2025年6月23日·1 分
Snowflakeのストレージとコンピュートの分離:性能とエコシステム
Snowflakeがストレージとコンピュートを切り離す考えを普及させた仕組み、スケーリングやコストのトレードオフをどう変えたか、そして単純な速度以上にエコシステムが重要な理由を解説します。
Snowflakeがストレージとコンピュートを切り離す考えを普及させた仕組み、スケーリングやコストのトレードオフをどう変えたか、そして単純な速度以上にエコシステムが重要な理由を解説します。
Snowflakeはクラウドデータウェアハウジングにおいて、単純だが影響の大きい考えを広めました:データの保存(ストレージ)とクエリ実行(コンピュート)を分離することです。この分離はデータチームの日常的な課題──ウェアハウスのスケーリング方法とコストの払い方──を変えます。
かつてはウェアハウスを一つの固定された「箱」のように扱い、ユーザー増加やデータ量増、複雑なクエリが同じリソースを奪い合っていました。Snowflakeのモデルではデータを一度保存し、必要なときに適切な量のコンピュートを立ち上げられます。その結果、回答までの時間が短くなり、ピーク時のボトルネックが減り、どのコストがいつ発生するかをより明確に管理できます。
この投稿では、ストレージとコンピュートを分離することが本質的に何を意味するのか、そしてそれが次にどう影響するのかを平易に説明します:
また、このモデルがすべての問題を魔法のように解決するわけではない点も指摘します。コストや性能の意外な問題は、プラットフォーム自体ではなくワークロードの設計に起因することが多いからです。
高速なプラットフォームだけでは全てが解決するわけではありません。多くのチームにとって、価値実現の速度は既存ツール(ETL/ELTパイプライン、BIダッシュボード、カタログ/ガバナンスツール、セキュリティ制御、パートナーデータソース)へどれだけ簡単に接続できるかに依存します。
Snowflakeのエコシステム(データ共有パターンやマーケットプレイス風の配布を含む)は、導入期間を短縮しカスタムエンジニアリングを減らせます。本稿では「エコシステムの深さ」が実務でどう見えるか、組織でどう評価すべきかを扱います。
このガイドはデータリーダー、アナリスト、非専門の意思決定者向けに書かれています。ベンダージャーゴンに埋もれず、Snowflakeのアーキテクチャ、スケーリング、コスト、統合のトレードオフを理解する必要がある人に向けたものです。
従来のデータウェアハウスは単純な前提で作られていました:固定量のハードウェアを購入(またはレンタル)し、その同じ箱やクラスタ上で全てを実行する、というものです。ワークロードが予測可能で成長が緩やかな間はうまく機能しましたが、データ量やユーザー数が加速すると構造的な制約が現れます。
オンプレ環境(や初期のクラウドのリフト&シフト展開)は通常こんな形でした:
ベンダーが「ノード」を提供しても、コアパターンは同じままでした:スケールとは通常、より大きいまたはより多くのノードを一つの共有環境に追加することを意味していました。
この設計はいくつかの共通の悩みを生みます:
これらのウェアハウスは環境に密に結びついていたため、統合はしばしば有機的に増えていきました:カスタムETLスクリプト、手作りコネクタ、ワンオフのパイプライン。機能はしても、スキーマが変わったり上流システムが移動したり新しいツールが導入されると壊れやすく、すべてを維持する作業が絶え間ない保守のように感じられがちでした。
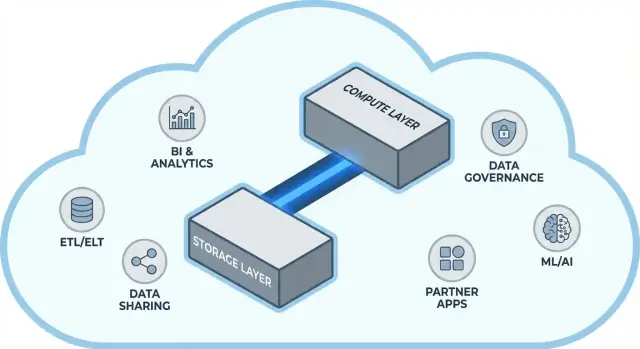
従来のデータウェアハウスでは、本来別の役割を持つ二つの仕事が結びついていることが多かった:ストレージ(データが置かれる場所)とコンピュート(そのデータを読み、結合し、集約し、書き戻す処理能力)です。
ストレージは長期保存用のパントリーのようなものです:テーブル、ファイル、メタデータが安全かつ安価に保管され、耐久性と常時アクセスを前提に設計されています。
コンピュートはキッチンスタッフのようなものです:CPUやメモリの集合で、実際にクエリを「調理」します。SQLを実行し、ソートし、スキャンし、結果を組み立て、多数のユーザーを同時に扱います。
Snowflakeはこれらを切り離し、片方を変えるともう片方まで強制的に変わることがないようにしています。
実務的には、これにより日々の運用が変わります:ストレージ増加を理由にコンピュートを過剰購入する必要がなくなり、分析者とETLのようなワークロードを分離して互いに遅くし合わないようにできます。
この分離は強力ですが万能ではありません。
価値は「制御」にあります:ストレージとコンピュートをそれぞれの性質に合わせて支払うことで、チームが実際に必要とするものに合わせられる点です。
Snowflakeは三つのレイヤーが連携する形で理解するのがわかりやすく、それぞれ独立してスケールできます。
テーブルは最終的にクラウドプロバイダのオブジェクトストレージ(S3、Azure Blob、GCSなど)のデータファイルとして存在します。Snowflakeはファイル形式、圧縮、組織化を管理します。ディスクをアタッチしたりストレージボリュームをサイズする必要はなく、データに応じてストレージは拡張します。
コンピュートは仮想ウェアハウスとしてパッケージ化されます:クエリを実行する独立したCPU/メモリのクラスタです。同じデータに対して複数のウェアハウスを同時に動かすことができます。これが、重いワークロードが同じリソースを争う古いシステムとの決定的な違いです。
別のサービス層がシステムの「頭脳」を担います:認証、クエリのパースと最適化、トランザクション/メタデータ管理、調整です。この層がクエリをどのように効率的に実行するかを決めてからコンピュートに渡します。
SQLを送信すると、Snowflakeのサービス層が解析し実行計画を組み、選ばれた仮想ウェアハウスに計画を渡します。ウェアハウスは必要なデータファイルだけをオブジェクトストレージから読み(可能な限りキャッシュの恩恵を受け)、処理して結果を返します——基データを恒久的にウェアハウスに移動するわけではありません。
多くの人が同時にクエリを実行する場合、次のどちらかができます:
これがSnowflakeの性能と「騒がしい隣人」対策の建築的基盤です。
Snowflakeの大きな実務的変化は、コンピュートをデータから独立してスケールできることです。「ウェアハウスが大きくなる」代わりに、各ワークロードごとにリソースを上げ下げでき、テーブルを複製したりディスクを再パーティショニングしたりダウンタイムをスケジュールする必要がなくなります。
Snowflakeでは仮想ウェアハウスがクエリを実行するエンジンです。秒単位でリサイズ(例:SmallからLargeへ)でき、データは共有ストレージに残ります。これにより、パフォーマンス調整はしばしば「このワークロードは今もっと処理能力が必要か?」という単純な問いになります。
これにより一時的なバーストも可能になります:月末の締めにスケールアップし、スパイクが終われば戻す、といった運用が行えます。
従来のシステムでは異なるチームが同じコンピュートを共有することが多く、ピーク時間はレジの列のようになっていました。
Snowflakeではチームやワークロードごとに別のウェアハウスを動かせます(例:分析用、ダッシュボード用、ETL用)。同じ基データを読みながら、"あなたのダッシュボードが私のレポートを遅くした"という問題を減らし、性能をより予測可能にします。
エラスティックコンピュートが自動的に成功を約束するわけではありません。よくある落とし穴は:
総じて、スケーリングと同時実行はインフラの大掛かりなプロジェクトから日常的な運用判断へと変わります。
Snowflakeの「使った分だけ払う」は基本的に並行して動く二つのメーターです:
この分離こそが節約に繋がる可能性のある部分です:データを多く保存していても比較的安価に保ち、コンピュートは必要なときにだけオンにできます。
多くの“予期せぬ”支出はストレージではなくコンピュートの振る舞いに由来します。一般的なドライバは:
ストレージとコンピュートを分離しても、悪いSQLはクレジットを急速に消費します。
財務部門を動員する必要はありません——いくつかのガードレールで十分です:
適切に使えば、このモデルは短時間で適切にサイズされたコンピュートと予測可能なストレージ増加を組み合わせた運用を報います。
Snowflakeは共有を単なる後付けの仕組みではなくプラットフォーム設計の一部として扱います。エクスポート、ファイルドロップ、ワンオフのETLに頼る代わりに、共有を設計に組み込むことで多くの利点があります。
抽出物をあちこちに送る代わりに、Snowflakeでは安全な「シェア」を通して別アカウントが同じ基データをクエリできるようにできます。多くの場合、データを第二のウェアハウスに複製したり、ダウンロード用にオブジェクトストレージに書き出したりする必要はありません。コンシューマは共有されたデータベース/テーブルをローカルのように参照でき、提供者は何を公開するかを制御できます。
この非複製的なアプローチはデータスプロールを減らし、アクセスを速くし、構築・保守するパイプラインの数を抑えられる点で有用です。
パートナー/顧客共有: ベンダーがキュレートしたデータセット(利用状況分析やリファレンスデータなど)を顧客に公開でき、許可されたスキーマやテーブルだけを露出する。
内部ドメイン共有: 中央チームが認定済みデータセットをプロダクト、ファイナンス、オペレーションに公開し、各チームが独自にコピーを作らずに自分のコンピュートで処理できるようにする。これにより「一連の数字」を保ちつつ各チームの自律性を保てる。
ガバナンスされた共同作業: 代理店、サプライヤー、子会社との共同プロジェクトで機密列をマスクしアクセスをログしながら共有データで作業することが可能。
共有は「一度設定して放置」できるものではありません。必要な要素は:
高速なウェアハウスは価値がありますが、プロジェクトが期日までに完了するかどうかを決めるのは単に速度だけではありません。決定的なのはプラットフォームの周囲にあるエコシステムです:既成の接続、ツール、ナレッジがどれだけカスタム作業を減らせるかが重要です。
実務では、エコシステムには次が含まれます:
ベンチマークは統制された条件下の狭い性能指標しか測りません。実際のプロジェクトで時間を取るのは:
これらのステップに成熟した統合があれば、接着コードを書く必要を避けられます。結果として実装期間が短くなり、信頼性が上がり、チームやベンダーを切り替えても大きな手戻りが発生しにくくなります。
エコシステムを評価する際は次を確認してください:
性能は機能を与えますが、エコシステムはその機能をどれだけ早くビジネス成果に変えられるかを決めます。
Snowflakeは高速なクエリを実行できますが、真の価値が現れるのはデータがスタック全体を通じて信頼性を持って流れるときです:ソースからSnowflakeへ、そして日常的に使うツールへ戻る。この「ラストマイル」がプラットフォームを煩わしいものにするか、手間のかからないものにするかを決めます。
多くのチームは次の組み合わせを必要とします:
すべての「Snowflake対応」ツールが同じ動きをするわけではありません。評価時には実務的な点に注目してください:
統合はDay-2の準備が必要です:監視とアラート、ラインエージ/カタログ連携、そしてインシデント対応ワークフロー(チケッティング、オンコール、ランブック)。強いエコシステムとはロゴの数だけでなく、深夜にパイプラインが壊れたときの驚きが少ないことでもあります。
チームが大きくなると、解析の最も難しい部分は速度ではなく、正しい人が正しいデータに正しい目的でアクセスできることを確実にし、統制が機能している証跡を残すことになります。Snowflakeのガバナンス機能はその現実に合わせて設計されています:多数のユーザー、たくさんのデータプロダクト、頻繁な共有が前提です。
まずは明確なロールと最小権限の考え方から始めます。個人に直接アクセスを付与する代わりに、ANALYST_FINANCE や ETL_MARKETING といったロールを定義し、それらのロールに対して特定のデータベース/スキーマ/テーブル/必要に応じてビューへのアクセス権を与えます。
機密フィールド(PII、財務識別子など)にはマスキングポリシーを使い、そのロールが許可されている場合のみ生データを見られるようにします。これに監査を組み合わせて、誰がいつ何をクエリしたかを追跡し、セキュリティやコンプライアンスの問い合わせに答えられるようにします。
良いガバナンスはデータ共有を安全かつ拡張可能にします。共有モデルがロール、ポリシー、監査済みアクセスに基づいていると、セルフサービス(より多くのユーザーがデータを探索すること)を安心して解放できます。偶発的な露出を招くことなく利用者を増やせるのです。
また、コンプライアンス作業の摩擦も減ります:ポリシーは一回限りの例外ではなく再現可能なコントロールになります。これはデータセットが多プロジェクトや多部門、外部パートナーで再利用される場合に重要です。
PROD_FINANCE、DEV_MARKETING、SHARED_PARTNER_X)。一貫性はレビューを速くしミスを減らします。スケール時の信頼は一つの「完璧な」コントロールではなく、小さく確実な習慣のシステムによって実現されます。
Snowflakeは多くの人やツールが同じデータを異なる目的でクエリするときに強みを発揮します。コンピュートが独立したウェアハウスにパッケージされているため、それぞれのワークロードを適切な形とスケジュールにマッピングできます。
Analytics & dashboards: BIツール用に専用のウェアハウスを置き、安定した予測可能なクエリ量に合わせてサイズを決めます。これによりダッシュボードのリフレッシュがアドホック探索によって遅くなるのを防げます。
Ad hoc analysis: 分析者用に別のウェアハウス(通常は小さめ)を与え、auto-suspend を有効にします。反復は速く、アイドル時間に対する費用は抑えられます。
Data science & experimentation: より大きなスキャンや時折のバーストに耐えられるウェアハウスを使います。実験がスパイクしたら一時的にスケールアップしてもBI利用者に影響しません。
Data apps & embedded analytics: アプリのトラフィックは本番サービスとして扱い、別のウェアハウス、保守的なタイムアウト、リソースモニタで予期せぬ支出を防ぎます。
軽量な社内データアプリ(例:SnowflakeをクエリしてKPIを表示するオプス用ポータル)を作る場合は、React + API のスキャフォールドを生成してステークホルダーと反復するのが近道です。Koder.ai のようなプラットフォーム(チャットからウェブ/サーバ/モバイルアプリを生成するvibe-codingプラットフォーム)は、Snowflake対応アプリのプロトタイプを素早く作り、運用化の準備ができたらソースコードをエクスポートするのに役立ちます。
単純なルール:対象(オーディエンス)と目的ごとにウェアハウスを分離する(BI、ELT、アドホック、ML、アプリ)。これに良いクエリ習慣を合わせる:広範な SELECT * を避け、早い段階でフィルタをかけ、非効率な結合に注意する。モデリング面では、人々のクエリの仕方(しばしばセマンティックレイヤや定義済みのマート)が合う構造を優先し、物理レイアウトを過度に最適化しすぎないことが多くのケースで有効です。
Snowflakeは何にでも置き換えられるわけではありません。高スループットで低レイテンシなトランザクション(典型的なOLTP)には専用のデータベースの方が適しており、Snowflakeは分析、レポーティング、共有、下流のデータプロダクト用に使うのが一般的です。ハイブリッド構成はよく見られ、実務上最も実用的なことが多いです。
Snowflakeへの移行はめったに「リフト&シフト」ではありません。ストレージ/コンピュートの分離はワークロードのサイズ決め、チューニング、課金方法を変えるため、事前の計画が驚きを防ぎます。
まずインベントリを取ります:どのデータソースがウェアハウスにデータを供給しているか、どのパイプラインがそれを変換しているか、どのダッシュボードが依存しているか、各要素の所有者は誰かを把握します。次にビジネスインパクトと複雑さで優先順位を付けます(例:重要なファイナンス報告を先、実験用サンドボックスは後)。
次にSQLとETLロジックを変換します。標準的なSQLは多くが移行できますが、関数、日付処理、手続き的コード、一時テーブルのパターンなどの詳細は書き換えが必要なことが多いです。早期に結果を検証してください:並列出力を走らせて行数や集計を比較し、エッジケース(NULL、タイムゾーン、重複除去ロジック)を確認します。最後にカットオーバー計画を立てます:フリーズウィンドウ、ロールバックパス、各データセットとレポートの「完了定義」を明確にします。
隠れた依存関係が最も一般的です:スプレッドシートの抽出、ハードコーディングされた接続文字列、誰も覚えていない下流ジョブなど。古いチューニング前提が通用しないことで性能の驚きが起こります(例:極小ウェアハウスの過剰使用、多数の小クエリ実行で同時実行を考慮していないなど)。コストのスパイクはウェアハウスを動かしっぱなしにする、制御されていないリトライや重複した開発/テストワークロードから来ることが多いです。権限ギャップは粗いロールからより細かいガバナンスに移行するときに現れやすいので、「最小権限」ユーザーでのテストを含めるべきです。
所有権モデルを設定(データ、パイプライン、コストの責任者)、分析者とエンジニア向けのロールベースのトレーニングを実施し、カットオーバー後数週間のサポート計画(オンコール、インシデントランブック、問題報告の窓口)を定義してください。
現代のデータプラットフォームを選ぶ際はピーク時のベンチマーク速度だけでなく、実際のワークロード、チームの働き方、既存ツールとの適合性を考慮する必要があります。
次の問いでベンダー候補やショートリストを評価してください:
2〜3件の代表的なデータセットを選びます(大きなファクトテーブル、半構造化で雑なソース、業務に重要なドメイン)。
実際のユーザークエリを走らせます:朝のピークでのダッシュボード、分析者の探索、定期ロード、いくつかの最悪ケース結合など。測定項目は:クエリ時間、同時実行時の挙動、取り込みの時間、運用コスト、ワークロードごとのコストです。
もし「どのくらい早く人が実際に使えるものを出せるか」を評価に含めるなら、パイロットに小さな成果物(内部の指標アプリやガバナイズされたデータリクエストワークフロー)を追加することを検討してください。その薄いレイヤーを作ることで、ベンチマークだけでは見えない統合やセキュリティの現実が早く明らかになります。Koder.ai のようなツールはチャットでアプリ構造を生成し、プロトタイプから本番までのサイクルを速めるのに役立ちます。
費用見積りやオプション比較の支援が必要であれば /pricing から始めてください。
移行やガバナンスのガイダンスについては /blog をご覧ください。
Snowflakeはデータをクラウドのオブジェクトストレージに保存し、クエリは「仮想ウェアハウス」と呼ばれる独立したコンピュートクラスタで実行されます。ストレージとコンピュートが切り離されているため、基盤となるデータを移動・複製することなく、コンピュートを上下にスケールしたり、ウェアハウスを追加したりできます。
リソース競合を減らすことで実現します。異なるワークロードを別々の仮想ウェアハウスに割り当てる(例:BI と ETL)か、需要が急増した際にコンピュートを追加できるマルチクラスター機能を使うことで、従来のMPPでよく起きた「ひとつの共有クラスター」による待ち行列問題を回避できます。
自動的にコストが下がるわけではありません。エラスティックなコンピュートは「制御」を提供しますが、次のようなガードレールは必要です:
悪いSQL、頻繁なダッシュボード更新、常時稼働のウェアハウスは依然として高いコンピュート費用を生む可能性があります。
請求は大きく二つの要素で分かれます:
これにより、今まさにコストが発生しているもの(コンピュート)と、時間とともに安定して増えるもの(ストレージ)を区別しやすくなります。
驚きのコスト増の多くはデータサイズではなく運用に起因します。主な原因は:
自動停止、リソースモニタ、スケジューリングといった実用的な制御だけで大きな節約が得られることが多いです。
サスペンドされたウェアハウスが再起動するときの遅延を指します。利用頻度の低いジョブでは auto-suspend によってコストを節約できますが、アイドル直後の最初のクエリは若干のレイテンシを受け入れる必要があります。ユーザ向けのダッシュボードでは、頻繁なサスペンド/再開を避けるために安定した負荷向けの専用ウェアハウスを用意することを検討してください。
仮想ウェアハウスはSQLを実行する独立したコンピュートクラスタです。チームの使い方にマッピングするのがベストプラクティスです。例えば:
これにより性能を分離し、コストの帰属が明確になります。
多くの場合可能です。Snowflakeの共有機能を使えば、別アカウントがあなたが公開したテーブルやビューをクエリできるようにし、ファイルを書き出したり追加のパイプラインを構築したりする必要を減らせます。ただし、共有を安全に行うには明確な所有権、アクセスレビュー、機密列に対するマスキング方針などのガバナンスが必要です。
納品スピードは単純なベンチマークよりも統合や運用作業で左右されることが多いからです。優れたエコシステムはカスタム開発を減らせます:
これにより実装期間が短くなり、運用の負担も軽くなります。
現実的なパイロット(通常2~4週間)を使うのが実践的です:
費用見積りが必要なら /pricing を、移行やガバナンスのガイドが必要なら /blog を参照してください。