2025年10月30日·2 分
プロダクト別に実験結果を追跡するウェブアプリの作り方
プロダクト横断の実験結果を追跡するウェブアプリの作り方:データモデル、メトリック、権限、統合、ダッシュボード、信頼できる報告の設計。
プロダクト横断の実験結果を追跡するウェブアプリの作り方:データモデル、メトリック、権限、統合、ダッシュボード、信頼できる報告の設計。
ほとんどのチームが実験で失敗するのはアイデア不足ではなく、結果が散在しているからです。あるプロダクトは分析ツールのチャート、別のプロダクトはスプレッドシート、さらに別はスライドデッキのスクリーンショット。数ヶ月後には「これを既にテストしたか?」や「どのバージョンが勝ち、どのメトリック定義を使ったか?」のような単純な質問に誰も答えられなくなります。
実験トラッキングのウェブアプリは、複数のプロダクトやチームにまたがって何をテストしたか、なぜ、それをどう計測したか、何が起きたかを中央にまとめるべきです。これがないと、レポートの再作成に時間を浪費し、数値の議論に時間を取り、学びが検索できないために古いテストをやり直してしまいます。
これは単なるアナリスト向けツールではありません。
優れたトラッカーは次を可能にしてビジネス価値を生みます:
このアプリは主に実験結果の追跡と報告を目的とし、実験をエンドツーエンドで実行することを主目的にしないでください。既存のツール(フィーチャーフラグ、分析、データウェアハウス)にリンクできる一方で、実験の構造化された記録と最終的な合意解釈を所有します。
MVPはドキュメントやスプレッドシートを探し回ることなく2つの質問に答えられるべきです:何をテストしているかと何を学んだか。プロダクト横断で使える少数のエンティティとフィールドから始め、チームが実際に痛みを感じたときだけ拡張してください。
データモデルはシンプルに保ち、すべてのチームが同じ方法で使えるように:
初日から一般的なパターンをサポート:
ロールアウトが最初は厳密な統計を使わなくても、実験と並列で追跡することで「記録のない“テスト”」を繰り返すのを防げます。
作成時には、後でテストを解釈するために必要な項目だけを要求してください:
構造化することで結果を比較可能にします:
これだけ整えれば、追加の高度な分析や自動化を入れる前でもチームは実験を確実に見つけ、設定を理解し、結果を記録できます。
クロスプロダクトの実験トラッカーはデータモデルに成功/失敗がかかっています。IDが衝突したり、メトリックがずれたり、セグメントが不整合だと、ダッシュボードは「見た目」は正しいが誤ったストーリーを伝えてしまいます。
識別子戦略を明確に始めてください:
product_id:リネームに耐える安定ID(表示名をキーに使わない)experiment_key:人間に読みやすいスラッグ(例:checkout_free_shipping_banner)と不変の experiment_idvariant_key:control, treatment_a のような安定ラベルこれにより「Web Checkout」と「Checkout Web」が同じものかどうかを推測する必要がなくなります。
コアエンティティは小さく明示的に保つ:
計算が外部で行われても、出力(results)を保存することで高速ダッシュボードと信頼できる履歴が作れます。
メトリックや実験は静的ではありません。次をモデル化してください:
これにより、先月の実験結果が誰かのKPI更新で変わってしまう事態を防げます。
国、デバイス、プラン階層、新規vsリピーターのような一貫したセグメントを計画してください。
最後に、誰がいつ何を変更したか(ステータス変更、トラフィックスプリット、メトリック定義の更新)を記録する監査トレイルを追加します。信頼、レビュー、ガバナンスに不可欠です。
トラッカーがメトリック計算を間違える(あるいはプロダクト間で不整合がある)と、結果は単なる“意見”になってしまいます。これを防ぐ最速の方法は、メトリックを個別のクエリ断片ではなく共有のプロダクト資産として扱うことです。
定義、計算ロジック、所有権の単一の情報源を作ってください。各メトリックエントリには:
カタログは人が使う場所に近く(例:実験作成フローからのリンク)、バージョンを付けて履歴説明ができるようにします。
各メトリックがどの“分析単位”を使うかを事前に決めてください:ユーザー単位、セッション単位、アカウント単位、注文単位など。例えば「コンバージョン率(ユーザー単位)」と「コンバージョン率(セッション単位)」は両方正しくても一致しません。
混乱を減らすため、メトリック定義に集計選択を保存し、実験設定時に必須にしてください。各チームが勝手に単位を選べないようにします。
多くのプロダクトはコンバージョンウィンドウを持ちます(例:今日サインアップ、14日以内の購入)。アトリビューションルールを一貫して定義してください:
これらのルールをダッシュボードに表示し、閲覧者が何を見ているかを理解できるようにしてください。
高速なダッシュボードと監査可能性のために両方を保存してください:
これにより素早いレンダリングが可能になり、定義が変わったときに再計算できます。
意味をエンコードする命名標準(例:activation_rate_user_7d, revenue_per_account_30d)を採用し、ユニークIDを必須にし、エイリアスを管理して、類似の重複を作成時に警告する仕組みを持ってください。
トラッカーの信頼性は取り込むデータの信頼性に依存します。目標はすべてのプロダクトで「誰がどのバリアントに露出したか」と「その後何をしたか」を確実に答えられることです。その他のすべて(メトリック、統計、ダッシュボード)はその上に成り立ちます。
多くのチームは次のいずれかを選びます:
いずれを選んでも、プロダクト間で最小イベントセットを標準化してください:exposure/assignment、主要なconversionイベント、結合に十分なコンテキスト(user ID/device ID、timestamp、experiment ID、variant)。
生イベントからトラッカーが報告するメトリクスへのマッピングを明確に定義してください(例:purchase_completed → Revenue, signup_completed → Activation)。このマッピングはプロダクトごとに維持しますが、名前はプロダクト横断で一貫させ、A/B結果ダッシュボードで互換性を保ちます。
早期に完全性を検証してください:
読み込みごとに実行し、重大な場合は即座に知らせるチェックを作ってください:
これらは実験に紐づく警告としてアプリに表示し、ログの奥深くに隠さないでください。
パイプラインは変わります。計装バグやデデュープロジックを修正したら、履歴データを再処理する必要があります。
計画すべきこと:
統合をプロダクト機能として扱い、サポートSDK、イベントスキーマ、トラブルシューティング手順を文書化してください。ドキュメント領域があれば相対パスでリンクします(例:/docs/integrations)。
数値が信頼されなければトラッカーは使われません。目標は数学で驚かせることではなく、意思決定を製品間で再現可能かつ説明可能にすることです。
アプリが報告するのは**頻度主義(p値、信頼区間)かベイズ(改善確率、信用区間)**のどちらかに統一してください。混在すると混乱を招きます(「このテストは勝率97%だが、あっちはp=0.08だ」など)。
実務的ルール:組織が既に理解している手法を選び、用語、デフォルト、閾値を標準化してください。
結果ビューには最低限、次を明確に示してください:
また 分析ウィンドウ、カウント単位(users, sessions, orders)、および 使ったメトリック定義のバージョン も示してください。これらが一貫した報告と議論の差を生みます。
多数のバリアント、多数のメトリック、日次チェックが行われると偽陽性が増えます。各チームに任せるのではなく方針を組み込みましょう:
結果横に自動フラグを表示してください:
数値の横に非技術者向けの短い説明を付けて信頼性を担保します。例:「推定リフトは+2.1%ですが、真の効果は-0.4%〜+4.6%の可能性があり、現時点では勝者と断定する十分な証拠はありません。」
良い実験ツールは人が次に何を見ればよいかと、何をするべきかの2点を素早く答えられるようにします。UIはコンテキスト探索を最小化し、決定状態を明確にしてください。
まずは以下の3ページで多くの用途をカバーします:
リストとプロダクトページではフィルタを高速かつ保持可能に:product, owner, date range, status, primary metric, segment。数秒で「Checkoutの今月実行中でオーナーがMaya、主指標がconversion、セグメントがnew users」などに絞れるべきです。
ステータスは制御語彙として扱い、フリーテキストにしないでください:
Draft → Running → Stopped → Shipped / Rolled back
リスト行、詳細ヘッダー、共有リンクのすべてにステータスを表示し、誰がいつ変えたかと理由を記録してください。これにより“こっそりローンチ”や不明確な結果を防げます。
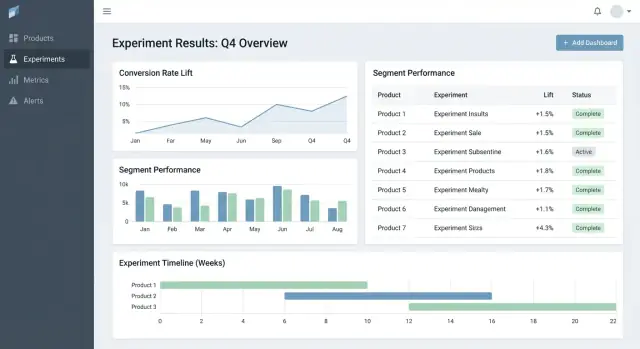
実験詳細ビューでは、メトリックごとにコンパクトな結果表を先頭に置いてください:
詳細チャートは「More details」セクションに隠して、決定者を圧倒しないようにします。
アナリスト用にCSVエクスポート、ステークホルダー向けに共有リンクを追加しますが、アクセスは役割とプロダクト権限に従わせてください。シンプルな「リンクをコピー」ボタンと「CSVエクスポート」アクションで多くのコラボレーション要件は満たせます。
トラッカーが複数プロダクトにまたがるなら、アクセス制御と監査可能性は必須です。これらがあるからこそツールは安全に受け入れられ、レビュー時に信頼されます。
まずはシンプルな役割セットで始め、アプリ全体で一貫させてください:
RBACは中央のポリシーレイヤーで管理し、UIとAPIが同じルールを強制するようにしてください。
多くの組織はプロダクト単位のアクセスが必要です:チームAはProduct Aの実験は見られるがProduct Bは見られない。これを明示的にモデル化(例:user ↔ product memberships)し、すべてのクエリがプロダクトでフィルタされることを保証してください。
敏感なケース(パートナーデータ、規制対象セグメント)では、行レベルの制限を追加します。実践的には実験または結果スライスに感度レベルのタグを付け、閲覧に追加権限を必要とするアプローチが現実的です。
次の2つを別々にログに残してください:
UIで変更履歴を見られるようにし、調査用にはより詳細なログを保管してください。
次のデータの保持ルールを定義してください:
保持はプロダクトや感度で設定可能にし、データ削除が必要な場合は最小限のトゥームストーン記録(ID、削除時刻、理由)を残して報告の整合性を保ちつつ機密情報を削除できるようにします。
トラッカーが真に有用になるのは、単なるp値保存にとどまらず実験ライフサイクル全体をカバーしたときです。ワークフロー機能は散在するドキュメント、チケット、チャートを反復可能なプロセスに変え、学びの再利用を容易にします。
実験を一連の状態(Draft, In Review, Approved, Running, Ended, Readout Published, Archived)としてモデル化してください。各状態には明確な“出口基準”があり、仮説、主要メトリック、ガードレールのような必須事項なしに実験がライブにならないようにします。
承認は重くある必要はありません。プロダクト+データの簡単なレビューステップと、誰がいつ承認したかの監査トレイルがあれば、避けられるミスを防げます。完了後は短いポストモーテムを必須にして「Published」にできるようにし、結果と文脈を確実に残すようにしてください。
次のテンプレートを用意してください:
テンプレートは“白紙恐怖”を減らし、レビューを速くします。プロダクトごとに編集可能にしつつ、共通コアは残してください。
実験は単体で存在しないことが多いので、ユーザーがチケットや仕様、関連の書き起こし(例:/blog/how-we-define-guardrails, /blog/experiment-analysis-checklist)を添付できるようにします。構造化された「Learning」フィールドを保存します:
ガードレール悪化時や遅延データ/メトリック再計算後に結果が大きく変わったときに通知を出します。アラートはアクション可能に:該当メトリック、閾値、期間、対応オーナーを示して認知/エスカレーションできるようにします。
プロダクト、機能領域、対象、メトリック、結果、タグ(例:「pricing」「onboarding」「mobile」)でフィルタできるライブラリを提供してください。共通タグやメトリックに基づく“類似実験”の提案を加え、同じ実験を繰り返さずに過去の学びを活用できるようにします。
“完璧”なスタックは不要ですが、どこにデータがあるか、どこで計算するか、チームがどう結果にアクセスするかの境界は明確にしてください。
多くのチームにとって、シンプルで拡張性のある構成は:
この分離によりトランザクションワークフローは高速になり、ウェアハウスが大規模計算を担えます。
プロトタイプを早く作りたい場合、フォームやダッシュボード、RBACスキャフォールド、監査フレンドリーなCRUDを素早く生成するために Koder.ai のようなvibe-codingプラットフォームを使うのは有効です。そこからデータ契約を分析チームと詰めていくことができます。
通常は三択:
データチームが既に信頼できるSQLを持っている場合はWarehouse-firstが簡単です。低レイテンシやカスタムロジックが必要ならバックエンド重視も可能ですが、アプリ複雑度が上がります。
ダッシュボードは同じクエリを繰り返すことが多いので:
多数のプロダクトや事業部をサポートするなら早めに決める:
妥協案は共有インフラに強い tenant_id モデルと行レベルアクセスを強制するやり方です。
APIは小さく明確に保ってください。大抵は experiments, metrics, results, segments, permissions(+監査用途の読み取り)エンドポイントがあれば十分で、新しいプロダクトを追加するときに配管を書き換えずに済みます。
人々がトラッカーを信用するには、厳格なテスト、明確な監視、予測可能な運用が必要です。特に複数プロダクトやパイプラインが同じダッシュボードに流れる場合は重要です。
イベント取り込み、割当て、メトリックのロールアップ、結果計算の各重要ステップで構造化ログを始めてください。product、experiment_id、metric_id、pipeline run_id のような識別子を含め、単一の結果を入力まで辿れるようにします。
システム指標(APIレイテンシ、ジョブ実行時間、キュー深度)とデータ指標(処理したイベント数、遅延イベントの割合、検証でドロップした割合)を追加し、サービス間のトレースで「なぜこの実験に昨日のデータがないのか?」に答えられるようにします。
データの新鮮さチェックはサイレントな故障を防ぐ最速の方法です。SLAが「毎日9時まで」なら、プロダクトとソースごとに新鮮さを監視し、以下をアラートしてください:
3層のテストを作成してください:
既知の出力を持つ小さな“ゴールデンデータセット”を維持し、回帰を本番に出す前に検出できるようにしてください。
マイグレーションは運用の一部として扱ってください:メトリック定義と結果計算ロジックにバージョンを付け、履歴実験を書き換えないようにします。変更が必要な場合は統制されたバックフィル経路を提供し、監査トレイルに何が変わったかを記録してください。
特定の実験/日付範囲でパイプラインを再実行したり、検証エラーを検査したり、インシデントにステータスを付ける管理ビューを提供してください。影響を受けた実験から直接インシデントノートにリンクして、ユーザーが遅延を理解し未完成データで決定を下さないようにします。
実験トラッキングアプリの展開は“ローンチ日”よりも、何が追跡され、誰が所有し、数値が現実と一致するかの曖昧さを段階的に減らすことが重要です。
まずは1つのプロダクトと少数の信頼度の高いメトリック(例:conversion, activation, revenue)から始めて、エンドツーエンドのワークフローを検証します:実験作成、露出と成果の取り込み、結果計算、決定記録。
最初のプロダクトが安定したら、プロダクトごとに予測可能なオンボーディングで拡張します。各新規プロダクトはカスタムプロジェクトではなく、反復可能なセットアップに感じられるべきです。
要件が長くなる傾向にある組織では、耐久性のあるデータ契約(イベント、ID、メトリック定義)を構築するのと並行して薄いアプリ層を作る二本立てアプローチが有効です。チームはKoder.aiのようなツールでフォーム、ダッシュボード、権限、エクスポートの薄いレイヤーを素早く立ち上げ、採用が進むにつれてハードニング(ソースコードのエクスポートやスナップショットによる段階的ロールバック)を行います。
オンボーディングとイベントスキーマを一貫して行うための軽量チェックリスト:
採用を促すため、実験結果から関連プロダクト領域への“次のステップ”リンクを付けても良い(例:価格実験なら /pricing へのリンク)。リンクは情報的で中立的に保ってください。
ツールが意思決定のデフォルトになっているかを測定:
多くの導入でつまずくのは次の点です:
実験ごとの最終合意された記録を中央集約することから始めてください:
フィーチャーフラグや分析ツールへのリンクは保持して構いませんが、トラッカー自体が構造化された履歴を所有して、結果が検索可能かつ比較可能であり続けることが重要です。
いいえ—スコープを結果の追跡と報告に絞ってください。
実用的なMVPの例:
これにより、実験実行プラットフォーム全体を再構築することなく“散在する結果”の問題を解決できます。
チーム横断で機能する最小モデルは次の通りです:
表示名は編集可能なラベルとして扱い、安定したIDを使ってください:
product_id:名前が変わっても変わらないIDexperiment_id:内部で不変のIDexperiment_key:プロダクト単位で一意にできる読みやすいスラッグセットアップ時に“勝敗基準”を明確にしてください:
この構造により、実験開始前に「勝ち」とは何かが明確になり、後の議論を減らせます。
次の要素を持つ正典(canonical)なメトリックカタログを作成してください:
ロジックを変更する際は既存履歴を上書きせず、新しいバージョンを出して、どの実験がどのバージョンを使ったかを保存してください。
最小限として、露出(assignment)と成果(conversion)の結合が確実であること:
自動チェック例:
1つの“方言”を選んで社内で統一してください:
どちらを採るにせよ、UIには必ず次を表示してください:
アクセス制御は後回しにできない基盤です。まずは:
さらに2種類の監査ログを残してください:
繰り返し可能な順序で展開してください:
避けるべき落とし穴:
product_id)experiment_id + 人間に読みやすい experiment_key)control, treatment_a 等)一貫したスライスが予想される場合は、早めに Segment と Time window を追加してください。
variant_keycontroltreatment_aこれにより衝突を防ぎ、命名のズレによるクロスプロダクト集計ミスを避けられます。
これらの警告は実験ページに表示し、見落とされないようにしてください。
組織的信頼性を得るには、一貫性が高度な数学より重要です。
これがあることでツールは組織横断で安全に採用できます。