2025年4月29日·2 分
SLA順守を正確に追跡するウェブアプリの作り方
SLA準拠を追跡するウェブアプリの設計と構築方法:メトリクス定義、イベント収集、計算ロジック、違反時のアラート、監査可能なレポーティングまでを解説します。
SLA準拠を追跡するウェブアプリの設計と構築方法:メトリクス定義、イベント収集、計算ロジック、違反時のアラート、監査可能なレポーティングまでを解説します。
SLA準拠とは、サービスレベルアグリーメント(SLA)—プロバイダと顧客間の契約—に書かれた計測可能な約束を満たすことを意味します。あなたのアプリの仕事は、証拠とともに単純な問いに答えることです:この顧客について、この期間に私たちは約束を守ったか?
次の3つの関連用語を分けて考えると便利です:
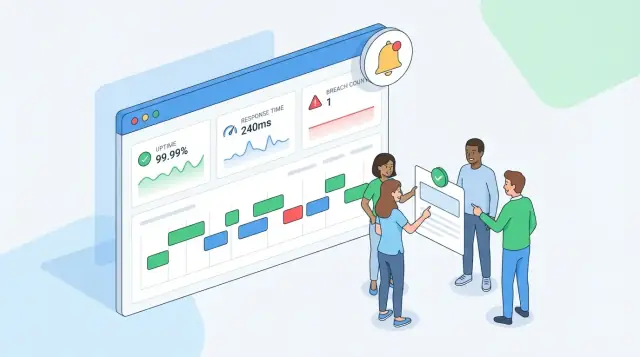
多くのSLAトラッキングウェブアプリは、小さなセットのメトリクスから始めます:
同じ“真実”を異なる形で見たいユーザーがいます:
このプロダクトは追跡、証明、報告が目的です:信号を収集し、合意されたルールを適用し、監査向けの結果を生成します。性能を保証するものではなく、正確で一貫性があり後で説明できる形で測定することが目的です。
テーブル設計やコードを書く前に、「準拠」があなたのビジネスで何を意味するかを痛いほど明確にしてください。多くのSLAトラッキングの問題は技術的ではなく、要件の問題です。
信頼できる情報源を集めます:
これらを明示的なルールとして書き出してください。ルールが明確に述べられないなら、信頼して計算できません。
SLA数値に影響する現実世界の「もの」を列挙します:
また誰が何を必要とするかも特定します:サポートはリアルタイムの違反リスクを、マネージャは週次の集計を、顧客はステータスページ向けの単純なサマリを求めることが多いです。
スコープを小さく保ちます。システムがエンドツーエンドで動くことを示す最小セットを選んでください。例:
後でテストできる1ページのチェックリストを作成します:
成功のイメージはこうです:2人が同じサンプル月を手動で計算し、あなたのアプリが完全に一致すること。
正しいSLAトラッカーは、数値が何故そうなっているか説明できるデータモデルから始まります。月間可用性を正確なイベントとルールに紐づけられないなら、顧客との紛争や内部の不確実性と戦うことになります。
最低限モデル化するもの:
有用な関係は:customer → service → SLA policy(plan経由も可)。IncidentやEventはserviceとcustomerを参照します。
時間のバグはSLA計算を誤らせる最大原因です。次を保存してください:
occurred_at を UTC(タイムゾーン意味付き)で保存received_at(システムがイベントを見た時刻)source(監視名、統合、手動)external_id(再試行をデデュープするため)payload(将来のデバッグ用に生JSON)また表示と営業時間ロジックのために customer.timezone(IANA形式、例:America/New_York)を保存しますが、イベント時間を書き換えないでください。
応答時間SLAが営業時間外で停止するなら、カレンダーを明示的にモデル化します:
working_hours を顧客(または地域/サービス)ごとに(日付毎の開始/終了)holiday_calendar を地域または顧客に紐づけ、日付範囲とラベルを持たせるルールをデータ駆動にして、オプスが祝日をデプロイなしで更新できるようにします。
生イベントは追加専用のテーブルに保存し、計算結果は別に保存(例:sla_period_result)します。各結果行には期間境界、入力バージョン(ポリシー版 + エンジン版)、使用したイベントIDの参照を含めるべきです。これにより再計算が安全になり、顧客から「どの障害分がカウントされたのか?」と聞かれても説明できます。
SLA数値は取り込んだイベントの信頼性次第です。目標は単純:カウントに関係するすべての変更(障害開始、インシデント承認、サービス復旧)を一貫したタイムスタンプと十分なコンテキストでキャプチャすることです。
多くのチームは複数のシステムから引っ張ってきます:
Webhookはリアルタイム精度と低負荷のため通常最適です:ソースがあなたのエンドポイントにイベントをプッシュします。
ポーリングはWebhookが使えない場合のフォールバック:アプリが定期的に前回以降の変更を取得します。レート制限と「since」ロジックに注意が必要です。
CSVインポートはバックフィルやマイグレーションに便利です。履歴の再処理が容易になるようにファーストクラスの取り込み経路として扱ってください。
上流のペイロードが違っても、内部では単一のイベント形に正規化します:
event_id(必須):再試行で安定する一意ID。ソースのGUIDを優先、なければ決定的ハッシュ生成source(必須):例 datadog, servicenow, manualevent_type(必須):例 incident_opened, incident_acknowledged, service_down, service_upoccurred_at(必須):発生時刻(発生時刻であり受信時刻ではない)、タイムゾーン付きreceived_at(システム):取り込んだ時刻service_id(必須):影響するSLA関連サービスincident_id(任意推奨):複数イベントを一つのインシデントにリンクattributes(任意):優先度、リージョン、顧客セグメントなどevent_id にユニーク制約を設け、取り込みを冪等にします:再試行しても重複が作られません。
以下のイベントは拒否または隔離してください:
occurred_at が将来過ぎるservice_id にマッピングできない(または明示的な“unmapped”ワークフローを要求)event_id と重複するこうした初期の規律があれば、後でSLAレポートを巡る議論を避けられます—いつでもクリーンでトレース可能な入力を示せるからです。
生イベントがSLA結果になり得るのは計算エンジン次第です。鍵は会計的に扱うこと:決定論的ルール、明確な入力、リプレイ可能なトレイルです。
すべてをインシデント(またはサービス影響)ごとの単一の順序付きストリームに変換します:
このタイムラインから区間を合算して期間を算出します。単純に2つのタイムスタンプを引くのは避けてください。
TTFRは incident_start と first_agent_response(または acknowledged)の間の“課金対象時間”として定義します。TTRは incident_start と resolved の間の“課金対象時間”です。
“課金対象”とは、次のような除外区間を取り除いたものを指します:
実装の詳細:カレンダ関数(営業時間、祝日)と、タイムラインを受け取って課金区間を返すルール関数を保存してください。
事前に次を決めておきます:
部分的な障害は、契約が影響度で加重することを要求する場合のみ加重し、そうでなければ“劣化”を別カテゴリの違反として扱ってください。
すべての計算は再現可能であるべきです。次を永続化してください:
ルール変更時に履歴を書き換えずにバージョンで再計算できることは、監査や顧客紛争で重要です。
レポーティングはSLAトラッキングが信頼を得るか疑念を招くかの分かれ目になります。アプリは何を測っているかの時間範囲、どの分がカウントされるか、最終数値がどう導出されたかを明確に示すべきです。
顧客が実際に使う一般的な報告期間をサポートします:
期間は明示的な start/end タイムスタンプとして保存し、後で計算を再生して説明できるようにしてください。
議論の元になりやすいのは分母を「期間全体」か「対象時間」かで扱うかです。
各期間に対して2つの値を定義します:
そして計算します:
availability_percent = 100 * (eligible_minutes - downtime_minutes) / eligible_minutes
eligible がゼロになる可能性がある場合(例えば、期間に監視対象の営業時間がまったく含まれないサービス)、事前にルールを決めてください:「N/A」か「100%」扱いにするなど。一貫して文書化してください。
多くのSLAは割合と二値の結果の両方を必要とします。
また「違反までの残り余地(残りのダウンタイム予算)」を保持すると、閾値を超える前にダッシュボードで警告できます。
最後に、原始入力(含めた/除外したイベントや調整)を保持して、各レポートが「なぜその数になったか」を手でごまかさず説明できるようにします。
計算エンジンが完璧でも、UIが基本的な問い「今すぐSLAを満たしているか、なぜ?」に答えられなければユーザーは失望します。各画面はまず明確なステータスを示し、そこから数値とそれを生んだ生イベントへドリルダウンできるように設計してください。
概要ダッシュボード(オペレーションとマネージャ向け)。 小さなタイルで現在の期間のコンプライアンス、可用性、応答時間コンプライアンス、「違反までの残り時間」を先頭に表示します。ラベルは明示的に(例:「Availability (this month)」ではなく「今月の可用性」)複数SLAをサポートする場合は最悪のステータスを先に表示し展開させると良いです。
顧客詳細(アカウントチームと顧客向け報告)。 顧客ページはその顧客のすべてのサービスとSLAティアを要約し、合格/警告/不合格のシンプルな状態と短い説明(例:「2件のインシデントがカウントされ、18分のダウンタイムが計上」)を表示します。/status(顧客向けステータスページ)へのリンクやレポートエクスポートへのリンクを追加します。
サービス詳細(深掘り調査用)。 ここでは適用されたSLAルール、計算ウィンドウ、コンプライアンス数がどのように形成されたかの内訳を表示します。可用性の時系列チャートとカウントされたインシデント一覧を含めます。
インシデントタイムライン(監査用)。 単一インシデントビューはイベントのタイムライン(検知、承認、緩和、解決)と、どのタイムスタンプが応答・解決メトリクスに使われたかを示します。
すべての画面でフィルタを一貫させます:日付範囲、顧客、サービス、ティア、重大度。単位も統一(分 vs 秒、同じ小数桁の割合)し、日付範囲を変えるとページ内の全メトリクスを更新して不整合を防ぎます。
要約メトリクスはすべて「なぜ?」パスを持たせます:
ツールチップは用語定義(「除外ダウンタイム」や「営業時間」など)に節度を持って使い、サービスページに適用ルールの正確な文言を表示してユーザーの推測を減らしてください。
略語より平易な表現を優先します(「Response time」ではなく「応答時間」)。ステータス表示では色とテキストラベルを組み合わせ(例:「危険:エラーバジェットの92%を消費」)て曖昧さを排除します。SLAルールや除外の変更履歴が見られる /audit への小さな「最終変更」ボックスを置くと監査性が高まります。
アラートはSLAトラッキングを受動的なレポートから、チームが罰則を回避するために動けるツールに変えます。最良のアラートはタイムリーで具体的、かつ実行可能です—単に「悪い」と伝えるのではなく「次に何をすべきか」を示します。
まず次の3種類のトリガーから始めます:
トリガーは顧客/サービス/各SLAごとに設定可能にして、契約ごとの許容度差に対応してください。
実際に対応する場所へアラートを送ります:
各アラートに /alerts, /customers/{id}, /services/{id}、インシデントやイベント詳細へのディープリンクを含め、対応者が迅速に数値を検証できるようにします。
重複抑止を実装して、同じキー(customer + service + SLA + period)のアラートをグルーピングし、クールダウン中は繰り返しを抑えます。
静穏時間(チームのタイムゾーンごと)を設定して、重要度が低い差し迫った違反アラートは営業時間まで遅らせ、重大度が高ければ静穏時間をオーバーライドするようにします。
最後にエスカレーションルール(例:10分でオンコールに通知、30分でマネージャへエスカレーション)をサポートして、アラートが一つの受信箱で滞留しないようにします。
SLAデータは内部のパフォーマンスや顧客固有の権利を露呈するため機微です。アクセス制御はSLAの「算出」に直結します:同じインシデントでも適用するSLA次第で結果が変わり得ます。
まずはロールを単純にして、徐々に粒度を細かくします。
実務的なデフォルトは RBAC + テナントスコーピング です:
顧客固有データについて明確にします:
まずは メール/パスワード を開始し、内部ロールにはMFAを必須にします。後で SSO(SAML/OIDC) を導入するために、アイデンティティ(誰か)と認可(何にアクセスできるか)を分離して設計してください。統合用にはスコープの狭いサービスアカウントAPIキーを発行し、ローテーションをサポートします。
次の変更について不変の監査エントリを追加します:
保存する情報は「誰が」「何を変えたか(前/後)」「いつ」「どこで(IP/ユーザーエージェント)」「相関ID」です。監査ログは検索可能かつエクスポート可能にしておく(例:/settings/audit-log)。
SLAトラッキングアプリは孤立して動くことは稀です。監視ツール、チケッティングシステム、内部ワークフローがインシデントを作成し、イベントをプッシュし、レポートを取得できるAPIが必要です。
バージョン付きベースパス(例:/api/v1/...)を使い、ペイロードを進化させても既存統合を壊さないようにします。
主要なエンドポイント:
POST /api/v1/events(状態変化取り込み)、GET /api/v1/events(監査・デバッグ)POST /api/v1/incidents, PATCH /api/v1/incidents/{id}(承認、解決、割当て), GET /api/v1/incidentsGET /api/v1/slas, POST /api/v1/slas, PUT /api/v1/slas/{id}(契約と閾値管理)GET /api/v1/reports/sla?service_id=...&from=...&to=...(コンプライアンスサマリ)POST /api/v1/alerts/subscriptions(Webhook/Emailターゲット管理)、GET /api/v1/alerts(アラート履歴)1つの慣例を選び全てに適用します。例:limit と cursor ページネーション、標準フィルタ service_id, sla_id, status, from, to。ソートは予測可能に(例:sort=-created_at)。
構造化されたエラーを返し、安定したフィールドを持たせます:
{ "error": { "code": "VALIDATION_ERROR", "message": "service_id is required", "fields": { "service_id": "missing" } } }
HTTPステータスは明確に(400 バリデーション、401/403 認証、404 未発見、409 競合、429 レート制限)。イベント取り込みでは冪等性(Idempotency-Key)を考慮して再試行でインシデントが重複しないようにします。
トークンごとに適切なレート制限を適用(取り込みエンドポイントはより厳しく)。入力をサニタイズし、タイムスタンプ/タイムゾーンを検証します。読み取り専用と書き込み権限でスコープされたAPIトークンを推奨し、誰がどのエンドポイントを呼んだかログに残しておきます(監査ログ節を参照、/blog/audit-logs)。
SLA数値は信頼されなければ意味がありません。SLAトラッキングアプリのテストは「ページが読み込むか」よりも「契約通りに時間計算が正確か」を重視すべきです。計算ルールを製品機能としてテストスイート化してください。
計算エンジンを決定論的な入力でユニットテストします:インシデントのタイムライン(opened, acknowledged, mitigated, resolved)と明確なSLAルールセットを与えます。
時間を固定(freeze time)してテストが時計に依存しないようにします。よく壊れるエッジケースをカバーしてください:
取り込み → 計算 → レポート生成 → UIレンダリング、というフローを通すE2Eテストを小セット用意します。これによりエンジンとダッシュボード間の不整合を検出できます。シナリオは少数だが価値の高いものに絞り、最終数値(可用性%、違反の有無、応答時間)をアサートします。
営業時間、祝日、タイムゾーンのテストフィクスチャを用意します。例:「現地金曜17:55にインシデントが発生」「祝日が応答時間カウントをずらす」などの再現可能なケースを作っておきます。
テストはデプロイで終わりません。ジョブ失敗、キュー/バックログのサイズ、再計算時間、エラー率を監視します。取り込みが遅延したり夜間ジョブが失敗すると、コードが正しくてもレポートが間違うので監視が重要です。
SLAトラッキングアプリを出すのは派手なインフラよりも運用の確実性が重要です:計算は期日通り実行され、データは安全で、レポートは再現可能であること。
まずはマネージドサービスを使って正確性に集中します。
環境は最小化:dev → staging → prod、それぞれ別DBとシークレットで。
SLAトラッキングは同期処理だけでなく定期処理に依存します。
ワーカプロセス+キューかマネージドスケジューラで運用し、ジョブは冪等にして再試行が安全であることを保証し、各実行をログに残してください。
データ種別ごとに保持方針を定め、導出結果は生イベントより長く保持します。エクスポートはまず CSV を提供し(透明で高速)、後でPDFテンプレートを追加。エクスポートは「最善努力のフォーマット」であり、データベースが真のソースであることを明確にしてください。
データモデル、取り込みフロー、レポーティングUIを素早く検証したいなら、Koder.ai のようなバイブコーディングプラットフォームが助けになります。チャット経由でフルアプリ(Web UI + バックエンド)を生成でき、以下を短期間で試せます:
要件と計算が検証できたら(ここが一番難しい)、ソースをエクスポートして通常のビルド&運用ワークフローへ移行し、スナップショットやロールバックといった機能を活用しながら反復できます。
SLAトラッカーは一つの質問に証拠つきで答えます:特定の顧客と期間に対して契約上のコミットメントを満たしたか?
実務上は、監視・チケット・手動更新といった生データを取り込み、顧客のルール(営業時間、除外事項)を適用し、監査対応可能な合否結果と補助的な詳細を出力することを意味します。
次のように使い分けます:
これらを個別にモデル化することで、可用性改善のためのSLO変更が誤って契約報告(SLA)に影響を与えるのを防げます。
MVPでは通常1〜3のメトリクスをエンドツーエンドで追うのがよいです:
これらは実データソースにマップしやすく、期間・カレンダー・除外といった難所を早期に実装させます。
要件の失敗は未定義のルールから来ます。次を収集して文書化してください:
ルールが明確に表現できなければ、コードで推測しないで明確化を求めてください。
信頼できるSLAトラッカーの最小データモデルは、冗長でなく明示的なエンティティから始めます:
目標はトレース可能性です:報告された数値は特定のevent IDとポリシーのバージョンに紐づくべきです。
時刻は一貫して正しく保存してください:
occurred_at はUTCで(タイムゾーン情報付き)保存received_at を保存(いつ取り込んだか)また期間は明示的な start/end タイムスタンプで保存し、DST の変化を含めて再現できるようにします。
重複や不正データでレポートを壊さないために、すべてを単一の内部イベント形に正規化します:
event_id(一意でリトライ時に安定)source, event_type, occurred_at, service_id計算はタイムライン上の区間を合算して行います。2つのタイムスタンプを単純に引くのではなく、計上すべき区間だけを合計してください。
計上対象から取り除くべきものの例:
導出された区間と理由コードを永続化して、何がカウントされたか説明できるようにします。
分母を明示的に2つ扱ってください:
そして計算します:
availability_percent = 100 * (eligible_minutes - downtime_minutes) / eligible_minutes
eligible がゼロになるケース(例:期間内に営業時間がない)については事前にルールを決め、整合的に適用・文書化してください(例:N/A または 100%)。
UIで瞬時に「SLAを満たしているか、になぜそうなっているか」を答えられるようにします:
アラートは「差し迫った違反」「違反発生」「繰り返し違反」等、行動につながるトリガーを優先し、該当の /customers/{id} や /services/{id} などへのディープリンクを含めてください。
incident_id と attributesevent_id にユニーク制約を入れて冪等性を担保し、マッピング不能や時系列順序外のイベントは隔離/フラグ立てする(自動修正はしない)ことでデータの清潔性を保ちます。