2025年12月02日·1 分
グーグルの長期戦略におけるラリー・ペイジのAIビジョン
ラリー・ペイジの初期のAIや知識に関する考えが、検索の質からムーンショットやAIファーストの賭けに至るまで、どのようにグーグルの長期戦略を形作ったかを探る。
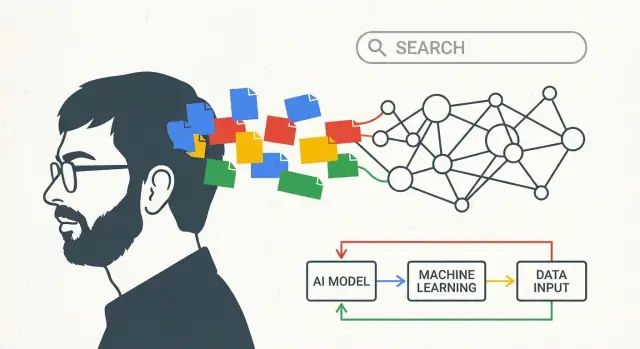
この投稿で言う「ラリー・ペイジのAIビジョン」とは
これは単一のブレークスルーを煽る記事ではありません。長期的な思考についての話です:企業が早期に方向性を選び、複数の技術変化を通じて投資を続け、大きなアイデアを日常的なプロダクトに変えていくやり方です。
この投稿で「ラリー・ペイジのAIビジョン」と言うとき、それは「グーグルが今日のチャットボットを予見していた」という意味ではありません。もっと単純で、そして持続的なことを指します:経験から学ぶシステムを作ることです。
平易な定義
ここでの「AIビジョン」はいくつかの関連する信念を指します:
- コンピュータは手書きのルールだけで動くのではなく、データから学ぶことで性能を向上させるべきだ。
- 実際の利用によるフィードバック(人が何をクリックするか、無視するか、どう言い換えるか)があるため、優れたシステムは時間とともに良くなる。
- 学習を実用化するにはインフラが必要だ:高速な計算、信頼できるストレージ、大規模に実験を安全に実行する仕組み。
つまり「ビジョン」は単一のモデルよりもエンジンに近い:信号を集め、パターンを学習し、改善を出荷し、繰り返す。
たどる道筋
その考えを具体化するために、残りは単純な進行をたどります:
- 検索(Search): 明確な問題から始める—人々が良い答えを見つける手助けをする。
- データ+インフラ: 実際の利用から「良い」が何かを学び、それを処理する機械を構築する。
- AIファースト製品: 学習システムをデフォルトのアプローチとして扱い、音声や画像、新しいインターフェースが根本から作り直すことなく機能するようにする。
最後には「ラリー・ペイジのAIビジョン」はスローガンではなく戦略のように感じられるはずです:学習システムに早期投資し、それらに供給するパイプを作り、年単位で複利的に進歩を積み上げるために忍耐強くあること。
グーグルが初期に解こうとした問題:良い答えを見つけること
初期のウェブは、結果が厄介になるような単純な問題を抱えていました:情報が突然圧倒的に増え、誰もが精査できる量ではなくなった一方で、当時の多くの検索ツールは何が重要かをほとんど推測していたのです。
クエリを打ち込むと、多くのエンジンは明白なシグナルに依存していました—ある単語がページにどれだけ出現するか、タイトルにあるか、サイト管理者が透明でない方法で詰め込んでいないか、など。これでは結果は操作されやすく、信頼しにくかった。ウェブはそれを整理するためのツールよりも速く成長していました。
推薦の説明としてのPageRank
ラリー・ペイジとセルゲイ・ブリンの重要な洞察は、ウェブ自体が既に組み込みの投票システムを持っていることでした:リンクです。
あるページから別のページへのリンクは、論文の引用や友人からの推薦に少し似ています。しかしすべての推薦が等しいわけではありません。多くの人が価値あると考えるページからのリンクは、無名のページからのリンクよりも価値があるべきです。PageRankはこの考えを数学に落とし込みました:ページをそのページ自身が言うことだけでランク付けするのではなく、リンクを通じてウェブ全体がそのページについて「言っていること」でランク付けするのです。
これは同時に二つの重要なことをもたらしました:
- 正確なクエリ用語を繰り返さなくても権威あるページを浮上させられるようになった。
- 信頼性はネットワーク全体で獲得される必要があり、ランキングを操作しにくくした。
初日から計測と反復が重要だった理由
巧妙なランク付けのアイデアがあるだけでは十分ではありません。検索の品質は動的な目標です:新しいページが登場し、スパムは適応し、クエリの意図は変わり得ます。
だからこそシステムは計測可能で更新可能でなければなりませんでした。グーグルは常時テストに頼り—変更を試し、結果が改善するか測り、繰り返す—という習慣を取りました。その反復の習慣が会社の長期的な「学習」システムへのアプローチを形作ったのです:検索は一度きりのエンジニアリングプロジェクトではなく、継続的に評価できるものとして扱う。
フライホイールとしてのデータ:実際の利用から学ぶ
優れた検索は巧妙なアルゴリズムだけで成り立つわけではなく、それらのアルゴリズムが学べる信号の質と量に依存します。
初期のグーグルは生来の優位性を持っていました:ウェブ自体が何が重要かについての「投票」で満ちているのです。ページ間のリンク(PageRankの基盤)は引用のように機能し、アンカーテキスト(「ここをクリック」対「ベストなハイキングブーツ」)は意味を付与します。さらにページ全体の言語パターンは同義語や綴りの揺れ、同じ質問のさまざまな表現を理解する助けになります。
複利的に働くフィードバックループ
一度人々が大規模に検索エンジンを使い始めると、利用は追加の信号を生みます:
- クリックは特定のクエリに対してどの結果が実際のユーザーにとって関連があるように見えるかを示す。
- 「長いクリック」対すぐ戻る挙動は満足度のヒントになる。
- クエリの言い換え(別の語で再検索)は意図と結果のミスマッチを露呈する。
これがフライホイールです:より良い結果はより多くの利用を呼び、より多くの利用は豊かな信号を生み、その信号がランク付けと理解を改善し、その改善がさらに多くのユーザーを引き寄せる。時間が経つにつれて、検索は固定されたルールの集合というより、実際に人々が有用だと感じるものに適応する学習システムになっていきます。
データの多様性が重要な理由
異なる種類のデータは互いに強化しあいます。リンク構造は権威性を示し、クリック行動は現在の好みを反映し、言語データは曖昧なクエリ(「jaguar」は動物か車か)を解釈する助けになります。これらが組み合わさることで、「この単語を含むページはどれか」ではなく「この意図にとって最良の答えは何か」を返せるようになります。
プライバシーについての注意
このフライホイールは当然プライバシーの問題を生みます。消費者向け大規模プロダクトが膨大なインタラクションデータを生成し、企業が集計された信号を品質向上に使うことは長く報告されてきました。グーグルが時間をかけてプライバシーとセキュリティのコントロールに投資してきたことも公に報告されていますが、その詳細や有効性については議論があります。
要点は単純です:実世界の利用から学ぶことは強力だ—そして信頼はその学習をどれだけ責任を持って扱うかに依存する。
「機械」を作る:AIを実用化したインフラ
グーグルが早期に分散コンピューティングに投資したのは流行だからではなく、ウェブのややこしいスケールに追いつく唯一の方法だったからです。何十億ページをクロールし、ランキングを頻繁に更新し、クエリに数分の一秒で応答したいなら、1台の大きなコンピュータには頼れません。何千台もの安価なマシンが協働し、障害を常態として扱うソフトウェアが必要です。
なぜ分散コンピューティングが早くから重要だったか
検索はグーグルに巨大なデータを信頼性高く保存・処理できるシステムを作らせました。その「多数のコンピュータ、ひとつのシステム」アプローチは後のすべての基盤になりました:インデクシング、分析、実験、そして最終的には機械学習です。
重要な洞察は、インフラはAIから分離したものではなく、どんな種類のモデルが可能かを決定するという点です。
インフラがAIをデモから製品に変える方法
有用なモデルを訓練するには大量の実例を見せる必要があります。そのモデルを提供するには、何百万人にも瞬時に、かつ停止なく動かす必要があります。両方とも「スケールの問題」です:
- **訓練(Training)**はデータを何度も処理するための巨大な計算を必要とする。
- **提供(Serving)**は推論を高速(多くの場合ミリ秒単位)に行い、トラフィックの急増時にも応答できるシステムを必要とする。
データ保存、計算分散、性能モニタリング、更新の安全なロールアウトのためのパイプラインを構築すれば、学習に基づくシステムは継続的に改善されることが可能になり、稀でリスキーな書き直しとして到来するのではなくなります。
「配管」が効いている日常の簡単な例
いくつか馴染みのある機能は、なぜその機械が重要なのかを示します:
- スペル補正: 「restarant」→「restaurant」のようなパターンに気づくには多くの検索とクリックから学び、クエリ時に即座に補正を適用する必要がある。
- オートコンプリート: 入力途中の予測は集計された行動と高速な推論に依存する—さもなければ提案が遅れて不自然に感じられる。
- 翻訳: より良い翻訳品質は大規模データセットでの訓練と、世界中のユーザー向けに高速で動作するモデルの提供から来る。
グーグルの長期的優位は単なる巧妙なアルゴリズムだけでなく、アルゴリズムがインターネット規模で学び、出荷し、改善できる運用エンジンを構築した点にありました。
ルールから学習へ:検索が静かにより「AI的」になった方法
最初のイテレーションを構築
AI戦略を、週単位で測定して改善できる実働アプリに変える。
初期のグーグルはすでに「賢く」見えましたが、その多くは設計によるものでした:リンク解析(PageRank)、手作りのランキングシグナル、多くのヒューリスティックです。時間とともに重心は、明示的なルールからデータからパターンを学ぶシステムへと移っていきました—特に人々が何を意味しているかについて学ぶ面で。
機械学習が検索の感触をどう変えたか
機械学習は徐々に一般ユーザーが気づく三つの点を改善しました:
- ランキング品質: 固定式の重み付けではなく、どのシグナルの組合せがユーザーを満足させるかをモデルが学ぶようになった(匿名化された集計行動や人間の品質評価者のフィードバックによって測定)。
- 意図理解: 「jaguar speed」や「apple support」のようなクエリは意味、文脈、曖昧さを推定させる。学習ベースのシステムは表現を概念や推定される目的にマッピングするのが上手になった。
- スパムと信頼: コンテンツファームや操作的SEOが拡大する中、MLは不自然なリンクパターンや薄いコンテンツなどを検出する助けとなり、高品質な結果を推進する動きを支えた。
読者向けのマイルストーンタイムライン
- 1998年: PageRank とオリジナルの Google 論文がリンクを介した関連性の基盤を築く。
- 2000年代初頭: 統計的スペル補正やクエリ提案が「did you mean」や言い換えを改善。
- 2011年: Panda が低品質コンテンツを標的にし、品質シグナルがより体系的になる。
- 2012年: Penguin がリンク操作にペナルティを与え、手動ルールを超えた対スパムの流れを加速。
- 2015年: RankBrain(学習ベースのランキングコンポーネント)が不慣れまたは曖昧なクエリを助ける。
- 2018–2019年: Neural matching と BERT が特に長いクエリや前置詞に関する言語理解を強化。
- 2021年以降: MUM時代のマルチタスクモデルと「ヘルプフルコンテンツ」取り組みが、より深い意図と有用性のシグナルに向かう動きを促す。
参考に値するソース
信頼性のために一次研究と公共の製品説明を混ぜて引用すると良い:
- 研究論文: Brin & Page(PageRank, 1998)、BERT(Devlin et al., 2018)。
- 公式の検索アナウンスメント: RankBrain、BERT、MUM、Panda/Penguin の Google Search ブログ投稿。
- 講演/インタビュー: Amit Singhal のランキング進化に関するインタビュー、Sundar Pichai の基調講演(Google I/O)、現代のマイルストーンに関する「Search On」イベント。
研究文化:長い賭けを有用なシステムに変える
グーグルのロングゲームは大きなアイデアを持つだけでなく、学術論文のような成果を何百万もの人が実際に使うものに変えられる研究文化に依存していました。つまり好奇心を評価しつつ、プロトタイプから信頼できるプロダクトへとつなげるための経路を作ることです。
「公開(publish)」から「出荷(ship)」へ
多くの企業は研究を別世界と扱います。グーグルはより密なループを促進しました:研究者は野心的な方向を探究し、結果を公開しつつもレイテンシ、信頼性、ユーザー信頼を気にするプロダクトチームと協力できたのです。そのループが機能すると、論文はゴールではなく、より良いシステムを作るための出発点になります。
このことがわかりやすく現れるのは、モデルのアイデアが「小さな」機能に現れる方法です:より良いスペル補正、賢いランキング、改善された推薦、より自然な翻訳。各ステップは漸進的に見えるかもしれませんが、一緒になると検索の実感を変えます。
ペースを作った象徴的な取り組み
いくつかの取り組みは、論文から製品へのパイプラインの象徴となりました。Google Brain は十分なデータと計算があれば深層学習が従来手法を上回ることを証明して、社内に深層学習を広めました。後には TensorFlow がチーム間でモデルを一貫して学習・デプロイしやすくし、これは機械学習を多くのプロダクトにスケールさせるための地味だが重要な要素でした。
ニューラル機械翻訳、音声認識、ビジョンシステムの研究も同様にラボの成果から日常体験へと移り、多くの場合品質改善とコスト削減を伴う複数の反復を経て実用化されました。
忍耐が重要な理由
リターンの曲線はめったに即時ではありません。初期バージョンは高コストで不正確だったり統合が難しかったりします。優位はインフラを構築し、フィードバックを集め、モデルを繰り返し改善して信頼できるものにするまでアイデアを維持することから生まれます。
その忍耐—長期的賭けに資金をつぎ込み、迂回を受け入れ、何年もかけて反復すること—が野心的なAI概念をグーグル規模で信頼される有用なシステムへと変えるのを助けました。
新しい入力:音声、画像、動画がより賢いモデルを強制した
テキスト検索は巧妙なランク付けトリックを報いてきました。しかしグーグルが音声、写真、動画を取り込み始めた瞬間、旧来のアプローチは限界にぶつかりました。これらの入力は雑多です:アクセント、背景ノイズ、ぼやけた画像、手ブレ、スラング、書かれていない文脈。これらを有用にするには、手書きのルールではなくデータからパターンを学ぶシステムが必要でした。
音声:音を意図へ変える
音声検索や Android の音声入力では、単に「単語を文字起こしする」以上のことが目標でした。それは迅速に、デバイス上または不安定な接続でも相手の意図を理解することです。
音声認識は大規模で多様な音声データセットで訓練すると性能が向上するため、グーグルを大規模機械学習への投資へと押しやりました。そのプロダクト圧力は訓練のための計算、専門的なツール(データパイプライン、評価セット、デプロイシステム)への真剣な投資を正当化しましたし、モデルを生きた製品として反復して改善する人材の採用も促しました。
写真:メタデータではなく意味
写真にはキーワードがついていません。ユーザーはタグ付けしていなくても「犬」や「ビーチ」や「パリ旅行」を見つけられることを期待します。
その期待は物体検出、顔のグルーピング、類似検索といったより強力な画像理解を必要としました。ルールでは現実の多様性をカバーできないため、学習システムが実用的な道筋になったのです。精度を上げるにはより多くのラベル付きデータ、改善された訓練インフラ、迅速な実験サイクルが必要でした。
動画と推薦:スケールが弱点を露呈する
動画は二重の課題を加えます:連続する画像に加えて音声がある。YouTube の検索、キャプション、「次はこれ」、安全フィルターを助けるには、トピックや言語を超えて一般化できるモデルが必要でした。
推薦は機械学習の必要性をさらに明確にしました。何十億ものユーザーがクリックし、視聴し、スキップし、戻ると、システムは継続的に適応しなければなりません。その種のフィードバックループは、モデルを壊さずに改善し続けるためのスケーラブルな訓練、指標、才能への投資に自然と報います。
AIファーストの転換:AIを機能ではなくデフォルトにする
開発予算を有効活用する
自分の成果を共有したり他の人をKoder.aiに紹介することでクレジットを獲得する。
「AIファースト」は製品上の決定として最も分かりやすく説明できます:AIを脇に置かれた特別なツールとして追加するのではなく、人々が既に使っているすべてのものの内部にエンジンとして組み込むのです。
グーグルはこの方向性を2016–2017年頃に公に説明し、モバイルファーストからAIファーストへの転換として位置づけました。アイデアはすべての機能が突然「スマート」になるということではなく、製品が改善されるデフォルトの方法が学習システム—ランキング、推薦、音声認識、翻訳、スパム検出—を通じて行われるようになる、ということです。
コアループの内部にAIを置く
実際には、AIファーストは製品の「コアループ」が静かに変わるときに現れます:
- 検索結果はチームが何千もの if-then ルールを手書きで追加するのではなく、クエリとクリックのパターンから学ぶことで改善される。
- 写真はファイル名やフォルダだけで整理されるのではなく、写っているものに基づいて整理される。
- Gmail は既知のキーワードを単にマッチさせるだけでなく、進化する行動を学んでより多くの迷惑メールを捕捉する。
ユーザーは「AI」と書かれたボタンを見ることはないかもしれません。間違いが減り、摩擦が少なくなり、答えが速くなることに気づくだけです。
アシスタントが自然言語の水準を引き上げた
音声アシスタントや会話型インターフェースは期待を変えました。「家に着いたら母に電話するようにリマインドして」と言えば、ソフトウェアが意図、文脈、日常の曖昧さを理解することを人々は期待し始めます。
それは製品を自然言語理解を基盤機能として持つ方向へ促しました—音声、入力、さらにはカメラに向けて何かを指して「これは何?」と尋ねるような操作まで含む。したがってこの転換は研究上の野心だけでなく、新しいユーザー習慣に応えることでもありました。
重要なのは、「AIファースト」は方向性として読むのが最適であり、すべてのアプローチを即座に置き換えたと主張するものではないという点です。
Alphabet とロングゲーム:検索を超えた賭けのための余地
2015年のAlphabetの創設はリブランディングというより運営上の判断でした:成熟した収益を生むコア(Google)をリスクの高い長期の取り組み(いわゆる「Other Bets」)から切り離すことです。その構造は、ラリー・ペイジのAIビジョンを単一の製品サイクルではなく数十年のプロジェクトとして考える際に重要です。
なぜ「コア」と「賭け」を分けたのか
Google 検索、広告、YouTube、Android は徹底した実行を必要とします:信頼性、コスト管理、継続的な反復。一方でムーンショット—自動運転車、生命科学、接続性プロジェクト—は違ったものを必要としました:不確実性への寛容、高価な実験の余地、失敗する許可。
Alphabetの下では、コアは明確な業績期待のもとで管理され、賭けは「重要な技術的仮定を検証したか?」「実世界データでモデルは十分改善したか?」「許容できる安全性レベルで問題が解けるか?」といった学習マイルストーンで評価できました。
ムーンショットの論理:実験を戦略にする
この「ロングゲーム」思考はすべてのプロジェクトが成功するとは想定しません。持続的な実験こそが後に重要になることを発見する方法だと想定します。
Xのようなムーンショット工場は良い例です:チームは大胆な仮説を試し、結果を計測し、証拠が弱ければ速やかにアイデアを止めます。この規律は特にAIに関係が深く、進歩はしばしば単一のブレークスルーではなく反復(より良いデータ、より良い訓練セットアップ、より良い評価)に依存します。
取るべき教訓(約束ではなく)
Alphabetは将来の勝利を保証するものではありませんでした。それは二つの異なる作業リズムを保護する方法でした:
- コアビジネスを集中し説明責任ある形で維持する。
- 高分散な研究や製品ベットのために明確な拠点を作る。
チームにとっての教訓は構造的です:長期的なAI成果を望むなら、それに合わせて設計しなさい。短期の提供と探索的作業を分け、実験を学習の手段として資金提供し、見出しだけでなく検証された洞察で進捗を測る。
難しい点:大規模での品質、安全性、信頼
成果物を自分のものにする
フルパイプラインを所有する準備ができたら、ソースコードをエクスポートしてコントロールを保つ。
AIシステムが何十億ものクエリに応えるとき、小さなエラー率が毎日の見出しになります。「ほとんど正しい」モデルでも数百万を誤導しかねません—特に健康、金融、選挙、速報に関しては。グーグル規模では品質は単なる好みではなく、累積する責任です。
中核的なトレードオフ
バイアスと表現。 モデルはデータからパターンを学ぶため、社会的・歴史的バイアスを学ぶ可能性がある。「中立的」なランキングでも支配的な見解を増幅したり、少数言語や地域を十分に扱えなかったりする。
誤りと過度の自信。 AIは説得力のある形で失敗することがある。最も害をもたらすエラーは明白なバグではなく、ユーザーが信頼してしまうもっともらしい誤答であることが多い。
安全性対有用性。 強いフィルタは害を減らすが正当なクエリを遮断することもある。緩いフィルタはカバレッジを上げるが詐欺や自己危害、誤情報を許してしまう危険がある。
説明責任。 システムが自動化されるほど、「誰がこの振る舞いを承認したのか」「どのようにテストされたのか」「ユーザーはどう異議を申し立てるか」を答えるのが難しくなる。
スケールするとガードレールの必要性が増す理由
スケールは能力を高めますが、同時に:
- エッジケースの数(言語、文化、敏感な文脈)が増える
- 悪用のインセンティブが高まる(スパム、プロンプトインジェクション、敵対的SEO)
- 製品全体に統合されると失敗のロールバックが難しくなる
だからガードレールもスケールさせる必要があります:評価スイート、レッドチーミング、ポリシー適用、ソースの出所情報、そして不確かさを示す明確なユーザーインターフェース。
AIの主張を評価するための実用チェックリスト
どんな「AI搭載」機能でも(グーグルのものでも他社のものでも)評価するために次を使ってください:
- 失敗モードは何か? デモだけでなくどこで壊れるかを示しているか?
- どう測定しているか? 曖昧な「改善」ではなく実際の指標(精度、毒性率、幻覚率)を示しているか?
- 何に訓練されているか? 最低でも広いカテゴリ、最新性、除外ポリシーを示しているか?
- ガードレールは何か? 安全ルール、人間による確認経路、悪用監視はあるか?
- ユーザーは検証できるか? 引用、リンク、または主張を確認できる説明があるか?
- 訂正はどう扱うか? 明確な報告、迅速な更新、監査可能性があるか?
信頼は繰り返し可能なプロセスを通じて得られるもので、単一のブレークスルーモデルではありません。
チームへの教訓:AIを長期で考える方法
グーグルの長期的アークのもっとも移植可能なパターンは単純です:「明確な目標 → データ → インフラ → 反復」。このループを使うのにグーグルのスケールは必要ありません—最も重要なのは何を最適化しているかについての規律と、実際の利用から学ぶ方法(自分を騙さないこと)です。
コピーできるコアパターン
ひとつの測定可能なユーザー向け約束(速度、エラー削減、より良いマッチング)から始めてください。それを観測できるようにインストルメント化し、改善を安全に収集・ラベリング・出荷できる最小限の「機械」を構築する。次に小さく頻繁なステップで反復し、各リリースを学習の機会として扱う。
「アイデア」から「計測されたプロダクト」へ速く移動することがボトルネックであるなら、現代のビルドワークフローが役に立ちます。たとえば Koder.ai はチャットインターフェースからウェブ、バックエンド、モバイルアプリを生成できるビジュアルコーディングプラットフォームで、フィードバックループ(賛否評価、問題報告、クイック調査)を含むMVPを数週間待たずに立ち上げるのに便利です。計画モードやスナップショット/ロールバックのような機能は「安全に実験し、測定し、反復する」原則に合致します。
リーダーが適用できる6つの教訓(グーグルである必要はない)
- ユーザー向けのノーススターを選ぶ。 「AIを導入する」よりも「検索体験を改善する」の方が明確だ。成功を人々が実感できる形で定義する。
- プロダクトを学習データを生むように設計する。 サムズアップ/ダウン、修正、 「役に立ったか?」など意図を捉えるフィードバックループを追加する。
- モデルだけでなく配管に早期投資する。 データ品質チェック、評価ダッシュボード、デプロイワークフローはワンオフのプロトタイプより勝る。
- 評価をプロダクト機能として扱う。 品質、レイテンシ、コスト、安全性の反復可能なスコアカードを作り、反復が手探りにならないようにする。
- スライスで出荷する。 狭いユースケースから始め、小さなユーザーで展開し、測定して拡大する。大規模一斉リリースより勢いが重要。
- 長期の賭けが生き残れるようにする。 実験のために小さなキャパシティを保護しつつ、学習マイルストーンを求めて正当性を保つ。
関連読むべき記事
実務的な次のステップを知りたいなら、チームのリーディングリストにこれらを追加してください:
- /blog/ai-strategy-basics
- /blog/data-flywheels-for-product-teams
- /blog/evaluating-ml-models-without-a-phd
- /blog/ai-governance-lightweight