmannのSaaSスケーリングの考え方
プロトタイプを信頼できるSaaSにする際にチームが直面する現実的な選択(データフロー、一貫性、バックプレッシャー)を基礎概念で解説します。
プロトタイプを信頼できるSaaSにする際にチームが直面する現実的な選択(データフロー、一貫性、バックプレッシャー)を基礎概念で解説します。
プロトタイプはアイデアを証明します。SaaSは実際の利用(ピークトラフィック、汚れたデータ、リトライ、ユーザーが気づく小さな不具合)を生き延びなければなりません。ここで混乱が生まれます。質問が「動くか?」から「動き続けるか?」に変わるからです。
実ユーザーがいると「昨日は動いていた」がつまらない理由で破綻します。バッチジョブが遅れて走る。ある顧客がテストデータの10倍の大きさのファイルをアップロードする。決済プロバイダが30秒止まる。どれも珍しい話ではありませんが、システムの部品が互いに依存し始めると波及効果が大きくなります。
複雑さは主に四つの場所に現れます:データ(同じ事実が複数箇所にあり乖離する)、レイテンシ(50msの呼び出しが時々5秒になる)、障害(タイムアウト、部分的更新、リトライ)、そしてチーム(異なる人が異なるスケジュールでサービスを出す)。
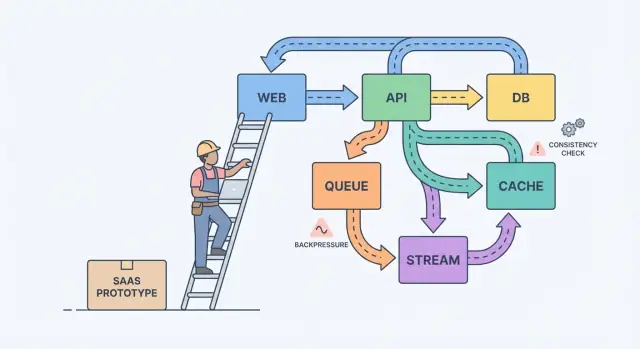
シンプルなメンタルモデルが役に立ちます:コンポーネント、メッセージ、状態。
コンポーネントは仕事をします(Webアプリ、API、ワーカー、データベース)。メッセージはコンポーネント間の仕事を移動させます(リクエスト、イベント、ジョブ)。状態はあなたが覚えているものです(注文、ユーザー設定、請求状況)。スケーリングの痛みはたいていミスマッチです:メッセージをコンポーネントが処理できる速度より速く送るか、状態を二か所で更新して真のソースが不明瞭になるか。
典型例は請求です。プロトタイプでは請求書を作り、メールを送り、ユーザーのプランを一つのリクエストで更新するかもしれません。負荷がかかるとメールが遅れ、リクエストがタイムアウトし、クライアントがリトライして二つの請求書と一つのプラン変更が生まれる。信頼性向上の仕事は、こうした日常的な失敗が顧客の目に触れるバグにならないようにすることです。
多くのシステムが難しくなるのは、何が正しくあるべきか、何が速いことを優先すべきか、障害時に何をすべきかについて合意がないまま成長するからです。
まずユーザーに約束する範囲を描いてください。その境界の中で「毎回正しくあるべきアクション」(お金の移動、アクセス制御、アカウント所有)に名前を付けます。次に「最終的に正しければよい領域」(分析カウント、検索インデックス、レコメンデーション)を名前にします。この一つの分割で曖昧な理論が優先順位になります。
次にソースオブトゥルースを書き下してください。事実が一度だけ確実に記録され、明確なルールで保たれる場所です。他はすべて速度や利便性のための派生データです。派生ビューが壊れたら、ソースオブトゥルースから再構築できるべきです。
チームが詰まったとき、以下の質問が何が重要かを明らかにします:
ユーザーが請求プランを更新したとき、ダッシュボードが遅れても構いません。しかし支払い状況と実際のアクセス権が矛盾することは許せません。
ユーザーがボタンを押してすぐに結果を見なければならない場合(プロフィール保存、ダッシュボード読み込み、権限確認)、通常のリクエスト—レスポンスAPIで十分です。直接的に保ってください。
作業を後で行えるなら非同期に移してください。メール送信、カード請求、レポート生成、アップロードのリサイズ、検索への同期などが該当します。ユーザーはそれを待つべきではなく、APIがその間占有されるべきでもありません。
キューはやることリストです:各タスクは一つのワーカーが一度だけ処理すべきです。ストリーム(またはログ)は記録です:イベントは順序を保って保存されるので複数のリーダーがリプレイしたり、追いついたり、新しい機能を作ったりできます。
実務的な選び方:
例:あなたのSaaSに「請求書作成」ボタンがあるとします。APIは入力を検証して請求書をPostgresに保存します。その後キューが「請求書メール送信」と「カード請求」を処理します。後でアナリティクス、通知、不正検知を追加するなら、InvoiceCreated イベントのストリームを用意すると各機能が購読でき、コアサービスが迷路化するのを防げます。
プロダクトが成長すると、イベントは「あるといい」から安全網になります。良いイベント設計は二つの質問に尽きます:どの事実を記録するか、そして他の部分が推測なしに反応できるか。
まず小さなビジネスイベントの集合から始めます。ユーザーや収益に関わる重要な瞬間を選んでください:UserSignedUp、EmailVerified、SubscriptionStarted、PaymentSucceeded、PasswordResetRequested。
名前はコードより長く残ります。完了した事実には過去形を使い、具体的にしてUI用語は避けてください。PaymentSucceeded は、クーポンやリトライ、複数の支払いプロバイダが後で増えても意味を保ちます。
イベントを契約として扱ってください。毎スプリント変わるフィールドの詰め合わせのような「UserUpdated」のような包括的イベントは避けましょう。長く保証できる最小の事実を公開する方が良いです。
安全に進化させるには、追加的変更(新しいオプションフィールド)を好み、破壊的変更が必要なら新しいイベント名(または明示的なバージョン)を公開し、古いコンシューマが消えるまで両方を走らせます。
何を保存すべきか?データベースに最新行だけを保持すると、そこに至る過程を失います。
生のイベントは監査、リプレイ、デバッグに優れます。スナップショットは高速な読み取りと迅速な復旧に向きます。多くのSaaSは両方を使います:重要なワークフロー(請求、権限など)には生のイベントを保存し、ユーザー向け画面にはスナップショットを維持します。
「プランを変えたのにまだFreeと表示される」や「招待を送ったのに同僚がまだログインできない」といった瞬間が一貫性として現れます。
強い一貫性は成功メッセージを受け取ったらすべての画面が即座に新しい状態を反映することを意味します。最終的な一貫性は変更が時間をかけて広がり、その短い間アプリの異なる部分が不一致になることを意味します。どちらが良いというものではなく、ミスマッチが生む被害の大きさで選びます。
強い一貫性は通常、お金、アクセス、安全性に適します:カード請求、パスワード変更、APIキー無効化、席数の制限の適用など。最終的な一貫性は活動フィード、検索、分析ダッシュボード、「最終アクセス」、通知などに当てはまることが多いです。
スタレネス(古さ)を受け入れるなら、それを隠すのではなく設計してください。UIに正直さを持たせ:書き込み後に確認が来るまで「更新中…」を出す、リストに手動更新を提供する、楽観的UIはロールバックが簡単にできる場合だけ使うといった具合です。
リトライは一貫性をややこしくします。ネットワークは落ち、クライアントはダブルクリックし、ワーカーは再起動します。重要な操作は冪等にして、同じ操作の繰り返しが二つの請求書や二重の招待、二重の返金を生まないようにしてください。一般的な方法は操作ごとの idempotency key と、同じキーのリクエストには元の結果を返すサーバ側のルールです。
バックプレッシャーは、リクエストやイベントがシステムの処理能力を超えて到着するときに必要です。これがないと作業がメモリに溜まり、キューが増え、最も遅い依存(多くの場合データベース)が全部の失敗の引き金になります。
平たく言うと:プロデューサが喋り続ける一方でコンシューマが溺れている状態です。受け入れを続ければ単に遅くなるだけではありません。タイムアウトとリトライの連鎖反応を引き起こし、負荷が倍増します。
警告サインは大抵アウト前に見えます:バックログだけが増え続ける、スパイクやデプロイ後にレイテンシが跳ねる、タイムアウトでリトライが増える、ある依存が遅くなると無関係なエンドポイントが失敗する、DB接続が枯渇している。
そのポイントに達したら、満杯のときに何が起きるかの明確なルールを選んでください。目標はすべてを処理することではなく、生き残って素早く回復することです。チームは通常一つか二つのコントロールから始めます:ユーザーやAPIキーごとのレート制限、定義されたドロップ/遅延ポリシーを持つ有界キュー、失敗する依存に対するサーキットブレーカー、インタラクティブなリクエストが背景ジョブより優先される優先度付け。
まずデータベースを保護してください。コネクションプールは小さく予測可能に保ち、クエリタイムアウトを設定し、アドホックレポートのような高コストなエンドポイントにハードリミットを置きます。
信頼性はめったに大規模な書き換えを必要としません。障害を可視化し、封じ込め、復旧可能にするいくつかの決定から来ることが多いです。
信頼を得たり失ったりするフローから始め、安全網を追加してから機能を増やしてください:
Map critical paths.(重要な経路をマップする) サインアップ、ログイン、パスワードリセット、決済フローの正確な手順を書き出してください。各ステップについて依存(DB、メールプロバイダ、バックグラウンドワーカー)を列挙します。これは何が即時であるべきか、何が「最終的に」修復可能かを明確にします。
Add observability basics.(観測性の基本を追加する) すべてのリクエストにログに載るIDを付与します。ユーザーの痛みに合った少数の指標(エラー率、レイテンシ、キュー深度、遅いクエリ)を追います。サービスを横断する要求だけにトレースを追加します。
Isolate slow or flaky work.(遅い/不安定な作業を切り離す) 外部サービスに依存するか、1秒以上かかることが常態化しているものはジョブとワーカーに移します。
Design for retries and partial failures.(リトライと部分失敗を設計する) タイムアウトは起きると想定してください。操作を冪等にし、バックオフを使い、時間制限を設け、ユーザー向けの操作は短く保ちます。
Practice recovery.(復旧を練習する) バックアップは復元できてこそ意味があります。小さなリリースを使い、素早いロールバック経路を保ってください。
ツールがスナップショットとロールバックをサポートしているなら(Koder.ai がそういった機能を持つなら)、それをインシデント時の裏技にするのではなく通常のデプロイ習慣に組み込みます。
クライアントのオンボーディングを助ける小さなSaaSを想像してください。フローは単純です:ユーザー登録、プラン選択、支払い、ウェルカムメールといくつかの「はじめに」ステップ受信。
プロトタイプではすべてが一つのリクエストで行われます:アカウント作成、カード課金、ユーザーの「有料」フラグ切替、メール送信。トラフィックが増え、リトライが発生し、外部サービスが遅くなると動かなくなります。
これを信頼できるものにするため、チームは主要なアクションをイベント化し、追記のみの履歴を保ちます。いくつかのイベントを導入します:UserSignedUp、PaymentSucceeded、EntitlementGranted、WelcomeEmailRequested。これにより監査トレイルが得られ、分析がしやすくなり、遅い作業をバックグラウンドで行ってもサインアップをブロックしません。
いくつかの選択が大部分の作業を片付けます:
PaymentSucceeded から権限を付与するときは明確な idempotency key を使い、リトライで二重付与されないようにする。支払いが成功したがアクセスがまだ付与されていないとユーザーは騙されたと感じます。解決は「どこでも完全な一貫性」にすることではありません。今すぐ一貫でなければならないものを決め、その決定をUIに反映して EntitlementGranted が来るまで「プランを有効化中」といった状態を表示することです。
悪い日はバックプレッシャーが差を生みます。マーケティングキャンペーン中にメールAPIが遅延すると、古い設計ではチェックアウトがタイムアウトしてユーザーがリトライし、二重課金や二重メールが発生します。改善された設計ではチェックアウトは成功し、メールリクエストはキューに溜まり、プロバイダが回復したらリプレイジョブがバックログを消化します。
ほとんどの障害は一つの壮大なバグが原因ではありません。プロトタイプで理にかなっていた小さな決定が習慣化したものです。
早すぎるマイクロサービス分割は典型的な落とし穴です。サービス同士が互いに呼び合うだけになり、所有権が不明確になり、変更が5回のデプロイを必要とするようになります。
別の落とし穴は「最終的な一貫性」を免罪符のように使うことです。ユーザーは用語を気にしません。Saveを押して後でページが古いデータを表示したり、請求書の状態が行ったり来たりすることを気にします。遅延を受け入れるなら、ユーザーフィードバック、タイムアウト、各画面での「十分良い」基準を定義する必要があります。
繰り返される他の過ち:再処理プランなしにイベントを公開する、インシデント中に負荷を増幅する無制限リトライ、すべてのサービスが同じDBスキーマに直接アクセスして一つの変更で多くのチームを壊すこと。
「本番準備済み」は深夜に指差せる決定群です。明確さは巧妙さに勝ります。
まずソースオブトゥルースに名前を付けます。各主要なデータタイプ(顧客、サブスクリプション、請求書、権限)について最終的なレコードがどこにあるか決めてください。アプリが二か所から「真」を読んでいるなら、いつか異なるユーザーに異なる答えを表示することになります。
次にリトライを確認します。重要なアクションはいつか二度走ると想定してください。同じリクエストが二度来ても二重課金、二重送信、二重作成を避けられますか?
多くの痛い失敗を捕まえる小さなチェックリスト:
もしプラットフォームがスナップショットとロールバックをサポートしているなら(Koder.ai のように)、それを通常のリリース習慣として使ってください。
システム設計は山のような理論ではなく、短い選択肢のリストとして扱うとスケールが楽になります。
今後一か月で直面しそうな決定を3〜5つ、平易な言葉で書き出してください:「メール送信をバックグラウンドジョブに移すか?」「分析は少し古くても許容するか?」「どのアクションを即時一貫性にするか?」そのリストでプロダクトとエンジニアリングを揃えます。
次に、現在同期的なワークフローを一つ選び、それだけを非同期に変換してみてください。領収書、通知、レポート、ファイル処理が一般的な初手です。前後で二つのことを計測してください:ユーザー向けレイテンシ(ページは速く感じるか?)と障害挙動(リトライが重複や混乱を生んでいないか)。
これらの変更を素早くプロトタイプしたければ、Koder.ai (koder.ai) は React + Go + PostgreSQL ベースのSaaSを反復しつつ、ロールバックやスナップショットを近くに保てるので役立ちます。基準はシンプル:一つの改善を出荷し、実際のトラフィックで学び、次を決める。
プロトタイプは「作れるか?」に答えます。SaaSは「ユーザーやデータ、障害が出ても動き続けるか?」に答える必要があります。
最も大きな変化は、次の点に対する設計です:
ユーザーに約束する範囲を決め、その中で影響の大きいアクションをラベル付けします。
まず「毎回正しくあるべきもの」から始めてください:
次に「最終的に正しければよいもの」をマークします:
短い決定書として書き残せば、皆が同じルールで実装できます。
各“事実”を一度だけ記録し最終的なものとして扱う場所を一つ選びます(小さなSaaSなら多くの場合Postgres)。それがソースオブトゥルースです。
他のものは速度や利便性のために派生したデータです(キャッシュやリードモデル、検索インデックス)。テストとして、派生データが壊れてもソースオブトゥルースから再構築できるかを確認してください。
ユーザーが即座の結果を必要とする場合はリクエスト—レスポンスを使います。
次のような作業は後回しにできるため非同期に移してください:
非同期にすることでAPIは速くなり、タイムアウトやクライアントのリトライを減らせます。
「キュー」はやることリスト:各ジョブは一度だけ、ひとつのワーカーが処理する想定です(リトライあり)。
「ストリーム/ログ」は順序付きの記録:複数のコンシューマがリプレイしたり、追いついたり、新しい機能を追加できます。
実践的なデフォルト:
PaymentSucceeded)にはストリーム/ログ。重要な操作を**冪等(idempotent)**にします:同じリクエストを繰り返しても二重に請求や請求書発行が起きないようにすること。
よくあるパターン:
さらに一意制約(例:注文ごとに一つの請求書)を使うと安全性が上がります。
成長したプロダクトでの良いイベント設計は、安定したビジネス事実を少数公開することです。過去形の名前(PaymentSucceededやSubscriptionStarted)を使い、UIの言葉ではなく具体的な事実にします。
良いイベントのポイント:
こうすればコンシューマが何が起きたかを推測する必要がなくなります。
バックプレッシャーが必要なサイン:
最初に導入するコントロール:
スケール前に必要な観測性の基本:
サービス間を横断するリクエストに対してのみトレーシングを追加し、すべてを計測し始める前に目的を明確にしましょう。
「本番準備完了」は深夜でも指差せる決定の集合です。巧妙さより明確さが重要です。
チェックリスト:
もしプラットフォームがスナップショットとロールバック(Koder.ai のような機能)をサポートしているなら、インシデント専用の裏技にするのではなく日常的に使ってください。