2025年3月17日·1 分
VMwareとBroadcom:仮想化がコントロールプレーンになるとき
VMwareがどのように企業ITのコントロールプレーンになったかをわかりやすく解説し、Broadcomによる所有権変化が予算・ツール・チームに与える影響を示します。
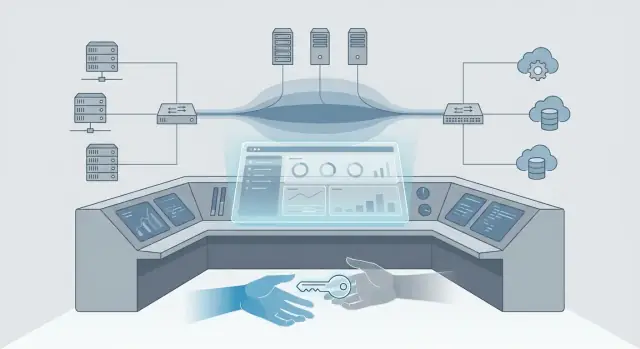
VMwareがどのように企業ITのコントロールプレーンになったかをわかりやすく解説し、Broadcomによる所有権変化が予算・ツール・チームに与える影響を示します。
仮想化は簡単に言えば、1台の物理マシンで多数の“仮想”サーバーを動かす仕組みです。一方でコントロールプレーンとは、システムで何をどこで動かすか、誰が変更できるか、どのように監視するかを定めるツールとルールの集合です。仮想化がエンジンだとすると、コントロールプレーンはダッシュボードであり、ハンドルであり、交通法規です。
VMwareは単にサーバーを減らす手助けをしただけではありません。時間とともに、vSphereやvCenterは次のような場になりました:
だからこそVMwareは単なる“VMを動かすもの”を超えて重要なのです。多くの企業では、インフラのオペレーティングレイヤーとして機能し、意思決定が実行・監査される地点になりました。
この記事では、仮想化がどのようにして企業のコントロールプレーンに成長したか、その戦略的重要性、そして所有権や製品戦略が変わったときに実務面で何が変わるかを見ていきます。簡単な歴史を振り返った後、運用、予算の示唆、リスク、エコシステム依存、そして現実的な選択肢(継続、分散、移行)を次の6〜18か月でどう扱うかに重点を置きます。
機密ロードマップを推測したり、特定の商業的動きを予言したりはしません。代わりに観察可能なパターンに焦点を当てます:買収後に通常最初に変わるもの(パッケージ、ライセンス、サポートの動き)、それらが日常業務にどう影響するか、そして不完全な情報でどう意思決定するか(固まらず過剰反応もしない)を扱います。
仮想化は最初から大きな「プラットフォーム」構想として始まったわけではありません。実用的な解決策として始まりました:未使用のサーバーが多すぎる、ハードウェアのスプロールが多い、あるアプリが物理ボックスを占有して夜遅くの障害を引き起こすといった問題です。
初期の訴求はシンプルでした――複数のワークロードを1台の物理ホストで動かし、サーバーを買い控える。これがすぐに運用上の習慣へと進化しました。
仮想化が一般化すると、最大の利点は単なる「ハードウェアコストの削減」ではなく、どこでも同じパターンを繰り返せることでした。
各拠点が独自のサーバー構成を持つ代わりに、仮想化は一貫したベースラインを促しました:類似したホストビルド、共通テンプレート、予測可能なキャパシティ計画、パッチや復旧のための共通手順。これは以下にまたがって重要でした:
基盤のハードウェアが異なっても、運用モデルはほぼ同じままにできました。
環境が成長するにつれて、重心は個別ホストから集中管理へ移りました。vCenterのようなツールは単に“仮想化を管理する”だけでなく、管理者が日常的な作業を行う場所になりました:アクセス制御、インベントリ、アラーム、クラスタの健全性、リソース配分、安全なメンテナンスウィンドウなどです。
多くの組織では、管理コンソールで見えないものは実質的に管理できないのと同じでした。
反復可能性を重視すると、単一の標準プラットフォームはベストオブブリードの寄せ集めを上回ることがあります。「どこでもまずまず」はしばしば次を意味します:
こうして仮想化は単なるコスト削減策から標準的な実践へ移り、企業のコントロールプレーンへと進化する下地ができたのです。
仮想化は最初、より多くのワークロードを少ないサーバーで動かす手段でした。しかし、ほとんどのアプリが共有仮想プラットフォーム上で動くようになると、“最初にクリックする場所”が意思決定を実行する場所になりました。これがハイパーバイザスタックがエンタープライズのコントロールプレーンへ進化する過程です。
ITチームは「計算」だけを管理しているわけではありません。日常の運用は次の領域にまたがります:
これらの層が一つのコンソールからオーケストレーションされると、基盤となるハードウェアが多様でも仮想化が実務の中心になります。
重要な変化は、プロビジョニングがポリシー駆動になることです。「サーバーを作る」代わりに、チームはガードレールを定義します:承認済みイメージ、サイズ制限、ネットワークゾーン、バックアップルール、権限。リクエストは標準化された結果に変換されます。
このためvCenterのようなプラットフォームはデータセンターのオペレーティングシステムのように機能します:アプリを直接実行するからではなく、アプリがどのように作られ、配置され、保護され、維持されるかを決めるからです。
テンプレート、ゴールデンイメージ、自動化パイプラインは行動を静かに固定します。一度チームがVMテンプレート、タグ付けスキーム、パッチや復旧のワークフローを標準化すると、それは各部門に広がります。時間が経つと、プラットフォームは単にワークロードをホストするだけでなく、運用習慣を組み込む存在になります。
一つのコンソールが「すべて」を動かすと、重心はサーバーからガバナンスへ移ります:承認、コンプライアンス証跡、職務分離、変更管理。だからこそ所有権や戦略の変化は単に価格に影響するだけでなく、ITの運用方法、対応スピード、変更の安全性に影響を与えます。
人々がVMwareを「コントロールプレーン」と呼ぶとき、それは単にVMが動く場所という意味ではありません。日常作業が調整される場所――誰が何をできるか、安全に何を変更できるか、問題をどう検出して解決するか――を指しています。
ほとんどのIT労力は初期デプロイ後に発生します。VMware環境ではコントロールプレーンがDay‑2運用の住処です:
これらのタスクは集中化されているため、チームはそれを基に再現可能なランブックを構築します:変更ウィンドウ、承認手順、「既知の良い」シーケンスなどです。
時間とともに、VMwareの知識は運用の筋肉の記憶になります:命名規則、クラスタ設計パターン、復旧訓練。代替は存在しても、一貫性がリスクを下げるので切り替えが難しいのです。新しいプラットフォームはエッジケースの再学習、ランブックの書き直し、プレッシャー下での前提の再検証を伴います。
障害時、対応者はコントロールプレーンを頼ります:
これらのワークフローが変わると、平均復旧時間(MTTR)も変わる可能性があります。
仮想化は単独で存在することは稀です。バックアップ、監視、災害復旧、構成管理、チケッティングシステムはvCenterやそのAPIと密に統合されています。DR計画は特定のレプリケーション動作を前提とするかもしれませんし、バックアップはスナップショットに依存するかもしれません。コントロールプレーンが移ると、これらの統合が最初の“驚き”になることが多いので、早めに棚卸してテストしてください。
VMwareのように中心的なプラットフォームの所有者が変わると、技術が一晩で壊れるわけではありません。最初に変わるのは商業的な包み(購入方法、更新方法、「通常」がどうなるか)です。
多くのチームは依然としてvSphereやvCenterから大きな運用価値を得ています――標準化されたプロビジョニング、一貫した運用、馴染みのあるツールチェーン。商業条件が急速に変わっても、その価値は安定していることがあります。
この2つは別々の会話にすると良いです:
新しいオーナーはカタログを簡素化したり、契約価値を上げたり、顧客を少ないバンドルに移行させようとすることが多いです。それは次の変化につながります:
実務的な心配事は地味ですが重要です:「来年のコストはどうなるのか?」、「複数年の予測はできるのか?」。財務は安定した予測を求め、ITは更新が急に建築上の決定を強要しないことを望みます。
数字の話を始める前に、クリアな事実ベースを作ってください:
これがあれば、滞在、分散、移行いずれの計画でも明確に交渉できます。
ベンダーの戦略が変わると、最初に多くのチームが感じるのは新機能よりも購入と計画の方法です。Broadcomの方向性を注視するVMware顧客にとっては、実務的影響はバンドル、ロードマップの優先度、どの製品が重視されるかに現れます。
バンドルは確かに助けになります:SKUが減り、どのアドオンを買うかの議論が少なくなり、チーム間の標準化が進みます。
しかしトレードオフは柔軟性です。バンドルに使わないコンポーネントが含まれていると棚卸しコストを払うことになったり、段階的な代替のパイロットが難しくなったりします。
製品ロードマップは収益や更新を牽引する顧客セグメントに合わせられがちです。結果として:
これ自体は必ずしも悪くありませんが、アップグレードや依存関係の計画方法を変えます。
ある機能が優先度を下げられると、チームはそのギャップを点(Point)ソリューションで埋めることが多くなります(バックアップ、監視、セキュリティ、自動化)。短期的には問題を解決しますが、長期ではツールスプロールを招きます:コンソールが増え、契約や統合の管理負荷が増え、事故の潜み場所が増えるのです。
次の点を明確にしてもらい、できれば書面で得てください:
これらの回答があれば、戦略変化を予算、要員、リスクの計画入力に変えることができます。
VMwareがコントロールプレーンとして扱われると、ライセンスやパッケージの変更は調達だけに留まりません。変更はITのワークフロー全体に波及します:誰が変更を承認するか、環境をどれだけ速くプロビジョニングできるか、チーム間での“標準”が何を意味するかが変わります。
プラットフォーム管理者は最初に影響を感じることが多いです。権利が簡素化されバンドルが減ると、日々の運用は柔軟性を失うことがあります:以前は「そこにあった」機能を使うのに内部承認が必要になったり、設定の標準化がより厳しく求められたりします。
これは見えにくい場所の管理負荷として現れます――プロジェクト開始前のライセンスチェック、アップグレードを合わせるための厳しい変更ウィンドウ、パッチと構成差分に関するセキュリティおよびアプリチームとの調整などです。
アプリチームは通常、性能と稼働率で評価されますが、プラットフォームの変化は前提を変えることがあります。クラスタ再バランス、ホスト数の変更、エンタイトルメントに合わせた機能使用の調整が行われると、アプリオーナーは互換性の再テストと性能の再ベースライン化が必要になります。
これは特に特定のストレージ、ネットワーク、HA/DR動作に依存するワークロードで顕著です。実務的な結果として、構造化されたテストサイクルと「このアプリが必要とするもの」の明確なドキュメントが求められます。
仮想化レイヤーがセグメンテーション、特権アクセス、監査証跡の施行点である場合、ツールや標準構成の変更はコンプライアンスに影響します。セキュリティチームは職務分離の明確化(誰がvCenterで何を変更できるか)、一貫したログ保持、例外構成の削減を求めます。ITはより正式なアクセスレビューと変更記録を準備すべきです。
トリガーがコストであっても、影響は運用面に及びます:チャージバック/ショウバックモデルの更新、コストセンター間で「何が含まれるか」の再交渉、予算予測がプラットフォームチームとの共同作業になること。
仮想化をコントロールプレーンとして扱う良い兆候は、ITと財務が更新後の驚きではなく共同で計画することです。
プラットフォームの所有権や戦略が変わると、最大のリスクは「静かな」部分――継続計画、サポート期待値、日常の運用安全性――に現れます。すぐに何も壊れなくても、長年頼ってきた前提が変わる可能性があります。
大きなプラットフォームの変化はバックアップ、DR、保持ポリシーへ微妙に波及します。バックアップ製品は特定のAPI、vCenter権限、スナップショット挙動に依存する場合があります。DRランブックは特定のクラスタ機能、ネットワークデフォルト、オーケストレーション手順を前提とすることが多いです。
実務的な取り組み:最も重要なシステム(Tier‑0のアイデンティティ、管理ツール、主要業務アプリ)のエンドツーエンドの復元プロセスを検証してください(バックアップ成功だけで満足しないこと)。
一般的なリスク領域は契約より運用的です:
実務的なリスクはコスト増ではなく「未知の未知」から来るダウンタイムです。
あるプラットフォームが支配的であると標準化、小さなスキルセット、整合したツール群の利点があります。トレードオフは依存です:ライセンス、サポート、製品フォーカスが変わったときの逃げ道が少なくなります。依存リスクはVMwareがワークロードだけでなく、アイデンティティ、バックアップ、ロギング、自動化を支えるときに最も高まります。
実際に動いているもの(バージョン、依存関係、統合点)を文書化し、vCenter/管理者ロールのアクセスレビューを厳格化し、テスト頻度を設定してください:四半期ごとの復元テスト、半期ごとのDR演習、アップグレード前のハードウェア互換性とサードパーティ確認を含む検証チェックリストなど。
これらは戦略の方向性に関わらず運用リスクを下げます。
VMwareは単独で動くことは稀です。多くの環境はハードウェアベンダー、MSP、バックアッププラットフォーム、監視ツール、セキュリティエージェント、DRサービスの網に依存しています。所有権や製品戦略が変わると、まずこのエコシステムに“爆発半径”が現れることが多く、vCenter内部より先に気づく場合もあります。
ハードウェアベンダー、MSP、ISVは特定のバージョン、エディション、展開パターンに合わせてサポートを調整します。彼らの認証とサポートマトリクスは何をトラブルシュートするか(あるいはしないか)を決めます。
ライセンスやパッケージが変わると間接的にアップグレードを強いることがあり、それがサーバーモデル、HBA、NIC、ストレージ配列、バックアッププロキシのサポート可否に影響します。
多くのサードパーティツールは従来「ソケット当たり」「ホスト当たり」「VM当たり」といった前提で価格やパッケージを組んでいました。プラットフォームの商業モデルが変わると、これらのツールも使用のカウント方法や、どの統合が含まれるか、どの機能が追加費用かを見直す可能性があります。
サポートの前提も変わり得ます。たとえばISVは特定のAPIアクセス、プラグイン互換、最低vSphere/vCenterバージョンを要求するかもしれません。時間が経つと「以前は動いていた」が「このバージョンとこの層だけで動く」になることがあります。
コンテナやKubernetesはVMスプロールの圧力を和らげることがありますが、多くの企業では仮想化の必要性をなくしません。チームは多くの場合KubernetesをVM上で運用し、仮想ネットワークやストレージポリシーに依存し、既存のバックアップやDRパターンを使います。
そのため、コンテナツールと仮想化レイヤーの相互運用性(アイデンティティ、ネットワーク、ストレージ、可観測性周り)は依然として重要です。
「滞在、分散、移行」を決める前に依存している統合を一覧化してください:バックアップ、DR、監視、CMDB、脆弱性スキャン、MFA/SSO、ネットワーク/セキュリティオーバーレイ、ストレージプラグイン、MSPの運用手順。
次に3点を検証します:今日サポートされていること、次のアップグレードでサポートされること、パッケージ/ライセンス変更でサポート外になる展開や管理方法があるか。
仮想化が日常のコントロールプレーンとして機能している場合、変更は単純な“プラットフォーム交換”ではありません。多くの組織は次の道のいずれか(時に複合)を選びます。
滞在は「何もしない」と同義ではありません。通常はインベントリを厳密化し、クラスタ設計を標準化し、偶発的なスプロールを排除して本当に運用している分だけ支払うようにします。
コスト管理が目的なら、ホストの右-sizing、未使用クラスタの削減、実際に必要な機能の検証から始めてください。レジリエンスが目的なら、運用の衛生管理(パッチ周期、バックアップテスト、記録された復旧手順)に注力します。
最も一般的な短期的対応は最適化です。リスクを下げ時間を稼げます。典型的な作業:管理ドメインの統合、テンプレート/スナップショットの整理、ストレージ/ネットワーク基準の整合。これで将来の移行が楽になります。
分散はすべてを一度に再プラットフォームするのではなく、安全なゾーンを選んで別スタックを導入する方法です。適合しやすい例:
目標は通常ベンダー分散や機動性の向上であり、即時の全置換ではありません。
「移行」はVMを移す以上の意味があります。ワークロードだけでなくネットワーク(VLAN、ルーティング、ファイアウォール、ロードバランサ)、ストレージ(データストア、レプリケーション)、バックアップ、監視、アイデンティティ/アクセス、そしてしばしば過小評価されるスキルと運用手順を計画する必要があります。
最初に現実的な目標を定めてください:価格の最適化、提供速度、リスク削減、戦略的柔軟性のどれを優先するか。優先順位が明確でなければ移行が終わりのない再構築になります。
VMwareが運用のコントロールプレーンであるなら、VMware/Broadcomの戦略変化に関する決定はベンダー発表から始めるべきではなく、まず自分たちの環境から始めるべきです。次の6〜18か月での目標は仮定を測定可能な事実に置き換え、リスクと運用適合性に基づいて道を選ぶことです。
運用チームが障害時に信頼できるインベントリを作ってください。調達用のスプレッドシートではなく実務で使えるものを。
このインベントリがvCenter運用が何を実際に可能にしているか、他所で再現が難しいものは何かの基礎になります。
vSphereライセンスや代替プラットフォームを比較する前に、ベースラインを定量化して明らかな浪費を取り除いてください。
注力点:
右-sizingは即時のコスト低減につながり、移行計画の精度も上がります。
意思決定基準を書き出し、重み付けしてください。典型的なカテゴリ:
代表的なワークロード(簡単なものではない)を選び、次を用意してパイロットを回してください:
パイロットをDay‑2運用のリハーサルとして扱い、単なる移行デモで終わらせないでください。
現場では、コントロールプレーンの大きな部分は周辺の小さなシステム群です:インベントリトラッカー、更新ダッシュボード、アクセスレビューのワークフロー、ランブックチェックリスト、変更ウィンドウの調整ツール。
短期間でそれらを作る・モダナイズする必要があるなら、チャットインターフェースで軽量な内部ウェブアプリを素早くプロトタイプできるプラットフォーム(Koder.aiのような)を活用すると良い場合があります。例えば、vCenter統合のインベントリアプリや更新準備度ダッシュボードをプロトタイプ(Reactフロントエンド、Go+PostgreSQLバックエンド)、カスタムドメインでホストし、完全な開発サイクルを待たずに要件の変化に合わせて反復できます。
完全な「プラットフォーム戦略」は不要です。今週の目標は不確実性を減らすこと:日付を把握し、カバレッジを確認し、意思決定時に誰を集めるかを明確にすることです。
会議で指差せる事実から始めてください。
所有権やライセンスの変化は、情報が分断されると驚きを生みます。
短い作業グループを招集してください:プラットフォーム/仮想化、セキュリティ、アプリオーナー、財務/調達。合意事項:
リスクとコストを見積もるのに「十分な」内容を目指し、完璧を目指さないでください。
これは一度きりの作業ではなく継続的な管理サイクルにしてください。
四半期ごとに見直すべきは:ベンダーロードマップ/ライセンス更新、走行コストと予算差、運用KPI(インシデント件数、パッチ準拠率、復元テスト結果)。結果を次回更新や移行計画に反映させてください。
ハイパーバイザーはVMを実行します。コントロールプレーンは、決定とガバナンスのレイヤーであり、次のことを決めます:
多くの企業では、vCenterが「最初にクリックする場所」になっており、そのため単なる仮想化ツールではなくコントロールプレーンとして機能しているのです。
運用上の価値が標準化と反復可能性に集中するからです。vSphere/vCenterはしばしば次の共通インターフェースになります:
こうした運用習慣が定着すると、プラットフォームを変えることはVMの実行場所を変えるだけでなく、Day‑2運用そのものに影響を与えます。
Day‑2運用とは、初期導入後にカレンダーを埋める繰り返しタスクのことです。VMware中心の環境では通常以下を含みます:
もし運用手順がこれらを前提としているなら、管理レイヤーは実質的に運用システムの一部になっています。
前提が変わったときに最初に壊れるのはこれらです。よく見落とされる依存関係は:
これらは早い段階でインベントリ化し、アップグレードやパイロット時にテストしてください。更新後に初めて気づくと手遅れになることが多いです。
通常は商業的なラッパーが最初に変わります。現場で最初に感じる変化は:
技術と商業条件は別トラックで扱い、運用上の価値を保ちながら契約面の不確実性を減らしてください。
交渉を推進するための事実ベースを作りましょう:
これがあれば、交渉は推測ではなく現実に基づいて行えます。
コントロールプレーンに依存する復旧ワークフローは、次を頼りにしています:
ツールや役割、ワークフローが変わると復旧時間が遅くなる可能性があるため、再訓練、役割の再設計、更新されたインシデントランブックを用意しておくべきです。
必ずしも悪いわけではありません。バンドルは購入を簡素化し、配備を標準化する利点がありますが、トレードオフは:
現実的な対処:バンドルの各コンポーネントが実際の運用ニーズに結びついているか(または採用計画があるか)を確認してから受け入れてください。
不確実なときは不確実さを減らし時間を買うことが現実的です:
これらは「滞在」「分散」「移行」のいずれを選んでもリスクを下げます。
運用を試験する統制されたパイロットにしてください:
パイロットは単なる移行デモではなく、パッチ適用、監視、バックアップ、アクセス制御などDay‑2運用のリハーサルとして扱ってください。