2025年10月10日·1 分
アプリケーション向けRedis:パターン、落とし穴、実践的なヒント
Redisをアプリで実践的に使う方法を学ぶ:キャッシュ、セッション、キュー、Pub/Sub、レート制限、さらにスケーリング、永続化、監視、注意点まで。
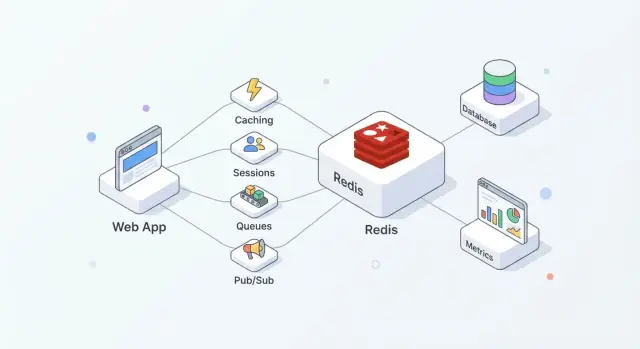
Redisをアプリで実践的に使う方法を学ぶ:キャッシュ、セッション、キュー、Pub/Sub、レート制限、さらにスケーリング、永続化、監視、注意点まで。
Redisはインメモリのデータストアで、アプリの共有「高速レイヤ」としてよく使われます。採用が容易で、一般的な操作に対して非常に高速であり、キャッシュ、セッション、カウンタ、キュー、Pub/Sub といった複数の役割をひとつのシステムでこなせる点が評価されています。
実務では、Redisを**速度+調整(coordination)として扱い、プライマリのデータベースを真の情報源(source of truth)**に残しておくのが最も有効です。
よくある構成は次のとおりです:
この分離によりDBは正確性と耐久性に集中でき、Redisが高頻度の読み書きを吸収して遅延や負荷を下げます。
うまく使えば、Redisは次のような実益をもたらします:
RedisはプライマリDBの代わりではありません。複雑なクエリ、長期保存の保証、分析系レポートが必要ならDBが適切です。
また、Redisが「デフォルトで耐久的」とは限りません。数秒分のデータ喪失が許されないなら、永続化設定を慎重に行うか、別のシステムを検討してください。
Redisはしばしば「キー・バリュー・ストア」と表現されますが、鍵で小さなデータ片を保持・操作できる非常に高速なサーバであると考える方が有用です。このモデルは予測可能なアクセスパターンを促し、通常はセッション、キャッシュ、カウンタなど「何を取りに行くか」が明確です。Redisは単一ラウンドトリップで取得・更新できます。
RedisはデータをRAMに置くため、マイクロ秒〜ミリ秒で応答できます。代償はRAMがディスクよりも制限的で高価なことです。
早い段階でRedisを次のどちらとして扱うか決めてください:
Redisはディスクへの永続化(RDBスナップショットやAOF)を提供しますが、永続化は書き込みオーバーヘッドを増やし、耐久性のトレードオフ(「速いが秒単位のデータ損失があり得る」対「遅いが安全」)を伴います。永続化はビジネスインパクトに応じて調整するダイヤルだと考えてください。
Redisは主に単一スレッドでコマンドを実行しますが、操作は通常小さく、複数ワーカースレッド間のロックオーバーヘッドがない点を考えると効率的です。重いコマンドや過大なペイロードを避ければ、高い同時性下でも非常に効率的に動きます。
アプリはTCPを介してクライアントライブラリでRedisと話します。コネクションプーリングを使い、リクエストは小さく保ち、複数操作が必要なときはバッチ/パイプラインを優先してください。
タイムアウトとリトライの計画を立てましょう:Redisは高速ですがネットワークはそうではなく、Redisが混雑したり一時的に利用できないときにアプリが優雅に劣化するようにする必要があります。
新しいサービスを作る際、Koder.ai のようなプラットフォームはReact + Go + PostgreSQLアプリのスキャフォールドを手早く作り、チャット駆動のワークフローでRedisを使った機能(キャッシュ、セッション、レート制限)を追加しつつ、ソースコードをエクスポートして好きな場所で動かせる柔軟性を提供します。
キャッシュが役に立つのは、誰が埋めるか、誰が無効化するか、「十分に新しい」の意味が明確なときだけです。
キャッシュアサイドではアプリが読み書きを制御します。
典型的なフロー:
Redisは高速なキー・バリューストアなので、シリアライズやバージョニング、期限切れの扱いはアプリが決めます。
TTLは技術的判断だけでなくプロダクト判断でもあります。短いTTLは古さを減らしますがDB負荷を増やし、長いTTLは仕事を節約しますが古い結果を返すリスクが上がります。
実務的なヒント:
user:v3:123)。\n- 意図的に古いデータを扱う:ビューによってはわずかに古いコンテンツで問題ない場合がある(在庫や認証はそうではない)。ホットキーが期限切れになると、多数のリクエストが同時にミスすることがあります。
一般的な対策:
良い候補は APIレスポンス、高コストなクエリ結果、計算済みオブジェクト(推薦、集約)です。フルHTMLページのキャッシュも使えますが、パーソナライゼーションや権限に注意し、ユーザ固有ロジックがある場合はフラグメントキャッシュにするのが安全です。
Redisは短期間のログイン状態(セッションID、リフレッシュトークンのメタデータ、デバイス記憶フラグ)を置くのに実用的です。目的は認証を高速化しながら、セッションの寿命と即時無効化を厳密に管理することです。
一般的なパターンは、アプリがランダムなセッションIDを発行し、コンパクトなレコードをRedisに保存してそのIDをHTTP-onlyクッキーでブラウザに返すことです。各リクエストでセッションキーを参照し、ユーザIDと権限をリクエストコンテキストに付与します。
Redisはセッション読み取りが頻繁であり、有効期限が組み込まれているためここで効果的に機能します。
キーはスキャンや取り消しがしやすいよう設計します:
sess:{sessionId} → セッションペイロード(userId、issuedAt、deviceId)\n- user:sessions:{userId} → アクティブなセッションIDのSet(任意。「全端末ログアウト」に便利)sess:{sessionId} に対してセッション寿命と一致するTTLを設定します。セッションをローテーションする場合(推奨)、新しいセッションIDを作り古いものは即削除してください。
「スライディング有効期限(リクエストごとにTTLを延ばす)」はヘビーユーザでセッションが永続化してしまうため、期限が近いときのみ延長するなど安全策を講じるのが良いトレードオフです。
単一デバイスをログアウトするには sess:{sessionId} を削除します。
全端末ログアウトの方法:
user:sessions:{userId} にある全セッションIDを削除する、または\n- user:revoked_after:{userId} のタイムスタンプを保持し、それ以前に発行されたセッションは無効と扱うタイムスタンプ方式は大規模なファンアウト削除を避けられます。
Redisには必要最小限を保存し、個人データは避けてIDを優先してください。生パスワードや長期シークレットは絶対に保存しないでください。トークン関連データを保存する場合はハッシュ化して短いTTLを使いましょう。
Redisへの接続を制限し、認証を必須にし、セッションIDは推測困難な高エントロピーにしてください。
レート制限はRedisが得意とする領域です:高速でアプリ全体で共有され、原子的な操作により高トラフィック下でもカウンタの整合性を保てます。ログイン、コストの高い検索、パスワードリセット、スクレイピングや総当たり攻撃の防止に有効です。
固定ウィンドウ:最も簡単(例:「1分間に100リクエスト」)。概念は簡単だが境界でバーストを許してしまうことがある(例、12:00:59に100件、12:01:00にさらに100件)。
スライディングウィンドウ:過去N秒/分を見て滑らかにする。公平だが実装コストが高く、ソート済み集合などの管理が必要になることが多い。
トークンバケット:バースト処理が得意。利用者は時間経過でトークンを蓄積し上限まで溜まり、リクエストごとにトークンを消費する。短いバーストを許しつつ平均レートを制限できる。
固定ウィンドウのよくあるパターン:
INCR key でカウンタを増やす\n- EXPIRE key window_seconds でTTLを設定/リセットする問題は INCR と EXPIRE を別々に呼ぶと、その間にクラッシュすると期限のないキーが残る点です。
安全な方法:
INCR と初回作成時の EXPIRE をLuaスクリプトでまとめて行う。\n- あるいは初期化に SET key 1 EX <ttl> NX を使い、その後 INCR する(競合回避のためスクリプトで包むのが通常安全)。トラフィックが急増する場面では原子操作が重要です。そうしないと二つのリクエストが同じ残量を見て両方通過してしまうことがあります。
多くのアプリは複数の層を必要とします:
rl:user:{userId}:{route})\n- IP別(匿名または事前認証エンドポイント、例:サインイン試行)\n- ルート別(検索やエクスポートなどホットスポットを保護)バーストがあるエンドポイントではトークンバケットか、寛容な固定ウィンドウに短いバーストウィンドウを併用すると正当なスパイクを罰しにくくなります。
"安全"の定義を事前に決めてください:
一般的な妥協策は低リスクなルートはfail-open、ログインやパスワードリセット、OTPなどセンシティブなルートはfail-closedにすることです。レート制限が止まった瞬間に気づけるよう監視を入れておくことも重要です。
Redisはメール送信、画像リサイズ、データ同期、定期タスクなど軽量キューを求める場合に使えます。重要なのは適切なデータ構造を選び、リトライと失敗処理のルールを明確にすることです。
Lists は最も単純なキューで、プロデューサは LPUSH、ワーカーは BRPOP を使います。簡単ですが「インフライト」ジョブ管理、リトライ、可視性タイムアウトのロジックを自前で作る必要があります。
Sorted sets はスケジューリングに優れます。スコアをタイムスタンプ(あるいは優先度)として、次に実行すべきジョブを取得します。遅延ジョブや優先度付きキューに向きます。
Streams は耐久的なワーク分配のデフォルトとして優れていることが多いです。コンシューマグループ、履歴保持、複数ワーカーの協調などを標準でサポートします。
Streamsのコンシューマグループではワーカーがメッセージを読み、後でACKします。ワーカーがクラッシュするとメッセージはpendingのまま残り、別のワーカーがclaimできます。
リトライには試行回数を追跡し(メッセージペイロードかサイドキーで)、指数バックオフで再実行し、最大試行回数を超えたらデッドレターキュー(別のストリームやリスト)に移して手動確認に回します。
ジョブは二度実行される可能性があると仮定して設計します:
job:{id}:done)を SET ... NX で作ってから副作用処理を行う。\n- 操作を「無条件作成」ではなくアップサートで設計する。\n- サードパーティAPI呼び出し時は外部のリクエストIDを記録する。ペイロードは小さく保ち(大きなデータは外部に置く)、キュー長を制限して遅延が増えたらプロデューサを遅くするなどバックプレッシャを実装します。保留深度と処理時間に基づいてワーカーをスケールするのも有効です。
Redis Pub/Subはイベントをブロードキャストする最も簡単な方法です:パブリッシャがチャネルにメッセージを送り、接続中の全サブスクライバが即時に受け取ります。ポーリング不要の軽量なプッシュで、リアルタイム更新に適しています。
Pub/Subは速度とファンアウトを重視し、配信保証を必要としないケースに向きます:
ラジオ放送に例えるとわかりやすい:聴いている人全員が放送を聞くが、自動で録音が残るわけではない。
Pub/Subには重要なトレードオフがあります:
従って、すべてのイベントを確実に処理する必要があるワークフローには不向きです。
耐久性、リトライ、コンシューマグループ、バックプレッシャの扱いが必要なら、Redis Streamsの方が適しています。Streamsはイベントを保存し、ACKで処理を管理し、再起動後の回復も可能にします。軽量メッセージキューに近い機能です。
実運用では複数インスタンスがサブスクライブすることになります。実務的なヒント:
app:{env}:{domain}:{event}(例:shop:prod:orders:created)。\n- ブロードキャスト用とターゲット用チャネルを分ける:notifications:global と notifications:user:{id} のように。\n- ペイロードは小さく自己完結させる:IDと最小メタデータだけを含め、詳細は必要に応じて別途取得する。このように使えば、Pub/Subは高速なイベントシグナル役になり、失えないイベントはStreamsや別のキューで処理できます。
データ構造の選択は「動くから」という理由だけで決めると後でメモリやクエリ速度、コードの複雑化で困ります。将来どう読み出すか(読み取りパターン)に合った構造を選ぶのが基本です。
INCR/DECR を使った原子カウンタにも。\n- Hashes:フィールドを持つオブジェクト(ユーザのプロファイルフィールド、カートの合計)。個々のプロパティを頻繁に更新する場合に有利。\n- Sets:一意性やメンバシップチェック(ユーザがクーポンXを既に獲得しているか)に最適。SISMEMBER が高速で集合演算も簡単。\n- Sorted sets (ZSETs):ランキングや「上位N」クエリ(リーダーボード、優先度リスト、時間ベースのスコア)に向く。Redisのコマンドはコマンド単位で原子的に実行されるので、カウンタの競合は回避できます。ページビューやレート制限のカウンタは文字列で INCR にTTLを組み合わせる典型例です。
リーダーボードはsorted setsが得意:ZINCRBY でスコアを更新し、ZREVRANGE で上位を効率的に取得できます。
user:123:name、user:123:email、user:123:plan のように多数のキーを作ると、キーごとのオーバーヘッドが増えて管理が煩雑になります。
user:123 のようなハッシュにフィールド(name、email、plan)をまとめれば関連データを一つのキーに集約でき、部分更新が容易になります。
迷ったら小さなサンプルでモデリングしてメモリ使用量を測定してから本番運用に移してください。
Redisは「インメモリ」と呼ばれますが、ノード再起動やディスク満杯、サーバ消失時にどうするか選べます。適切な構成は、許容できるデータ損失量と復旧速度によって決まります。
RDBスナップショットはデータセットの時点ダンプを保存します。コンパクトで起動時の読み込みが速く、再起動が速いのが利点です。欠点は、最後のスナップショット以降の書き込みを失う可能性があることです。
**AOF(append-only file)**は書き込み操作を逐次ログとして残します。通常はデータ損失が少なくなりますが、ファイルが大きくなり起動時のリプレイに時間がかかることがあります。RedisはAOFのリライトでファイルを圧縮できます。
多くのチームは両方を運用し、スナップショットで起動を速め、AOFで書き込み耐久性を高めています。
永続化は無料ではありません。ディスク書き込み、AOFのfsyncポリシー、バックグラウンドのリライト処理は、ストレージが遅いか飽和している場合にレイテンシスパイクを引き起こす可能性があります。一方で永続化があれば再起動時の空っぽ状態を防げます。
レプリカはデータのコピーを保持してプライマリ障害時のフェイルオーバーを可能にします。通常の目標は可用性優先であり、完全な一貫性を保証するわけではありません。障害時にはレプリカが若干遅れることがあり、フェイルオーバーで最後の数書き込みが失われるシナリオもあり得ます。
何かを調整する前に2つの数値を決めてください:
これらの目標に基づきRDB頻度、AOF設定、レプリカの有無・自動フェイルオーバーの必要性を決めます(Redisをキャッシュ、セッションストア、キュー、あるいは主要データストアとして使うかで選択が変わります)。
単一のRedisノードでかなりの範囲をカバーできます:運用が簡単で動作が分かりやすく、多くのキャッシュ、セッション、キューのワークロードには十分です。
スケールが必要になるのは通常、メモリ上限、CPU飽和、または単一ノードが単一障害点になって受け入れられないときです。
次のいずれかに該当したらノード追加を検討します:
実務的な第一歩は、クラスタに飛ぶ前にワークロードを分離して二つの独立Redisインスタンスにすることです。
シャーディングはキーを複数ノードに分割し、各ノードがデータの一部だけを持つようにすることです。Redis Clusterはこの仕組みを自動化し、キー空間をスロットに分けて各ノードがいくつかのスロットを所有します。
利点は総メモリと総スループットの増加です。トレードオフは複雑性の増加:マルチキー操作が同一シャード上でしか動作しなくなったり、トラブルシューティングが難しくなります。
均等シャーディングでも実際のトラフィックは偏ることがあります。単一の人気キー("ホットキー")が1ノードを過負荷にし、他は遊んでいることがある。
対策は短いTTLとジッターを入れる、値を複数キーに分割する(キーのハッシュ化)、あるいは読み取りを分散させるようにアクセスパターンを見直すなどです。
Redis Clusterではトポロジを発見し適切なノードへルーティングし、スロット移動時にリダイレクトを追えるクラスタ対応クライアントが必要です。
移行前に確認すること:
スケーリングは計画的に行うと効果的です:ロードテストで検証し、キーごとのレイテンシを計測し、トラフィックを段階的に移行してください。
Redisは内部インフラとみなされがちですが、それゆえに露出すると重大なリスクになります。単一の公開ポートが全データ漏洩や攻撃者によるキャッシュ操作につながることがあります。Redisは一時データであっても機密扱いで運用してください。
まず認証を有効にし、ACL(Redis 6+)を使ってください。ACLでできること:
全コンポーネントで共通のパスワードを使うのは避け、サービスごとに権限を絞った資格情報を発行してください。
最も効果的なのは到達できないようにすることです。Redisをプライベートインターフェースにバインドし、プライベートサブネットに置き、必要なサービスだけが接続できるようセキュリティグループ/ファイアウォールで制限してください。
Redisトラフィックがホスト境界を越える(AZ間、共有ネットワーク、Kubernetesノード、ハイブリッド環境)場合はTLSを使って盗聴や資格情報漏洩を防いでください。セッションやトークン、ユーザ関連データを扱うなら小さなオーバーヘッドに見合う価値があります。
乱用されると重大なダメージを与えるコマンドはACLでロックダウンしてください。代表例:FLUSHALL、FLUSHDB、CONFIG、SAVE、DEBUG、EVAL(スクリプトを厳密に管理すること)など。rename-commandで隠す手法もありますが、ACLの方が監査しやすく明確です。
Redisの資格情報はシークレットマネージャに保管し、コードやコンテナイメージに埋め込まないでください。ローテーションを計画し、クライアントが再デプロイなしで資格情報をリロードできるか、移行ウィンドウ中に2つの有効な資格情報を許す仕組みがあるとローテーションが容易になります。
実用的なチェックリストはランブックと一緒に保管し、/blog/monitoring-troubleshooting-redis のような運用ノートを用意しておくと便利です。
Redisは“問題なさそうに見える”ことが多いですが、トラフィックの変化、メモリの増加、重いコマンドの発生で簡単に問題になります。軽量な監視と明確なインシデントチェックリストがあれば多くの驚きを防げます。
チーム全員が説明できる小さなセットから始めてください:
「遅い」と感じたらRedis自身のツールで確認を:
KEYS、SMEMBERS、大きな LRANGE の呼び出しが増えていないかをチェックする。レイテンシが上がっているのにCPUは平常という場合、ネットワーク飽和、過大なペイロード、ブロックされたクライアントも疑ってください。
成長に備えて**余裕(headroom)**を確保してください(一般的に20〜30%の空きメモリ)。ローンチや新機能後には仮定を見直す習慣をつけ、持続的なエビクションは障害として扱ってください。
インシデント時に順番にチェックする項目:メモリ/エビクション、レイテンシ、クライアント接続、slowlog、レプリケーションラグ、最近のデプロイ。再発する原因を記録して恒久対策を入れましょう。アラートだけでは不十分です。
チームが素早く反復するなら、これら運用期待値を開発ワークフローに組み込むと良いです。例えば、Koder.ai のプランニングモードやスナップショット・ロールバックを使えば、Redisを使った機能(キャッシュやレート制限)をプロトタイプして負荷テストし、実装をソースコードとしてエクスポートしつつ安全に差し戻せます。
Redisは共有されるインメモリの「高速レイヤ」として最適です:
耐久性と複雑なクエリはプライマリDBに任せ、Redisはアクセラレータ兼コーディネータと考えてください。
いいえ。Redisは永続化の選択肢を持ちますが、「デフォルトで耐久的」ではありません。複雑なクエリや強い耐久保証、分析・レポーティングが必要ならプライマリDBに保持してください。
数秒分のデータ喪失が許容できない場合、Redisの永続化設定だけで要件を満たせるとは限りません。慎重に設定するか、別のシステムを検討してください。
許容できるデータ損失と再起動時の振る舞いに基づいて決めます:
キャッシュアサイドではアプリがロジックを管理します:
ミスが時々発生しても許容でき、期限/無効化の方針が明確な場合に適しています。
TTLはユーザー体験とバックエンド負荷のトレードオフです:
user:v3:123)を使う。\n- フィードは多少古くても良いが、認証や在庫は古さが許されない、といった区別を明確にする。\n
迷うときは短めで始めて、DB負荷を見ながら調整してください。以下のいずれか(または複数)を使います:
これらで同時ミスによるDB過負荷を避けられます。
一般的な方法は:
sess:{sessionId} にセッションデータをTTL付きで保存する(セッション寿命に合わせる)。\n- 必要なら user:sessions:{userId} をアクティブなセッションIDのSetとして保持し、「全端末ログアウト」に使う。\n- 最小限のデータ(IDやタイムスタンプ)だけを保存し、個人情報は避ける。「スライディング有効期限」(リクエストごとにTTLを延ばす)は重いユーザーでセッションが永続化してしまうため、期限が近いときだけ延長するなどの制御が望ましいです。
原子性を担保してカウンタが競合しないようにします:
INCR と EXPIRE を別々に裸で実行しない。クラッシュでTTLが設定されないリスクがあるためです。\n- INCR と初回作成時の EXPIRE をLuaスクリプトでまとめて行うか、 で初期化してから を使う(ただし競合回避のためスクリプト推奨)。\n
キーのスコープは用途に応じて設計(、IP別、ルート別など)し、Redisが使えないときにどう振る舞うか(fail-openかfail-closedか)を事前に決めておくことも重要です。用途と運用ニーズで選びます:
ジョブのペイロードは小さく保ち、大きなデータは別に保存して参照を渡すようにしてください。
Pub/Subはリアルタイムなブロードキャスト向け(欠落が許容される場面)に使います:
全てのイベントを確実に処理する必要があるなら、耐久性とACKを持つRedis Streamsを選んでください。また運用面ではACLやネットワーク隔離、レイテンシやエビクションの監視を行い、/blog/monitoring-troubleshooting-redis のようなランブックを用意しておくと良いでしょう。
SET key 1 EX <ttl> NXINCRrl:user:{userId}:{route}