2025年9月05日·2 分
Web Worker と Service Worker: それぞれの役割と使いどころ
Web Worker と Service Worker の違い、各々が何をするか、いつ使うべきかを学び、ページの応答性向上、バックグラウンド処理、キャッシュ、オフライン対応にどう役立つかを理解します。
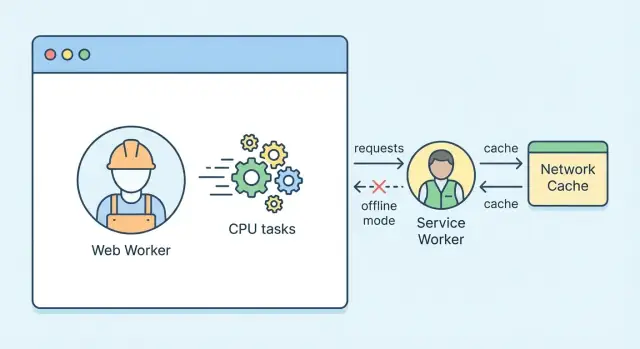
Web Workers vs Service Workers: クイック概要
ブラウザはほとんどの JavaScript をメインスレッドで実行します—ユーザー入力、アニメーション、ページの描画と同じ場所です。そこに重い処理(大きなデータの解析、画像処理、複雑な計算)があると、UI がカクついたり「フリーズ」したように見えます。ワーカーは特定のタスクをメインスレッドから切り離す、あるいはページの直接管理外に置くことで、アプリの応答性を保つために存在します。
ワーカーが解決する問題
ページが 200ms の計算で忙しいと、ブラウザはスムーズにスクロールできず、クリックに反応せず、アニメーションを 60fps で維持できません。ワーカーはバックグラウンドで処理を行い、メインスレッドがインターフェースに集中できるようにします。
簡単な定義
Web Worker はページから作成するバックグラウンドの JavaScript スレッドです。UI をブロックする CPU 集中型の作業に向いています。
Service Worker はウェブアプリとネットワークの間に入る特殊なワーカーです。リクエストを横取りしたり、レスポンスをキャッシュしたり、オフライン対応やプッシュ通知のような機能を可能にします。
単純なメンタルモデル:"スレッド" 対 "ネットワークの門番"
Web Worker を別室で計算するヘルパーだと考えてください。メッセージを送ると処理し、結果を返してくれます。
Service Worker は玄関の門番のようなものです。ページ、スクリプト、API 呼び出しのリクエストがそこを通り、ネットワークから取るかキャッシュから返すか、あるいは別の応答を返すかを決められます。
この記事で学べること
この記事の終わりには以下がわかります:
- いつ Web Worker がパフォーマンス対策に適しているか(そして何にアクセスできないか)
- Service Worker がオフラインキャッシュ、アップデート、PWA の振る舞いに何をもたらすか
postMessageのようなメッセージングがワーカーモデルにどのように組み込まれるか、オフラインに重要な Cache Storage API がなぜ重要か
この概要で「なぜ」やメンタルモデルを固めたら、次に各ワーカー種別の振る舞いと実際のプロジェクトでの位置づけを詳しく見ていきます。
ブラウザにワーカーがある理由
ウェブページを開いたとき、ユーザーが“感じる”ほとんどは メインスレッド 上で起きます。ピクセルの描画(レンダリング)、タップやクリックへの反応(入力)、そして多くの JavaScript の実行がそこにあります。
メインスレッドは共有のレジ待ち列のようなもの
レンダリング、入力処理、JavaScript が同じスレッドで順番に処理されるため、ひとつの重いタスクが他を待たせてしまいます。だからパフォーマンス問題は単なる「遅いコード」ではなく、応答性 の問題として現れがちです。
ブロッキングがユーザーに与える感覚:
- スクロールがカクつく(ジャンク)
- ボタンがすぐに反応しない
- タイピングの入力が遅れる
- アニメーションが一瞬停止する
非同期 = 並列 ではない
JavaScript には fetch() やタイマー、イベントなど多くの非同期 API がありますが、非同期が重い処理をレンダリングと同時に「並列」で実行してくれるわけではありません。
画像処理、大きな JSON の計算、暗号処理、複雑なフィルタリングなどの高負荷計算をメインスレッドで行えば、UI 更新と競合し続けます。非同期は実行のタイミングを遅らせることはできますが、同じスレッドで動く限り、実行時にはジャンクを引き起こす可能性があります。
ブラウザアーキテクチャにおけるワーカーの位置づけ
ワーカーはブラウザがページの応答性を保ちながら実用的な作業を行えるようにするためにあります。
- Web Workers はバックグラウンドスレッドで JavaScript を実行し、CPU 集中型タスクを処理します。
- Service Workers は特定のページに依存せずに実行され、ネットワークとキャッシュのレイヤーとして振る舞い、ページが開かれていないときでも機能します。
要するに:ワーカーはメインスレッドを守り、バックグラウンドで実務的な仕事をさせるための仕組みです。
Web Worker とは何か?
Web Worker は JavaScript をメインスレッドの外で実行する方法です。レンダリングやスクロール、クリック応答と競合する代わりに、ワーカーは独立したバックグラウンドスレッドで動くため、重い処理を行ってもページが「固まった」ように感じさせません。
ページはユーザーインタラクションに集中し、ワーカーは大きなファイルのパース、数値計算、チャート用データの準備などの CPU 集中型作業を処理します。
実行される場所
Web Worker は独自のグローバルスコープを持つ別スレッドで実行されます。多くの Web API(タイマー、fetch(多くのブラウザで)、crypto など)にアクセスできますが、ページから意図的に分離されています。
Dedicated Worker と Shared Worker の違い
一般的な種類としては:
- Dedicated Worker:単一のページ/タブに接続されます。ページが消えるとワーカーも通常終了します。
- Shared Worker:同一オリジンの複数のページ/タブで共有でき、タブ間で作業を調整したり単一の接続を共有したりするのに便利です。
初めてワーカーを使う人が見るサンプルの多くは Dedicated Worker です。
Web Worker の通信方法
ワーカーはページ内の関数を直接呼べません。通信はメッセージで行います:
- ページは
postMessage()でワーカーにデータを送る。 - ワーカーも
postMessage()で応答する。 - データは structured clone アルゴリズムで転送され、多くの組み込み型(オブジェクト、配列、文字列、数値、Map/Set、ArrayBuffer など)をサポートします。
大きなバイナリデータでは、ArrayBuffer の所有権を転送してコピーを避けると、メッセージパスが高速のまま保たれます。
一般的な制約(設計上の制限)
ワーカーは分離されているため、いくつかの重要な制約があります:
- DOM に直接アクセスできない:ワーカーはページの HTML、CSS、レイアウトを読み書きできません。
- 異なるグローバル:
windowやdocumentは使えません。ワーカーはself(ワーカーのグローバルスコープ)で実行され、利用可能な API はメインスレッドと異なります。 - 非同期思考:すべてがメッセージベースなので、仕事を送って結果を受け取る構造にコードを書きます。
適切に使えば、Web Worker はアプリの動作を変えずにメインスレッドのパフォーマンスを改善する最も簡単な方法のひとつです—高負荷処理を実行する場所だけを変えます。
Web Worker を使うべきとき(および使わないほうがよいとき)
Web Worker は、JavaScript がメインスレッドで重い仕事をしてページが「固まる」ように感じるときに適しています。メインスレッドはユーザー操作とレンダリングも担当するため、そこでの重い処理はジャンクや遅延クリック、スクロールの固まりを引き起こします。
Web Worker に向くケース
DOM に直接アクセスする必要がない CPU 集中型の仕事があるときに Web Worker を使います:
- 重い計算:シミュレーション、データ集計、数値計算
- パースと変換:大きな JSON の解析、CSV パース、スキーマ検証
- 圧縮/解凍:zip/gzip スタイルの処理、エンコード/デコード
- 画像処理:リサイズ、フィルタリング、サムネイル生成(対応ブラウザでは OffscreenCanvas と併用)
実用的な例:大きな JSON ペイロードを受け取り、パースで UI がカクつくなら、そのパースをワーカーへ移して結果だけ返すとよいです。
データ処理のヒント(速度向上)
ワーカーとの通信は postMessage で行います。大きなバイナリデータには transferable objects(例:ArrayBuffer)を使い、ブラウザがメモリの所有権をワーカー側に移せるようにするとコピーを避けられ高速です。
// main thread
worker.postMessage(buffer, [buffer]); // ArrayBuffer を転送する
これはオーディオバッファや画像バイトなど、大きなデータに特に有効です。
Web Worker を使わないほうがよい場合
ワーカーにはオーバーヘッドがあります:追加ファイル、メッセージパス、異なるデバッグフロー。次の場合は使わないほうがよいです:
- タスクが 極小(数ミリ秒)で稀にしか実行されない場合。
- 作業が 頻繁な DOM 読み書き を要する場合(ワーカーは DOM にアクセスできない)。
- 超低レイテンシのやり取りが必要で、頻繁な
postMessageの往復が利点を打ち消してしまう場合。
シンプルな経験則
タスクが目に見える停止(多くの場合 ~50ms 以上)を引き起こし得て、かつ「入力 → 計算 → 出力」と表現できて DOM アクセスを必要としないなら、Web Worker を採用する価値があります。作業が主に UI の更新であれば、メインスレッド上で最適化する方がよいです。
Service Worker とは何か?
Service Worker はブラウザのバックグラウンドで動く特殊な JavaScript ファイルで、サイトのためのプログラマブルなネットワーク層として振る舞います。ページ自体ではなく、ウェブアプリとネットワークの間に位置して、アプリがリソース(HTML、CSS、API 呼び出し、画像)を要求したときに何をするか決められます。
ライフサイクルの基本(register → install → activate → control)
Service Worker は単一のタブに紐づかない独立したライフサイクルを持ちます:
- 登録(Register):ページがブラウザに「このサイトには Service Worker がある」と伝える(通常はメイン JS から)。
- インストール(Install):ブラウザがスクリプトをダウンロードしてインストールステップを実行し、重要なファイルのプリキャッシュに使われることが多い。
- アクティベート(Activate):新しいワーカーが引き継ぎ、古いタブを閉じるか安全に置き換えられる時に有効化される。
- 制御(Control):アクティブになると、スコープ内のページを「制御」し、リクエストを横取りできるようになる。
ブラウザはワーカーを停止・再起動できるため、イベント駆動スクリプトとして扱い、仕事は素早く行い、状態は永続ストレージに保存し、常に常駐しているとは仮定しない設計にしてください。
スコープとオリジンルール(概要)
Service Worker は 同一オリジン に制限され、通常ワーカーが提供されるフォルダ(およびその下位)をスコープとしてページを制御します。また、ネットワークリクエストに影響を与え得るため HTTPS(開発時は localhost を除く)が必要です。
よく使われる API
- Fetch イベント:リクエストを横取りしてネットワークを使うか、キャッシュを使うか、カスタムレスポンスを返すかを決める。
- Cache Storage API:キャッシュされたレスポンスを保存・取得してオフラインを可能にする。
- Clients API:ワーカーが制御する開いているタブ/ウィンドウと通信・管理する。
Service Worker が使われる目的
メインスレッドのカクつきを解消
バックグラウンドでデータ処理を行いながらも応答性を保つ小さなアプリを作ります。
Service Worker は主にウェブアプリとネットワークの間に位置し、いつネットワークを使うか、いつキャッシュを使うか、バックグラウンドで少し作業をするかを決められます—しかもページをブロックしません。
オフラインサポート(スマートキャッシュ)
もっとも一般的な役割は、アセットやレスポンスをキャッシュしてオフラインや低速接続時の体験を向上させることです。
よく見るキャッシュ戦略:
- Cache-first:静的ファイル向け。高速でオフライン対応。
- Network-first:頻繁に変わるコンテンツ向け。オフライン時はキャッシュにフォールバック。
- Stale-while-revalidate:まずキャッシュを即時表示し、裏で更新して次回に備える。
これは通常 Cache Storage API と fetch イベントハンドリングで実装します。
再訪問時の高速化
Service Worker はリターンビジットで体感速度を上げられます:
- プリキャッシュ:インストール時に必須ファイル(アプリシェル)を保存する。
- ランタイムキャッシュ:ユーザーがナビゲートするたびにページや API レスポンスをキャッシュする。
結果としてネットワークリクエストが減り、起動が速く、不安定な接続でもより一貫したパフォーマンスが得られます。
バックグラウンド機能(サポートがある場合)
Service Worker は プッシュ通知 や バックグラウンド同期(ブラウザ・プラットフォーム依存)を提供できます。つまり、ページが開かれていなくてもユーザーに通知したり、失敗したリクエストを後で再送したりできます。
PWA の構成要素
プログレッシブウェブアプリを作るとき、Service Worker は重要な役割を担います:
- インストール可能性(Web App Manifest と組み合わせて)
- 信頼できる オフラインページ(親切なフォールバック)
- アプリシェル モデルによる高速なナビゲーション
主な違い:Web Worker と Service Worker
一言で言えば:Web Worker は UI を固まらせずに重い処理をさせるため、Service Worker はネットワークリクエストを制御してインストール可能なアプリのように振る舞わせるためのものです。
実行場所(何をするためのものか)
Web Worker:CPU 集中型タスク(大きなデータのパース、サムネイル生成、数値計算)をメインスレッド外で行わせ、UI の応答性を保つためのもの。
Service Worker:リクエストの処理やアプリのライフサイクルタスク(オフライン対応、キャッシュ戦略、バックグラウンド同期、プッシュ通知)を担当し、アプリとネットワークの間に位置する。
ライフタイムと“所有者”
Web Worker は通常 ページ/タブに紐づく。ページが閉じられるとワーカーも終了することが多い(SharedWorker などの特殊例を除く)。
Service Worker は イベント駆動 で、ブラウザはイベント(fetch や push)を処理するために起動し、処理が終わると停止します。つまりページが開いていなくても動作します。
ネットワークアクセスと制御
Web Worker はページが行うネットワークリクエストを横取りできません。ワーカー自身が fetch() することはできますが、サイトの他の部分のリクエストを書き換えたりキャッシュしたりはできません。
Service Worker は fetch イベントでネットワークリクエストを横取りし、ネットワークを使うかキャッシュを返すか、フォールバックを返すかを決められます。
ストレージとキャッシュ
Web Worker はアプリの HTTP キャッシュを直接管理しません。
Service Worker は Cache Storage API を使ってリクエスト/レスポンスのペアを保存・提供し、オフラインキャッシュと“即時”再読み込みの基盤を作ります。
セットアップ方法(ハイレベルな手順)
アイデアをコードに
workerプランを編集・エクスポート可能な実働コードベースに変えます。
ワーカーを動かすには"どこから"実行するか、"どう読み込むか"を考える必要があります。Web Worker はページが直接作成します。Service Worker はブラウザに登録され、あなたのサイトのネットワークリクエストの前に立ちます。
Web Worker:ページから作成する
Web Worker はページが作成すると動き始めます。別の JavaScript ファイルを指し、postMessage で通信します。
// main.js (ページで実行)
const worker = new Worker('/workers/resize-worker.js', { type: 'module' });
worker.postMessage({ action: 'start', payload: { /* ... */ } });
worker.onmessage = (event) => {
console.log('From worker:', event.data);
};
ワーカーファイルは単に別のスクリプト URL としてページがフェッチできるファイルですが、メインスレッド外で実行されます。
Service Worker:登録(register)してブラウザにインストールさせる
Service Worker はユーザーが訪れるページから登録する必要があります:
// main.js
if ('serviceWorker' in navigator) {
navigator.serviceWorker.register('/sw.js');
}
登録後、ブラウザがインストール/アクティベートのライフサイクルを処理します。sw.js は install、activate、fetch などのイベントをリッスンできます。
なぜ Service Worker に HTTPS が必要か
Service Worker はネットワークリクエストを横取りしてキャッシュを操作できます。HTTP 上で登録を許可すると、ネットワーク上の攻撃者が悪意ある sw.js を差し替えて将来の訪問を制御できてしまいます。HTTPS(開発時は http://localhost)はスクリプトとそれが影響するトラフィックを保護します。
バージョニングの考え方:ワーカーファイルをデプロイ可能な "リリース" と考える
ブラウザはワーカーを通常のページスクリプトとは異なる方法でキャッシュ・更新します。更新に備えて計画してください:
- 振る舞いを変えたいときはファイルを変更する(新しい
sw.js/ワーカーバンドルをデプロイする)。 - Service Worker では "更新" フローがあり:新しいワーカーがインストールされ、安全になった時点でアクティブ化される。
- キャッシュ戦略を変更する場合、アクティベーション時に古いキャッシュをクリーンアップするロジックを含める。
滑らかなロールアウト戦略を後で取り入れたい場合は、/blog/debugging-workers のようなデバッグ習慣を参照して、更新に関するエッジケースを早期にとらえるとよいでしょう。
ブラウザでのワーカーのデバッグとテスト
ワーカーは通常のページ JavaScript とは異なる形で失敗します:別コンテキストで動き、独自のコンソールを持ち、ブラウザにより再起動されることがあります。堅実なデバッグ習慣があれば時間を大幅に節約できます。
Web Worker のデバッグ(DevTools)
DevTools を開き、ワーカー専用のターゲットを探してください。Chrome / Edge では Sources にワーカーがリストされることが多く、コンソールのコンテキストセレクタから切り替えられます。
メインスレッドと同じツールを使います:
- Console ログ:Web Worker のログは DevTools に表示されますが、正しいコンテキストを見ていることを確認してください。
- ブレークポイント:ワーカースクリプト内にブレークポイントを置き、
onmessageハンドラや長時間実行される関数をステップ実行する。 - パフォーマンスプロファイル:パフォーマンストレースを録って、ワーカーが重い作業をしている間にメインスレッドが応答性を保っているか確認する。
メッセージが“失われる”ように見える場合は両側を点検:worker.postMessage(...) を呼んでいるか、ワーカー側に self.onmessage = ... があるか、メッセージ形状が合っているかを確認してください。
Service Worker のデバッグ(Application パネル)
Service Worker は Application パネルでデバッグするのが最適です:
- 登録状況、スコープ、アクティブ/待機/インストール済みバージョンを確認。
- Skip waiting や Unregister などのライフサイクルコントロールを使って状態をリセット。
- Update on reload を有効にして、繰り返し開発中に古いコードを追いかけ回さないようにする。
また、インストール/アクティベート/フェッチのエラーはコンソールに出ることが多く、キャッシュやオフライン動作がうまくいかない原因を説明してくれます。
よくある落とし穴とテストのヒント
キャッシュの問題が最も時間を取ります:誤ったファイルをキャッシュしたり、強すぎるキャッシュで古い HTML/JS が残ることがあります。テスト時は ハードリロード を試し、実際に何が提供されているか確認してください。
現実的なテストのために DevTools を使って:
- オフライン モードをシミュレートしてフォールバックページを検証
- ネットワークスロットリング を適用
- 複数回リロードして Service Worker の更新とメッセージ処理を検証
PWA を素早く反復開発するなら、予測可能な Service Worker とビルド出力を持つベースアプリを生成してからキャッシュ戦略を調整するワークフローが役立ちます。Koder.ai のようなプラットフォームは、チャットプロンプトから React ベースのウェブアプリをプロトタイプしてソースコードをエクスポートし、ワーカー設定やキャッシュルールをより短いフィードバックループで試せる点で便利です。
セキュリティ、プライバシー、パフォーマンスの考慮点
ワーカーはアプリを滑らかで機能的にしますが、コードが実行される場所やアクセス範囲を変えます。セキュリティ、プライバシー、パフォーマンス面のチェックをしておくと驚きのバグや不満に繋がる事態を避けられます。
セキュリティ境界(同一オリジンが重要な理由)
Web Worker と Service Worker はどちらも 同一オリジンポリシー によって制限されます:同一のスキーム/ホスト/ポートのリソースしか直接やり取りできません(サーバー側で明示的に CORS を許可している場合を除く)。これによりワーカーが他サイトから密かにデータを取得して混ぜるのを防ぎます。
Service Worker は追加のガードレールを持ちます:通常 HTTPS が必要です(開発時の localhost を除く)。ネットワークリクエストを横取りできるため、権限のあるコードとして扱い、依存を最小限にし、動的コードの読み込みを避け、キャッシュロジックはバージョン管理して古いキャッシュが使われ続けないようにしてください。
プライバシーとユーザー期待
バックグラウンド機能は予測可能であるべきです。プッシュ通知 は強力ですが、許可プロンプトは乱用しやすいです。
明確な利点があるときだけ許可を求め(例:ユーザーが設定で通知を有効にした後)、どんな通知を受け取るかを説明してください。バックグラウンドでデータを同期/プリフェッチするなら、それが何をするかを分かりやすく示しましょう—ユーザーは予期しないネットワーク活動や通知に気づきます。
注意すべきパフォーマンスリスク
ワーカーには "無料" の性能はありません。多用すると逆効果になります:
- メッセージのオーバーヘッド:頻繁な
postMessage(特に大きなオブジェクト)はボトルネックになります。バッチ処理や transferables を検討してください。 - メモリコスト:各ワーカーは独自のメモリと起動オーバーヘッドを持つため、ワーカーが多すぎると RAM 使用量やバッテリー消費が増える。
- キャッシュの肥大化:過度にキャッシュする Service Worker はストレージを圧迫します。キャッシュ制限や更新時のクリーンアップを実装してください。
優雅なフォールバック
すべてのブラウザがすべての機能をサポートしているわけではなく、ユーザーが権限をブロックすることもあります。機能検出を行い、段階的にフォールバックしてください:
if ('serviceWorker' in navigator) {
// service worker を登録
} else {
// オフライン機能なしで継続
}
目標は:コア機能は常に動作し、オフラインやプッシュ、重い計算といった "あれば嬉しい" 機能は利用可能なときだけ追加することです。
両方を組み合わせたよくあるパターン
コードベースを管理する
生成されたベースラインから始め、sw.jsやworkerモジュールを自信を持ってローカルで調整します。
Web Worker と Service Worker は別々の問題を解くので、重い計算と高速かつ信頼できる読み込みの両方が必要なアプリでは相性が良いです。良いメンタルモデルは:Web Worker = 計算、Service Worker = ネットワーク+キャッシュ、メインスレッド = UI です。
パターン 1:画像処理 + オフラインギャラリー
ユーザーが写真を編集して(リサイズ、フィルタ、背景除去)後でオフラインでも閲覧できるギャラリーを想像してください。
- Web Worker は CPU 集中型の作業(デコード、変換、サムネイル生成)を行い、スクロールやタップをスムーズに保ちます。
- Service Worker は生成されたサムネイルやオリジナルを Cache Storage(またはメタデータを IndexedDB)に保存し、再訪問やオフライン時に即座に配信します。
この「計算してからキャッシュする」アプローチは役割を明確に分け、ワーカーは結果を作り、Service Worker がそれをどのように保存・提供するかを決めます。
パターン 2:データ同期 + バックグラウンドキャッシュ
フィードやフォーム、フィールドデータを扱うアプリの場合:
- Web Worker は大きな JSON ペイロードの正規化、差分計算、検証を UI をブロックせずに行う。
- Service Worker は API レスポンスをキャッシュして高速起動を提供し、オフライン読み取りを可能にする。接続が回復したらキャッシュを更新し、可能ならバックグラウンド同期で送信を完了させる。
バックグラウンド同期がなくても、Service Worker はキャッシュされたレスポンスを返して即時性を高め、裏で更新する役割を果たします。
責任を分ける
役割を混ぜないようにする:
- UI スレッド: レンダリング、ユーザー入力、アクセシビリティ、最小限の状態連携。
- Web Worker: 純粋な計算とデータ準備(多くは
postMessage経由)。 - Service Worker: リクエストのルーティング、キャッシュ戦略、オフラインフォールバック。
クイックチェックリスト:どちらが必要?
- タスクが CPU 集中型(パース、エンコード、暗号、画像/音声処理)なら Web Worker を使う。
- タスクがフェッチの横取り、オフライン、キャッシュに関するなら Service Worker を使う。
- 速い UI と速い読み込み/オフラインの両方が必要なら 両方 を使う。ただし境界を明確に:計算は Web Worker、保存と配信は Service Worker に任せる。
FAQ: よくある実用的な質問
Service Worker は DOM にアクセスできますか?
いいえ。Service Worker はバックグラウンドで動き、どのページタブにも属さないため、ページの DOM(HTML 要素)に直接アクセスできません。
この分離は意図的で、ページが開かれていない状況(例えばプッシュイベントに応答する場合)でも動作するように設計されています。Service Worker がユーザーに見せる影響を与えたい場合は、postMessage 等でページに伝え、ページ側で UI を更新させます。
Web Worker に Service Worker は必要ですか?
いいえ。両者は独立しています。
- Web Worker:重い JavaScript をメインスレッドから切り離して実行するため。
- Service Worker:ネットワークレベルの機能(オフライン、キャッシュ、背景同期、プッシュ)を提供するため。
どちらも単独で使えますし、両方を組み合わせることもできます。
ワーカーはどの程度サポートされていますか?
現代のブラウザでは Web Worker は広くサポートされており、基準的な選択肢です。
Service Worker も主要ブラウザの現在のバージョンで広くサポートされていますが、要件やエッジケースが増えます:
- HTTPS が必要(開発時は
localhostを除く)。 - プッシュ通知など一部の機能はブラウザやプラットフォームによって差があります。
互換性が重要なら、Service Worker 機能は漸進的強化として扱い、まずは確かなコア体験を構築しておき、利用可能なブラウザにだけオフライン/プッシュを追加してください。
これでサイトが自動的に速くなりますか?
自動ではありません。
- Web Worker はメインスレッドでの CPU 重負荷が原因でサイトが遅くなっている場合に効果的です。重い処理を移すことでジャンクを減らせますが、データの送受信にオーバーヘッドがある点は考慮する必要があります。
- Service Worker はネットワークリクエストがボトルネックのときに効果を発揮します。キャッシュとスマートな fetch ハンドリングで再訪問が速くなりますが、誤ったキャッシュはコンテンツの陳腐化を招きます。
本当の効果は、ボトルネックに対して適切なワーカーを選び、計測して改善を確認することから生まれます。
よくある質問
Web Worker を使うべきかどうかはどう判断しますか?
Web Worker は、入力 → 計算 → 出力 と表現でき、DOM を必要としない CPU 負荷の高い処理を行うときに使います。
適した例:大きなペイロードのパース/変換、圧縮、暗号処理、画像/オーディオ処理、複雑なフィルタリングなど。作業が主に UI 更新や頻繁な DOM 読み書きであれば、ワーカーは役に立たず(そもそも DOM にアクセスできません)、使うべきではありません。
Service Worker を使うべきかどうかはどう判断しますか?
ネットワーク制御が必要なときに Service Worker を使います:オフライン対応、キャッシュ戦略、リクエストのルーティング、そして(サポートされていれば)プッシュ通知やバックグラウンド同期など。
「UI が計算中にフリーズする」問題は Web Worker が解決します。「読み込みが遅い/オフラインが使えない」問題は Service Worker の領域です。
Web Worker は Service Worker を必要としますか(またはその逆ですか)?
いいえ。Web Worker と Service Worker は独立した機能です。
- Web Worker:ページから作成して背景で計算を行う。
- Service Worker:ブラウザにインストールされ、リクエストを横取りしたりキャッシュを管理したりする。
どちらか一方だけでも使えますし、計算とオフライン/ネットワーク制御の両方が必要なら両方を組み合わせて使えます。
Web Worker と Service Worker のライフタイムの最大の違いは何ですか?
主に「スコープとライフタイム」の違いです。
- Web Worker:通常はページ/タブに紐づき(特に Dedicated Worker)、ページが閉じられると終了することが多い。
- Service Worker:イベント駆動で、
fetchのようなイベントで起動され、処理後にアイドル時に停止する。ページが開いていなくてもイベントで起動できる点が特徴です。
Web Worker は DOM にアクセスして変更できますか?
いいえ。Web Worker は window / document にアクセスできません。
UI に反映する必要がある場合は、postMessage() でメインスレッドにデータを送り、ページ側で DOM を更新してください。ワーカーは純粋な計算に集中させましょう。
Service Worker は DOM にアクセスできますか?
いいえ。Service Worker も DOM にアクセスできません。
ユーザーに見せる内容を変えたい場合は、Clients API と postMessage() などで制御下のページとやり取りし、ページ側で UI を更新させます。
Web Worker にデータを効率的に送る最適な方法は何ですか?
両方向とも postMessage() を使います。
- メインスレッド → ワーカー:
worker.postMessage(data) - ワーカー → メインスレッド:
self.postMessage(result)
大きなバイナリデータには transferable(例:ArrayBuffer)を使ってコピーを避けると効率的です:
Service Worker でのオフラインキャッシュはどう機能しますか?
Service Worker はアプリとネットワークの間に入って、Cache Storage API を使ってリクエスト/レスポンスを保存・返却できます。
よくある戦略:
- Cache-first:静的アセット向け(CSS・JS・ロゴ)
- Network-first:頻繁に変わるデータ向け(ニュース、フィード)
- Stale-while-revalidate:まずキャッシュを返してから裏で更新
リソース種類(アプリシェル vs API データ)ごとに戦略を分けるのが一般的です。
同じアプリで Web Worker と Service Worker を一緒に使えますか?
はい。ただし役割を明確に分けてください。
一般的なパターン:
- Web Worker:計算(サムネイル生成、大きな JSON の正規化など)
- Service Worker:キャッシュして配信(オフライン/高速な再訪問のため)
- メインスレッド:UI
このように責任を分けると背景処理と配信が混ざらず、予測しやすくなります。
ワーカーが期待通り動かないときの最短のデバッグ手順は?
それぞれの DevTools 表面を使って調べます。
- Web Worker:DevTools のワーカーターゲット(Sources / Console のコンテキスト)を確認し、
onmessageにブレークポイントを置く。プロファイルを取ってメインスレッドが応答性を保っているか確認する。 - Service Worker:Application パネルで登録/スコープを点検し、「Update on reload」や「Unregister」「Skip waiting」などで状態をリセットする。
キャッシュの不具合を調べるときは、実際に何がネットワークから来ているか、キャッシュから来ているかを必ず確認し、オフライン/スロットリングでの再現を試してください。