2025年10月05日·2 分
アプリ向け RabbitMQ:パターン、セットアップ、運用
RabbitMQ をアプリに導入する方法:コア概念、一般的パターン、信頼性対策、スケーリング、セキュリティ、そして本番運用向けの監視について学びます。
なぜアプリチームに RabbitMQ が重要なのか
RabbitMQ はメッセージブローカーです:システムの各部分の間に入り、プロデューサからコンシューマへ“作業”(メッセージ)を信頼して移動させます。アプリチームが直接同期的な呼び出し(サービス間の HTTP、共有 DB、cron ジョブ)で壊れやすい依存関係、偏った負荷、デバッグが難しい障害連鎖に悩むとき、しばしば RabbitMQ に手が伸びます。
RabbitMQ が解決する問題
トラフィックスパイクと不均一な負荷。 例えば短時間にサインアップや注文が 10 倍になった場合、すべてを即時に処理しようとすると下流サービスが圧倒されます。RabbitMQ を使えば、プロデューサは作業を素早くキューに入れ、コンシューマは制御されたペースでそれを消化できます。
サービス間の結合の強さ。 サービス A がサービス B を呼んで待つ必要があると、失敗や遅延が伝播します。メッセージングはこれを分離します:A はメッセージを公開して続行し、B は利用可能になったときに処理します。
失敗処理の安全性。 すべての失敗をユーザー向けのエラーにする必要はありません。RabbitMQ はバックグラウンドでのリトライ、“毒”メッセージの隔離、一時的な障害時の作業ロス回避を助けます。
チームが通常得られる成果
チームは通常、滑らかな負荷(ピークの緩衝)、分離されたサービス(ランタイム依存の削減)、制御されたリトライ(手作業での再処理減少) を得ます。同じくらい重要なのは、作業がどこで詰まっているか(プロデューサ、キュー、消費者のどこか)を推理しやすくなることです。
このガイドの対象(と対象外)
このガイドはアプリチーム向けの実践的な RabbitMQ に焦点を当てます:コア概念、一般的なパターン(pub/sub、work queue、リトライと DLQ)、および運用上の考慮事項(セキュリティ、スケーリング、可観測性、トラブルシュート)。
これは 完全な AMQP 仕様の解説 やすべての RabbitMQ プラグインの深掘りを目的とするものではありません。目標は、実際のシステムで保守可能なメッセージフローを設計できるようにすることです。
簡単な用語集
- Producer: メッセージを送るアプリのコンポーネント。\n- Consumer: メッセージを受け取り処理するコンポーネント。\n- Queue: コンシューマが処理するまでメッセージを保持するバッファ。\n- Exchange: メッセージをキューへルーティングする入口。\n- Routing key: エクスチェンジがメッセージの行き先を決めるためのラベル。
RabbitMQ の基本:何で、いつ使うか
RabbitMQ は システムの部分間でメッセージをルーティングするメッセージブローカー です。プロデューサは作業を委ね、コンシューマは準備ができたときに処理します。
AMQP メッセージングと直接 HTTP 呼び出しの違い
直接の HTTP 呼び出しでは、サービス A がサービス B にリクエストを送り、通常 応答を待ちます。B が遅いかダウンしていると、A は失敗するか止まります。呼び出し側でタイムアウト、リトライ、バックプレッシャーを都度扱う必要があります。
RabbitMQ(一般的には AMQP を経由)では、サービス A はブローカーにメッセージを公開します。RabbitMQ はそれを 保持してルーティング し、適切なキューに届けます。サービス B は非同期にそれを消費します。キーとなる変化は、永続的な中間層 を介して通信し、スパイクをバッファして不均一な負荷を平滑化する点です。
メッセージングが適する場合(および適さない場合)
メッセージングは以下のような場合に適しています:
- チーム/サービスを分離して独立してデプロイやスケールを可能にしたいとき。\n- ユーザーリクエストをブロックせずに 非同期作業(メール送信、PDF 生成、不正検出など)を行いたいとき。\n- バースト的なトラフィックを吸収してピークをキューで処理したいとき。\n- 確実な配信(ack、リトライ、DLQ)が必要なとき。
メッセージングが適さないのは:
- 即時の回答が必須な場合(例:「このパスワードは有効か?」)。\n- 単純な同期読み取りで直接呼び出しの方が明快でデバッグが簡単な場合。\n- メッセージのバージョン管理、リトライ、監視の計画がない場合(複雑さを別の場所に移すだけになります)。
リクエスト/レスポンス vs 非同期ワークフロー(単純な例)
同期(HTTP):
チェックアウトサービスが請求サービスへ HTTP で「請求書作って」と呼び出す。ユーザーは請求処理が終わるまで待つ。請求が遅ければチェックアウトの遅延が増え、ダウンしていればチェックアウトが失敗する。
非同期(RabbitMQ):
チェックアウトは invoice.requested(注:このままバッククオート内は翻訳しません)を order id と一緒に公開する。ユーザーには注文を受け付けた即時確認を返す。請求サービスはこのメッセージを消費して請求書を生成し、invoice.created を公開してメール/通知が拾う。各ステップは独立してリトライでき、一時的な障害が全体を壊すことはありません。
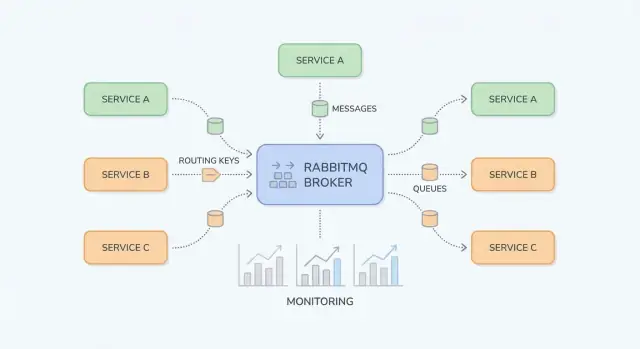
コアの構成要素:Exchange、Queue、ルーティング
RabbitMQ を理解するには「メッセージがどこに公開されるか」と「どこに保管されるか」を分けて考えると楽です。プロデューサは exchanges に公開し、エクスチェンジは queues にルーティングし、コンシューマがキューから読みます。
Exchange:RabbitMQ がメッセージの行き先を決めるしくみ
Exchange はメッセージを保持しません。ルールを評価して 1 つまたは複数のキューへフォワードします。
- Direct exchange:ルーティングキーの厳密一致でルートを決めます。
billingやemailのような明確な宛先に使います。\n- Topic exchange:ルーティングキーのパターンでルートを決めます。カテゴリ単位で購読したい場合に使います。\n- Fanout exchange:ルーティングキーを無視してバウンドされたすべてのキューにブロードキャストします。全消費者がすべてのイベントを受け取る必要がある場合に使います(キャッシュ無効化など)。\n- Headers exchange:ルーティングをメッセージヘッダに基づいて行います。複数属性(例:region=euANDtier=premium)でルーティングしたい特殊ケースで使いますが、扱いが難しいため限定的に留めるのが良いでしょう。
キューとバインディング:メッセージが正しい場所に届くしくみ
Queue はメッセージがコンシューマに処理されるまで座る場所です。キューは 1 つの消費者でも多くの消費者(競合する消費者)でも動作し、通常メッセージは一度に 1 つの消費者に配信されます。
Binding はエクスチェンジとキューを結びつけ、ルーティングルールを定義します。例:「exchange X に routing key Y で来たメッセージは queue Q に届ける」。複数のキューを同じエクスチェンジにバインドして pub/sub にしたり、単一キューを複数のルーティングキーでバインドすることもできます。
ルーティングキーとパターン(topic exchange)
direct exchange ではルーティングは厳密一致です。topic exchange のルーティングキーはドットで区切った単語列の形を取ります。例:
orders.created\n-orders.eu.refunded
バインディングはワイルドカードを含められます:
*はちょうど1語にマッチ(例:orders.*はorders.createdにマッチ)\n-#は0語以上にマッチ(例:orders.#はorders.createdとorders.eu.refundedにマッチ)
これにより、プロデューサを変更せずに新しいコンシューマを追加できる、柔軟で理解しやすい仕組みが実現します。
メッセージの確認(ack、nack、requeue)
RabbitMQ がメッセージを配信した後、コンシューマは結果を報告します:
- ack:"正常に処理した"。RabbitMQ はメッセージをキューから削除します。\n- nack(または reject):"失敗した"。破棄するか requeue(再キュー)するか選べます。\n- requeue:メッセージを戻して再試行させます(通常は即時)。
requeue には注意が必要です:常に失敗するメッセージが永遠にループしてキューを塞ぐ可能性があります。多くのチームは nack をリトライ戦略とデッドレターキュー(後述)と組み合わせて、失敗を予測可能に処理します。
実際のアプリにおける一般的なユースケース
RabbitMQ はワークや通知をシステムの一部から別の一部へ移動させたいときに威力を発揮します。以下は日常的に登場する実践パターンです。
Publish/subscribe の通知(fanout/topic)
複数の消費者が同じイベントに反応すべきで、かつ発行者が誰に通知すべきかを知らない場合に適します。
例:ユーザーがプロフィールを更新したとき、検索インデックス、分析、CRM 同期を並列で通知したい。fanout ならすべてのバウンドキューにブロードキャストします。topic を使えば user.updated、user.deleted のように選択的にルーティングできます。これによりプロデューサの結合を避け、新しい購読者をプロデューサを変えずに追加できます。
背景ジョブの work queue
処理に時間がかかるタスクはキューに押し込み、ワーカーが非同期に処理します:
- 画像/動画処理\n- トランザクションメール送信\n- PDF/レポート生成\n- データのインポート/エクスポート
これにより Web リクエストを高速化し、ワーカーを個別にスケールできます。キューは「やることリスト」、ワーカー数は「スループットの調整ノブ」として自然に使えます。
サービス間のイベント駆動型連携
多くのワークフローはサービスを横断します:order → billing → shipping の例が古典です。1 つのサービスが次を呼んでブロックする代わりに、各サービスが自分のステップを終えたらイベントを公開し、下流はそのイベントを消費して処理を続けます。
これにより回復力が増し(配送の一時的な障害がチェックアウトを壊さない)、オーナーシップが明確になります:各サービスは自分が関心のあるイベントに反応します。
遅い/不安定な依存との橋渡し
RabbitMQ は遅いか不安定な依存(サードパーティ API、レガシーシステム、バッチ DB)のバッファにもなります。リクエストを素早くエンキューし、制御されたリトライで処理します。依存先がダウンしている間は作業が安全に蓄積され、後で排出されます—これによりアプリケーション全体でタイムアウトが発生することを防げます。
段階的にキューを導入するなら、小さな “async outbox” や単一のバックグラウンドジョブキューから始めるのが良い(参照:/blog/next-steps-rollout-plan)。
保守しやすいメッセージフローの設計
RabbitMQ の構成が扱いやすいままでいるためには、ルートが予測しやすく、名前が一貫し、ペイロードが古いコンシューマを壊さずに進化することが重要です。新しいキューを追加する前に、そのメッセージの “物語” が明瞭か確認してください:起点はどこか、どうルーティングされるか、チームメンバーがエンドツーエンドでデバッグする方法は何か。
ルーティングニーズに合ったエクスチェンジを選ぶ
適切なエクスチェンジを選ぶと、ワンオフのバインディングや予期せぬファンアウトを減らせます:
- Direct exchange:ルーティングキーが特定のキューに対応する場合に最適(例:
billing.invoice.created)。\n- Topic exchange:パターンベースの柔軟な pub/sub に最適(例:billing.*.created、*.invoice.*)。イベント型ルーティングでは最も一般的。\n- Fanout exchange:すべての消費者が各メッセージを受け取るべきときに最適(ビジネスイベントでは稀; ブロードキャスト信号で一般的)。
1 つの目安:コードの中で複雑なルーティングロジックを“発明”しているなら、それは topic exchange パターンに置くべきかもしれません。
メッセージスキーマの基本:バージョン管理と後方互換性
メッセージ本文は公開 API のように扱ってください。明示的な バージョン管理(例:トップレベルフィールド schema_version: 2)を使い、後方互換性 を目指します:
- フィールドを追加し、名前を変更・削除しない。\n- 省略可能なフィールドを安全なデフォルトで扱う。\n- 破壊的変更が避けられない場合は、古いものを静かに変更するのではなく新しいメッセージ種別/ルーティングキーを公開する。
これにより古いコンシューマが動作を継続し、新しいコンシューマが段階的に採用できます。
相関 ID とトレース ID による横断デバッグ
トラブルシュートを簡単にするためにメタデータを標準化してください:
correlation_id:同一ビジネスアクションに属するコマンド/イベントを紐づける。\n-trace_id(または W3C のtraceparent):HTTP と非同期をつなぐ分散トレース。
すべてのプロデューサが一貫してこれらをセットすると、単一トランザクションを複数サービスにわたって追跡できます。
スケールする命名規則
検索しやすく予測可能な名前を使ってください。一般的なパターンの一例:
- Exchanges:
<domain>.<type>(例:billing.events)\n- Routing keys:<domain>.<entity>.<verb>(例:billing.invoice.created)\n- Queues:<service>.<purpose>(例:reporting.invoice_created.worker)
一貫性はひらめきより勝ります:将来のあなた(とオンコールの人)が感謝します。
信頼性パターン:リトライ、DLQ、冪等性
最初のキューサービスを構築
プロンプトからRabbitMQのプロデューサー/コンシューマーの骨組みを生成し、コーディング前に反復できます。
信頼できるメッセージングは主に失敗を計画することです:コンシューマがクラッシュしたり、下流 API がタイムアウトしたり、メッセージ自体が壊れていることがあります。RabbitMQ はツールを提供しますが、アプリケーション側の協調が必要です。
at-least-once 配信(とコードの意味)
一般的なセットアップは at-least-once delivery:メッセージは複数回配信されることがあるが、黙って失われてはならない、という性質です。これは通常、コンシューマがメッセージを受け取り処理を始めたが ack する前に失敗した場合に発生します—RabbitMQ は再キューして再配信します。
実務上の教訓:重複は通常のものとして扱う ので、ハンドラは複数回実行されても安全であるべきです。
コンシューマの冪等性戦略
冪等性とは「同じメッセージを2回処理しても 1 回処理したのと同じ効果になる」ことです。実用的な方法:
- Dedupe keys:安定した
message_id(またはorder_id + event_type + versionのようなビジネスキー)を含め、TTL 付きの “処理済み” テーブル/キャッシュに保存する。\n- 安全な更新:条件付き書き込み(例:ステータスがまだPENDINGのときだけ更新)、データベースの一意制約を使う。\n- Outbox/Inbox パターン:最初にイベント受領を永続化し、その後処理することで、リトライで副作用が繰り返されないようにする。
TTL + DLX/DLQ を使ったリトライ
リトライはコンシューマ内の tight loop として扱うより、別フローとして扱う方が良いです。
一般的なパターン:
- 一時的な失敗時に拒否して retry queue にルーティングし、そのキューに TTL を設定する(あるいはメッセージ単位で TTL を設定)。\n2. TTL が切れると、メッセージは dead-letter exchange (DLX) を通じて元のキューに戻る。\n3. ヘッダで試行回数を追跡し、N 回を超えたら停止する。
これによりインラインで何度も再試行する代わりにバックオフが実現できます。
毒メッセージ:隔離とリプレイ
永遠に成功しないメッセージ(スキーマ不備、参照欠落、コードバグなど)は存在します。検出条件:
- 最大リトライ回数に到達\n- 同一のエラー署名で繰り返し失敗
これらは DLQ に隔離します。DLQ は運用用の受信箱として扱い、ペイロードを調査し、根本問題を修正した後で選択的に手動で再生(理想的にはツール/スクリプト経由で)します。全件を無秩序に main queue に戻すのは避けてください。
パフォーマンスとスケーリング:実務的なチューニング
RabbitMQ のパフォーマンスは通常、接続の管理、コンシューマの処理速度、キューを“ストレージ”として使っていないかに制約されます。目標は、増え続けるバックログを作らずに安定したスループットを得ることです。
接続とチャネル(再利用と制限)
誤りがちな点は、パブリッシャやコンシューマごとに新しい TCP 接続を開くことです。接続は思ったより重く(ハンドシェイク、ハートビート、TLS)、長期間使い回してください。
チャネル を使って少数の接続上で多重化します。経験則:接続は少なく、チャネルは多く。とはいえ無制限にチャネルを作るのも良くありません—各チャネルにもオーバーヘッドがあり、クライアントライブラリに制限があります。サービスごとに小さなチャネルプールを持ち、パブリッシュにはチャネルを再利用するのが良いでしょう。
Prefetch と並列度(過負荷に陥らないスループット)
コンシューマが一度に多くのメッセージを取得するとメモリが跳ね上がり、処理時間が増え、レイテンシが不均一になります。各コンシューマが保持する未ack メッセージ数を制御するために prefetch(QoS)を設定してください。
実務的ガイダンス:
- 遅いジョブ(API 呼び出し、ファイル処理)では、コンシューマごとに prefetch 1–10 から始める。\n- 軽いハンドラなら prefetch を徐々に上げ、ack レートとホスト資源を監視する。\n- prefetch を極端に上げる前に 消費者インスタンスを増やす ことでスケールする。
メッセージサイズ:ペイロードは小さく保つ
大きなメッセージはスループットを下げ、パブリッシャ、ブローカー、コンシューマのメモリ負荷を増やします。ドキュメントや画像、大きな JSON がある場合は外部(オブジェクトストレージや DB)に格納し、RabbitMQ には ID + メタデータだけ送ることを検討してください。
目安:メッセージは MB ではなく KB レンジに保つ。
バックプレッシャー:"無限キュー成長" を防ぐ
キューの成長は戦略ではなく症状です。プロデューサが消費者に追いつかないときはプロデューサを抑制する仕組みが必要です:
- 消費者の作業を制限:並列度と prefetch をキャップして in-flight 作業を予測可能にする。\n- 増加を検出して対応:キュー深度や publish rate と ack rate の差をアラートにする。\n- 負荷の削減:非重要なイベントはスパイク時にドロップやサンプリングする。
迷ったら一つずつノブを変えて計測してください:publish rate、ack rate、queue length、エンドツーエンドレイテンシ。
RabbitMQ のセキュリティチェックリスト
より安全なメッセージフローを設計
実装前にプランニングモードでリトライ、DLQの流れ、メッセージバージョンを設計できます。
RabbitMQ のセキュリティは主に“エッジ”の強化—クライアント接続、操作権限、資格情報の管理—にあります。以下を土台として順守し、あなたのコンプライアンス要件に合わせて調整してください。
接続の暗号化(TLS)
- すべてのクライアント接続に TLS を有効化する(AMQP over TLS は 5671、または選んだポート)。最新の TLS バージョンと強い暗号を優先する。\n- ブローカーのホスト名と一致する証明書を使う。\n- 証明書のローテーションを計画する:有効期限を追跡し、自動更新を可能にし、ローテーションが原因で停止しないよう再読み込み手順を練習する。\n- 可能なら内部の機密サービスには mTLS によるクライアント検証を行う。
認証と認可
RabbitMQ の権限は一貫して使えば強力です。\n
- 各アプリケーションに別々のユーザーを作成する(共有アカウントを避ける)。\n- vhost を使ってテナントやシステムを分離する(例:製品/チームごとに vhost)。\n- vhost ごとに最小権限を適用する(configure/write/read)。
dev/staging/prod の分離
- 可能なら環境ごとにクラスタを分けて運用する。インフラを共有する場合は厳格な vhost 境界と別々の資格情報で分離する。\n- dev アプリを prod ブローカーに誤って接続できないようにネットワークポリシーや DNS 名で不可能にする。
アプリ内でのシークレットの扱い
- 資格情報をコードや git にコミットしない、コンテナイメージに埋め込まない。\n- ランタイムでプラットフォーム経由(Kubernetes Secret、シークレットマネージャ、暗号化された CI 変数)で注入する。\n- 定期的に資格情報をローテーションし、使われていないユーザーは削除する。
運用のハードニング(ポート、ファイアウォール、監査)については短い内部ランブックを用意し、/docs/security から参照できるようにしてください。
監視と可観測性:何を測るか
RabbitMQ に問題があるとき、症状はまずアプリケーション側に現れます:エンドポイントの遅延、タイムアウト、更新が来ない、ジョブが "終わらない" など。良い可観測性はブローカーが原因かどうかを特定し、ボトルネック(プロデューサ、ブローカー、コンシューマのどれか)を見つけ、ユーザーが気づく前に対処することを可能にします。
追うべき主要なブローカメトリクス
メッセージが流れているかを示す最小限の指標から始めます:
- キュー深度(messages ready + unacked):深度が上がれば消費者が追いついていないか、スタックしている。\n- Publish rate と ack rate:publish が増えて ack が横ばい=バックログ。ack が急に下がる=消費者の障害やタイムアウト。\n- 消費者の利用率:消費者がアイドルか飽和か頻繁に再起動しているか。prefetch と並べて見る。\n- Redeliveries / requeues:処理エラー、誤ったリトライポリシー、毒メッセージの強い指標。
早期検知のためのアラート
閾値ではなくトレンドでアラートする:
- 数分間にわたるバックログの増加:深度が一貫して増加することは、単なる一時的ピークより有益なアラート。\n- 再キュー/再配信の多発:失敗ループを示す。CPU を浪費しキューを詰まらせる。\n- 接続・チャネルのチャーン:頻繁な切断はアプリのクラッシュ、ネットワーク問題、ハートビート設定ミスを示す。\n- 長時間の高 unacked 数:消費者がハングしているか一メッセージの処理が長すぎる。
障害時のログとメッセージトレース
ブローカログからは「RabbitMQ が落ちている」のか「クライアントが誤用している」のかを切り分けられます。認証失敗、接続ブロック(リソースアラーム)、頻繁なチャネルエラーを探してください。アプリ側は各処理試行で correlation ID、キュー名、結果(acked、rejected、retried)をログに残しましょう。
分散トレーシングを使う場合は、メッセージプロパティを通じてトレースヘッダを伝搬して「API リクエスト → 公開されたメッセージ → コンシューマの処理」を繋げられるようにします。
ダッシュボードと内部ランブック
重要なフローごとにダッシュボードを作ります:publish rate、ack rate、depth、unacked、requeues、consumer count。ダッシュボードに運用手順書(/docs/monitoring など)へのリンクとオンコール担当者向けの "まず何を確認するか" チェックリストを張っておくと素早い対応が可能になります。
よくある RabbitMQ の問題のトラブルシュート
何かが“動かなくなった”とき、まずは再起動したくなる衝動を抑えてください。多くの問題は(1)バインディングとルーティング、(2)コンシューマの健康、(3)リソースアラームを確認すれば明らかになります。
メッセージが消費されない場合
プロデューサが「正常に送信した」と報告するのにキューが空(または別のキューに入っている)なら、まずはルーティングを疑いましょう。
Management UI で始める:
- exchange の種類とキューに期待する binding があるかを確認する。\n- プロデューサが出している routing key がバインディングパターンと一致しているか(特に
topicの場合)。\n- 正しい vhost に publish しているか確認する。
キューにメッセージがあるが誰も消費していない場合は:
- 消費者が接続されていて正しいキューを購読しているか。\n- コンシューマが遅い下流処理でブロックされていないか、あるいは
prefetch設定が原因で滞留していないか。\n- ack が行われているか(unacked 数の増加は ack していないか、オーバーロードを示す)。
重複と順序の乱れ
重複は通常、リトライ(処理後にクラッシュして ack できない)、ネットワークの断、手動での再キューが原因です。データベースでのデデュープ(message ID による)で対処します。
複数の消費者や再キューがある場合、順序が保たれないのは正常です。順序が重要なら、そのキューに対して単一コンシューマを使うか、キーごとにパーティション化して複数キューを使ってください。
メモリ/ディスクアラーム
アラームは RabbitMQ が自己防衛していることを示します。\n
- ディスクアラーム:空きディスクを確保する(ログ移動やボリューム拡張)してアラームが解除されるか確認する。\n- メモリアラーム:in-flight メッセージを減らす(prefetch を下げる、キューをドレインする)、過大なメッセージがないか確認する。
DLQ からの安全なリプレイ
再生する前に根本原因を修正し、毒メッセージのループを防いでください。少量のバッチで再投入し、リトライ上限を設け、失敗時のメタデータ(試行回数、最後のエラー)を付与してください。再生用の別キューに一旦送って挙動を監視するのも有効です。
RabbitMQ と他の選択肢:適切なツールの選び方
非同期ワークフローに移行
イベント駆動のワークフローを作成し、複雑なHTTP連鎖なしにサービスを疎結合に保てます。
メッセージングツールの選定は「どれがベストか」ではなく、トラフィックパターン、失敗に対する許容度、運用上の慣れに合っているかが重要です。
RabbitMQ が適する場面
RabbitMQ は 確実なメッセージ配信と柔軟なルーティング が必要なアプリ間連携に向いています。コマンド、バックグラウンドジョブ、ファンアウト通知、リクエスト/レスポンスパターンなどの古典的な非同期ワークフローで優れています。特に:
- メッセージごとの ack とバックプレッシャーが必要なとき(遅い消費者が作業を落とさない)\n- 複雑なルーティング(topic、headers、direct)を自前で作りたくないとき\n- 多くのチームにとって運用が比較的簡単で、消費者を増やし、prefetch をチューニングし、キューを管理することでスケールしやすい
イベント履歴を長期間保ち解析用途で再生したいかどうかが主要な分岐点です。ワークを動かすことが主目的で履歴保持が不要なら RabbitMQ が扱いやすいデフォルトになることが多いです。
RabbitMQ と Kafka ライクなストリーミングシステムの違い
Kafka は 高スループットのストリーミングと長期保存されるイベントログ のために設計されています。Kafka の方が適切なケース:
- 履歴を再処理(リプレイ)したいとき\n- パーティションによる非常に高いスループットが必要なとき\n- 分析とサービス両方のための単一の “ソースオブトゥルース” が欲しいとき
トレードオフ:Kafka 系は運用コストが高くなりやすく、スループット志向の設計(バッチ処理、パーティション戦略)を強いることがあります。RabbitMQ は低〜中スループットで複雑なルーティングや低レイテンシを扱うには扱いやすい傾向があります。
単純なタスクキューで足りる場合
一つのアプリがジョブを出し、ワーカープールがそれを消費するだけでよく、単純なセマンティクスで足りるなら Redis ベースのキューやマネージドなタスクサービスで十分なことがあります。チームは通常、強い配信保証、デッドレタリング、多様なルーティングパターン、プロデューサとコンシューマの明確な分離が必要になった時点でこれを乗り越えます。
将来に備えた移行の考慮事項
将来別のシステムに移す可能性を考えてメッセージ契約を設計してください:
- メッセージスキーマをバージョン化し、後方互換性を保つ。\n- ペイロードにブローカー固有の機能を埋め込まない(ルーティング情報はヘッダ/メタデータに置く)。\n- プロデューサとコンシューマが移行中に並行動作できるように作る。
後で履歴を再処理可能なストリームが必要になったら、RabbitMQ のイベントをログベースのシステムにブリッジする形で両者を併用できます。実践的な移行計画は /blog/rabbitmq-rollout-plan-and-checklist を参照してください。
次のステップ:ロールアウト計画とチームチェックリスト
RabbitMQ の導入は "製品として" 扱うと成功します:小さく始め、オーナーシップを定義し、拡張前に信頼性を実証します。
スターターのチェックリスト(ワンサービス導入)
非同期処理で効果がある単一のワークフローを選びます(例:メール送信、レポート生成、サードパーティ API 同期):
- メッセージ契約を定義する:必須フィールド、バージョン、"成功" の定義。\n- 明確な命名規則で 1 つの exchange + 1 つの queue を作る。\n- 下流を過負荷にしないために消費者の並列度と prefetch を設定する。\n- 初日からリトライ(バックオフ)とデッドレターキュー(DLQ)を設ける。\n- ハンドラを冪等に(同じメッセージを二度処理しても安全に)。\n- 運用の “出血を止める” 手順(コンシューマを一時停止、キューのドレイン、DLQ の再生)を文書化する。
命名やリトライ層、基本ポリシーのテンプレートを /docs に集中管理しておくと参照しやすくなります。
実装中はスキャフォールディングを標準化することを検討してください。例えば Koder.ai を使うチームはチャットプロンプトから小さな producer/consumer のスケルトンを生成し(命名規約、retry/DLQ の配線、trace/correlation ヘッダを含む)、ソースコードをレビューしてロールアウト前に計画モードで反復します。
運用オーナーシップ(明確にする)
RabbitMQ は “誰がキューを管理するか” を決めておくと成功します:
- 誰が監視するか:通常はプラットフォーム/SRE チームがブローカの健全性を見て、サービスチームが自分のキューとコンシューマ挙動を管理します。\n- 誰が DLQ を扱うか:サービスチームのオンコール(明確なエスカレーション経路を設定)。\n- ランブック:ブローカレベルのランブック一つと、重要なキューごとのサービスレベルのランブックを用意する。
マネージドホスティングやサポートを形式化するなら、早めに期待値を合わせておく(参照:/pricing、連絡窓口 /contact)。
次に試す実験(拡張前に検証)
小さく時間を区切った実験で自信をつけます:
- ロードテスト:ピーク想定の負荷でスループット、消費者並列度、レイテンシを検証する。\n- 障害訓練:コンシューマを落とす、ブローカ再起動をシミュレートする、ネットワーク遅延を発生させる、リトライと DLQ の挙動を確認する。\n- スキーマバージョニング:v2 メッセージを導入しつつ v1 コンシューマが稼働を続けられるかを検証する。
1 つのサービスが数週間安定したら同じパターンを再利用して他サービスに展開してください。再発明は避けましょう。
よくある質問
アプリケーションチームはいつ直接の HTTP 呼び出しではなく RabbitMQ を使うべきですか?
サービスをデカップリングしたい、トラフィックスパイクを吸収したい、あるいはリクエストパスから重い処理を切り離したい場合は RabbitMQ を使ってください。
適している例:バックグラウンドジョブ(メール、PDF 生成)、複数の消費者へのイベント通知、下流の一時的な障害があっても継続すべきワークフロー。
避けるべき場面:即時の応答が必須なケース(単純な読み取りやバリデーションなど)、あるいはメッセージのバージョン管理やリトライ、監視を運用する意思がない場合—本番ではそれらは必須です。
direct、topic、fanout、headers のどれを選べばいいですか?
発行先は exchange、受け取り先は queue です:
- direct exchange: ルーティングキーが特定の宛先に厳密一致する場合に使います。\n- topic exchange:
orders.*やorders.#のような柔軟なパターンでルーティングしたいときに使います。\n- fanout exchange: すべてのバウンドされたキューにブロードキャストする場合に使います。\n- headers exchange: 複数属性に基づくルーティングが必要な特殊ケースでのみ使うのが良いでしょう。
多くのチームはメンテナンスしやすいイベント型ルーティングのために topic exchange をデフォルトにします。
キューとバインディングの違いは?ルーティングはどうして失敗しますか?
キューはメッセージを保管する場所で、バインディングは exchange と queue を結びつけるルールです。
ルーティング障害をデバッグするには:
- exchange の種類とキューのバインディングパターンを確認する。\n- プロデューサーが出しているルーティングキーがバインディングと一致しているか(topic のワイルドカードに注意)。\n- 正しい vhost に publish/consume しているかを確認する。
この3点で「発行したが消費されない」問題の大半が説明できます。
バックグラウンドジョブ用の最も単純な “work queue” パターンはどんなものですか?
ワーカープロセスのうち1つがタスクを処理する典型的なパターンです。
実践的な設定のコツ:
- 各メッセージを 1 単位の作業として小さくし、リトライ可能にする。\n- ワーカーが未ack のメッセージを取りすぎないように
prefetchを設定する。\n- スケールは prefetch を極端に上げる前に、消費者インスタンス数を増やして行う。\n- ペイロードは小さく(大きなバイナリは外部ストレージ)、ID + メタデータを送る。
at-least-once 配信とは何か、重複はどう扱うべきですか?
少なくとも一度配信(at-least-once)とは、メッセージが複数回配信される可能性があることを意味します(たとえば、消費者が処理した後に ack する前にクラッシュした場合など)。
重複に対処するために:
- 安定した
message_id(またはビジネスキー)を含め、処理済み ID を TTL 付きで保存する。\n- 条件付き書き込み(たとえばステータスがPENDINGのときだけ更新)やデータベースの一意制約を使う。\n- 副作用を分離し、リトライで二重請求や二重メールが起きないようにする。
重複は通常のこととして設計してください。
RabbitMQ でのリトライとデッドレターキュー (DLQ) はどう実装すべきですか?
緊密な requeue ループは避けるべきです。よくあるアプローチは「リトライ用キュー」+ DLQ です:
- 一時的な失敗時はメッセージを retry queue に送り、そこの TTL(遅延)を利用してバックオフさせる。\n- TTL が切れるとメッセージは DLX を経由して元のキューに戻される。\n- ヘッダで試行回数を追跡し、N 回を超えたら永続的な失敗として DLQ に送る。\n DLQ からの再投入は根本原因を修正してから、小さなバッチで行ってください。
サービスが進化してもメッセージ契約を保守可能にするには?
予測可能な名前付けとメッセージを公開 API として扱うことから始めてください:
- ペイロードに
schema_versionを追加する。\n- 追加は許容(フィールドを追加)、名前変更や削除は避ける。\n- 破壊的変更が必要なら、新しいメッセージ種別/ルーティングキーで公開する。
標準化するメタデータ:
correlation_id:同一ビジネスアクションに属するコマンド/イベントを紐づける。\n-trace_id(または W3C のtraceparent):HTTP と非同期フローを結びつけるトレース用。
本番で監視すべき主要なメトリクスとアラートは?
以下のシグナルに注目すれば、作業が流れているかを把握できます:
- キュー深度(ready + unacked)\n- Publish レートと Ack レート\n- 再配信(redeliveries)/ 再キュー(requeues)\n- 消費者数、利用率、再起動の頻度
アラートは閾値ではなくトレンドに基づいて設定するのが有効です(例:「バックログが10分間増加し続けている」)。ログにはキュー名、correlation_id、処理結果(acked/retried/rejected)を含めてください。
RabbitMQ をデプロイする際の最低限のセキュリティチェックリストは?
基本を一貫して行ってください:
- クライアント接続は TLS を使う。機密性の高い内部サービスでは mTLS を検討する。\n- アプリごとに専用ユーザーを作る(共有資格情報は避ける)。\n- vhost で環境やテナントを分離し、最小権限(configure/write/read)を適用する。\n- シークレットはハードコーディングせず、ランタイム注入(Kubernetes Secret、シークレットマネージャなど)で扱い、定期的にローテーションする。
内部で参照できる短い運用手順書を用意して、チームが同じ基準を守れるようにしてください(例:/docs/security)。
「メッセージが消費されない」「全体が詰まっている」をどうトラブルシュートする?
フローがどこで止まっているかを特定するところから始めてください:
- キューが空なら exchange/binding/routing key と vhost を確認する。\n- キューにメッセージがあるが動かないなら、消費者接続、prefetch、unacked の増加を確認する。\n- 重複や順序が狂う場合はリトライや競合消費者を疑い、冪等性やパーティショニングで対処する。\n- ディスク/メモリのアラームが出ている場合は、in-flight メッセージを減らし(prefetch/concurrency の調整)、パブリッシャーを制限し、リソースを確保してから対処する。
ほとんどの場合、まず再起動するのは最善手ではありません。状況を把握してから行動しましょう。