2025年5月07日·1 分
データベースのシャーディングの仕組み — 理解が難しい理由
シャーディングはデータを複数ノードに分割してデータベースをスケールさせる手法だが、ルーティング、リバランス、シャード間の失敗モードを生み、システムを理解しにくくする。
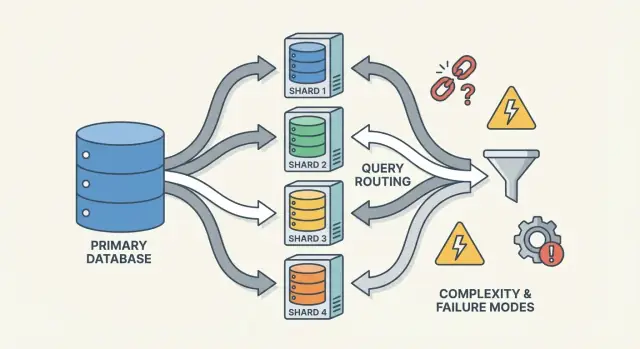
シャーディングはデータを複数ノードに分割してデータベースをスケールさせる手法だが、ルーティング、リバランス、シャード間の失敗モードを生み、システムを理解しにくくする。
シャーディング(別名 水平分割)とは、アプリケーションから見ると「1つの」データベースに見えるもののデータを、複数のマシン(シャードと呼ぶ)に分割することです。各シャードは行の一部だけを保持しますが、全体としては完全なデータセットを表します。
役立つ考え方は、論理構造と物理配置の違いです。
アプリからは1つのテーブルのようにクエリを実行したいですが、内部ではシステムがどのシャードに話すべきかを決める必要があります。
シャーディングはレプリケーションとは異なります。レプリケーションは同じデータのコピーを複数のノードに作り、主に高可用性や読み取りスケールのために使います。シャーディングはデータを分割し、各ノードが異なるレコードを保持します。
また、垂直スケーリング(単一データベースをより大きなマシンに移す)とも異なります。垂直スケールは単純な場合が多いですが、実際には限界がありコストが急増します。
シャーディングは容量を増やしますが、すべてのクエリが速くなるわけではありません。以下の点は残ります:
したがってシャーディングは ストレージとスループットをスケールする手段 として理解するのが正しく、すべての挙動を自動的に良くする魔法ではありません。
シャーディングはほとんどの場合最初の選択肢ではありません。多くのチームはシステムが成功して物理的限界に達したり、運用上の痛みが頻発するようになったときに選びます。動機は「シャーディングしたい」ではなく「1つのデータベースが単一障害点やコストの原因になって成長を阻害している」からです。
単一ノードが容量不足になるパターンはいくつかあります:
これらが頻発する場合、多くは単一の悪いクエリが原因というより「一台の機械が過度な責任を負っている」ことが原因です。
データベースのシャーディングはデータとトラフィックを複数ノードに分散させ、能力をマシン追加で拡張できるようにします。うまくやれば ワークロードの分離(あるテナントの負荷が他のレイテンシを壊さない)や、超大型インスタンスを避けてコストを管理することも可能です。
繰り返し現れるパターン:ピーク時のp95/p99が定常的に上昇する、レプリケーションラグが長くなる、バックアップ/リストアが許容ウィンドウを超える、ちょっとしたスキーマ変更が大仕事になる等。
決断前にチームは通常、インデックスやクエリ改善、キャッシュ、リードレプリカ、単一DB内のパーティショニング、古いデータのアーカイブ、ハードウェアアップグレードといったより簡単な対策を使い尽くします。シャーディングはスケール問題を解けますが、協調や運用の複雑性、新しい障害モードを追加するためハードルは高くなるべきです。
シャード化されたデータベースは単独のものではなく、協調する小さなシステム群です。シャーディングが「理解しにくい」と感じられる理由は、正しさと性能が単一のDBエンジンではなくこれらの部品の相互作用に依存するためです。
シャードはデータのサブセットで、通常はそのサーバやクラスター上に保存されます。各シャードは通常:
アプリから見るとシャード化構成は1つの論理データベースに見せようとしますが、単一ノードの「インデックス検索1回」が「正しいシャードを見つけてからの検索1回」に置き換わる点に注意が必要です。
ルーター(コーディネータ、クエリルータ、プロキシとも呼ぶ)は交通整理役で、与えられたリクエストをどのシャードが処理するべきか答えます。
一般的なパターンは2つ:
ルーターはアプリ側の複雑さを減らしますが、適切に設計しないとボトルネックや新たな障害点になり得ます。
シャーディングは次のようなメタデータに依存します:
この情報は設定サービス(小さなコントロールプレーンDB)に置かれることが多く、メタデータが古いか不整合だと、シャード自体が健康でもルーターが誤った場所へ送ってしまいます。
シャーディングは時間経過で使いやすさを保つためにバックグラウンド処理に依存します:
これらは初期には無視されがちですが、稼働中にシステムの形を変える点で多くの本番トラブルの原因になります。
シャードキーは行をどのシャードに置くか決めるフィールド(または組み合わせ)で、この一択が性能、コスト、将来の機能性に大きく影響します。シャードキーはリクエストが1つのシャードに行くか多数にファンアウトするかを制御します。
良いキーは概ね:
user_id)例:マルチテナントアプリで tenant_id をキーにすることでテナント内の読み書きが一つのシャードに収まりやすく、テナント数が多ければ負荷も分散します。
問題を招くキーの例:
低カードinalityキーはフィルタには便利でも、ルーティング不能なクエリを多数のシャードにファンアウトさせる原因になりがちです。
ロードバランスに有利なシャードキーが必ずしもプロダクト側のクエリにとって最良とは限りません。
user_id に最適化すると多くのレイテンシに敏感な操作が単一シャードに収まるが、グローバルなレポーティングは遅くなるか別系統が必要になる。region に最適化するとレポートは楽になるが、ホットスポットや不均等な容量配分のリスクが高まる。多くのチームは主要でレイテンシに敏感な操作に合わせてシャードキーを決め、他はインデックス、デノーマライズ、レプリカ、専用の分析テーブルで補います。
最良の方法は一つではありません。選択肢はルーティングの容易さ、データの均等分散、アクセスパターンの弱点を形作ります。
レンジシャーディングでは各シャードがキー空間の連続区間を所有します(例:
ルーティングは単純ですがホットスポットの問題があります。新しいユーザーに増分IDを割り当てる場合、最新のシャードが書き込みのボトルネックになります。範囲クエリ(例:10月1日〜10月31日の注文)は物理的にまとまっているため効率的に処理できるのが利点です。
ハッシュシャーディングはシャードキーをハッシュ関数に通し、その結果でシャードを選びます。これによりデータがより均等に分散され、「最新シャードにすべてが行く」問題を避けやすくなります。
代償として範囲クエリが困難になります。ID X〜Y のようなクエリは少数のシャードに絞れず、多数に触れる可能性があります。
現実的な実装では一貫ハッシュを使い、シャード数が増えても全キーが大きく再配置されないように仮想ノードを配置することが一般的です。
ディレクトリシャーディングはキー→シャードの明示的マッピングを保持します。柔軟性が高く、特定テナントを専用シャードに置く、個別に移動する、不均一なシャードサイズを許容するといった運用が可能です。
欠点は依存先が増えることです。ディレクトリが遅い、陳腐化、または利用不能になるとルーティングが破綻します。
実際のシステムは戦略を混ぜます。複合シャードキー(例:tenant_id + user_id)はテナントを分離しつつテナント内の負荷を分散できます。サブシャーディングは類似のアプローチで、まずテナントでルートし、その内部をハッシュして大きなテナントが1つのシャードを独占しないようにします。
シャード化されたデータベースには非常に異なる二つの「クエリ経路」があります。どちらの経路になるかを理解すれば、パフォーマンスの驚きの多くが説明できます。
理想はクエリが正確に1つのシャードにルーティングされることです。リクエストにシャードキーが含まれているか、ルーターがマッピングできればシステムは直接正しいシャードに送れます。
そのためチームは一般的な読み取りを「シャードキーに気づかせる」ことに執着します。単一シャードだとネットワーク往復や協調が少なくなり、ロックや実行もシンプルです。
クエリが正確にルーティングできない場合(非シャードキーでフィルタしている等)、システムは多くのまたは全シャードにブロードキャストすることがあります。各シャードがローカルでクエリを実行し、ルーターが結果をマージ(ソート、重複除去、LIMIT適用、部分集計の合算)します。
このファンアウトはテールレイテンシを増幅します:9個のシャードが速くても1つの遅いシャードが全体を遅らせる。ユーザーの1回のリクエストがN回のシャードリクエストになるので累積負荷も増えます。
シャード間ジョインは高コストです。通常は各シャードで部分計算をしてから集約する二相計画が必要になります。
多くのシステムはデフォルトでローカルインデックスを使います:各シャードが自身のデータだけをインデックスする。保守コストは低いがルーティングは助けません。
グローバルインデックスは非シャードキーでのターゲットルーティングを可能にしますが、書き込みオーバーヘッドや追加の一貫性問題を伴います。
書き込みはシャーディングが「ただのスケール手段」から設計を変える領域です。単一シャードで完結する書き込みは速く単純ですが、複数シャードに跨る書き込みは遅く失敗が起きやすく、正しく実装するのが難しくなります。
各リクエストが1つのシャードにルーティングされる場合(通常はシャードキーを利用)、そのシャードの通常のトランザクション機構を使えます。原子性と分離性はそのシャード内で保証され、運用上の課題は単一ノードのものと似た形になります。
2つ以上のシャードを1つの論理操作で更新する必要が出ると(例:送金、注文の所有者移動、別の場所にある集計の更新)、分散トランザクションの領域に入ります。分散トランザクションは遅延、ネットワーク分断、再起動などにより難しく、二相コミットのようなプロトコルは追加の往復を生み、タイムアウトでブロックしたり失敗時の状態が曖昧になりがちです。
シャーディング環境ではリトライは不可避です。書き込みを冪等にするために、安定した操作ID(冪等性キー等)を使い、既に適用されたマーカーをDBに保存しておくと、タイムアウト後の再試行が二重課金や重複注文を生まないようにできます。
シャーディング(水平分割)は、単一の論理データセットを複数のマシン(「シャード」)に分割し、それぞれが別の行を保持する設計です。
対照的に、レプリケーションは同じデータのコピーを複数のノードに保持し、可用性や読み取りスケールの向上を主な目的としています。
垂直スケーリングは単一のデータベースサーバーをより強力なマシンに移すことです。運用は単純になりがちですが、物理的な限界やコストの問題が早晩出てきます。
シャーディングはマシンを増やしてスケールアウトするアプローチですが、その代わりにルーティング、リバランシング、シャード間の整合性などの課題が生じます。
チームがシャーディングを選ぶのは、単一ノードが再発的にボトルネックになったときです。例えば:
シャーディングはデータとトラフィックを分散させ、ノードを追加することで容量を増やします。
典型的なシャーディングシステムは次を含みます:
これらの要素が一貫して動かないと、パフォーマンスや正しさが損なわれます。
シャードキーは、どのフィールド(またはフィールドの組み合わせ)で行をどのシャードに置くかを決めるものです。これが、リクエストが単一シャードに到達するか多数にファンアウトするかを決め、将来のパフォーマンスやコストに大きく影響します。
良いシャードキーの特徴:
user_id)例えばマルチテナントでは でシャードすることがよくあり、ほとんどの操作が同じシャード内で完結します。
「悪い」シャードキーの例とその弊害:
これらはルーティングが曖昧になり、ルックアップが散らばる(scatter-gather)原因になります。
代表的なシャーディング戦略:
実運用では複合キー(例:)やサブシャーディング(まずテナントでルーティングし、その内部をハッシュする)といった混合戦略を使うことが多い。
シャード化後のクエリには大きく二通りのパスがあります:
クロスシャードの結合や集約は二段階計算(各シャードで部分集計→マージ)が必要になり、コストが高くなります。ローカルインデックスは各シャード内で有効だが、ルーティングを助けない点に注意。グローバルインデックスはルーティングを改善できるが、書き込み負荷や一貫性の問題が増える。
書き込みはシャーディングの苦労が最も顕著に出る領域です。
回避パターン:
シャーディングはデータを分割しても冗長性は必要です。各シャード内でのレプリケーションは、ノード障害時の可用性を保ちますが、「今の正しい状態は何か?」を判断するのが難しくなります。
グローバルな制約(ユニーク性、外部キー、グローバルカウンタ)は難題です。例えば全体で一意にするには集中インデックスや専用の制約シャード、アプリ側の予約ワークフローが必要になることがあります。これらの選択は製品上の「正しさ」の定義に直結します。
リバランシングはシステムを使いやすく保つために不可欠です。データ成長やスキュー、ノード追加や廃棄に伴ってデータの場所を変える必要が出ますが、これはルーティングの変更を伴うため難易度が高い作業です。
よく使われるオンライン移行パターン(コピー→オーバーラップ→カットオーバー):
シャーディングは「均等分割」を前提とするが、実運用では見かけ上均等でも劇的に不均衡に振る舞うことがあります。
検出方法:シャードごとのダッシュボード(p95 レイテンシ、QPS、ストレージ使用量等)を素早く確認する。あるシャードのレイテンシだけが上がっていればホットスポットの兆候です。
緩和策:トラフィック分散を優先するシャードキー選定、ホットキーへのバッキング/ソルト(bucketing/salting)、ホットアイテムのキャッシュ、テナントレベルのレート制限、ホットシャードの分割・移動などがあります。
シャーディングはサーバーの数を増やすだけでなく、故障の種類と調査対象を増やします。多くのインシデントは「データベースが落ちた」ではなく「あるシャードだけ使えない」「どこにデータがあるか合意が取れていない」といった形で現れます。
よくある障害モード:
シャーディングは便利なスケーリング手段ですが、恒久的にシステムの複雑さを増すため、可能なら避けるべきです。シャード化前にまず試す価値のある選択肢:
シャーディングを安全に進めるには、ルーティングや冪等性、移行ワークフロー、観測性といった“配管”を本格導入前にプロトタイプするのが有効です。
tenant_idtenant_id + user_idまた、シャーディング環境ではリトライが不可避なので、書き込みを**冪等(idempotent)**にすることが重要です。操作IDや冪等キーを使い、既に適用済みマーカーを保存することで、再送による二重適用を防げます。
クライアントがルーティング結果をキャッシュしていると破壊的になるため、ルーティングメタデータはバージョン管理し、頻繁にリフレッシュするよう設計する必要があります。運用上は追加負荷やキャッシュチェンジによる一時的な性能低下、ロールバック計画、観測性の確保が重要です。
デバッグ手法の違い:リクエスト追跡のために相関IDを導入し、API層からルーター、シャードまで伝搬させる。分散トレーシングでどのシャードが遅いかを可視化し、メトリクスは必ずシャード単位で分解する。
データ整合性の事故例:リトライによる重複、データ移動後にルーティングが古い場所を指し続けたため行が見つからない、メタデータのスプリットブレインで二つのビューが同じキーを書き受ける等。
バックアップ/リストアとDRは「多くのパーツを正しい順序で戻す」作業になります。メタデータを先に復元し、各シャードを復元してシャード境界とルーティングが復元ポイントに一致していることを検証するリハーサルが必要です。
例:Koder.ai のようなツールを使えば、チャットから小さな現実的サービス(管理UI+バックエンド+PostgreSQLなど)を素早く立ち上げ、シャードキーに依存するAPIや冪等キー、カットオーバー挙動をサンドボックスで試せます。スナップショットやロールバック、ソースコードエクスポートがあると、設計上の判断を本番スタックに持ち込む前に検証できます。
シャーディングが適するのは、単一ノードの限界を明確に超え、かつ重要なクエリの大半がシャードキーでルーティングできる場合です。一方でアドホックなクエリや頻繁なマルチエンティティトランザクション、グローバル一意制約が多い製品では不向きです。
短いチェックリスト:
最後に、シャーディングを先延ばしにしても移行経路を設計しておくこと(将来のシャードキーをブロックしない識別子の選択、単一ノード前提をハードコーディングしないこと、最小ダウンタイムの移行手順のリハーサル)が重要です。