2025年9月09日·2 分
SaaSのステータスページを作る方法(インシデント履歴付き)
インシデント履歴、分かりやすい文言、購読機能を備えたSaaSのステータスページを計画し、構築して公開する方法を学びます。障害時に顧客が情報を得られるようにするベストプラクティスを解説します。
SaaSステータスページとは(そしてなぜ重要か)
SaaSのステータスページは、製品が今動いているかどうか、動いていなければ何をしているかを示す公開(または顧客限定)のウェブサイトです。インシデント時の単一の信頼できる情報源になり、ソーシャルメディアやサポートチケット、噂と切り離されます。
思ったより多くの人に役立ちます:
- 顧客は「自分だけ?」かをすばやく確認し、待つか、再試行するか、回避策を使うかを判断できます。
- サポートチームは、一つの正準的な更新をリンクして多数のチケットで繰り返す代わりに済みます。
- 営業/カスタマーサクセスは、正確でタイムスタンプ付きの情報で更新や主要アカウントをプロアクティブに管理できます。
リアルタイムステータス vs インシデント履歴 vs ポストモーテム
良いサービスステータスサイトは通常、関連するが異なる三つの層を含みます:
- リアルタイムステータス:API、ダッシュボード、請求など、各コンポーネントの「今」の状態(稼働、ダウン、劣化)
- インシデント履歴ページ:過去のインシデントとメンテナンスのタイムライン。顧客がパターンを理解し、問題が対処されたことを確認できる
- ポストインシデントレビュー(ポストモーテム):根本原因、修正、再発防止策を詳述する深掘りしたレポート。公開するか、影響を受けた顧客へ個別共有するかを選べます。
目標は明快さです:リアルタイムは「今使えるか?」に答え、履歴は「どれくらい頻繁か?」に答え、ポストモーテムは「なぜ起きたか、何が変わったか?」に答えます。
期待値設定:透明性、速度、明瞭さ
ステータスページは更新が速く、平易な言葉で、影響について正直であるときに機能します。完璧な診断は不要ですが、タイムスタンプ、適用範囲(誰が影響を受けるか)、次回更新時間は必須です。
よく使う場面
ステータスページは、停止(アウトジー)、性能劣化(ログインが遅い、Webhookの遅延)、予定されたメンテナンスなどで頼りになります。
ステータスページをワンオフのオプスページではなくプロダクトの一部と扱えば、オーナーを定義し、テンプレートを作り、監視を接続するなどの準備が容易になります。毎回ゼロからやり直す必要はありません。
目標、対象、オーナーを決める
ツールやレイアウトを選ぶ前に、ステータスページで何を達成したいかを決めてください。明確な目標と明確なオーナーがあれば、インシデント中の混乱した状況でもページは役立ち続けます。
目標を定義する("成功"の基準)
多くのSaaSチームは現実的な3つの成果のためにステータスページを作ります:
- サポートチケットの削減:結論を一か所で示すことで「ダウンしているか?」への重複対応を減らす
- 信頼の構築:タイムリーで平易な更新を共有する
- コミュニケーションの高速化:サポート、エンジニアリング、営業、CS間の情報伝達を速める
起動後に追跡できる2〜3の測定可能な指標(例:インシデント時の重複チケット数の減少、初回更新までの時間、購読者数)を書き出してください。
対象読者と読みやすさを決める
主な読者は通常非技術系の顧客です。知りたいことは:
- 製品は今動いているか?
- 何が影響を受けているか(ログイン、API、請求など)?
- 次に何をすべきか?
- いつ直る見込みか?
専門用語は最小限に。"一部の顧客がログインできません" は "認証で5xxが増えています" より顧客に親切です。技術的な詳細が必要なら短い補助文に収めてください。
トーン、ルール、オーナーを決める
プレッシャー下でも維持できるトーン(落ち着いた、事実重視、透明性ある)を選んでください。事前に決めること:
- 誰が更新を投稿できるか(単一の役割かオンコールローテーションか)
- 誰が更新を承認するか(承認が必要なら許容される遅延時間)
- アクティブなインシデント中の最小更新頻度(例えば30分ごと)
所有者を明確にしておけば「みんなの仕事」にならず、やがて「誰の仕事でもない」状況を防げます。
どこに置くかを決める
一般的な選択肢は2つ:
- 独立サイト(例:status.yourcompany.com):分離が明確で、障害時により耐性があることが多い
- サブパス(例:/status):ブランディングや分析が単純
メインアプリが落ちる可能性があるなら、独立したステータスサイトが安全です。アプリやヘルプセンター(例:/help)から目立つリンクを貼るとよいでしょう。
サービスマッピングとコンポーネントステータスモデル
ステータスページは、その背後にある“地図”の有用性に依存します。色やコピーを書く前に、実際に何を報告するか決めてください。目標は、組織の編成図ではなく顧客が製品をどう体験するかを反映することです。
コンポーネントのインベントリから始める
顧客が「壊れている」と言ったときに想起する要素をリストアップします。多くのSaaSでは実用的な出発点は:
- API
- Webアプリ
- ダッシュボード / 管理画面
- 認証(ログイン、SSO)
- 請求
- インテグレーション(Slack、Salesforce、Webhooksなど)
複数リージョンやプランがあるならそれもキャプチャします(例:「API – US」「API – EU」)。名前は顧客向けに:"Login" は "IdP Gateway" より明瞭です。
コンポーネントをどうグループ化するか決める
顧客の考え方にマッチするグルーピングを選んでください:
- プロダクト別:別々の提供物がある場合に有効(プロダクトA vs プロダクトB)
- リージョン別:地域で可用性が大きく異なる場合に有効
- 機能/ワークフロー別:レポーティング、インポート、通知など特定のジョブに依存する顧客向け
無限にリストを増やすのは避けて。多数のインテグレーションがあるなら親コンポーネント("Integrations")と影響の大きい子をいくつか(例:"Salesforce", "Webhooks")にするのが現実的です。
ステータスレベルを定義する(意味も)
シンプルで一貫したモデルはインシデント時の混乱を防ぎます。一般的なレベル:
- Operational:期待通りに動作
- Degraded Performance:通常より遅い、または断続的なエラー
- Partial Outage:ユーザーや機能の大きなサブセットが利用不可
- Major Outage:サービスが広範に利用不可
各レベルの内部基準を文書化してください(公開しなくてもよい)。例えば「Partial Outage = 一地域のダウン」や「Degraded = p95レイテンシがXを超えてY分継続」など。定義の一貫性が信頼を生みます。
依存関係を把握し、表示するか決める
多くの障害はサードパーティに関係します:クラウドホスティング、メール配信、決済、IDプロバイダなど。これらの依存を文書化しておくと更新が正確になります。
公開するかは観客次第です。顧客に直接影響する(例:決済)なら公開コンポーネントに含めると有用です。ノイズになりやすく責任のなすりつけを招くなら内部に留め、更新時に言及する(例:「決済プロバイダでエラーが増加しているため調査中」)にとどめてください。
このコンポーネントモデルがあれば、インシデントごとに「どこか」と「どれくらい悪いか」が即座に決まります。
シンプルで顧客フレンドリーなページを設計する
ステータスページは、数秒で顧客の疑問に答えるときに最も有用です。訪問者は通常ストレスを感じており、ナビゲーションより明快さを求めます。
顧客が最初に必要とする情報から始める
最上部に必須情報を優先配置:
- 現在の状態:稼働/劣化/ダウンか
- 影響:何が影響を受けているか(誰/どのリージョン/どの機能)と顧客が体験する事象
- ETA(もしあるなら):防御できる見積もりのみ共有すること
- 次回更新時刻:"次の更新は14:30 UTCまでに"のような具体的な約束はリピートチケットを減らす
言葉は平易に。"APIリクエストのエラー率が増加"は"上流の依存で部分的障害"より明確です。技術用語を使う場合は短い解説を添えてください(例:「一部のリクエストが失敗またはタイムアウトする可能性があります」)。
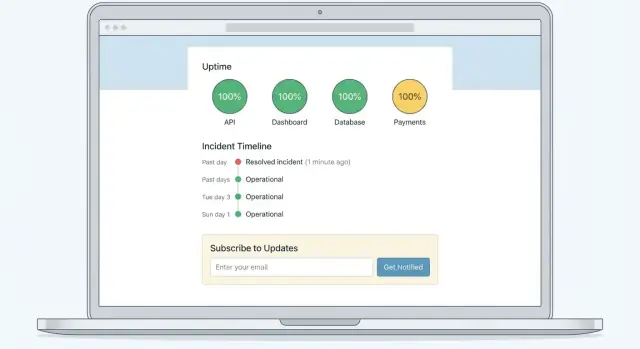
シンプルでスキャンしやすいレイアウトを使う
信頼性の高いパターン:
- トップバナー:全体のステータス(All Systems Operational / Degraded Performance / Major Outage)
- コンポーネントリスト:Web App、API、Billing、Integrationsなどの明確なステータス
- アクティブなインシデントと予定メンテナンス:最新の更新順に表示
コンポーネントラベルは顧客向けに。内部で "k8s-cluster-2" と呼ぶより "API" や "バックグラウンドジョブ" の方が分かりやすいです。
アクセシビリティとモバイルの基本
緊張した状況でも読みやすくするために:
- 強い色のコントラストとテキストラベル(色だけに頼らない)
- 一貫した意味を持つアイコン(緑=稼働、黄=劣化、赤=障害)
- モバイル対応の間隔とタップターゲット
多くのユーザーはスマホでステータスを確認します。
人が期待するクイックリンクを追加する
バナーの近く(ヘッダーやバナー直下)に小さなリンク群を置く:
- Subscribe(メール/SMS/Webhook購読)
- Incident History(過去のインシデントとタイムライン)
- Contact Support(/support)
目的は安心感:何が起きているか、何に影響するか、次にいつ連絡があるかを即座に理解させることです。
インシデントおよびメンテナンス更新テンプレートを作る
インシデント発生時は診断、緩和、顧客対応の同時進行になります。テンプレートがあれば更新が一貫し速くなり、異なる人が投稿してもばらつきが減ります。
常に公開するインシデント項目を定義する
良い更新は毎回同じコア情報から始まります。最低限標準化すべき項目:
- インシデント開始時刻(タイムゾーン付き)
- 影響を受けるコンポーネント/サービス(ステータスモデルに紐づけ)
- 顧客への影響(誰がどう影響を受けるか)
- 現在の状態(Investigating、Identified、Monitoring、Resolved)
- 更新ログ(タイムスタンプ付きのエントリ)
- 復旧時刻(サービスが正常に戻った時刻)
インシデント履歴ページを公開するなら、これらを一貫して保つと過去の比較が簡単になります。
単純で繰り返し使える更新テンプレート
短く、顧客が毎回同じ質問に答えられるようにします。実用的なテンプレート例:
Title: 簡潔で具体的な要約(例:"EUリージョンのAPIエラー")
Start time: YYYY-MM-DD HH:MM (TZ)
Affected components: API, Dashboard, Payments
Impact: ユーザーが見ている現象(エラー、タイムアウト、性能劣化)と影響範囲
What we know: 確認済みの原因がある場合の一文(憶測は避ける)
What we’re doing: 具体的な対応(ロールバック、スケーリング、ベンダーへのエスカレーション)
Next update: 次の更新時刻
Updates:
- HH:MM (TZ) — Investigating: …
- HH:MM (TZ) — Identified: …
- HH:MM (TZ) — Monitoring: …
- HH:MM (TZ) — Resolved: …
更新頻度ルールを決める
顧客は情報だけでなく予測可能性を求めます。
- 重大インシデントでは30〜60分ごとの更新を約束する(内容が"調査中"でも良い)
- 軽微な問題は頻度を下げられるが、必ず次回更新時刻を示す
- cadence(約束)を守れない場合は短い注記で遅延を伝え、期待値を再設定する
メンテナンス告知テンプレート
予定メンテナンスは落ち着いた構成で。標準化項目:
- メンテナンス窓:開始/終了時刻(タイムゾーン付き)
- 想定影響:none / degraded / intermittent / downtime
- 影響コンポーネント
- 顧客アクション(ある場合):"特に操作は不要" か 明確な手順
- 開始時と終了時の短い通知
具体的に何が変わるか、ユーザーが何を感じるかを明記し、過度な約束は避け正確性を優先してください。
スキャンしやすいインシデント履歴を作る
エクスポートで管理を維持
コードベースをすべて所有し、準備ができたら自社のスタックに合わせて適用する
インシデント履歴は単なるログではなく、顧客やチームが問題の頻度や傾向、対応を見るための手段です。
履歴を残す価値
透明性は信頼を築きます。定期的な"APIレイテンシ"の再発が見えれば、性能改善投資の判断材料になります。継続的な報告はサポートチケットの自己解決につながり、時間の節約にもなります。
保持期間を決める
顧客の期待やプロダクトの成熟度に応じて保持ウィンドウを選んでください:
- 90日:初期段階のSaaSによく使われる、ページを軽く保てる
- 6〜12か月:信頼性を評価するエンタープライズ顧客向けに適切
- それ以上:古い記録は別のアーカイブページにエクスポートすることを検討
選んだら明記してください(例:「インシデント履歴は12か月保持」)。
各エントリを瞬時に理解できるようにする
スキャンしやすさは一貫性から生まれます。予測可能な命名例:
YYYY-MM-DD — 短い要約(例:"2025-10-14 — メール配信遅延")
各インシデントには最低でも:
- 影響コンポーネント
- 開始/終了時刻(タイムゾーン付き)
- 影響レベル(小/大)
- 短い解決ノート
詳細がある場合はリンクする
ポストモーテムを公開しているなら、インシデントの詳細ページからリンクしてください(例:「ポストモーテムを読む」 -> /blog/postmortems/2025-10-14-email-delays)。タイムラインは簡潔に保ちながら、詳細を読みたい人に深掘りを提供できます。
購読と通知を追加する
顧客がページを見に来るのを待つより、購読で自動的に通知を送る方が有効です。購読があればページを何度もリロードする必要がありません。
顧客が既に使っているチャネルを提供する
一般的には少なくとも:
- Email(多くの顧客のデフォルト)
- SMS(緊急で重要な通知向け)
- Slack / Microsoft Teams(ビジネス顧客や運用チーム向け)
- RSS/Atom(技術ユーザーや内部ツールで有用)
複数チャネルをサポートする場合、登録フローは一貫させて四つに分かれるように感じさせないようにしてください。
オプトインと設定を明確にする
購読は常にオプトイン。特にSMSは、確定前に何を受け取るかを明示してください。
購読者に以下の選択肢を与えるとアラート疲れを防げます:
- 範囲:全更新 vs 選択したコンポーネントのみ(例:「API」のみ)
- 種類:インシデントのみ、メンテナンスのみ、または両方
- 重大度(任意):"Major outageのみ" vs "全更新"
コンポーネント別購読がすぐに提供できない場合は、まず"全更新"で始め、後からフィルタを追加してください。
通知が障害時に失敗しないようにする
インシデント中はメッセージ量が急増し、サードパーティがスロットルする可能性があります。確認ポイント:
- 配信能力:メールのSPF/DKIM/DMARC、検証済み送信ドメイン、顧客が認識するFromアドレス
- レートリミットとスロットリング:メール/SMSプロバイダの制限、Slack/TeamsのWebhook制限、再試行の挙動
- フォールバック:Slackが失敗したらメールを送る、SMSが遅延したらステータスページに明確なバナーを出す等
四半期ごとの定期テストを行い、購読機能が期待通り動くことを確認する価値があります。
"更新を購読" を見逃せない場所に置く
ステータスホームページの折りたたまれない領域(上部)に目立つコールアウトを置き、顧客が次のインシデント前に登録できるようにします。モバイルでも表示されるようにし、サポートポータルやヘルプセンターからもリンクしてください。
構築方法の選択:ホステッド vs 自前
コンポーネントを正しくマッピング
顧客に伝わる、分かりやすいコンポーネント一覧とステータスモデルを生成
どう作るかは「作れるか」よりも、何を最優先するか(立ち上げの速さ、障害時の信頼性、運用コスト)で決めます。
オプション1:ホステッドのステータスツールを使う
ホステッドは通常最速の道です。既製のステータスページ、購読機能、インシデントタイムライン、監視との統合を得られます。
ホステッドツールを選ぶ際のチェックポイント:
- 信頼性と独立性:メインアプリがダウンしてもステータスページにアクセスできる
- APIと自動化:インシデント作成、コンポーネント更新、API/Webhook経由での進捗更新
- アクセス制御:投稿可能な役割とドラフト/公開の管理。SSOはプラス
- ブランディングとカスタムドメイン:status.yourcompany.comなど
- 分析:購読者数、更新の閲覧数、メール配信のメトリクス
- コンプライアンス要件:監査ログや保持期間が必要な場合の対応
オプション2:自前(DIY)で構築する
フルコントロールが得られますが、信頼性と運用は自分で担保する必要があります。現実的なDIYアーキテクチャ:
- 静的サイト(高速・キャッシュに強い)でUIと履歴を提供
- APIバックエンド/軽量CMSでインシデントとコンポーネントを管理
- CDNと積極的なキャッシュで障害時のトラフィックに耐える
セルフホストするなら障害時のフェールモードを計画してください:主要DBが落ちたら、デプロイパイプラインが落ちたらどうするか。多くのチームはメインプロダクトとは別のインフラやプロバイダでステータスページを運用します。
DIYのコントロールを得つつ全てを作り直したくない場合、チャット駆動の仕様からカスタムなステータスサイト(Web UIと小さなインシデントAPI)を素早く立ち上げられるようなプラットフォーム(例:Koder.ai)の利用も検討できます。これにより、コンポーネントモデルやインシデント履歴UX、内部の管理ワークフローをカスタマイズしつつ、ソースコードをエクスポートしてデプロイできます。
コスト計画
ホステッドは月額が予測しやすい一方、DIYはエンジニア時間、ホスティング/CDN、継続的な運用コストがかかります。選択時は予想月額と必要な内部工数を見積もり、予算と照らし合わせてください(参照:/pricing)。
監視とインシデントワークフローを接続する
ステータスページは迅速に現実を反映してこそ有用です。問題を検出するシステム(監視)と対応を調整するシステム(インシデント管理)をつなげると、更新が一貫して迅速になります。
ステータス更新はどこから来るべきか
多くのチームは三つを組み合わせます:
- 監視アラート(ヘルスチェック、シンセティックテスト、エラー率、レイテンシ、キュー深度)。検知に優れるが顧客影響を必ずしも説明しない
- 手動更新(オンコールやサポートチーム)。人は文脈(誰が影響を受けるか、回避策など)を追加できる
- インシデント管理ツール(PagerDuty、Opsgenie、Jira Service Managementなど)。タイムライン、役割、解決メモを要約してステータスページに反映できる
実用ルール:監視が検出し、インシデントワークフローが調整し、ステータスページが伝える。
役立つ自動化(過度な約束はしない)
自動化は数分を節約できます:
- 高重大度のモニタがトリガーしたときにインシデントを自動作成(タイトル、影響コンポーネント、初期重大度をプリセット)
- ヘルスチェックからコンポーネント状態を更新(例:レイテンシ閾値超過で"Web app: Degraded Performance")
- ステータス変更をSlack/Teamsのインシデントチャンネルに同期し、対応者が顧客の見ている内容を確認できるようにする
初回の公開メッセージは保守的に:"調査中:エラー増加" は 検証中に "障害確定" と出すより安全です。
人のレビューなしで全自動にしない
完全自動は誤報や誤解を招く危険があります:
- ノイジーなアラートで誤ったインシデントが投稿される
- 一部の監視では顧客に支障がない場合でも"ダウン"に見えることがある
- 自動解決でユーザーがまだ影響を受けているのに閉じてしまうことがある
自動化は下書きや提案の作成に使い、特に Identified / Mitigated / Resolved のステートは人の承認を必須にするのが安全です。
監査ログを保持する
ステータスページを顧客向けのログブックとして扱い、次を答えられるようにしてください:
- 誰がインシデント状態を変更したか?
- 何が変更されたか(テキスト、コンポーネント、タイムスタンプ)?
- いつ変更されたか?
監査ログは事後レビューや引き継ぎ時の混乱を減らし、顧客からの照会に対する信頼できる回答になります。
信頼性を確保する:ホスティング、DNS、障害対策
ステータスページは、製品がダウンしているときにアクセス可能でなければ意味がありません。最も一般的な失敗は、ステータスページをアプリと同じインフラに構築してしまうことです。するとアプリの障害とともにステータスも消えてしまいます。
コアスタックから分離する
可能ならステータスページはプロダクションアプリとは別のプロバイダ(または別リージョン/別アカウント)でホスティングしてください。目標はブラスト半径の分離です:アプリ基盤の障害が通信基盤まで及ばないようにします。
DNSも分離を検討してください。メインドメインのDNSがアプリのエッジ/CDNと同じ場所にあると、DNSや証明書の問題で双方がブロックされることがあります。多くのチームは独立したサブドメイン(例:status.yourcompany.com)と独立DNSを使います。
ページを高速かつ堅牢にする
アセットは軽量に:最小限のJavaScript、圧縮CSS、アプリAPIに依存しないレンダリング。CDNを前段に入れ、静的リソースはキャッシュしてトラフィックピーク時にもロードされるようにします。
実用的な安全策はフォールバックの静的モードです:
- 最終状態やインシデントバナーを事前レンダリングしておく
- オブジェクトストレージや静的ホスティングから配信する
- 動的更新が可能な時は動的に、できない時は優雅に劣化させる
公開を基本に、管理画面は安全に
顧客はログイン不要で稼働状況を見られるべきです。一方、管理/編集ツールは認証(可能ならSSO)で保護し、強いアクセス制御と監査ログを設けてください。
最後に、フェールシナリオをテストしてください:ステージング環境でアプリ起点を一時的に遮断し、ステータスページが解決・高速に読み込め、必要な更新を投稿できるか確認します。
運用プロセス:誰がいつ更新するか
ワークフローを先に計画
Planning Modeを使って、担当者・実行頻度ルール・ワークフローを構築前に定義
ステータスページはインシデント時に一貫して更新されて初めて信頼を築けます。その一貫性は偶然には生まれません。明確な所有、単純なルール、予測可能な更新頻度が必要です。
役割を事前に定義する
コアチームは小さく明確に:
- Incident Commander(IC):対応を指揮し、安定化を確認
- Communications Lead:ステータスページに投稿し、顧客向けの文言を整える
- オンコールのエンジニア:調査・緩和を行い、ICへ事実を伝える
小規模チームなら一人が二役を兼任しても構いませんが、事前に役割の引き継ぎとエスカレーション経路をオンコールハンドブックに記載しておいてください(参照:/docs/on-call)。
毎回従う単純な更新チェックリスト
アラートが顧客影響インシデントになったら、再現可能なフローに従います:
- 認知:速やかに「Investigating」を投稿(詳細が乏しくても可)
- 影響評価:どのコンポーネント/リージョン/顧客セグメントが影響を受けるか確認
- 投稿:ユーザーが見る症状、回避策(あれば)、次回更新時刻を共有
- 解決:サービス復旧を確認し、監視していることを伝える
- 要約:短い総括を追加し、完全なレビューへのリンクを貼る
実用ルール:初回更新は10〜15分以内に、影響継続時は30〜60分ごとに投稿する("変化なし、調査中"も可)。
解決後:振り返りと改善
解決後1〜3営業日以内に軽量な事後レビューを実施:
- タイムライン:検知から復旧までの主要イベント
- 根本原因(現時点での最良推定):平易な言葉で説明
- アクションアイテム:具体的な修正、担当者、期日
その後、インシデントエントリを最終まとめで更新し、履歴が単なる"解決"のログで終わらないようにします。
ローンチチェックリストと継続的改善
ステータスページは見つけやすく、信頼でき、継続的に更新されることが重要です。公開前に実務的なチェックを行い、ローンチ後は軽い改善サイクルを回してください。
ローンチチェックリスト(実務版)
コピーと構成
- コンポーネント名が顧客の呼び方と一致しているか確認(例:"Dashboard" vs 内部名)
- "このページが示すこと" の短い説明文とアカウント固有問題用のサポートリンク(例:/support)を追加
- インシデント更新が顧客影響("決済失敗")と次の対応("10分後に再試行")を説明しているか
ブランディングと信頼
- ロゴ、ファビコン、シンプルな色分け(微妙すぎる色は避ける)を追加
- タイムスタンプ形式とタイムゾーンを明確にする
アクセスと権限
- インシデント投稿、メンテスケジューリング、ページ設定編集の権限を確認
- "オンコールバックアップ" を設定して一人に依存しないようにする
フルワークフローのテスト
- テストインシデントを実行(テストであると明示して解決まで行う)
- メール/SMSで購読して通知が届くか、リンクが正しいかを確認
アナウンス
- アプリフッターやヘルプセンター、サポートの自動返信にステータスページのリンクを追加
- 短い顧客向け案内を送り、何を期待するかと購読方法を説明
自前で構築する場合はステージングで同じチェックリストを回すことを推奨します。Koder.aiのようなツールは、Web UI、管理画面、バックエンドエンドポイントを仕様から生成してエクスポート/デプロイできるため、反復を速められます。
"改善した" の測定方法
月次レビューでいくつかの成果を追跡:
- チケット削減:ローンチ前後のインシデント関連チケット数比較
- 初回更新の速さ:検知から初回公開までの時間の短縮
- 購読者増加:チャネル別とどのコンポーネントをフォローしているか
インシデントパターンから学ぶ
単純な分類で履歴を実用化:
- インシデントにカテゴリを付ける(性能、部分障害、サードパーティ、メンテナンス、セキュリティ関連)
- 再発するコンポーネントを記録
- これを優先度の決定やポストインシデントレビューに活かす
SEOの基本(顧客がページを見つけやすくする)
- ページタイトルは「Service Status」や「Incident History」など明瞭に
- 見出しはH2/H3で構造化し、履歴ページがスキャンしやすいように
- (セキュリティ上の理由がなければ)インシデント履歴ページはインデックス可能にし、メインのステータスページと各インシデントにクロール可能なリンクを張る
小さな改善(明瞭な文言、速い更新、よりよい分類)は積み重なって、チケット減少や顧客信頼の向上につながります。
よくある質問
SaaSステータスページとは何で、なぜ重要ですか?
SaaSのステータスページは、現在のサービス稼働状況とインシデントの更新情報を一箇所で提供する専用ページです。これにより「ダウンしているの?」というサポート問い合わせが減り、障害時の期待値を設定でき、タイムスタンプ付きの明確なコミュニケーションで信頼を築けます。
リアルタイムステータス、インシデント履歴、ポストモーテムの違いは何ですか?
リアルタイムのステータスは「今この瞬間、製品を使えますか?」に答え、コンポーネント単位の状態を示します。
インシデント履歴は「どれくらい頻繁に起きているか?」に答え、過去のインシデントやメンテナンスのタイムラインを提示します。
ポストモーテムは「なぜ起きたか、何を変えたか?」に答え、根本原因と再発防止策を説明する詳細な報告です(インシデントの詳細ページからリンクすることが多いです)。
ステータスページの目標はどう決めればよいですか?
まず2〜3つの測定可能な成果を決めます。例:
- インシデント時の重複チケットの減少
- 初回更新までの時間の短縮(例:10〜15分以内)
- 通知購読数(メール/SMS/Slack)の増加
これらを文書化し、月次で見直すとステータスページが陳腐化しません。
誰がステータスページの更新を担当すべきですか?インシデント時の混乱を避けるには?
明確な所有者とバックアップを割り当てます(多くはオンコールのローテーション)。一般的な役割:
- インシデントコマンダー(IC):対応を取りまとめ、優先度を決定
- コミュニケーションリード:顧客向けの文言を投稿
事前に誰が投稿できるか、承認が必要か、最小更新頻度(例:重大インシデント時は30〜60分ごと)を定義しておくと混乱を避けられます。
ステータスページにどのコンポーネントを表示すべきですか?
顧客が問題を説明する言葉に基づいてコンポーネントを選びます。一般的な項目例:
- API
- Webアプリ / ダッシュボード
- 認証(ログイン / SSO)
- 請求
- インテグレーション(重要な子項目:WebhooksやSalesforceなど)
信頼性が地域で異なるなら地域別に分けます(例:「API – US」「API – EU」)。内部のサービス名は避け、顧客向けの名称を使ってください。
どんなステータスレベルを使うべきですか?一貫性はどう保てばいいですか?
小さく一貫したステータスセットを使い、各レベルの内部基準を文書化します。例:
- Operational(稼働中)
- Degraded Performance(性能劣化)
- Partial Outage(部分的な障害)
- Major Outage(大規模障害)
一貫性が重要です。顧客は繰り返し使うことで各レベルの意味を理解します。
顧客にとって役立つインシデント更新には何を含めるべきですか?
有用なインシデント更新は最低でも以下を含みます:
- 開始時刻(タイムゾーン付き)
- 影響を受けるコンポーネント/リージョン
- 平易な言葉での顧客影響
- 現在の状態(Investigating / Identified / Monitoring / Resolved)
- 実行可能な次回更新時刻
根本原因が不明でも、範囲と影響、次のアクションを伝えれば顧客は状況を把握できます。
障害時にどれくらいの頻度でステータスページを更新すべきですか?
初回の「Investigating」更新は速やかに(確認後10〜15分以内が目安)投稿します。それから:
- 重大インシデント:30〜60分ごとに更新
- 小規模インシデント:頻度は低くて良いが、次回更新時刻は必ず示す
約束した頻度を守れない場合は、短い注記で遅延を知らせて期待値をリセットしてください。沈黙は避けるべきです。
ホステッドのステータスツールを使うべきですか、それとも自前で作るべきですか?
ホステッドツールは立ち上げが早く、購読やインシデント履歴、外部監視との統合を備えている場合が多いです。一方DIYは完全なコントロールを得られますが可用性を自分で担保する必要があります。
DIYの推奨アーキテクチャ:
- ステータスUIと履歴は静的サイト
- インシデントやコンポーネントは軽量なAPIやCMSで管理
- CDNと積極的なキャッシュでトラフィックスパイクに耐える
比較時は月額費用と内部工数の両方を見積もって選んでください(参照:/pricing)。
どの通知チャネルを提供すべきですか?アラート疲れを防ぐには?
顧客が普段使っているチャネルを提供します(一般的にはメールとSMS。ビジネス顧客向けにSlack/Teams、技術ユーザー向けにRSS/Atomも有用)。購読はオプトインにし、以下を明確にします:
- 受け取る内容(インシデント、メンテナンス、または両方)
- コンポーネントや重大度でのフィルタ(可能であれば)
配信能力、レートリミット、送信ドメインの設定(SPF/DKIM/DMARC)を定期的にテストし、障害時でも通知が届くようにしてください。