2025年6月27日·2 分
ローカリゼーションと翻訳を管理するウェブアプリの作り方
翻訳ワークフロー、ロケールデータ、レビュー、QA チェック、リリースを管理するウェブアプリを計画する。データモデル、UX、連携を含む。
Web アプリで解決すべきこと
ローカリゼーション管理とは、プロダクトのテキスト(場合によっては画像、日付、通貨、フォーマットルール)を壊さずに翻訳、レビュー、承認、出荷する日常作業です。
プロダクトチームにとっての目標は「すべてを翻訳すること」ではなく、プロダクトの変更に合わせて各言語版を正確かつ一貫して最新に保つことです。
あなたが解決する問題
ほとんどのチームは良い意図で始めて混乱に陥ります:
- 分散したロケールファイル:リポジトリ、フォルダ、スプレッドシートに散らばり、単一の真実がない。\n- 表現の不一致(「Sign in」と「Log in」)、重複した文字列、同じ概念の異なる翻訳。\n- 遅いレビューサイクル:フィードバックがメールやコメント、チャットに散らばる。\n- ステータスが不明確:何が翻訳済みか、古くなっているか、リリースして良いかが分からない。\n- 手作業のリスク:エクスポート/インポートの手順でキーの欠落、プレースホルダの破損、上書きミスが生じる。\n
アプリの対象者
有用なローカリゼーション管理ウェブアプリは複数の役割をサポートします:
- 開発者:信頼できる文字列更新、クリーンな diff、マージコンフリクトの減少を求める。\n- 翻訳者:コンテキスト、用語ガイダンス、集中できる作業キューが必要。\n- レビュアー:明確な承認フローと特定の文字列にコメントする機能が必要。\n- PM やローカリゼーションリード:進捗の可視化と信頼できる締め切りが必要。\n
最終的に作るもの
MVP は文字列を集中管理し、ロケールごとにステータスを追跡し、基本的なレビューとエクスポートをサポートします。完成度の高いシステムは自動化(同期、QA チェック)、より豊富なコンテキスト、用語集や翻訳メモリのようなツールを追加します。
スコープと MVP 機能の定義
テーブルや画面を設計する前に、アプリが何を担うかを決めます。範囲を絞ることで最初のバージョンを使いやすくし、後で全て作り直す必要を減らせます。
まずコンテンツタイプを列挙する
翻訳は一箇所にしか存在しないことは稀です。初日からサポートすべきものを書き出します:
- UI 文字列(ラベル、ボタン、エラーメッセージ)\n- トランザクションメール(件名とテンプレート)\n- ドキュメントスニペット(短い再利用ブロック)\n- マーケティングページ(別チームが所有することが多く、レビュー要件が異なる)\n このリストにより「ワンサイズのワークフロー」を避けられます。例えばマーケティング文は承認が必要で、UI 文字列は迅速な反復が必要、という具合です。
サポートするファイル形式を決める
MVP では 1–2 形式 を選び、後で拡張します。一般的な選択肢は JSON, YAML, PO, CSV。実務的にはアプリ文字列用に JSON または YAML を選び、スプレッドシート依存がある場合にのみ CSV を追加するのが良いでしょう。
複数形、ネストされたキー、コメントの扱いなど要件を明確にしてください。これらはロケールファイル管理と将来のインポート/エクスポートの信頼性に影響します。
ロケールとフォールバックルールを選ぶ
基準となるソース言語(多くは en)を定義し、フォールバック動作を設定します:
- 欠落した文字列は en にフォールバックする。\n- 必要に応じて親ロケールにフォールバック(例:
pt-BR → pt → en)。\n また、ロケールごとに「完了」の定義(100% 翻訳済み、レビュー済み、出荷済み)を決めます。
MVP と後続機能
MVP では翻訳レビューと基本的な i18n ワークフロー(作成/編集、作業割り当て、レビュー、エクスポート)に集中します。
後で追加する予定の機能は スクリーンショット/コンテキスト, 用語集, 翻訳メモリの基礎, 機械翻訳の統合 などですが、コアワークフローを実データで検証するまでは作らないでください。
データモデルの設計
翻訳アプリはデータモデル次第で成功も失敗も決まります。エンティティとフィールドが明確なら、UI、ワークフロー、連携の実装が格段に簡単になります。
コアエンティティから始める
多くのチームは少数のテーブル/コレクションで 80% をカバーできます:
- Project:プロダクト/アプリや文字列領域。\n- Locale:言語・地域(例:
en,en-GB,pt-BR)。\n- Key:コードで使う安定した識別子(例:checkout.pay_button)。\n- Source string:キーに紐づく参照テキスト(基準言語)。\n- Translation:キー+ロケールに対するローカライズされた値。\n- Version:リリース、インポート、ファイル改訂のスナップショット。\n 関係性を明示的にモデル化します:Project は複数の Locales を持ち、Key は Project に属し、Translation は Key と Locale に属します。
ステータスフィールドでワークフローを表現する
各翻訳にステータスを追加して、人間の案内をしやすくします:
draft→in_review→approved\n- レガルレビューやコンテキスト不足などで出荷すべきでない場合はblockedを使う
ステータス変更はイベント(または履歴テーブル)として残し、「誰がいつ承認したか」を後で答えられるようにします。
ミスを防ぐメタデータを保存する
翻訳は単なるテキスト以上の情報を必要とします。次をキャプチャしてください:
- プレースホルダ(例:
{name},%d)とソースとの整合性ルール\n- 最大文字数(ボタン等の UI 制約)\n- コンテキストノート(出現場所、意味、トーン)\n- タグ(機能領域、プラットフォーム、緊急度)
監査フィールドは省略しない
最低でも created_by, updated_by, タイムスタンプ、短い change_reason を保存します。これによりレビューが早くなり、アプリに何が搭載されたかを比較するときの信頼が得られます。
ストレージとバージョニング計画
ストレージの決定は編集 UX、インポート/エクスポートの速度、差分表示、出荷の確実性に影響します。
文字列の保存:row-per-key と document-per-file
Row-per-key(キー毎に行)はダッシュボードやワークフローに向きます。フィルタで「フランス語が欠けている」や「レビューが必要」を簡単に抽出できる利点があります。欠点はエクスポート時にファイルの再構成やソートが必要になる点です。
Document-per-file(各ロケールファイルを JSON/YAML ドキュメントとして保存)はリポジトリの構造と親和性が高く、フォーマット維持が容易です。しかし検索やフィルタが難しくなるため、キーやステータスのインデックスを別に持つ必要があります。
多くのチームはハイブリッドを採用:row-per-key を真実のソースにし、エクスポート用に生成されたファイルスナップショットを保持します。
バージョニング:翻訳単位とリリースごとの改訂
翻訳ユニットレベルのリビジョン(キー+ロケール)を保持します。変更は前の値、新しい値、作者、タイムスタンプ、コメントを記録します。これによりレビューやロールバックが容易になります。
別に リリーススナップショット を管理します:"v1.8 に実際に搭載されたもの" のように、承認済みリビジョンの一貫したセットを指すタグです。これにより、後からの編集が出荷内容を静かに変えてしまうのを防げます。
複数形と性別ルール
「複数形」を単純なブール値で扱わないでください。ICU MessageFormat や CLDR のカテゴリ(one, few, many, other)を使って、ポーランド語やアラビア語のような言語が英語ルールに押し込められないようにします。
性別や他のバリエーションは、同じキー(またはメッセージ)のバリアントとしてモデル化し、翻訳者が全体のコンテキストを見られるようにします。
スケールする検索とフィルタ
キー、ソーステキスト、翻訳、開発者ノートに対して全文検索を実装します。現実の作業に合わせたフィルタ:status(新規/翻訳済み/レビュー済み)、tags、file/namespace、missing/empty を用意します。
これらのフィールドは早い段階でインデックス化してください—検索は毎日何百回も使われる機能です。
スケーラブルなアーキテクチャの選択
ローカリゼーション管理アプリは、最初はシンプルですが、製品やロケール、リリースが増えると複雑になります。柔軟にする最も簡単な方法は関心事の分離です。
実用的なスタック
一般的でスケーラブルな構成は API + Web UI + バックグラウンドジョブ + データベース:
- Web UI:翻訳エディタ、レビュー画面、プロジェクト設定。\n- API:UI、CLI、連携の単一の真実のソース。\n- Background jobs:インポート/エクスポート、QA スキャン、同期などの長時間作業。\n- Database:プロジェクト、キー、翻訳、履歴、権限を保存。
この分割により、重い処理に対してワーカーを追加するだけで拡張できます。
開発初期に素早く動かすなら、Koder.ai のようなプロトタイピングプラットフォームで React の UI、Go の API、PostgreSQL スキーマをチャットでスキャフォールドしてからソースコードをエクスポートして本番用に移行する手もあります。
API の構造化
コアリソースに集中させます:
- Projects、Locales、Keys、Translations
エンドポイントは人間向け編集と自動化両方をサポートするように設計します。たとえばキーの一覧は "missing in locale"、"changed since"、"needs review" のようなフィルタを受け取れるべきです。
必要なバックグラウンドジョブ
自動化は非同期作業として扱います。典型的には:
- Imports(ロケールファイル解析、検証、キー作成/更新)\n- Exports(リリース用のロケールバンドル生成)\n- QA checks(プレースホルダ、長さ、HTML、禁止語)\n- Sync jobs(Git、CI、他システムへの pull/push)
ジョブは冪等にし、再試行が安全であること、プロジェクト毎にジョブログを残すことを心がけます。
早期に重要なパフォーマンス対策
小さなチームでも大きなデータセットを作れます。リスト(キー、履歴、ジョブ)にはページネーションを入れ、よく使う読み取りはキャッシュし(プロジェクトのロケール統計など)、インポート/エクスポートや公開トークンを保護するためにレート制限を適用します。
これらの地味な対策が、採用が進んだときにシステムが遅くなるのを防ぎます。
認証と権限
ローカリゼーションのバグを早期に検出
翻訳が本番に行く前に、プレースホルダーとフォーマットの正当性をチェックするQAを作成します。
ソース文字列や翻訳履歴を保存するなら、アクセス制御は任意ではなく必須です。これは偶発的な編集を防ぎ、決定の追跡性を確保します。
実務に合った役割選定
シンプルな役割セットで多くのチームをカバーできます:
- Admin:組織設定、ロケール、連携、ユーザー管理。\n- Developer:ソース文字列編集、キー作成、インポート/エクスポート。\n- Translator:割り当てられたロケールの翻訳編集。\n- Reviewer:翻訳の承認/却下と最終文言のロック。\n- Viewer:閲覧のみ。
権限を明確に定義する(タイトルだけでなく)
各アクションを権限として扱い、将来的に進化できるようにします。一般的なルール:
- Edit source:Admin、Developer のみ(翻訳者が意味を変えないようにする)\n- Approve:Reviewer(必要に応じて Admin)\n- Export:Developer/Admin、またはリリースを担当する Reviewer に許可\n- Manage locales:Admin のみ(ロケール追加はワークフローと予算に影響するため)\n- Edit translations:割り当てられたロケールとプロジェクト内で Translator/Reviewer に許可
これは翻訳管理システムに自然にマッピングし、外部の契約者にも柔軟に対応できます。
ログイン:SSO とメール認証
Google Workspace、Azure AD、Okta を既に使っているなら SSO によりパスワードリスクを減らし、退職時のアクセス失効を即時にできます。小規模チームならメール/パスワードで十分ですが、強力なパスワードとリセットフローを必須にしてください。
セッションセキュリティの基本
HTTP-only クッキー、短寿命セッション、CSRF 保護、レート制限、可能なら 2FA を導入します。
説明責任のためのアクティビティログ
誰がいつ何を変更したかを記録します:編集、承認、ロケール変更、エクスポート、権限更新。このログとバージョン履歴を組み合わせて "元に戻す" 機能を提供するとロールバックが安全で速くなります(詳細は /blog/plan-storage-and-versioning を参照)。
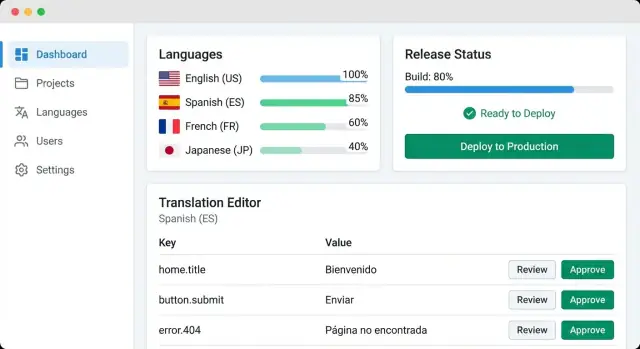
コア UI 画面の作成
UI はローカリゼーション作業の現場です。往復作業を減らし、ステータスを一目で分かるようにする画面を優先してください。
1) プロジェクト概要(コントロールルーム)
ダッシュボードは次の 3 点に素早く答えるべきです:何が終わっているか、何が不足しているか、何がブロックされているか。
ロケールごとの進捗(翻訳率、レビュー率)、"欠落文字列" カウント、承認待ちのレビューキュー、最近の変更フィードを表示します。フィルタ(ロケール、プロダクト領域、ステータス、担当者、"前回リリース以降の変更")はチャートより重要です。
2) 翻訳エディタ(高速・コンテキスト・監査可能)
良いエディタはサイドバイサイド:左にソース、右にターゲット、常にコンテキストが見えること。
コンテキストにはキー、スクリーンショット(ある場合)、文字数制限、プレースホルダ(例:{name}, %d)を含めます。履歴とコメントも同一ビューに入れて、翻訳者が別画面に行かなくて済むようにします。
ステータス変更はワンクリックで:Draft → In review → Approved。
3) 一括操作(マネージャー/リード向け)
ローカリゼーション作業は "多くの小さな変更" です。複数選択で担当割当、ステータス変更、ロケールやモジュール単位のエクスポート/インポートなどを実行できるようにします。
一括操作は権限で制御してください(詳細は /blog/roles-permissions-for-translators を参照)。
4) アクセシビリティとキーボードショートカット
重労働の翻訳者はエディタを長時間使います。フルキーボードナビゲーション、フォーカス状態の可視化、次のようなショートカットを提供します:
- 次/前の文字列\n- 保存して "In review" にする\n- ソースをターゲットにコピー
スクリーンリーダー対応やハイコントラストモードも提供してください。アクセシビリティは全員の速度を上げます。
翻訳ワークフローの作成
ローカリゼーション管理アプリはワークフローで成功するか失敗するかが決まります。次に何を翻訳すべきか、誰の決定か、何がブロックされているかが不明瞭だと遅延と品質低下を招きます。
割り当てフロー:誰が何をいつまでに翻訳するか
作業単位を明確にします:特定バージョンのロケールに対するキーの集合。プロジェクトマネージャーやリードは ロケール, ファイル/モジュール, 優先度、任意で期限を指定して作業を割り当てられるようにします。
「マイワーク」受信箱で何が割り当てられているか、期限切れのものは何か、他者待ちのものは何かを表示します。大規模チーム向けに作業量シグナル(アイテム数、単語数見積もり、最終アクティビティ)を追加すると公平な割り当てができます。
レビューフロー:コメント、提案、承認、却下
シンプルなステータスパイプラインを構築します:Untranslated → In progress → Ready for review → Approved。
レビューは単なる二者択一ではありません。インラインの コメント、提案編集、承認/却下理由 をサポートします。却下された場合は履歴を残し、上書きしないでください。
これにより翻訳レビューは監査可能になり、繰り返しのミスが減ります。
コンフリクト処理:ソース変更と "Needs update" フラグ
ソーステキストは変わります。変更があった場合、既存の翻訳に Needs update を付けて差分や "何が変わったか" の概要を表示します。古い翻訳は参照用として残し、明示的な判断なしに再承認できないようにします。
通知:割り当てやレビュー依頼のメール/インアプリ通知
進行を止めるイベントに対して通知します:新しい割り当て、レビュー要求、却下、期限接近、ソース変更による影響など。
通知は深いリンク(例:/projects/{id}/locales/{locale}/tasks)を含め、ワンクリックで解決に移れるようにします。
インポート、エクスポート、同期の自動化
コア画面を構築
ドラフトから承認までのワークフローに沿ったダッシュボード、エディタ、レビューキューを生成します。
手作業によるファイル操作はローカリゼーションがずれる原因です。翻訳者が古い文字列で作業したり、開発者が更新を取り込むのを忘れ、リリースに半分しか完成していないロケールが混入します。
インポート/エクスポートは一度きりの作業ではなく、再現可能なパイプラインとして扱うべきです。
インポート/エクスポートパイプラインを構築する
チームが実際に使うパスをサポートします:
- リポジトリからプル(GitHub/GitLab/Bitbucket):スケジュールまたはオンデマンドでロケールファイルを取得。\n- リポジトリへプッシュ:更新翻訳で直接 main を書き換えるのではなく PR を開く。\n- 手動アップロード/ダウンロード:ベンダーやレガシー用に残す。
エクスポート時は プロジェクト、ブランチ、ロケール、ステータス(例:"approved only")でフィルタできるようにして、部分的にレビューされた文字列が本番に漏れないようにします。
文字列抽出と安定したキー
同期が機能するにはキーが安定している必要があります。文字列生成の方針を早めに決めてください:
- 人間可読キー(例:
checkout.button.pay_now)を使うなら、意図せぬリネームから守る。\n- ハッシュベースキーを使う場合は、ソース文字列とコンテキストを保存して、更新で重複が生じないようにする。
ソース文字列が変わったがキーは同じ場合、翻訳を上書きするのではなく needs review にマークする機能が必要です。
コミット/リリース用の Webhook
自動同期のために Webhook を追加します:
mainへの新しいコミット → ソース文字列をインポート。\n- リリースタグ作成 → 承認済み翻訳をエクスポートして PR を開く。
Webhook は冪等で(再試行しても安全)、何が変わったか、何がスキップされたか、理由を分かりやすくログに残すべきです。
統合のドキュメント
実装するなら、最もシンプルなエンドツーエンドのセットアップ(リポジトリ権限 + Webhook + PR エクスポート)を UI から参照できるようにし、/docs/integrations へのリンクを貼って案内します。
ローカリゼーション QA チェックの追加
ローカリゼーション QA は単なるエディタを超え、本番バグを防ぐ機能です。目的は、特定のロケールファイルでのみ現れる問題を出荷前に検出することです。
1) バリデーション(致命的エラー)
UI を壊したりフォーマットを崩したりするチェックから始めます:
- プレースホルダの欠落や不一致(例:英語にある
{count}がフランス語になければエラー)\n- 無効な HTML(許可されるマークアップでの破損)\n- ファイル形式に対するエスケープ不備(JSON 内の引用符、printf スタイルの%、ICU メッセージの破損)
これらはデフォルトで "リリースをブロックする" とし、該当するキーとロケールへの明確なポインタを表示します。
2) 一貫性チェック(警告)
品質やブランド一貫性に関わるが直ちに壊れないもの:
- 用語集の違反:必須用語が使われていない、あるいは不一致がある場合にフラグを立てる。\n- 句読点・空白・大小の不一致:二重スペース、末尾スペース、終止句未使用、引用符の不一致。
3) 視覚的チェック(コンテキスト重視)
テキストが正しくても見た目が不適切なことがあります。キーごとに スクリーンショットコンテキスト を要求できる仕組みを作るか、キーにスクリーンショットを添付して、翻訳者やレビュアーが切れや改行、トーンを UI 上で検証できるようにします。
4) レポーティング(リリース向けサマリ)
リリース前にロケールごとの QA サマリを自動生成します:エラー、警告、未翻訳文字列、上位の問題点。
このサマリはエクスポートや内部リンク(例:/releases/123/qa)が簡単にできるようにして、チームが一つの "go/no-go" ビューを持てるようにします。
用語集、翻訳メモリ、機械翻訳のサポート
インポート/エクスポートのフローをテスト
バックグラウンドワーカーでインポート/エクスポート処理をプロトタイプし、後でリポジトリ同期に拡張します。
用語集、翻訳メモリ(TM)、機械翻訳(MT)はローカリゼーションを大幅に高速化しますが、アプリはそれらを "最終出力" ではなくガイダンスや補助として扱うべきです。
用語集:ロケールごとの承認済み用語
用語集は用語ごとにロケール別の承認翻訳を持つキュレートされたリストです。
エントリを term + locale + approved translation + notes + status として保存します。
翻訳エディタ内で用語一致をハイライトし、承認済みの訳語を提案する、あるいはプロジェクト設定で逸脱を警告/ブロックする、といった機能を追加します。変化形や小文字大文字の扱いは緩やかなルールで対応してください。
翻訳メモリの基礎
TM は以前承認された翻訳を再利用します。シンプルに保ちます:
- (正規化したソーステキスト、コンテキストキー、ロケール)でインデックス化。\n- まず "approved" セグメントを優先し、次に "reviewed" や "imported" を用いる。\n- 一致度(完全一致 vs 近似)と元のコンテキストを提示して信頼性を担保。
TM は提案システムとして扱い、ユーザーが受け入れ、編集、否定できるようにします。受け入れた翻訳のみ TM にフィードバックします。
機械翻訳は支援として
MT は草稿やバックログの処理に有効ですが、デフォルトで最終出力にするべきではありません。
プロジェクトやジョブ単位で MT をオプトインにし、MT で埋めた文字列は通常のレビュー工程を通すようにします。
コストとプライバシー設定
チームにはそれぞれ制約があります。管理者がプロバイダを選べるようにし(あるいは MT を完全に無効化)、使用量制限を設定し、送信データ(機密キーを除外するなど)を選べるようにします。
コスト可視化と監査のためリクエストをログに残し、/settings/integrations にオプションの説明を載せます。
リリースを安全に出荷する
ローカリゼーションアプリは単に翻訳を保存するだけでなく、安全に出荷する支援をするべきです。
キーとなる考えは リリース:承認済み文字列の凍結スナップショットで、配備時に何が送られたかを再現できることです。
「リリース」に含めるものを定義する
リリースを不変のバンドルとして扱います:
- ロケール + namespace/file + key + 最終承認テキスト\n- メタデータ:承認ステータス、レビュアー、タイムスタンプ、ソース文字列のハッシュ\n- 任意で:ビルド番号、git コミット、アプリバージョン
これにより「v2.8.1 の fr-FR で何を出荷したか」を確実に答えられます。
環境(ステージング vs プロダクション)をサポートする
出荷前に翻訳を検証したいケースが多いです。エクスポートを環境別にモデル化します:
- Staging export:新しく承認された文字列と候補翻訳(プレビュー用)を含むことがある\n- Production export:完全に承認されたコンテンツのみ、リリース ID に紐づける
エクスポートのエンドポイントは明示的にし(例:/api/exports/production?release=123)、レビューされていないテキストが誤って流出するのを防ぎます。
初めからロールバックを計画する
リリースが不変であればロールバックは容易です。問題が起きたら:
- 以前のリリースエクスポートにアプリを戻す\n- 問題のある文字列を再オープンして修正し、新しいリリースを切る
"本番で直接編集する" のは避けてください—監査トレイルが壊れ、インシデント解析が困難になります。
Koder.ai のようなプラットフォームはスナップショットとロールバックをファーストクラスワークフローとして扱っており、この不変のリリース思考はローカリゼーション設計にも有効です。
デプロイ後のチェックリストと監視
デプロイ後は小さな運用チェックを行います:
- すべてのロケールのエクスポートが成功、欠落ファイルなし\n- 主なユーザーフローでの基本的なランタイムスモークテスト\n- 翻訳エラー信号の監視(欠落キー、プレースホルダ不一致、フォールバックの急増)
UI にリリース履歴を表示するなら、前回リリースとの差分ビューを付けてリスクの高い変更を素早く発見できるようにします。
セキュリティ、分析、次の一手
セキュリティと可視性は、使えるツールと信頼されるツールの差です。ワークフローが安定したらロックダウンし、計測を始めます。
基本的なセキュリティ対策
最小権限の原則をデフォルトに:翻訳者がプロジェクト設定を変えられない、レビュアーが請求情報にアクセスできない等。役割を明確にし、監査可能にします。
秘密情報は安全に保存します。データベース資格情報、Webhook 署名鍵、サードパーティトークンはシークレットマネージャや暗号化環境変数に保管し、リポジトリに置かないでください。人が退職したら鍵のローテーションを行います。
バックアップは必須です。データベースやオブジェクトストレージ(ロケールファイル、添付)を自動でバックアップし、リストアをテストし、保持期間を定義します。"復元できないバックアップ" は単なる無駄なストレージです。
PII に関する配慮
文字列にユーザー生成コンテンツ(サポートチケット、名前、住所など)が含まれうる場合、翻訳システムに直接保存しない方が良いです。プレースホルダや参照を使い、ログからは機密値を削除します。
どうしても処理する必要があるなら、保持ルールとアクセス制限を定義します。
実務に役立つ基本的な分析
ワークフローの健全性を示す数件の指標を追いましょう:
- スループット:1 日/週あたりの翻訳文字列数\n- レビュー時間:"翻訳済み" から "承認" までの平均時間\n- 変更が多いキー:不安定な UI 領域の特定
シンプルなダッシュボードと CSV エクスポートで十分に役立ちます。
次に拡張すべきこと
基盤が安定したら検討する項目:
- プッシュ/プルと状態確認のための開発者 CLI\n- UI 上で文字列をプレビューできるインコンテキストエディタ\n- CI/GitHub/GitLab/Slack などの連携用 API キー
これをプロダクトとして提供する予定があれば、明確なアップグレードパスと CTA(例:/pricing)を用意します。
即座にワークフローを実ユーザーで検証したいなら、Koder.ai で MVP をプロトタイプするのも有効です:ロール、ステータスフロー、インポート/エクスポート形式を設計モードで記述し、チャットを通じて React UI と Go API を反復し、準備ができたらコードベースをエクスポートして本格運用に移せます。
よくある質問
ローカリゼーション管理ウェブアプリとは何で、どんな問題を解決しますか?
ローカリゼーション管理ウェブアプリは、文字列を一元化し、それらの翻訳、レビュー、承認、エクスポートにまつわるワークフローを管理します。これにより、壊れたキー、欠落したプレースホルダ、不明瞭なステータスが原因でリリースが失敗するリスクを減らせます。
MVP のローカリゼーション管理アプリはどのようにスコープを決めればいいですか?
まず次を明確にします:
- コンテンツの種類(UI文字列、メール、スニペット、マーケティング)
- ファイル形式(MVPでは JSON/YAML など 1〜2 種類)
- ロケールとフォールバックルール(例:
pt-BR → pt → en) - ロケールごとの完了定義(翻訳済み/レビュー済み/出荷済み)
範囲を絞ることで「すべてに一律のワークフロー」になる失敗を防ぎ、MVP を実用的に保てます。
翻訳とワークフローのためのデータモデルはどう設計すべきですか?
多くのチームは次のエンティティでコアワークフローをカバーできます:
- Project(プロジェクト)、Locale(ロケール)、Key(キー)、Source string(ソース文字列)、
翻訳ミスを避けるためにどんなメタデータを保存すべきですか?
本番の間違いを防ぐために保存すべきメタデータ:
翻訳はデータベースの行で保存すべきですか、それともロケールファイルとして保存すべきですか?
目的に応じて選びます:
- キー単位の行(row-per-key):フィルタ、キュー、進捗レポートに最適。ロケールファイルを再構築する追加処理が必要。
- ファイル単位のドキュメント(document-per-file):リポジトリのファイル構造と一致し、フォーマット保持が容易。ただし検索やフィルタがやや難しい。
多くのチームはハイブリッドを採用します:row-per-key を真実のソースにし、エクスポート用に生成されたファイルスナップショットを持つ方式です。
ローカリゼーションアプリでのバージョニングとリリースはどう設計すべきですか?
2 層構成を推奨します:
- 翻訳単位ごとのリビジョン(キー+ロケール):誰がいつ何を変えたかを記録してロールバック可能にする。\n- リリーススナップショット:承認済みのリビジョンを凍結したバンドル。これにより “既に出荷されたものがいつの間にか変わる” を防ぎます。
ローカリゼーションワークフローに必要な役割と権限は何ですか?
実務に則した役割を用意します:
- Admin(管理者):組織設定、ロケール、連携、ユーザー管理
- Developer(開発者):ソース文字列の編集、キー作成、インポート/エクスポート
- Translator(翻訳者):割り当てられたロケールの翻訳編集
- Reviewer(レビュアー):翻訳の承認/却下
- Viewer(閲覧者):読み取り専用
将来的に柔軟にするため、アクション単位でのパーミッション設計をおすすめします(例:誰がソースを編集できるか、誰が承認できるか、など)。
UI と自動化の両方を支える API エンドポイントはどう設計すべきですか?
API は主要リソースを中心に設計します:
Projects、Locales、Keys、Translations
リスト取得エンドポイントは実務的なフィルタを受け取れるようにします:
早い段階で用意すべきバックグラウンドジョブは何ですか?
初期に用意すべき非同期ジョブ:
- インポート/エクスポート(ファイル解析、検証、キー作成/更新)
- リポジトリ同期(Pull/Push、PR 作成)
- QA スキャン(プレースホルダ、長さ、HTML、禁止語)
ジョブは**冪等(idempotent)**にして再試行可能にし、プロジェクト単位でログを残して自己診断しやすくします。
リリースをブロックすべきローカリゼーション QA チェックは何ですか?
出荷をブロックすべきチェック優先度:
- プレースホルダ不一致(
{count},%dなど)や複数形の未対応 - フォーマット有効性(JSON エスケープ、ICU 構文)
- HTML の整合性(許可されるマークアップの破損)
これらはデフォルトでリリースブロッキングにし、用語集の不一致や空白・句読点の問題はソフトな警告として扱うとバランスが良いです。