信頼できるWebhook統合:署名、冪等性、デバッグ
署名検証、冪等性キー、リプレイ保護、顧客報告の高速デバッグワークフローを使って信頼できるWebhook統合を学びます。
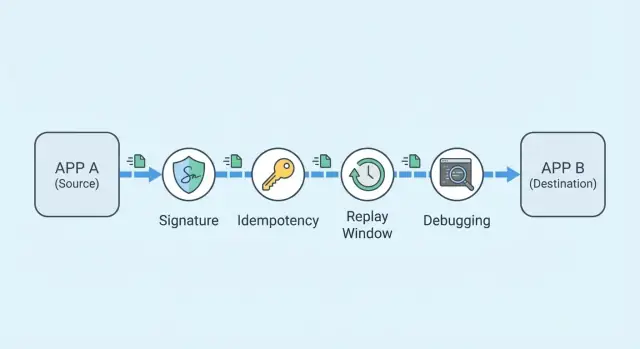
実運用でWebhookが失敗する理由
「Webhookが壊れている」と言われたとき、それは大抵次のどれかです:イベントが届かなかった、イベントが二重に届いた、またはイベントの順序がわかりにくかった。利用者から見るとシステムが「何かを取りこぼした」ように見えます。プロバイダ側はイベントを送っているのに、あなたのエンドポイントが受け取らなかった、受け入れなかった、処理しなかった、あるいは期待した形で記録しなかった、ということです。
Webhookはパブリックなインターネット上にあります。リクエストは遅延したり、再試行されたり、順序が入れ替わって届くことがあります。多くのプロバイダはタイムアウトや非2xx応答を見て積極的に再試行します。これは小さな問題(遅いDB、デプロイ、短時間の障害)を重複や競合状態に変えてしまいます。
ログが不十分だと、これがランダムに見えます。受信リクエストが本物かどうか証明できなければ、安全に処理できません。顧客の報告を特定の配信試行に紐づけられなければ推測に頼ることになります。
現実の失敗はたいてい次のいくつかに分かれます:
- 「消えた」イベント(タイムアウト、エラー返却、ack後に失敗)
- 重複(再試行+ハンドラが冪等でない)
- 順序違い(配信順序=イベント順と仮定した)
- 不審なリクエスト(署名検証がなく、本物と偽物を分けられない)
実用的な目標は単純です:本物のイベントを一度だけ受け入れ、偽物を拒否し、顧客の報告を数分でデバッグできるように明確な跡を残すことです。
Webhookは実際にどう振る舞うか
Webhookは、プロバイダがあなたの公開したエンドポイントへ送る単なるHTTPリクエストです。APIのように取りに行くものではありません。送信側が何か起きたときにプッシュし、あなたの仕事はそれを受け取り、素早く応答し、安全に処理することです。
典型的な配信にはリクエストボディ(多くはJSON)と、受信を検証・追跡するためのヘッダーが含まれます。多くのプロバイダはタイムスタンプ、イベントタイプ(例:invoice.paid)、重複検出用に保存できる一意のイベントIDを付けます。
驚くべき点はこれ:配信はほとんど「ちょうど一回」にはなりません。多くのプロバイダは「少なくとも一回」を目指しており、同じイベントが何度も、場合によっては数分や数時間ずれて届くことがあります。
再試行はありふれた理由で起きます:サーバが遅い、タイムアウト、あなたが500を返す、送信側が200を見逃す、デプロイやトラフィックの山でエンドポイントが一時的に使えない、などです。
タイムアウトは特に厄介です。サーバ側はリクエストを受け取り処理を終えていても、レスポンスが送信者に間に合わないことがあります。プロバイダから見ると失敗なので再試行します。保護がなければ同じイベントを二度処理してしまいます。
良い考え方は、HTTPリクエストを「配信試行(delivery attempt)」として扱うことです。イベントはそのIDで識別されます。処理はプロバイダが何回コールしたかではなく、そのIDに基づいて行うべきです。
平易な言葉でのWebhook署名
Webhook署名は、送信者がそのリクエストを本当に送ったこと、途中で改ざんされていないことを証明する方法です。署名がなければ、誰でもあなたのWebhook URLを推測して偽の「支払い成功」や「ユーザアップグレード」イベントをPOSTできます。さらに悪いことに、本物のイベントが途中で改ざんされ(額、顧客ID、イベントタイプなど)、それでもアプリ上は有効に見えてしまう可能性があります。
最も一般的なパターンは共有シークレットを使ったHMACです。双方が同じ秘密値を持ち、送信者は生のペイロード(通常はリクエストボディのバイト列)をその秘密でHMACして、署名をヘッダー等で送ります。あなたは同じバイト列で同じHMACを計算し、署名が一致するかを確認します。
署名データは通常HTTPヘッダーに入ります。プロバイダによってはタイムスタンプも同じヘッダーに含め、リプレイ保護に使えるようにしています。稀に署名をJSONボディ内に埋めるものもありますが、パーサや再シリアライズでフォーマットが変わる危険があるためリスクが高いです。
署名比較は通常の文字列比較を使わないでください。基本的な比較はタイミング差を漏らしてしまい、攻撃者が繰り返し試すことで正しい署名を推測できる恐れがあります。言語や暗号ライブラリの定数時間比較関数を使い、不一致なら拒否してください。
顧客から「あなたのシステムが我々の送っていないイベントを受け入れた」と言われたら、まず署名を確認してください。署名検証が失敗するなら、シークレットが合っていないか、ハッシュ対象のバイト列が間違っている(例えばパース後のJSONを使っている)可能性が高いです。検証が通れば送信者の正当性を信頼して、重複排除や順序、再試行の問題へ進めます。
ステップバイステップ:Webhook署名を検証する
信頼できるWebhook処理は一つの地味なルールから始まります:受け取ったものを検証し、望むものを検証しない。
安全な検証方法
受信した生のリクエストボディをそのままのバイト列で取得してください。検証前にJSONをパースして再シリアライズしないでください。わずかな違い(空白、キー順、ユニコード表現)がバイト列を変え、有効な署名を無効に見せることがあります。
次にプロバイダが署名対象として期待する正確な文字列を再現します。多くのシステムは timestamp + "." + raw_body のような文字列に署名します。タイムスタンプは装飾ではありません。古いリクエストを拒否するためにあります。
共有シークレットと正しいハッシュ(多くはSHA-256)でHMACを計算します。シークレットは安全な場所に保管し、パスワードのように扱ってください。
最後に定数時間比較で計算値とヘッダーの署名を比較します。一致しなければ4xxを返して停止します。決して「とりあえず受け入れる」べきではありません。
簡単な実装チェックリスト:
- ボディは一度バイト列として読み、保管してその同じバイト列を検証に使う。
- 区切りやタイムスタンプのフォーマットを含め、署名された文字列を正確に再現する。
- 正しいシークレットとアルゴリズムでHMACを計算する。
- 署名値を安全に比較し、不一致を拒否する。
- 検証失敗の理由(ヘッダー欠如、タイムスタンプ不正、ミスマッチなど)を、シークレットや完全な署名をログに残さずに記録する。
簡単な例
ある顧客が「JSONパースミドルウェアを追加してからWebhookが動かなくなった」と報告したとします。署名ミスマッチが頻発し、特に大きなペイロードで顕著です。対処法は通常、パースの前に生のボディで検証するように戻し、どの段階で失敗したか(例:「署名ヘッダーがない」や「タイムスタンプがウィンドウ外」)をログに残すことです。その小さな違いだけでデバッグ時間が何時間から数分に短縮することがよくあります。
冪等性キー:一度だけ安全に受け入れる
プロバイダは配信が保証されないので再試行します。サーバが1分ダウンすることもあるし、ネットワーク経路でドロップが起きることもある、ハンドラがタイムアウトすることもあります。プロバイダは「もしかして成功したかも」と判断して同じイベントを再送します。
冪等性キーは、既に処理したイベントを識別するための受付番号です。セキュリティ機能ではなく、署名検証の代替にもなりません。また、並行処理時に安全に保存・確認しないと競合状態は解決しません。
キーの選択はプロバイダが何を提供するかによります。再試行で安定する値を優先してください:
- イベントID(1イベント→1ビジネス変更のときに最良)
- デリバリIDやメッセージID(再試行時に同じ配信識別子が使われるなら良い)
- 安定したフィールドのハッシュ(IDがない場合の最終手段)
Webhookを受けたら、まず一意性ルールでキーをストレージに書き込み、ただ一つのリクエストだけが“勝つ”ようにします。その後でイベントを処理してください。同じキーを再度見たら、重複して作業を繰り返さずに成功を返します。
保存する「レシート」は小さく有用に保ってください:キー、処理ステータス(受信/処理済み/失敗)、タイムスタンプ(初回/最終)、最小限のサマリ(イベントタイプと関連オブジェクトID)。多くのチームは7〜30日キーを保持して、遅い再試行や顧客問い合わせに対応しています。
本物のトラフィックを妨げないリプレイ保護
リプレイ保護はこうした問題を防ぎます:誰かが本物のWebhook(有効な署名付き)をキャプチャして後で再送した場合、ハンドラがそれを新しいものとして扱うと、重複返金や招待の二重送信、状態変化の繰り返しが起きます。
一般的な方法は、ペイロードだけでなくタイムスタンプにも署名することです。Webhookに X-Signature や X-Timestamp のようなヘッダーを含め、受信時に署名とともにタイムスタンプが短いウィンドウ内かを確認します。
時計のずれ(clock drift)が誤判定の主な原因です。あなたのサーバと送信側のサーバが1〜2分ずれていたり、ネットワークが配信を遅らせたりします。余裕を持たせ、拒否理由をログに残してください。
実用的なルール:
abs(now - timestamp) <= windowの条件で受け入れる(例:5分+小さな猶予)。- 実際の安全網は冪等性。ウィンドウ内でも再試行で二重適用されないようにする。
- 時刻で拒否した場合は明確な4xxを返し、受信したタイムスタンプとサーバ時刻をログに残す。
タイムスタンプがない場合、時間だけで真のリプレイ防止はできません。その場合はIDによる冪等性に頼り、次のWebhookバージョンでタイムスタンプを必須にすることを検討してください。
シークレットローテーションも重要です。署名シークレットを切り替えるときは、短期間複数のシークレットを同時に有効にしてください。まず新しいシークレットで検証し、次に古いシークレットでフォールバックします。これによりローリングアウト中の顧客障害を避けられます。もしチームが迅速にエンドポイントを出荷する(例えばKoder.aiでコード生成し、スナップショットとロールバックを使うなど)なら、古いバージョンが短時間生きている可能性があるため、このオーバーラップは助けになります。
リトライしても問題にならないハンドラ設計
リトライは正常です。各配信が重複、遅延、順序違いのいずれかで来る可能性を前提にしてください。ハンドラは1回でも5回でも見た時と同じ振る舞いをするべきです。
リクエストパスは短く保ってください。受け入れに必要な処理だけを行い、重い作業はバックグラウンドジョブに移します。
本番で堅牢な単純なパターン:
- 基本を検証(メソッド、コンテンツタイプ、必須ヘッダー)。
- 正当性検証(署名)。失敗は拒否。
- ペイロードをパースして検証。
- イベントID(または冪等キー)で重複排除。ユニーク制約のあるテーブルを使う。
- イベントIDを含めて作業をキューに入れ、応答する。
署名を検証し、イベントを記録(またはキューに入れ)た後にのみ2xxを返してください。保存する前に200を返すとクラッシュでイベントを失う可能性があります。応答前に重い処理をするとタイムアウトで再試行が発生し、副作用が繰り返されます。
下流システムが遅いことが再試行を厄介にする主因です。メールプロバイダ、CRM、DBが遅ければ、遅延をキューで吸収させてください。ワーカーはバックオフ付きで再試行でき、詰まったジョブをアラートできます。
順序が入れ替わることもあります。例えば subscription.updated が subscription.created より先に届くことがあります。現在の状態を確認してから変更を適用する、アップサートを許す、オブジェクトが見つからないときは(意味があるなら)後で再試行する、などで耐性を持たせてください。
トラブルの元になるよくあるミス
多くの「ランダム」なWebhook問題は自分たちで招いたものです。フラッフィーなネットワークに見えますが、パターンが繰り返され、通常はデプロイ後、シークレット回転後、あるいはパースの小さな変更の後に起きます。
最も一般的な署名バグは「間違ったバイト列をハッシュしている」ことです。先にJSONをパースすると、サーバが再フォーマット(空白、キー順、数値の表現)してしまい、送信者が署名したものと違うボディで検証することになります。常に受信した生のリクエストボディのバイト列で検証してください。
次の大きな混乱の元はシークレットです。ステージングでテストしているつもりが本番のシークレットで検証している、あるいはローテーション後に古いシークレットを残している、などです。顧客が「ある環境だけで失敗する」と言ったら、まずシークレットや設定ミスを疑ってください。
長引く調査につながるミスの例:
- デバッグのためにボディ全体をログに出して、トークンやメール、支払い情報を流出させる。
- 500を返しつつ副作用(メール送信、注文更新)を行う。再試行で副作用が繰り返される。
- 冪等性キーが本当にユニークでない(例えばイベントタイプ+分)。本来のイベントが「重複」として落ちる。
- 2xxを「処理済み」とみなしてしまうが、実際はただキューに入れただけで後に失敗している。
例:顧客が「order.paid が届かなかった」と言う。調査すると、リファクタでリクエストパースミドルウェアを切り替えた後に署名失敗が始まっている。ミドルウェアがJSONを読み込んで再エンコードしているため署名検証が変更後のボディを使っており失敗している。対処は単純だが、そこを見ることを知らないと見逃す。
顧客報告を素早くデバッグする
顧客が「Webhookが来なかった」と言ったら、推測ではなくトレースの問題として扱ってください。プロバイダの一つの配信試行に着目して、それをシステム内で追跡します。
まずプロバイダの配信識別子、リクエストID、イベントIDを取得してください。その単一の値で該当するログエントリを素早く見つけられるはずです。
そこから順番に確認すること:
- 署名検証は通ったか?
- タイムスタンプやリプレイウィンドウのチェックは通ったか(使っている場合)?
- 冪等性は新規として扱ったか、重複として扱ったか?
次にプロバイダに何を返したか確認します。遅い200は500と同様に問題を引き起こします(プロバイダがタイムアウトして再試行するため)。ステータスコード、レスポンスタイム、ハンドラが重い作業前にackしたかを見てください。
再現が必要な場合は安全に行ってください:ヘッダーの鍵部分と生ボディを赤字削除したサンプルを保存し、同じシークレットと検証コードでテスト環境にリプレイします。
10分で実行できる簡易チェックリスト
Webhook統合が「ランダムに」失敗し始めたら、完璧を目指すよりスピードが大事です。この手順はよくある原因を掴みます。
まず一つの具体例を引き出す:プロバイダ名、イベントタイプ、概算タイムスタンプ(タイムゾーン付き)、顧客が見ているイベントIDのいずれか。
その上で確認する点:
- 署名検証は受信した生のリクエストボディバイトを使っており、その環境で正しいシークレットを使っているか。
- リプレイチェックは実際の再試行挙動に合っているか(サーバ時計が正しいか)。
- 冪等性が本当に重複排除しているか(ユニーク制約、処理前に書き込む、保持期間が妥当)。
- ハンドラは検証と永続記録/キューイングの後にのみackしているか。
- ログに検索しやすい最小限のレシートが含まれているか:provider, event_id, signature_ok, replay_ok, idempotency_status, response_code, latency_ms。
プロバイダが「20回再試行した」と言うなら、まずは典型的なパターンを確認:誤ったシークレット(署名失敗)、時計ずれ(リプレイウィンドウ)、ペイロードサイズ制限(413)、タイムアウト(応答なし)、下流依存の5xxの連続。
例:"届かなかったイベント"報告を端から端まで追跡する
顧客から「昨日 invoice.paid イベントを見逃した。我々のシステムが更新されなかった」とメールが来たとします。素早く追跡する方法:
まず、プロバイダが配信を試みたか確認します。イベントID、タイムスタンプ、宛先URL、あなたのエンドポイントが返した正確なレスポンスコードを取得してください。再試行があれば、最初の失敗理由と後で成功したかを記録します。
次にエッジであなたのコードが何を見たか検証します:そのエンドポイントに設定された署名シークレットを確認し、生のリクエストボディで署名検証を再計算し、受信タイムスタンプを許容ウィンドウと照らし合わせます。
再試行時のリプレイウィンドウに注意してください。ウィンドウが5分でプロバイダが30分後に再試行したなら、正当な再試行を拒否している可能性があります。そのポリシーが意図的で文書化されているかを確認してください。意図していないならウィンドウを広げるか、冪等性が主な防御になるようにロジックを変えます。
署名とタイムスタンプが問題なければ、イベントIDをシステム内で追跡し、処理したか、重複として扱ったか、あるいは破棄したかを確認します。
よくある結論:
- 重複扱い:冪等性キーが既にあり、200を返してビジネスロジックは再実行しなかった。
- 拒否:バリデーション失敗(署名ミスマッチ、タイムスタンプ外、ヘッダー欠落)。
- タイムアウト:ハンドラが遅く、プロバイダが失敗とみなして再試行した。
顧客への回答は簡潔かつ具体的に:
「10:03と10:33 UTCに配信試行を受け取りました。最初は10秒でタイムアウトしました;リトライは我々の5分ウィンドウ外のタイムスタンプだったため拒否されました。ウィンドウを広げ、ackを早くする変更を加えました。必要ならイベントID X を再送してください。」
次のステップ:再現可能にする
Webhookの火災を止める最速の方法は、すべての統合で同じプレイブックに従うことです。送信者と合意する契約を文書化してください:必須ヘッダー、正確な署名方式、使うタイムスタンプ、ユニークと見なすID。
次に、各配信試行で何を記録するかを標準化します。小さなレシートログで十分なことが多いです:received_at, event_id, delivery_id, signature_valid, idempotency_result (new/duplicate), handler_version, response status。
成長しても有用なワークフロー:
- 署名を検証し、ビジネスアクションを実行せずに2xxを返す専用のテストエンドポイントを用意する。
- デバッグとリプレイのために生のリクエストボディと主要ヘッダーを短期間保存する。
- 保存したイベントを同じハンドラ経路で安全に再処理できるリプロセスジョブを作る。
- サポート、QA、エンジニアリングが共有する内部チェックリストを一つ作る。
もしKoder.ai (koder.ai)でアプリを構築するなら、Planning ModeでまずWebhook契約を定義(ヘッダー、署名、ID、再試行挙動)し、その後に一貫したエンドポイントとレシート記録を生成するのが便利です。その一貫性が、デバッグを英雄的な対応ではなく迅速な手順にします。
よくある質問
なぜWebhookは本番で“ランダムに”失敗したり重複したりするように見えるのですか?
Because webhook delivery is usually at-least-once, not exactly once. Providers retry on timeouts, 5xx responses, and sometimes when they don’t see your 2xx in time, so you can get duplicates, delays, and out-of-order deliveries even when everything is “working.”
Webhookリクエストを処理する際の最も安全な基本フローは何ですか?
Default to this rule: verify the signature first, then store/dedupe the event, then respond 2xx, then do heavy work asynchronously.
If you do heavy work before replying, you’ll hit timeouts and trigger retries; if you reply before recording anything, you can lose events on crashes.
署名検証でミスマッチを避けるにはどうすればいいですか?
Use the raw request body bytes exactly as received. Don’t parse JSON and re-serialize before verification—whitespace, key order, and number formatting changes can break signatures.
Also make sure you’re recreating the provider’s signed payload precisely (often timestamp + "." + raw_body).
署名検証に失敗したとき、エンドポイントはどうすべきですか?
Return a 4xx (commonly 400 or 401) and do not process the payload.
Log a minimal reason (missing signature header, mismatch, bad timestamp window), but don’t log secrets or full sensitive payloads.
Webhookの冪等性キーとは何で、どの値を使うべきですか?
An idempotency key is a stable unique identifier you store so retries don’t re-apply side effects.
Best options:
- Event ID (ideal when one event maps to one business change)
- Delivery/message ID (if it stays constant across retries)
- Hash of stable fields (last resort)
Enforce it with a unique constraint so only one request wins under concurrency.
競合条件なくWebhookを重複排除するにはどうすればいいですか?
Write the idempotency key before doing side effects, with a uniqueness rule. Then either:
- Mark it processed after success, or
- Record a failure status so you can retry safely
If the insert fails because the key already exists, return 2xx and skip the business action.
正当なリトライを妨げずにリプレイ保護を追加するには?
Use a timestamp in the signed data and reject requests outside a short window (for example, a few minutes).
To avoid blocking legitimate retries:
- Allow some clock drift
- Log your server time and received timestamp on rejection
- Treat idempotency as the main protection against duplicates; the time window is mainly to stop late replays
順不同のWebhookイベントはどう扱うべきですか?
Don’t assume delivery order equals event order. Make handlers tolerant:
- Use upserts where possible
- Check current state before applying changes
- If an object isn’t found, consider retrying later (via a queue) instead of permanently failing
Store the event ID and type so you can reason about what happened even when order is weird.
Webhookのデバッグで推測にならないように何をログすべきですか?
Log a small “receipt” per delivery attempt so you can trace one event end-to-end:
- provider, event_id, delivery_id
- signature_ok, replay_ok
- idempotency result (new/duplicate)
- response_code, latency_ms
- timestamps (received/first_seen/last_seen)
Keep logs searchable by event ID so support can answer customer reports quickly.
Webhookが“届かなかった”というカスタマー報告を素早く調査する方法は?
Start by asking for a single concrete identifier: event ID or delivery ID, plus an approximate timestamp.
Then check in this order:
- Signature verification result
- Timestamp/replay window result (if used)
- Idempotency outcome (new vs duplicate)
- What you returned (status code + latency)
If you build endpoints using Koder.ai, keep the handler pattern consistent across projects (verify → record/dedupe → queue → respond). Consistency makes these checks fast when incidents happen.