2025年11月14日·1 分
リードレプリカが存在する理由と実際に役立つ場面
リードレプリカが存在する理由、解決する問題、実際に役立つ/裏目に出る場面を解説します。一般的なユースケース、制限、実務的な判断ポイントを含みます。
リードレプリカが存在する理由、解決する問題、実際に役立つ/裏目に出る場面を解説します。一般的なユースケース、制限、実務的な判断ポイントを含みます。
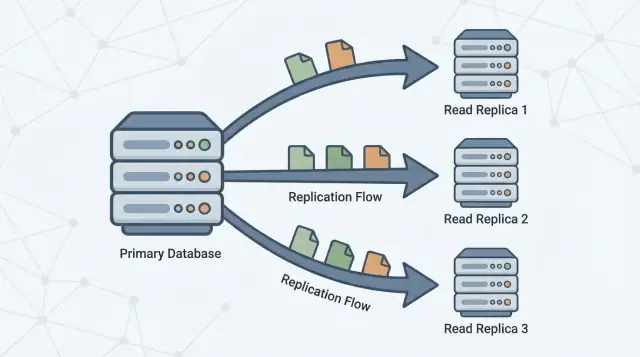
リードレプリカは、メインのデータベース(しばしばプライマリと呼ばれる)のコピーで、プライマリから継続的に変更を受け取り最新状態を保ちます。アプリはレプリカに読み取り専用のクエリ(例:SELECT)を送れる一方、プライマリは引き続きすべての書き込み(INSERT、UPDATE、DELETEなど)を処理します。
約束はシンプルです:プライマリに余計な負荷をかけずに読み取りキャパシティを増やすこと。
アプリにホームページ、商品ページ、ユーザープロファイル、ダッシュボードなどの“取得”トラフィックが多い場合、それらの読み取りの一部を一つ以上のレプリカに移すことでプライマリが書き込みと重要な読み取りに集中できるようになります。多くの構成ではアプリ側の変更は最小限で済みます:一つのデータベースをソースオブトゥルースとして残し、レプリカをクエリ先として追加するだけです。
リードレプリカは有用ですが魔法のボタンではありません。次のことはできません:
レプリカを「トレードオフのある読み取りスケーリング手段」と考えてください。以下では、実際に役立つ場面、よく裏目に出るパターン、そしてレプリケーションラグや最終的整合性がレプリカから読む際にユーザが見る挙動にどう影響するかを説明します。
単一のプライマリデータベースサーバーは、最初は“十分大きい”ように見えます。書き込み(インサート、更新、削除)を処理し、アプリ、ダッシュボード、内部ツールからのすべての読み取り(SELECT)にも応答します。
利用が増えると、通常読み取りが書き込みよりも早く増えます:ページビューごとに複数のクエリが走ることがあり、検索画面は多くのルックアップを発生させ、分析系クエリは大量の行をスキャンします。書き込み量が中程度でも、プライマリは変更を安全に素早く受け入れることと、増え続ける読み取りトラフィックに低レイテンシで応答するという二つの仕事を同時にこなさねばならず、ボトルネックになり得ます。
リードレプリカはその負荷を分割するために存在します。プライマリは書き込みと“真実のソース”の維持に集中し、1つ以上のレプリカが読み取り専用クエリを処理します。アプリがレプリカに一部のクエリをルーティングできれば、プライマリのCPU、メモリ、I/O負荷が減り、全体的な応答性が改善し、書き込みバーストに対する余裕が生まれます。
レプリケーションは、プライマリから他のサーバに変更をコピーしてレプリカを最新に保つ仕組みです。プライマリが変更を記録し、レプリカがそれらを適用してほぼ同じデータでクエリに応答できるようにします。
このパターンは多くのデータベースシステムやマネージドサービス(PostgreSQL、MySQL、クラウドのバリアントなど)で共通です。実装の細部は異なりますが、目的は同じ:プライマリを無限に垂直スケールさせることなく読み取りキャパシティを増やすことです。
プライマリデータベースを“真実のソース”と考えてください。プライマリはすべての書き込み——注文作成、プロファイル更新、支払記録——を受け入れ、それらに確定的な順序を割り当てます。
1つ以上のリードレプリカはプライマリを追いかけ、変更をコピーして読み取りクエリに応答できるようにします(例:「自分の注文履歴を表示」)。
読み取りはレプリカから提供できますが、書き込みは依然としてプライマリへ行きます。
レプリケーションには大きく分けて二つのモードがあります:
レプリカがプライマリに遅れるその差をレプリケーションラグと呼びます。ラグは自動的に障害を意味するわけではなく、読み取りスケールを優先する際によく受け入れられるトレードオフです。
エンドユーザにとって、ラグは最終的整合性として現れます:なにかを変更しても、システムはやがてどこでも一貫した状態になりますが、即座ではないことがあります。
例:メールアドレスを更新してプロファイルページをリフレッシュしたとします。ページが数秒遅れたレプリカから返されると、古いメールアドレスが一瞬表示されるかもしれません——レプリカがその更新を適用して“追いつく”までの間は。
リードレプリカは、プライマリが書き込みには健全だが 読み取りトラフィックの処理に圧倒されている場合に役立ちます。書き込み方法を変えずに意味のある割合のSELECT負荷をオフロードできるときに最も効果的です。
次のようなパターンを探してください:
SELECTの比率がINSERT/UPDATE/DELETEに比べて非常に高いレプリカを追加する前に、いくつかの明確なシグナルで検証してください:
SELECTが占める割合多くの場合、最初に行うべきはチューニングです:適切なインデックスを追加する、クエリを書き直す、N+1呼び出しを減らす、ホットな読み取りをキャッシュする。これらの変更は、レプリカを運用するより速く安く済むことが多いです。
レプリカを選ぶべき場合:
まずはチューニングすべき場合:
リードレプリカは、プライマリがチェックアウト、サインアップ、更新などの書き込みを忙しく処理している一方で、大きな割合のトラフィックが読み取り中心であるときに最も価値があります。プライマリ–レプリカ構成では、適切なクエリをレプリカに押し出すことでアプリケーションの機能を変えずにデータベース性能を改善できます。
ダッシュボードはしばしば長いクエリを実行します:グルーピング、広い日付範囲のフィルタ、複数テーブルの結合など。これらはCPUやメモリ、キャッシュをトランザクション処理と争います。
レプリカは次の用途に向きます:
プライマリは高速で予測可能なトランザクションに集中させ、分析読み取りは独立してスケールさせます。
カタログ閲覧、ユーザープロファイル、コンテンツフィードは類似した多くの読み取りクエリを発生させることがあります。読み取りスケーリングの圧力がボトルネックであれば、レプリカがトラフィックを吸収してレイテンシのスパイクを減らせます。
特に有効なのは、キャッシュミスが多い(多くのユニーククエリ)場合やアプリ側キャッシュだけではまかなえない場合です。
エクスポート、バックフィル、要約の再計算、大規模な検索ジョブはプライマリを乱すことがあります。これらのスキャンをレプリカで実行するのが安全なことが多いです。
ただし、ジョブが最終的整合性を許容すること(レプリカラグにより最新の更新が見えない可能性がある)を確認してください。
グローバルにユーザを提供する場合、レプリカをユーザに近い場所に置くと RTT が短くなります。トレードオフはレプリカラグやネットワーク障害時に古い読み取りにさらされることであり、閲覧やおすすめ、公開コンテンツなど「ほぼ最新」で問題ないページに適しています。
リードレプリカは「十分に近ければ良い」場合に優れています。製品が暗黙にすべての読み取りが最新であると仮定していると、レプリカは裏目に出ます。
ユーザがプロファイルを編集してフォームを送信し、次のページ表示が数秒遅れたレプリカから返されると、更新は成功しているのに古いデータが表示されます。ユーザは再試行したり二重送信したり信頼を失ったりします。
これは、メールアドレスの変更、設定切替、ドキュメントアップロード、コメント投稿後のリダイレクトなど、即時の確認を期待するフローで特に問題になります。
一部の読み取りは短時間でも古さを許容できません:
レプリカが遅れていると誤った合計を表示したり、在庫を過剰販売したり、古い残高を見せる可能性があります。後で正しくなってもユーザ体験とサポート負荷にダメージがあります。
内部ダッシュボードは不正検知、カスタマーサポート、注文処理、モデレーション、インシデント対応など実際の判断を駆動します。管理ツールがレプリカから読んでいると不完全なデータで判断してしまうリスクがあります(例:すでに返金済みの注文に返金をかけるなど)。
一般的なパターンは条件付きルーティングです:
これによりレプリカの利点を保ちつつ、一貫性に関するUXの問題を避けられます。
レプリケーションラグは、プライマリでの書き込みがレプリカで見えるようになるまでの遅延です。アプリがこの遅延中にレプリカから読めば、“古い”結果(直前には正しかったが今は違うデータ)を返す可能性があります。
ラグは正常であり、負荷が増すと通常大きくなります。一般的な原因:
ラグは“鮮度”だけでなく、ユーザから見た正確性にも影響します:
機能がどれだけ古さを許容できるかをまず決めましょう:
レプリカラグ(時間/バイト差)、レプリカの適用率、レプリケーションエラー、レプリカのCPU/ディスクI/Oを追跡します。ラグが合意した許容値(例:5s、30s、2m)を超えたらアラートを出し、ラグが継続的に増加する場合はレプリカが介入なしには追いつけない兆候です。
リードレプリカは読み取りスケーリングのツールであり、SELECTクエリを提供する追加の場所を増やします。書き込みスケーリング(INSERT/UPDATE/DELETEの受け入れ能力を上げる)には向きません。
レプリカを追加すると、読み取りキャパシティが増えます。アプリが読み取り中心のエンドポイントでボトルネックになっている場合、複数のマシンにクエリを分散できます。
これによりよく改善される点:
SELECT向けにCPU/メモリ/I/Oが増える)「レプリカを増やせば書き込みスループットも増える」という誤解があります。典型的なプライマリ–レプリカ構成では、すべての書き込みは依然としてプライマリに行くため、レプリカは書き込みの天井を上げません。むしろ、プライマリは各レプリカへレプリケーションデータを生成・送信するため、作業量がわずかに増えることもあります。
書き込みが問題なら、通常は別のアプローチ(クエリ/インデックスチューニング、バッチ処理、パーティショニング/シャーディング、データモデルの変更)を検討します。
レプリカで読み取りCPUが増えても、最初に接続数の上限に引っかかることがあります。各データベースノードには同時接続の最大数があり、レプリカを追加するとアプリが接続しうる場所が増えるだけで、総需要は減りません。
実用的なルール:接続プーリング(あるいはプーラ)を使い、サービスごとの接続数を意図的に管理してください。さもないと、レプリカは「オーバーロードできる別のデータベース」になってしまいます。
レプリカは実コストを伴います:
トレードオフは明快です:レプリカは読み取り余力と分離を買えますが、複雑さを増やし、書き込みの上限は動かしません。
リードレプリカは読み取りの可用性を高めることができます:プライマリが過負荷または一時的に利用不可でも、レプリカから一部の読み取りを続けられる場合があります。これにより、若干古くても許容できるコンテンツの顧客向けページが応答を続けられ、プライマリ障害の影響を減らせます。
ただし、レプリカだけでは完全な高可用性計画にはなりません。レプリカは通常自動的に書き込みを受け付ける状態ではなく、「読み取り可能なコピーがある」ことは「システムが安全かつ迅速に書き込みを再開できる」こととは異なります。
フェイルオーバーは概念的には:プライマリ障害を検知 → レプリカを選ぶ → それを新しいプライマリに昇格する → 書き込み先をリダイレクトする、という流れです。
一部のマネージドデータベースはこれを自動化しますが、コアの考え方は変わりません:どのノードが書き込みを受け付けるかを切り替えます。
フェイルオーバーは練習すべきです。ステージングでゲームデイテストを行い(本番では低リスクウィンドウで慎重に)、プライマリ喪失をシミュレートして復旧時間を測り、ルーティングを検証し、アプリが読み取り専用期間や再接続を適切に処理することを確認してください。
リードレプリカはトラフィックが実際にそれらに届いて初めて役立ちます。「読み書き分離」は書き込みをプライマリへ、適切な読み取りをレプリカへ送るためのルール群です——正確性を壊さないように。
最も単純なのはデータアクセス層で明示的にルーティングする方法です:
INSERT/UPDATE/DELETE、スキーマ変更)はすべてプライマリへ理由付けが分かりやすく、ロールバックもしやすい。例えば「チェックアウト後はしばらく注文状態をプライマリから読む」といったビジネスルールを埋め込めます。
データベースプロキシや賢いドライバが“プライマリ vs レプリカ”エンドポイントを把握し、クエリタイプや接続設定に基づいてルーティングする方法もあります。アプリコードの変更を減らせますが、プロキシはプロダクト的にどの読み取りが“安全”かを確実に判断できない点に注意してください。
良い候補:
ユーザの書き込み直後に続く読み取り(例:「プロフィール更新 → プロフィール再読込」)は、一貫性戦略がない限りレプリカへ回すべきではありません。
トランザクション内ではすべての読み取りをプライマリに保持してください。
トランザクション外では“read-your-writes”セッションを考慮:書き込み後にユーザ/セッションを短期間プライマリにピン留めするか、特定のフォローアップクエリをプライマリへルーティングします。
まずは1台のレプリカを追加し、限定的なエンドポイント/クエリをルーティングして比較しましょう:
効果が明確で安全なら段階的にルーティングを拡大します。
リードレプリカは“設定して放置”するものではありません。追加のデータベースサーバとしてそれぞれに性能限界や障害モード、運用作業があります。いくつかの監視習慣が「レプリカが助けになった」か「混乱を招いただけか」の分かれ目です。
ユーザに見える症状を説明する指標に集中してください:
読み取りオフロードが目的なら1台から始めます。次を追加するのは明確な制約があるときだけ:
実用的なルール:読み取りがボトルネックであることを確認した後でレプリカを増やす。
リードレプリカは読み取りスケーリングの一手段ですが、通常最初に試すべきレバーではありません。運用の複雑さを増やす前に、よりシンプルな修正で同じ効果が得られないか検討してください。
キャッシュはデータベースから読み取りを丸ごと取り除けます。読み取り中心のページ(商品詳細、公開プロフィール、設定)ではアプリキャッシュやCDNで負荷を大幅に削減でき、レプリケーションラグを導入せずに済みます。
インデックスとクエリ最適化は、一般的なケースでレプリカより高い効果を発揮します:適切なインデックス追加、返すカラムの削減、N+1の回避、悪い結合の修正で「レプリカが必要」だった状況が「単に設計がまずかった」に変わることがよくあります。
マテリアライズドビュー/事前集計はワークロードが本質的に重い(分析、ダッシュボード)場合に有効です。複雑なクエリを繰り返す代わりに計算済み結果を保持してスケジュールで更新します。
書き込みが問題(ホット行、ロック競合、書き込みI/O制限)であれば、レプリカではあまり助けになりません。その場合、テーブルを時間やテナントで分割したり、顧客IDでシャードするなどして書き込み負荷を分散する必要があります。大きな構造変更ですが、根本的な制約に対処します。
次の4つの質問を自問してください:
プロトタイプや素早くサービスを立ち上げる場合、これらの制約を早期にアーキテクチャに織り込むと助けになります。例えば、Koder.ai(チャットからReactフロントとGo+PostgreSQLバックエンドを生成するvibe-codingプラットフォーム)上で開発するチームは、単純さのために最初は単一のプライマリで始め、ダッシュボードやフィード、内部レポーティングがトランザクションと競合し始めたらレプリカへ移行することが多いです。計画重視のワークフローにしておくと、どのエンドポイントが最終的整合性を許容でき、どれがプライマリからの"read-your-writes"であるべきかを前もって決めやすくなります。
必要なら /pricing を見てオプションを確認するか、/blog の関連ガイドを参照してください。
リードレプリカは、プライマリデータベースのコピーで、継続的に変更を受け取り、読み取り専用のクエリ(例:SELECT)に応答できるようにしたものです。プライマリへのその種の読み取り負荷を増やさずに、読み取りキャパシティを追加するのに役立ちます。
いいえ。典型的なプライマリ–レプリカ構成では、すべての書き込みは依然としてプライマリに入ることになります。むしろ、プライマリは各レプリカへ変更を送る必要があるため、若干のオーバーヘッドが増えることすらあります。
主に「読み取りがボトルネックになっている」状況で有効です:SELECTトラフィックが多く、プライマリのCPU/I/Oや接続数に負荷をかけている場合です。また、レポーティングやエクスポートなど重い読み取りをトランザクション処理から分離するのにも役立ちます。
必ずしもそうではありません。クエリがインデックス不足や悪い結合、巨大なテーブル走査などで遅い場合、レプリカでも同様に遅くなります——ただし別の場所で遅くなるだけです。まずはクエリとインデックスのチューニングを行ってください。
レプリケーションラグは、プライマリで書き込みがコミットされてから、その変更がレプリカで見えるようになるまでの遅延です。その間、レプリカからの読み取りは古い(stale)データを返す可能性があり、このためレプリカを使うシステムでは一部の読み取りが**最終的整合性(eventual consistency)**になることが多いです。
ラグが悪化する主な原因:
次のような『書いた直後に最新でなければならない』領域は、レプリカからの読み取りに頼るべきではありません:
これらは少なくとも重要なパスではプライマリから読むようにしてください。
「自分が書き込んだ結果が見えない」問題を防ぐ方法として、read-your-writes戦略があります:
監視すべき小さな信号群:
ラグがプロダクトの許容値(例:5秒/30秒/2分)を超えたらアラートを出しましょう。
よく使われる代替手段:
レプリカは、読み取りが既にある程度最適化されていて、ある程度の古さが許容できる場合に最も有効です。