2025年7月27日·1 分
言語・データベース・フレームワークが一体として動く仕組み
言語、データベース、フレームワークが一体となってどう動くかを学ぶ。トレードオフ、統合ポイント、整合したスタックを選ぶ実践的な方法を比較します。
言語、データベース、フレームワークが一体となってどう動くかを学ぶ。トレードオフ、統合ポイント、整合したスタックを選ぶ実践的な方法を比較します。
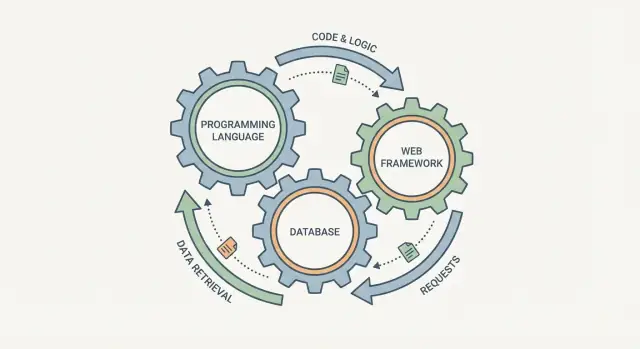
プログラミング言語、データベース、ウェブフレームワークを独立したチェックボックスのように選びたくなりますが、実際には連動する歯車のように振る舞います:ひとつを変えれば、他も影響を受けます。
ウェブフレームワークはリクエストの扱い方、データのバリデーション、エラーの出し方を規定します。データベースは「簡単に保存できる」ものの形を決め、情報の問合せ方法や複数ユーザーが同時に動くときの保証を与えます。言語はその間に位置し、ルールを安全に表現できるか、並行処理をどう扱うか、どんなライブラリやツールを使えるかを決定します。
スタックを単一のシステムとして扱うとは、各部分を孤立して最適化しないということです。目指す組み合わせは次のようなものです:
この記事は実践的で意図的に技術詳細には深入りしません。データベース理論や言語実装の暗記は不要で、選択がアプリ全体にどのように波及するかを見ることが目的です。
簡単な例:高度に構造化され、レポート重視の業務データをスキーマレスなデータベースで扱うと、ルールがアプリコードに散らばり、後の分析が混乱しがちです。同じドメインをリレーショナルDBと、一貫したバリデーションとマイグレーションを促すフレームワークで組み合わせれば、製品が進化してもデータが整合したまま維持されます。
スタックを一緒に設計するということは、3つの別々の賭けではなく、1つのトレードオフのセットを設計することです。
スタックを考えるときに役立つのは、ユーザーからのリクエストがシステムに入り、レスポンス(と保存されたデータ)が出てくる単一のパイプラインとして見ることです。言語、フレームワーク、データベースは独立した選択肢ではなく、その旅路の3つの部分です。
顧客が配送先住所を更新する場面を想像してください。
/account/address)。バリデーションが入力をチェックする。これら三つが揃うと、リクエストは滑らかに流れます。揃わないと、ぎこちないデータアクセスや漏れるバリデーション、微妙な整合性バグが発生します。
多くの「スタック論争」は言語やデータベースのブランドから始まりますが、より良い出発点はデータモデルです。なぜなら、それがバリデーション、クエリ、API、マイグレーション、チームのワークフローに自然か苦痛かを静かに決めるからです。
アプリケーションは通常、次の4つの形を同時に扱います:
コアデータとこれらの形の間を常に変換していると疲弊します。コアデータが密に接続されている(ユーザー ↔ 注文 ↔ 製品)なら、行とJOINがロジックを単純に保ちます。エンティティごとに可変フィールドが多いならドキュメントは手間を減らしますが、横断的な集計が必要になると問題が出ます。
データベースに強いスキーマがあると、多くのルールをデータ近くに置けます:型、制約、外部キー、一意性。これによりサービス間での重複チェックが減ります。
柔軟な構造ではルールが上位(アプリ)に移り、バリデーションコードやバージョン付きペイロード、バックフィル、慎重な読み取りロジック(「フィールドが存在するなら…」)が必要になります。週単位で要件が変わるときは有効ですが、フレームワークとテストの負担が増えます。
あなたのモデルはコードが主に何をするかを決めます:
これにより言語やフレームワークの要件が変わります:強い型付けはJSONフィールドの微妙なズレを防げますし、スキーマが頻繁に進化するなら成熟したマイグレーションツールが重要になります。
モデルを先に選んでください。正しいフレームワークとデータベースの選択はその後で明確になることが多いです。
トランザクションはアプリが静かに依存する「全か無か」の保証です。チェックアウトが成功するとき、注文レコード、支払い状態、在庫更新がすべて適用されるか、まったく適用されないことを期待します。その約束がないと、稀だがコストの高い再現しにくいバグが発生します。
トランザクションは複数のDB操作を単一の作業単位にまとめます。途中で何かが失敗した場合(バリデーションエラー、タイムアウト、プロセスクラッシュなど)、DBは前の安全な状態にロールバックできます。
これは金銭フロー以外でも重要です:アカウント作成(ユーザ行+プロファイル行)、コンテンツ公開(投稿+タグ+検索ポインタ)など、複数テーブルに触れるワークフローで必要です。
整合性は「読み取りが現実に一致する」こと、速度は「すぐに何かを返す」ことです。多くのシステムはここでトレードオフをします:
よくある失敗は、最終的整合性のセットアップを選んでおきながら、コードは強い整合性を期待して書かれていることです。
フレームワークやORMは、複数のsaveを呼んだだけでトランザクションを自動作成したりはしません。明示的なトランザクションブロックが必要なものもあれば、リクエストごとにトランザクションを開始するものもあり、それがパフォーマンス問題を隠すことがあります。
リトライも難しい:ORMはデッドロックや一時的な失敗でリトライすることがありますが、そのコードは二重実行に対して安全でなければなりません。
部分書き込みはAを更新してからBの更新に失敗する時に起きます。重複アクションはタイムアウト後のリトライで起きやすく、特にカード課金やメール送信をトランザクションコミット前に行うと危険です。
簡単なルール:副作用(メール、Webhook)はDBコミット後に行い、操作はユニーク制約や冪等キーで冪等にすること。
これはアプリコードとDBの間の「翻訳層」です。日常的には、ここでの選択がデータベースのブランドよりも重要になることがよくあります。
ORM(Object-Relational Mapper)はテーブルをオブジェクトのように扱えます:Userを作り、Postを更新するとORMが裏でSQLを生成します。共通作業を標準化し繰り返し作業を隠すので生産的です。
クエリビルダーはより明示的で、コードでSQLライクなクエリを組み立てます(チェーンや関数)。まだ「ジョイン、フィルタ、グループ」と考えるが、パラメータ安全性と合成性があります。
Raw SQLは実際のSQLを書くこと。複雑なレポーティングクエリでは直接的で明快ですが、手作業と慣行が必要です。
型安全な言語(TypeScript、Kotlin、Rust)は、クエリや結果形状を早期に検証できるツールへと押し出します。これによりランタイムの驚きが減りますが、型のズレを防ぐためにデータアクセスを集中させたくなります。
柔軟なメタプログラミングが得意な言語(Ruby、Python)はORMが自然で早い反復を可能にしますが、隠れたクエリや暗黙の振る舞いが理解しにくくなることがあります。
マイグレーションはスキーマ変更のバージョン化されたスクリプトです:カラム追加、インデックス作成、データのバックフィル。目標は簡単:誰でもアプリをデプロイして同じDB構造を得られること。マイグレーションをレビューし、テストし、場合によってはロールバックできるように扱ってください。
ORMは気づかないうちにN+1クエリを生成したり、不要な巨大な行をフェッチしたり、ジョインを扱いにくくすることがあります。クエリビルダーは読みにくいチェーンになり、Raw SQLは複製や不整合を生みやすい。
良いルールは:意図が明白である限り最も単純な道具を使うこと。重要な経路では実行されるSQLを確認すること。
ページが遅いと感じるとき、人は「データベースのせいだ」と言いがちですが、ユーザーが体感する遅延の多くはリクエストパス全体にまたがる小さな待ち時間の合計です。
単一リクエストは通常、次のコストを支払います:
たとえDBが5msで応答できても、アプリが1リクエストあたり20クエリ実行したり、I/Oでブロックしたり、巨大なレスポンスのシリアライズに30msかけたりすれば体感は遅くなります。
新しいDB接続を開くのは高コストで、負荷時にはDBを圧倒します。接続プールは既存接続を再利用し、リクエストが毎回接続確立コストを払わないようにします。
注意点:適切なプールサイズはランタイムモデルに依存します。高並列な非同期サーバは同時に大量の接続要求を作る可能性があり、プール制限がなければキューイングやタイムアウト、騒々しい失敗が起きます。逆に厳しすぎるとアプリがボトルネックになります。
キャッシュはブラウザ、CDN、プロセス内キャッシュ、共有キャッシュ(Redisなど)に置けます。同じ結果が多数リクエストされるときに有効です。
しかしキャッシュでは救えないもの:
プログラミング言語のランタイムはスループットを形作ります。リクエストごとにスレッドを作るモデルはI/O待ちでリソースを浪費しがちです。非同期モデルは並列性を高めますが、バックプレッシャ(プール制限など)を必須にします。だからパフォーマンス調整はスタック全体の問題です。
セキュリティはフレームワークプラグインやDB設定で「後付け」するものではありません。言語/ランタイム、ウェブフレームワーク、データベースの間で「常に真でなければならないこと」についての合意です—開発者が間違ったり新しいエンドポイントが追加されても守られるべきこと。
認証(これは誰か?)は通常フレームワークのエッジにあります:セッション、JWT、OAuthコールバック、ミドルウェア。認可(何ができるか?)はアプリロジックとデータルールの両方で一貫して強制されるべきです。
よくあるパターン:アプリが意図を判断する(「このユーザーはこのプロジェクトを編集できるか?」)、DBが境界を強制する(テナントID、所有権制約、行レベルポリシー)。認可がコントローラだけにあると、バックグラウンドジョブや内部スクリプトが簡単にそれを迂回します。
重要な項目は両方で扱ってください:
これにより、二つのリクエストが競合したときや新しいサービスが異なる書き方をしたときに「あり得ない状態」が減ります。
シークレットはランタイムとデプロイワークフロー(環境変数、シークレットマネージャ)で扱い、コードやマイグレーションにハードコーディングしないでください。暗号化はアプリ側(フィールド単位の暗号化)かDB側(at-rest暗号化、KMS)で行えますが、鍵のローテーションやリカバリの責任を明確にしておく必要があります。
監査も共有責任です:アプリは意味のあるイベントを出し、DBは必要に応じて追記専用の監査テーブルや制限付きアクセスの不変ログを保持します。
アプリロジックを過信することが古典的な失敗です:制約の欠如、無音のNULL、管理者フラグがチェックなしで保存されるなど。対策は単純:バグは起きる前提で設計し、データベースが危険な書き込みを拒否できるようにしておくことです(自分のコードからでも)。
スケーリングが失敗する理由は「データベースが耐えられないから」というより、負荷の形が変わったときにスタック全体がうまく反応できないことです:あるエンドポイントが人気になり、あるクエリがホットになり、あるワークフローがリトライを始めるときに壊れます。
多くのチームがぶつかる初期のボトルネック:
last_seen、キューテーブル)、全体が遅くなる。迅速に対応できるかは、フレームワークとDBツールがクエリプラン、マイグレーション、接続プール、セーフなキャッシングパターンをどれだけ見せてくれるかに依存します。
一般的なスケーリング手法は次の順で現れることが多い:
スケーラブルなスタックはバックグラウンドタスク、スケジューリング、安全なリトライを一級でサポートする必要があります。
ジョブシステムが冪等性を保証できないと(同じジョブが二回走って二重請求や二重送信が起きる)、データ破損に"スケール"してしまいます。暗黙のトランザクションや弱い一意制約、OpaqueなORM挙動に頼る初期選択は、アウトボックスパターンやほぼ一度だけ(exactly-once-ish)のワークフローを導入する際の障害になります。
初期の整合が将来を楽にします:整合性要件に合うデータベースを選び、リプリカ、キュー、パーティショニングへの次の一歩がサポートされているフレームワークエコシステムを選んでください。
スタックが「使いやすい」と感じられるのは、開発と運用が同じ前提を共有しているときです:アプリの起動方法、データの変化方法、テストの走らせ方、障害時に何が起きたか知る方法。これらが合わないとチームは接着コード、脆いスクリプト、手作業のランブックに時間を浪費します。
高速なローカルセットアップは機能です。新しい仲間がクローンして、インストールし、マイグレーションを実行し、現実に近いテストデータを数分で整えられるワークフローを好みます。
通常は:
フレームワークのマイグレーションツールがデータベース選択と戦うなら、スキーマ変更が小さなプロジェクトになってしまいます。
スタックは次を書くのを自然にするべきです:
失敗モードとしては、統合テストのセットアップが遅いためチームがユニットテストだけに頼ることがあります。多くの場合はテストDBのプロビジョニング、マイグレーション、フィクスチャが整備されていないのが原因です。
レイテンシが急増したとき、フレームワークからDBへの1リクエストを追跡できる必要があります。
一貫した構造化ログ、基本的なメトリクス(リクエスト率、エラー、DB時間)、クエリ時間を含むトレースがあると良いでしょう。簡単な相関IDがアプリログとDBログの両方に出ていれば「推測」ではなく「発見」が可能になります。
運用は開発から続くものです。次のようなツールを選んでください:
ローカルで復元やマイグレーションのリハーサルができなければ、実際に問題が起きたときにうまく対処できません。
スタック選定は「最高のツール」を選ぶことではなく、現実的制約下で一緒に動くツールを選ぶことです。以下のチェックリストで早期に整合を促してください。
2–5日で時間箱を切り、薄い縦切りを作る:ひとつのコアワークフロー、ひとつのバックグラウンドジョブ、ひとつのレポート系クエリ、基本的な認証。開発フリクション、マイグレーションの扱いやすさ、クエリの明瞭さ、テストのしやすさを測定します。
探索を加速したければ、Koder.ai のようなツールはチャット主導でスナップショット/ロールバックを使いながらUI、API、DBからなる動く縦切りを素早く生成し、方針決定のための基盤を作るのに役立ちます。
Title:
Date:
Context (what we’re building, constraints):
Options considered:
Decision (language/framework/database):
Why this fits (data model, consistency, ops, hiring):
Risks & mitigations:
When we’ll revisit:
優秀なチームでもスタックミスマッチに陥ります—個別では問題なさそうに見えても、システムが組み上がると摩擦を生む選択です。良いニュースは:ほとんどが予測可能であり、いくつかのチェックで回避できます。
トレンドだからという理由でDBやフレームワークを選び、実際のデータモデルが曖昧なままにするのは古典的な匂いです。もう一つは早すぎるスケール最適化:何百万人ユーザーのために最適化する前に数百ユーザーを安定して扱えないと、余計なインフラと新たな障害モードを生みます。
またチームが主要な構成要素がなぜ存在するか説明できないスタックはリスク蓄積の兆候です。答えが「みんな使っているから」なら再考を。
多くの問題は継ぎ目で発生します:
これらは「DBの問題」でも「フレームワークの問題」でもなく、システムの問題です。
動く部品は少なく、よく使う作業に対して一つの明確な道を用意してください:マイグレーション方式は一つ、クエリスタイルは主要機能は一つ、サービス間での慣習を統一する。フレームワークがあるパターン(リクエストライフサイクル、DI、ジョブパイプライン)を奨励するなら、混ぜるよりその流儀に従うほうが良いです。
次のようなときに決定を見直してください:本番インシデントが繰り返すとき、開発者の摩擦が解消されないとき、または新しいプロダクト要件がデータアクセス形態を根本から変えるとき。
安全に変えるには継ぎ目を隔離すること:アダプタ層を導入し、段階的に移行(デュアルライトやバックフィル)、自動化テストでパリティを証明してからトラフィックを切り替える。
プログラミング言語、ウェブフレームワーク、データベースを選ぶことは三つの独立した決定ではなく、三か所に表現された一つのシステム設計決定です。最良の選択は、あなたのデータ形状、整合性要件、チームのワークフロー、そしてプロダクトの成長想定に合致する組み合わせです。
選択の理由を書き留めてください:予想されるトラフィックパターン、許容できるレイテンシ、データ保持ルール、許容する障害モード、今は明示的に最適化していないもの。これはトレードオフを可視化し、将来の仲間が「なぜ」を理解し、要件変更時の無意識のアーキテクチャ漂流を防ぎます。
現在のセットアップをチェックリストに通し、決定が噛み合っていない箇所(例:ORMと戦うスキーマ、バックグラウンド作業が面倒なフレームワーク)を書き出してください。
新方向を模索するなら、Koder.aiのようなツールでベースラインアプリ(一般的にはウェブはReact、サービスはGo+PostgreSQL、モバイルはFlutterなど)を素早く生成して比較し、長期的な構築にコミットする前に検証できます。
さらに深く読みたい場合は /blog の関連ガイド、/docs の実装詳細、/pricing のサポートとデプロイオプション比較を参照してください。
パイプライン全体として扱ってください:フレームワーク → コード(言語) → データベース → レスポンス。どれか一つが他を阻害する(例:スキーマレスな保存先+大量レポーティング)と、接着コードや重複したルール、デバッグしにくい整合性の問題に多くの時間を取られます。
まずはコアなデータモデルと最も頻繁に行う操作から始めてください:
モデルがはっきりすると、必要なデータベース機能やフレームワーク機能が自ずと見えてきます。
データベースに強いスキーマがあれば、ルールをデータに近いところに置けます:
NOT NULL、一意性CHECK 制約柔軟な構造ではルールがアプリケーション側に移り(バリデーション、バージョン管理されたペイロード、バックフィル)、初動は速くてもテスト負荷やサービス間のズレが増えます。
複数の書き込みが一緒に成功するか失敗するかを保証する必要があるときにトランザクションが重要です(例:注文+支払い状態+在庫更新)。トランザクションを無視すると:
副作用(メールやWebhook)はコミット後に行い、操作はユニーク制約や冪等キーで冪等にしてください。
意図を明確に保てる最もシンプルなツールを選んでください:
N+1や暗黙の動作を隠すことがある。重要な経路では、実際に発行されるSQLを必ず確認してください。
スキーマとコードを同期させ、マイグレーションを『本番用コード』として扱ってください:
マイグレーションが手作業で不安定だと環境が漂流し、デプロイは危険になります。
リクエスト全体のプロファイルを行ってください。遅延は多くの小さな待ちが合わさった結果です:
DBが5msで答えられても、アプリが20クエリ発行したりI/Oでブロックしたりすれば体感は遅いままです。
接続プールは接続確立コストを避け、DBを保護するために使います。実務的なアドバイス:
プールが不適切だと、トラフィック急増時にタイムアウトや騒々しい障害として表れます。
両方を使ってください:
NOT NULL、CHECKこれにより、リクエストの競合やバックグラウンドジョブ、忘れられたエンドポイントによる“ありえない状態”を減らせます。
2〜5日で時間箱を切った小さなPoCを作り、実際の継ぎ目を検証してください:
その後、1ページの意思決定記録を書いて( /docs や /blog の関連ガイドも参照)、変更が意図的であるようにしてください。