2025年7月03日·1 分
サポート負荷と人員ニーズを追跡するWebアプリを作る
サポートの負荷、主要指標、スタッフ必要数を予測・アラート・レポートで可視化し、チームが行動できるWebアプリの計画と構築方法を解説します。
このWebアプリが解決すべきこと
このWebアプリは実用的な問いに答えるためにあります:「入ってくる需要に対して十分なサポート能力があるか?」。不確かな答えが出るとボトルネック、ストレスの多いエージェント、サービスレベルのばらつきが生まれます。
チームにとっての「サポート負荷」を定義する
「サポート負荷」は単一の数値ではありません。到着する仕事、待っている仕事、解決に必要な労力の組み合わせです。多くのチームで含まれるのは:
- 着信量:チケット、ライブチャット、通話、メール(運用しているチャネル)
- バックログ:オープン項目、経過時間の長い項目、目標を超えている項目
- 作業の複雑さ:単純な質問と多段階ケース(通常は処理時間、タグ、カテゴリに反映)
- 中断:エスカレーション、再オープン、引継ぎ、顧客待ちサイクル
アプリは何を負荷として数えるかを選べるようにし、それを一貫して計算するべきです—そうすれば計画は意見から共通の数値になります。
目指す成果
良い最初のバージョンは次を助けます:
- どこで、いつキューが積み上がるか(とその理由)を発見する
- 日々の需要を明確な人員計画に変換する(今日、来週、来月)
- サービスレベル(応答時間、解決時間、SLA遵守)を推測ではなく保護する
未来を完璧に予測する必要はありません。サプライズを減らし、トレードオフを明確にすることが目的です。
利用者と日常的な疑問
このアプリの主な利用者はサポートリード、サポートオプス、マネージャーです。日常的に尋ねられる典型的な質問は:
- 「今、追いつけているか、それとも遅れているか?」
- 「ボリュームが急増したら、追加で何人必要で、どれくらいの期間か?」
- 「バックログが増えているのは需要、複雑さ、キャパシティのどれのせいか?」
- 「どのチャネルやキューが実際のボトルネックか?」
期待値の設定:まずはシンプルに、徐々に改善
少数のメトリクスと基本的な人員見積もりから始めましょう。人々が数値を信頼するようになったら、キュー・地域・ティアでのセグメンテーション、より正確な処理時間、改善された予測を追加していきます。
要件:ゴール、ユーザー、成功指標
チャートや連携を選ぶ前に、アプリの目的と除外事項を定義してください。明確な要件は最初のバージョンを小さく、有用で、採用しやすく保ちます。
小さな目標を選ぶ
日常のサポート計画に直接結びつく2〜4の目標から始めます。初期の良い目標は具体的で測定可能です。例:
- 来週の日ごとのチケットボリュームを予測する(必要なら時間別)
- バックログがキャパシティより速く増えている時間帯を特定する
- 今日と明日のバックログ対キャパシティを一目で見えるようにする
- 人員変更が違反やエスカレーションを減らしたかを追跡する
目標が1~2週間以内に行動に繋がらないなら、v1には広すぎます。
5~10のユーザーストーリーでユーザーを定義する
誰がアプリを開き、何をしたいのかを短く具体的に列挙します:
- 「サポートリードとして、今日のバックログ対キャパシティを一目で見て、再割り当ての判断をしたい。」
- 「チームマネージャーとして、週ごとのボリューム傾向を比較して次週のスケジュールを立てたい。」
- 「エージェントとして、全員対応モードの時に非緊急作業を止められる通知が欲しい。」
- 「オペレーションとして、共有用の週次スタッフサマリをエクスポートしたい。」
このリストがビルドチェックリストになります:画面やメトリクスがストーリーをサポートしないなら任意です。
アプリが可能にすべき意思決定を定義する
要件はデータだけでなく意思決定をサポートするべきです。人員と負荷追跡でアプリは次のような決定を支援する必要があります:
- シフトを追加、カバレッジを延長、他キューから人を移す
- チケットを再割り当て(またはルーティングを変更)して待ち時間を減らす
- ピーク時にプロジェクトや研修を一時停止する
- 残業を承認するかオンコールの入れ替えを行う
行動を明確に名前にできないなら、その機能が役立つか評価できません。
成功基準を設定する
いくつかのアウトカムと測定方法に合意してください:
- レポート時間: 例「日次スタッフビューは10秒以内で読み込まれる」
- 採用率: リード/マネージャーの週次アクティブユーザー、繰り返し利用
- 運用影響: エスカレーション減少、SLA違反減少、初回応答時間短縮
- 計画の信頼度: 突発的なスケジュール変更減少、予期せぬバックログ急増減少
これらをプロジェクト文書に書き、ローンチ後に見直してください。チャートの数ではなく有用性で評価されるようにします。
データソースと必要最小限のデータ
スタッフと負荷のアプリは、取り込めるデータの信頼性に依存します。初期バージョンの目標は「すべてのデータ」ではなく、負荷を説明しキャパシティを測りリスクを検出するのに十分な一貫したデータです。
計画すべき主要ソース
まず仕事、時間、利用可能な人を表すシステムを列挙します:
- ヘルプデスク(チケット):件数、ステータス、優先度、割当、タイムスタンプ
- チャットツール:着信チャット、対応済みチャット、待ち時間、キュー別のスタッフ情報(利用可能なら)
- 電話システム:通話量、応答済みvs不在、平均処理時間
- スケジュール/WFMまたはカレンダー:シフト、PTO、オンコール、タイムゾーンのカバレッジ
- HR/ヘッドカウント:チーム構成、開始/終了日、役割(エージェント/リード)、契約時間
電話やチャットが雑なら、日一番にチケットから始め、パイプラインが安定したら追加してください。
API連携 vs CSVインポート(v1の判断)
- API連携は頻繁な更新、自動化、一貫したスキーマが必要なときに最適です。構築に時間はかかりますが手作業を減らします。
- CSVインポートはテンプレートが厳格であればスケジュールやHRの最速の第一歩です。
実務的には混合アプローチ:ヘルプデスクはAPI、高頻度で時間感度が高いもの、スケジュールやヘッドカウントはCSVで始める、が良いでしょう。
更新頻度:リアルタイムが常に必要なわけではない
支援する意思決定に応じて更新頻度を選びます:
- リアルタイム/準リアルタイム: ライブキューモニタリング、「遅れている」アラート
- 毎時: 日中の人員調整と傾向の可視化
- 日次: 週次計画、人員増員の正当化、経営向け報告
抑えておくべき最小の次元
メトリクスを行動可能にするために、ソースごとにこれらの次元を保存してください:
チャネル(ticket/chat/phone)、チーム、優先度、タイムゾーン、言語、顧客ティア。
初期に一部フィールドが欠けていても、後で作り直さずに済むようスキーマを拡張可能に設計してください。
追跡すべきサポート指標(過剰に複雑にしない)
全てを追うとプロジェクトは脱線します。到着量、待機量、応答・解決速度の3点を説明する少数の指標から始めましょう。
コア指標(まずここから)
多くのチームが早期に信頼できる4つの指標に注力します:
- 着信量: 日次/週次の新規チケット、できればチャネルと優先度別
- バックログ: ある時点のオープンチケット数とバックログ年齢(X時間/日を越えた件数)
- 初回応答時間(FRT): 作成から最初の人による返信までの時間。中央値と90パーセンタイルを追う
- 解決時間: 作成から解決/クローズまでの時間。中央値と90パーセンタイルを追う
この4つで「追いつけているか?」と「どこで遅延が出ているか?」に答えられます。
生産性指標(慎重に追加)
定義に全員が合意している場合のみ有用です。
二つの一般的な選択肢:
- 担当あたりの処理数: エージェント1人あたりの日次/週次の解決数。"処理"を解決/返信/関与のどれと定義するかを明確にする。
- 稼働率(Occupancy): エージェントの時間のうちチケット作業に費やした割合。時間計測が信頼できないならv1では除外する。
エージェント間の比較はルーティング、複雑さ、シフト時間で歪みやすい点に注意してください。
SLAターゲットと違反
SLAを追うならシンプルに:
- 優先度とチャネルごとにSLA目標を定義する(例:P1チャット:FRT < 5分; P3メール:FRT < 8時間)
- FRTと解決での違反を別々にカウントする
- SLAタイマーが営業時間外で停止するか(そして「営業時間」が何か)を保存する
定義を明確にするための用語集を作る
アプリ内に単一の用語集ページ(例:/glossary)を追加し、各指標の定義、計算式、エッジケース(マージされたチケット、再オープン、内部メモ)を載せておきましょう。一貫した定義は議論を防ぎ、ダッシュボードの信頼性を高めます。
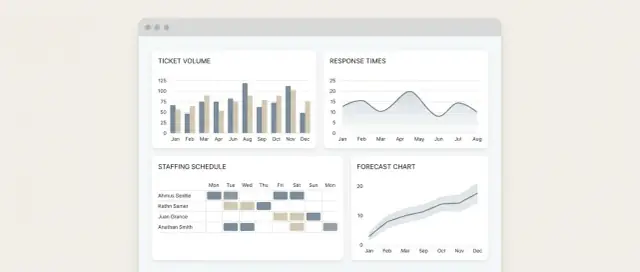
ダッシュボード設計:画面、フィルタ、ビジュアル
プロトタイプから本番へ
カスタムドメインと再現可能なデプロイで、デモから実運用へ移行。
良いサポートダッシュボードは数秒で繰り返し尋ねられる問いに答えます:"ボリュームは変わっているか?", "追いつけているか?", "どこがリスクか?", "来週何人必要か?"。UIはこれらの問いを中心に設計してください。
3つのコア画面
1) Overviewダッシュボード(コマンドセンター)
日次チェックインのデフォルト着地ビューです。今日/今週の着信、解決、現在のバックログ、需要がキャパシティを上回っているかを表示します。
2) Team drill-down(負荷の蓄積を診断)
リードが単一のチームやキューをクリックし、負荷の原因(チャネル構成、優先度構成、バックログ増加の主因)を確認できるようにします。
3) Staffing planner(メトリクスを人員数に変える)
需要を必要キャパシティに翻訳するビュー:予測ボリューム、想定処理時間、利用可能なエージェント時間、単純な"ギャップ/余剰"結果を表示します。
質問ごとに一つの主要チャート
各チャートは一つの意思決定に紐づけます:
- ボリューム傾向: 日/週別の着信チケットの単純な折れ線
- バックログ: 時系列のオープンチケットのラインまたはエリアチャート("開始vs終了バックログ"ラベル付き)
- キャパシティ対需要: 必要チケット(または時間)対利用可能チケット(または時間)の二本線/バー
補助指標は小さな数値カードとして隣に置けます(例:「% within SLA」「中央値初回応答」)が、カードを全てチャートにしないでください。
実際に使われるフィルタ
デフォルトフィルタは多くのワークフローをカバーします:
- 日付範囲("過去7日"、"今月" などのクイックピック)
- チーム/キュー
- チャネル
- 優先度(必要に応じて"顧客ティア")
フィルタは画面間でスティッキーにして、ユーザーが何度も選び直さなくて良いようにします。
すばやく確認できるようにデザインする
プレーンなラベル("Open tickets"、"Resolved")と一貫した単位を使い、閾値ごとにステータス色(緑/黄/赤)を付けます。メトリックカードにはスパークラインを入れて方向感を示し、可能ならば"何が変わったか"(例:"Backlog +38 since Monday")を表示して次のアクションを明確にします。
人員ニーズのための需要とキャパシティモデル
これがアプリの中心にある"計算機"です:どれだけのサポートリクエストが来るか(需要)、チームがどれだけの作業を扱えるか(キャパシティ)、ギャップはどこか。
ステップ1:需要(着信作業)のモデル化
シンプルかつ説明可能に始めます。初期は移動平均で十分なことが多いです:
- 過去2〜8週間のデータから時間帯・日別にチケット/チャットを予測
- チャネルごとに別カーブを保つ(メールとチャットで挙動が違う場合)
- ユーザーが参照ウィンドウを選べるようにする(例:"過去4週間を使用")。季節性や最近のローンチで歪むことがあるためです。
履歴が十分でなければ、"昨日の同じ時間"や"先週の同じ日"にフォールバックし、予測の信頼度が低い旨を表示します。
ステップ2:キャパシティ(利用可能な生産作業)のモデル化
キャパシティは「ヘッドカウント×8時間」ではありません。エージェントが1時間にどれだけ処理するかで調整した勤務時間です。
実用的な式:
Capacity(チケット/時) = スケジュールされたエージェント数 × 1人あたりの生産時間 × 生産性率
ここで:
- 1人あたりの生産時間はスケジュール時間から縮減(shrinkage)を差し引いたもの
- 生産性率は「生産時間ごとの解決チケット数」(または1時間あたりのチャット処理数)で、まずはチャネルごとに単一の数値を使い後で精緻化します
ステップ3:縮減(shrinkage)を設定可能にする
縮減は支払われるが利用できない時間:休憩、PTO、研修、ミーティング、1:1などです。これらを編集可能なパーセンテージ(またはシフトごとの固定分)として扱い、オペレーション側でコード変更なしに調整できるようにします。
ステップ4:実行可能なスタッフギャップを出力する
需要対キャパシティを明確な推奨に変換します:
- 「14時〜18時に+2人が必要」または「1人の過剰」
- 「中程度の信頼度:4週間移動平均に基づく;祝日週は除外」といった信頼度注記を付ける
これにより、より高度な予測を追加する前からモデルを有用に保てます。
初期バージョンで効く予測手法
初期予測は高度な機械学習を必要としません。目的はシンプルで十分に説明可能な見積りを出し、リードがシフトを計画し、負荷を察知できることです。
シンプルに始める:移動平均
強力なベースラインは過去N日の移動平均です。ランダムなノイズを平滑化し、トレンドを素早く把握できます。
ボラティリティが高ければ2本を併記:
- 7日移動平均(反応が速い)
- 28日移動平均(より安定)
軽量の季節性を追加(曜日・時間帯)
サポートの仕事は通常パターン化しています:月曜と金曜は違う、朝と夜は違う。複雑にしすぎず平均を計算する方法:
- 曜日別(Mon–Sun)
- 必要に応じて時間帯ブロック(例:2時間区切り)
その後「典型的な月曜」プロファイルを使って翌週を予測するだけでも、単純な移動平均より良い結果を出すことが多いです。
スパイクはイベントマーカーで扱う
実際には外れ値(ローンチ、請求変更、障害、祝日)が出ます。これらでベースラインが歪まないように:
- 手動のイベントマーカー(日付範囲+ラベル+ノート)を追加
- 極端な日をベースライン計算から除外するか、イベント日と通常日の比較を保つ
週次で検証し誤差を追跡する
毎週、予測と実績を比較し誤差指標を記録します。単純で良い指標:
- MAPE(平均絶対パーセンテージ誤差)
- 平均%誤差(符号付き:過大/過少)
誤差をトレンド化してモデルが改善しているか、ずれているかを確認します。
見積りを説明可能にする
「必要人員:12人」を根拠なしに表示しないでください。数値の横に入力と手法を示します:
- 期待ボリューム(とそのソース)
- 想定生産性(チケット/時)
- カバレッジ係数(ミーティング、休憩、バックログ)
- 使用したベースライン(7日移動平均、曜日パターン等)
透明性が信頼を生み、仮定の誤りを素早く修正できます。
ユーザーロール、権限、運用ワークフロー
ソースをエクスポートして構築
エクスポートして準備ができたらリポジトリに保存できる、すぐに動くコードを取得。
人々が数値を信頼し、変更できる範囲を知っていることが重要です。小さなロールセット、明確な編集権限、スタッフ決定に影響するものは承認フローを用意して始めましょう。
コアロール(とそれぞれの権限)
Admin(管理者)
- システム設定:データソース接続、チケットフィールドのマッピング、チーム管理、グローバルデフォルト(営業時間、タイムゾーン)
- ユーザー管理と権限設定
Manager(マネージャー)
- 集約パフォーマンスと計画ビューの閲覧:ボリューム傾向、バックログリスク、キャパシティ対需要、予定カバレッジ
- 人員仮定や目標の提案/承認
Agent(エージェント)
- 個人キューのメトリクス、チームレベルの負荷、スケジュール/シフトの確認
- ツールをパフォーマンスの公開掲示板にしないため、エージェントのアクセスは制限する
アプリ内で編集可能にすべきもの(編集不可のもの)
計画入力は編集可能にし、インポートされた事実は編集不可にします。例:
編集可能:
- スタッフィングターゲット(例:「4時間以内に応答」)
- スケジュールと計画カバレッジ(シフト、PTO、研修)
- 仮定(処理時間、縮減、チャネルミックス、予測オーバーライド)
編集不可:
- インポートされたチケット件数やタイムスタンプ。問題があればソース側で修正するかマッピングルールで対処する。
監査履歴と承認
予測やカバレッジに影響する変更は全て監査エントリを作成します:
- 誰が何をいつ変更したか
- オプションのノート("祝日週調整"、"新製品ローンチ")
- 仮定やスケジュールのバージョン管理(過去の計画と結果を比較可能にする)
シンプルなワークフローが有効です:Managerが下書きを作成 → Adminが承認(小チームではManager承認でも可)。
機微なデータへのアクセス制御
保護すべきカテゴリ:
- エージェントの個別パフォーマンス詳細(個別の処理時間、再オープン率)
- 顧客情報(名前、メール、メッセージ内容)
最小権限をデフォルトに:エージェントは他者の個別指標を見られない、マネージャーはチーム集計を見られる、管理者のみ顧客レベルのドリルダウンにアクセス可能にします。個人情報や顧客データを隠した"マスクビュー"を用意し、計画作業をデータ露出なしに行えるようにします。
アーキテクチャと技術スタック(シンプルで保守しやすく)
初期版は複雑なスタックが不要です。予測可能なデータ、速いダッシュボード、将来のツール追加で抵抗しない構造が必要です。
シンプルで実績ある構成
4つのブロックから始めます:
- Web UI: マネージャーがダッシュボードと人員予測を見る場所
- API: ダッシュボードクエリに応え、取り込んだメトリクスを受け取るバックエンド
- データベース: 生イベント(チケット、ステータス変更)と集計メトリクスを保存
- スケジュールジョブ: データ取り込み、日次/時間別サマリ計算、キャッシュ更新
この形にすることで障害の原因("取り込みが壊れた" vs "ダッシュボードが遅い")を切り分けやすく、デプロイも単純にできます。
ストレージ:専用の時系列DBはまだ不要
初期のヘルプデスク分析ではリレーショナルテーブルで十分です。一般的なアプローチ:
tickets_raw(チケットまたはステータスイベントごとに1行)metrics_hourly(キュー/チャネルごとの時間毎の行)metrics_daily(高速レポーティング用の日次ロールアップ)
time、queue、channelにインデックスを付け、データが増えたら月単位でパーティション化するか集計を専用の時系列ストアに移行できます—アプリ全体を書き直す必要はありません。
データパイプライン:ingest → normalize → aggregate → cache
パイプラインを明示的な段階に分けます:
- Ingest:API/Webhookでヘルプデスクツールから取り込む
- Normalize:一貫したスキーマにフィールドを正規化(キュー、優先度、営業時間)
- Aggregate:キュー管理やスタッフ計算機に必要なメトリクスに集計
- Cache:フィルタが高速に読み込めるようにダッシュボード向け結果をキャッシュ
境界をきれいに保つ統合設計
外部システムはコネクタモジュールとして扱います。ツール特有の癖はそのコネクタの中に閉じ込め、安定した内部フォーマットを他の部分に公開します。そうすれば後から別の受信箱やチャットツール、電話システムを追加しても複雑さが漏れ出しません。
外部設計の参照構造を作るなら、/docsから"Connectors"と"Data Model"ページにリンクして、エンジニアでない人でも何が含まれ何が含まれないかを理解できるようにしてください。
Koder.aiで最初の開発を加速(任意)
v1を素早くサポートリードに見せたいなら、Koder.aiのようなvibe-codingプラットフォームで概観・ドリルダウン・スタッフプランナーのコア画面、API、PostgreSQLベースのスキーマをプロトタイプ化できます。ソースコードのエクスポートやスナップショット、ロールバックが可能なため、一時的プロトタイプに縛られず実験できます。
アラート、レポート、オートメーション
v1をより早くリリース
最初のバージョンを作成し、学びながら予測・SLA・フィルタを改善。
ダッシュボードは探索に優れますが、サポートチームはルーティンで動きます。アラートと軽量な自動化があると、誰もチャートを見ていない時でもアプリは役立ちます。
行動につながるアラート(ノイズは出さない)
何をすべきかに直結する閾値を設定します。少数から始めて調整します:
- バックログ過多: オープンチケットが許容範囲をX時間/日超え
- SLAリスク: 予測違反率が閾値を超える(例:「初回応答が5%超で未達予測」)
- スタッフギャップ: 予測需要と計画カバレッジの差が次のシフト/日に不足を示す
各アラートには何がトリガーされたか、どれほど深刻か、説明するビューへのリンクを含めます(例:/alerts、/dashboard?queue=billing&range=7d)。
EmailとSlackへの通知
チームが既に使っている場所に通知を送ります。メッセージは短く一貫性を保つ:
- タイトル:「Billingキュー:バックログが閾値を超過」
- 主要数値:バックログサイズ、SLA危険カウント、推定消化時間
- リンク:
/queues/billing?range=24h
Slackはリアルタイム運用向け、メールはFYIやステークホルダー向けに向きます。
意思決定を促す週次サマリ
毎週自動で(例:月曜朝)レポートを生成:
- 傾向のハイライト(ボリューム増減、バックログ傾向、SLA傾向)
- 主なドライバー(キュー、チャネル、タグ、カテゴリ)
- 推奨スタッフ調整(例:「火曜10–14に+1、金曜深夜シフトを削減」)
サマリは基になるビューにリンクし、すぐに検証できるようにします:/reports/weekly。
ステークホルダー向けエクスポート
ログインしない人もいるのでエクスポートを許可します:
- CSV:スプレッドシートでの詳細分析用
- PDF:更新共有用
エクスポートは画面上のフィルタ(期間、キュー)を反映するようにし、ステークホルダーが数値を信頼できるようにします。
テスト、ローンチ、継続的改善
サポート運用アプリは意思決定を変えることが成功の指標です。ローンチは信頼性・理解・利用を証明するものであるべきです。
重要な箇所にテストを集中する
正確さと明瞭さに集中:
- データ精度チェック: 共通カテゴリから20〜50の実際のチケットをピックし、アプリのカウント、応答時間、SLA結果が元システムと一致するか検証
- エッジケース: 欠損フィールド(カテゴリなし、担当者なし)、再オープン、マージ、タイムゾーン差分
- パフォーマンス簡易チェック: 日常使用で"即時"と感じる程度の読み込み速度を目標にする
自動テストを書くなら変換と計算ロジック(サポート負荷追跡のロジック)を優先し、UIのピクセル単位テストは重要度を下げます。
ベースラインを取り、前後比較を行う
ローンチ前に過去4〜8週間のベースラインをスナップショット:
- 日/週ごとのチケットボリューム
- 年齢バケット別バックログ
- 初回応答時間と解決時間
- 使ったスタッフ入力(予定時間、縮減仮定)
アプリが意思決定に使われた後、同じ指標を比較してスタッフ予測やキャパシティ計画の仮定が成果を改善しているかを検証します。
1チームでパイロットし、段階的に拡げる
まず1チームまたは1キューでパイロットを行い、2〜4週間運用してフィードバックを集める:
- チケットボリュームダッシュボードが週次計画に答えているか
- 混乱するフィルタや欠けているフィルタはあるか
- スタッフ計算機が現実離れしている箇所(スパイクに敏感すぎる等)はどこか
迅速に繰り返し改善します:ラベル修正、セグメント追加、デフォルト調整などの小さなUX改善が採用を促進します。
採用率は軽く、かつ配慮して追跡する
侵襲的な分析は不要です。利用状況を把握するために最小限だけ追跡:
- 週次のアクティブユーザー
- レポート閲覧数とダッシュボードの開封数
- アラートのクリック数
採用が低ければ理由を問います:データを信頼していないのか、ダッシュボードが煩雑なのか、ワークフローが合っていないのか?
次のステップを文書化して製品を前進させる
パイロットの学びに基づく"v2バックログ"を作成します:
- より良い連携(チャット、電話、CSAT)
- 予測と季節性処理の改善
- シナリオプランニング("FTEを1人増やしたら?" / "ボリュームが20%増えたら?")
このリストを可視化して優先度付けし、継続的改善をルーチン化してください。
よくある質問
まずこのアプリは何を解決すべきか?
まず一貫して追跡すべきは次の3点です:
- 需要(Demand): 時系列での新規チケット/チャット/通話
- 進行中の作業(Work-in-progress): 現在のバックログと年齢バケット
- キャパシティ(Capacity): スケジュールされたカバレッジを縮小率と合意された生産性で調整した値
これらの入力が安定していれば、「我々は追いついているか?」に答えられ、過剰構築せずにスタッフギャップ推定を出せます。
実用的に使える「サポート負荷」はどう定義すべきか?
負荷は次の要素の組み合わせとして定義します:
- 着信量(新規作業)
- バックログ(オープンかつ経過時間のある作業)
- 複雑さの代理指標(対応時間、タグ、優先度、顧客層)
- 中断(再オープン、エスカレーション、引継ぎ、顧客待ちサイクル)
測定可能な定義を選び、用語集に文書化しておけばチームは数字ではなく意思決定を議論できます。
この種のアプリでのv1の良い目標は何か?
v1は1〜2週間で行動に移せる目標に絞りましょう。良い例:
- 翌週の日ごとのボリュームを予測する(必要に応じて時間別)
- バックログが増える時間帯を特定する
- 今日/明日のバックログとキャパシティを可視化する
- 人員調整がSLA違反を減らしたかを追跡する
目標が迅速な運用決定を変えないなら、初回リリースには広すぎます。
スタッフ見積もりを出すために最低限必要なデータは何か?
v1は以下があれば十分に実用的なインサイトを出せます:
- ヘルプデスクのチケットデータ(タイムスタンプ、ステータス、優先度、キュー/チーム)
- スケジュール/カバレッジ(シフト、PTO、研修ブロック)
- 基本的なヘッドカウント/ロール(誰がアクティブか、どのチームか)
チャットや電話は後回しで、まず一つのチャネルを一貫して扱う方が優れます。
v1ではAPI連携とCSVインポートどちらが良いか?
実務的なハイブリッドが一般的です:
- 高頻度で時間感度の高いシステム(ヘルプデスク)はAPI連携
- 変化が遅い入力(スケジュール、HR)はCSVインポート
CSVを使う場合はテンプレートを厳格に管理して、列や意味がずれないようにしましょう。
過剰にならずに最初に追うべきサポート指標は何か?
多すぎる指標は混乱を招きます。まず信頼できる4つに集中しましょう:
- 着信量(チャネル・優先度別)
- バックログとバックログ年齢
- 初回応答時間(FRT)(中央値と90パーセンタイル)
- 解決時間(中央値と90パーセンタイル)
これらで需要の増減、停滞箇所、サービスレベルのリスクがわかります。
需要とキャパシティをどうやって実行可能なスタッフ数に変換するか?
説明可能なシンプルなモデルを使います:
- 需要(Demand): 移動平均や曜日・時間帯パターンでボリュームを予測
- キャパシティ(Capacity): スケジュールされたエージェント × 実働時間/人 × 生産性
- 縮減(Shrinkage): 休憩、PTO、研修、ミーティングを設定で調整
結果は「14時〜18時に+2人が必要」のような運用可能な指示にします。入力と仮定を必ず表示して透明性を保ってください。
サポートボリュームの予測に機械学習は必要か?
初期段階では高度なMLは不要です。効果的な手法:
- 7日/28日の移動平均(反応速い線と安定した線)
- 曜日・時間帯の季節性(典型的な月曜、金曜、時間ブロック)
- イベントマーカー(ローンチや障害、祝日などの外れ値を除外)
常に使用した手法と入力を結果のそばに表示し、仮定を検証しやすくしてください。
最初のバージョンでUIに含めるべきダッシュボードとフィルタは?
最初は次の3画面を中心に設計します:
- Overview(概観): 今日/今週のバックログ、流入、解決、リスク
- Team/queue drill-down(チーム診断): バックログを生んでいる要因(チャネル/優先度)
- Staffing planner(スタッフプランナー): 需要対キャパシティのギャップ表示
フィルタは日付、チーム/キュー、チャネル、優先度をスティッキーにし、ラベルと単位は明確にしましょう。
役割、権限、承認フローはどう設計すべきか?
最小権限で始め、編集範囲を明確にします:
- 管理者(Admin): コネクタ設定、マッピング、グローバル設定、ユーザー管理
- マネージャー(Manager): プランニングビュー、仮定の提案/承認
- エージェント(Agent): 個人のキューメトリクスやチームカバレッジ(他者の個人指標は非表示)
インポートされた事実(チケットのタイムスタンプ等)は直接編集不可にし、変更は監査ログと承認ワークフローで追跡します。