2025年8月21日·1 分
知っておきたい6つのSQL結合(簡単でわかりやすい例付き)
INNER、LEFT、RIGHT、FULL OUTER、CROSS、SELFの6種類のSQL JOINを実例で学ぶ。使いどころ、一般的な落とし穴、パフォーマンスの基本をわかりやすく解説します。
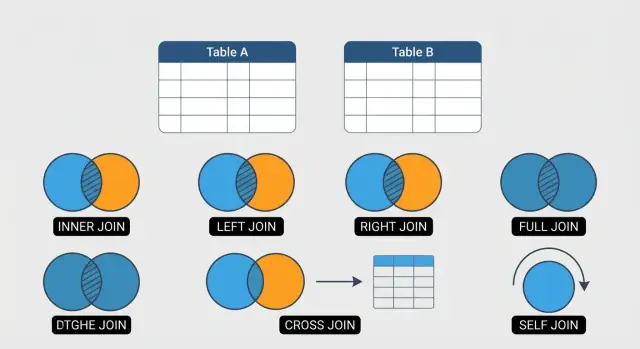
INNER、LEFT、RIGHT、FULL OUTER、CROSS、SELFの6種類のSQL JOINを実例で学ぶ。使いどころ、一般的な落とし穴、パフォーマンスの基本をわかりやすく解説します。
SQLのJOINは、関連する列(通常はID)で2つ以上のテーブルの行を結びつけ、1つの結果セットにまとめる方法です。
実務ではデータベースは繰り返しを避けるために複数のテーブルに分割されます。たとえば、顧客の名前はcustomersテーブルにあり、購入はordersテーブルにあります。JOINは、レポートや分析でそれらを再結合する手段です。
そのため、JOINはレポーティングや分析のあらゆる場面に登場します:
JOINがなければ別々にクエリを実行して手作業で結合する必要があり、遅くてエラーが起きやすく再現性も低くなります。
製品(ダッシュボード、管理画面、内部ツール、顧客ポータル)を関係データベース上で作る場合も、JOINの基礎は重要です。例えば、Koder.aiのようなプラットフォームでReact + Go + PostgreSQLのアプリを自動生成しても、正確な一覧ページやレポート、突合画面を作るには適切なJOINロジックが欠かせません。
このガイドでは日常的によく使う6つのJOINを扱います:
JOINの構文はPostgreSQL、MySQL、SQL Server、SQLiteなどで非常に似ています。FULL OUTER JOINのサポートや一部の挙動に差はありますが、概念と基本パターンは共通です。
例を単純にするために、顧客が注文を行い、注文に支払いが紐づくという一般的な構成の3つの小さなテーブルを使います。
以下のサンプルテーブルは一部の列しか示していませんが、後のクエリではorder_date、created_at、status、paid_atなどの典型的な列を参照します。実運用のスキーマでよくある列だと考えてください。
主キー: customer_id
| customer_id | name |
|---|---|
| 1 | Ava |
| 2 | Ben |
| 3 | Chen |
| 4 | Dia |
主キー: order_id
外部キー: customer_id → customers.customer_id
| order_id | customer_id | order_total |
|---|---|---|
| 101 | 1 | 50 |
| 102 | 1 | 120 |
| 103 | 2 | 35 |
| 104 | 5 | 70 |
注意:order_id = 104はcustomer_id = 5を参照していますが、customersに5は存在しません。こうした「一致しない」ケースはLEFT JOINやFULL OUTER JOINの挙動を確認するのに役立ちます。
主キー: payment_id
外部キー: order_id → orders.order_id
| payment_id | order_id | amount |
|---|---|---|
| 9001 | 101 | 50 |
| 9002 | 102 | 60 |
| 9003 | 102 | 60 |
| 9004 | 999 | 25 |
ここで学びのために重要な点が二つあります:
order_id = 102には2つの支払い行があります(分割支払い)。ordersとpaymentsを結合すると、その注文は2回現れます。これが重複で驚く原因になります。payment_id = 9004はorder_id = 999を参照していますが、ordersに999はありません。これも「一致しない」ケースです。ordersとpaymentsの結合で2行になるINNER JOINは両方のテーブルに一致がある行のみを返します。顧客に注文がなければ結果に出ません。注文が存在しない顧客IDを参照していれば(データ不整合)、その注文も結果に出ません。
「左」テーブルと「右」テーブルを選び、ON句で結合条件を指定します。
SELECT
c.customer_id,
c.name,
o.order_id,
o.order_date
FROM customers c
INNER JOIN orders o
ON o.customer_id = c.customer_id;
ポイントはON o.customer_id = c.customer_idで、どの列で行を対応づけるかを指定している点です。
注文を1つでも出した顧客だけをリストしたいときはINNER JOINが自然です:
SELECT
c.name,
o.order_id,
o.total_amount
FROM customers c
INNER JOIN orders o
ON o.customer_id = c.customer_id
ORDER BY o.order_id;
これは「注文フォローのメールを送る」や「購入がある顧客に対する売上集計」などに有効です。
ON条件を忘れる(または間違った列で結合する)と、意図せずデカルト積(全組み合わせ)になったり、微妙に間違ったマッチが生じます。
やってはいけない例:
SELECT c.name, o.order_id
FROM customers c
JOIN orders o;
常にON(あるいは適切な場合はUSING)で明確な結合条件を指定してください。
LEFT JOINは左テーブルのすべての行を返し、右テーブルに一致があればそのデータを追加します。一致がなければ右側の列はNULLになります。
メインのテーブルの全行を取りつつ、関連データを任意で付けたいときにLEFT JOINを使います。
例:「すべての顧客を表示し、もし注文があればその注文を含める」
SELECT
c.customer_id,
c.name,
o.order_id,
o.order_date
FROM customers c
LEFT JOIN orders o
ON o.customer_id = c.customer_id
ORDER BY c.customer_id;
o.order_idなどはNULLになります。LEFT JOINのよくある使い方は、関連レコードが存在しない項目を探すことです。
SELECT
c.customer_id,
c.name
FROM customers c
LEFT JOIN orders o
ON o.customer_id = c.customer_id
WHERE o.order_id IS NULL;
このWHERE ... IS NULLが、結合で一致が見つからなかった左側の行だけを残します。
右側に複数一致があると左側の行が「重複」して見えます。例えば1人の顧客が3件の注文を持つと、その顧客は3回出力されます。これは期待される動作ですが、顧客数を数えたい場合に誤解を招きます。
例えば次は注文の件数を数えます(顧客数ではない):
SELECT COUNT(*)
FROM customers c
LEFT JOIN orders o
ON o.customer_id = c.customer_id;
顧客数を数えたいなら通常はCOUNT(DISTINCT c.customer_id)のようにキーを基準にします。
RIGHT JOINは右テーブルのすべての行を保持し、一致する左側の行だけを追加します。一致しない場合は左側の列がNULLになります。LEFT JOINの鏡です。
すべての支払いをリストしたい(たとえ注文に紐づかないものがあっても)場合:
SELECT
o.order_id,
o.customer_id,
p.payment_id,
p.amount,
p.paid_at
FROM orders o
RIGHT JOIN payments p
ON o.order_id = p.order_id;
この場合:
paymentsのため)。o.order_idやo.customer_idはNULLになります。通常はテーブルの順序を入れ替えてLEFT JOINに直せます:
SELECT
o.order_id,
o.customer_id,
p.payment_id,
p.amount,
p.paid_at
FROM payments p
LEFT JOIN orders o
ON o.order_id = p.order_id;
この方が「メインにしたいテーブルから始めて、必要な関連をLEFT JOINで付ける」という読み方に沿うため多くのチームで好まれます。
多くのSQLスタイルガイドはRIGHT JOINを避けるよう勧めます。なぜなら、読者がテーブルの主語を逆に考えないといけないためです。
ただし、既存の長いクエリの一部を編集するときに右テーブルを残したままにしたいケースでは、RIGHT JOINは素早い対応手段になります。
FULL OUTER JOINは両テーブルのすべての行を返します。
INNER JOINのように)。NULLになります。NULLになります。注文と支払いの突合は典型例です:
SELECT
o.order_id,
o.customer_id,
p.payment_id,
p.amount
FROM orders o
FULL OUTER JOIN payments p
ON p.order_id = o.order_id;
FULL OUTER JOINはPostgreSQL、SQL Server、Oracleでサポートされています。
MySQLやSQLiteではサポートされていないため、回避策が必要です。
DBがFULL OUTER JOINをサポートしない場合、次のようにLEFT JOINと(場合によっては)RIGHT JOINをUNIONで組み合わせてエミュレートします。
SELECT o.order_id, o.customer_id, p.payment_id, p.amount
FROM orders o
LEFT JOIN payments p
ON p.order_id = o.order_id
UNION
SELECT o.order_id, o.customer_id, p.payment_id, p.amount
FROM orders o
RIGHT JOIN payments p
ON p.order_id = o.order_id;
片側がNULLになっている行は「相手側に存在しなかった」ことを示しており、監査や突合には役立ちます。
CROSS JOINは2つのテーブル間のすべての組み合わせを返します。テーブルAが3行、テーブルBが4行なら結果は3 × 4 = 12行になります(デカルト積)。
用途が限られますが、有用な場面もあります。
sizesとcolorsのように別テーブルにオプションを持っている場合、全バリエーションを作るのに使えます:
SELECT
s.size,
c.color
FROM sizes AS s
CROSS JOIN colors AS c;
結果(3 × 2 = 6行):
行数は掛け算で増えるため、CROSS JOINはすぐに巨大な結果を作ります。入力テーブルが大きい場合は実行しないか、制限やフィルタを必ず組み合わせてください。
SELF JOINは同じテーブルを2回使って互いに関連づけるケースで使います。最もよくあるのは従業員とその上司の関係です。
同じテーブルを2回参照するので、各コピーに別名(エイリアス)を付けてどちらの側かを明確にします。慣例として:
e を従業員(employee)にm をマネージャー(manager)にemployeesテーブルが id, name, manager_id を持つとすると:
SELECT
e.id,
e.name AS employee_name,
m.name AS manager_name
FROM employees e
LEFT JOIN employees m
ON e.manager_id = m.id;
上司がいない従業員(manager_idがNULL)を保持するためにLEFT JOINを使っています。INNER JOINにすると上司がいない人は結果から消えてしまいます。
JOINはテーブル同士の関係を知らないので、どの列で結合するかを明示する必要があります。結合条件はJOINに近い位置に置くのが自然です。
ON:最も柔軟で一般的列名が異なる場合や複雑な条件を使いたい場合はONを使います。
SELECT
c.customer_id,
c.name,
o.order_id,
o.created_at
FROM customers AS c
INNER JOIN orders AS o
ON o.customer_id = c.customer_id;
ONでは複数列での比較や追加条件も書けるため、曖昧さが少なくなります。
USING:同名列のときに短く書けるPostgreSQLやMySQLではUSINGが使え、両テーブルに同名の列がありその列で結合する場合に短く書けます。
SELECT
customer_id,
name,
order_id
FROM customers
JOIN orders
USING (customer_id);
USINGの利点は出力に同名列が1つだけ残ることが多い点です。
結合するとidやcreated_atなど列名が重なることが多いです。SELECT idのように書くとDBが曖昧だとエラーになるか、意図しない列を参照する危険があります。テーブル接頭辞(またはエイリアス)を使いましょう:
SELECT c.customer_id, o.order_id
FROM customers AS c
JOIN orders AS o
ON o.customer_id = c.customer_id;
SELECT *は避ける結合クエリでSELECT *を使うと不要な列を引き込み、重複名の混乱を招き、意図を読み取りにくくします。必要な列だけを指定する習慣をつけると結果がきれいで保守性も上がります。
ONは結合時にどの行をマッチさせるかを決め、WHEREは結合結果の最終行を絞り込みます。このタイミングの違いにより、LEFT JOINがINNER JOINのように振る舞ってしまうことがあります。
「すべての顧客を表示しつつ、最近の有料注文だけを含めたい」とした場合:
SELECT c.customer_id, c.name, o.order_id, o.status, o.order_date
FROM customers c
LEFT JOIN orders o
ON o.customer_id = c.customer_id
WHERE o.status = 'PAID'
AND o.order_date >= DATE '2025-01-01';
問題点:注文がない顧客ではo.statusやo.order_dateがNULLであり、WHEREで弾かれてしまうため、LEFT JOINの意図(左側の全行を保持)が失われます。
SELECT c.customer_id, c.name, o.order_id, o.status, o.order_date
FROM customers c
LEFT JOIN orders o
ON o.customer_id = c.customer_id
AND o.status = 'PAID'
AND o.order_date >= DATE '2025-01-01';
こう書くと、条件に合致する注文があればその注文がつき、合致する注文がなければNULLになって顧客行は残ります。
WHERE o.order_id IS NOT NULLを使うJOINは列を追加するだけでなく行を掛け合わせることで増やします。これが正しい挙動であることが多いですが、合計が突然倍になるなどで驚くことがあります。
一致する行ごとに出力行が作られるためです。
payments × itemsのように掛け合わせが起きます。「顧客ごとに1行」や「注文ごとに1行」を保ちたいなら、多側を先に集約してから結合します:
-- paymentsを注文ごとに1行にまとめる
WITH payment_totals AS (
SELECT
order_id,
SUM(amount) AS total_paid,
COUNT(*) AS payment_count
FROM payments
GROUP BY order_id
)
SELECT
o.order_id,
o.customer_id,
COALESCE(pt.total_paid, 0) AS total_paid,
COALESCE(pt.payment_count, 0) AS payment_count
FROM orders o
LEFT JOIN payment_totals pt
ON pt.order_id = o.order_id;
これにより「1注文 = 1行」の形が保たれます。
SELECT DISTINCTは重複を見かけ上取り除きますが、本質的な問題を隠すことがあるため注意が必要です。
必要な場合だけ、理由が明確なときに使ってください。
結果を信用する前に次を比較してください:
もし数が不意に増えているなら、どのキーで複数マッチが起きているかを調べ、事前集約や別の結合経路を検討します。
JOINが「遅い」と言われるとき、原因は通常「データ量」と「マッチ行の検索のしやすさ(インデックスなど)」です。
インデックスは本の目次のようなもので、無いとDBは多くの行を走査して一致を探す必要があります。結合キーにインデックスがあると、DBは該当する行に素早くジャンプできます。
頻繁に結合に使う列(ON a.id = b.a_idなど)はインデックス候補です。
可能なら安定した一意の識別子で結合してください:
customers.customer_id = orders.customer_idcustomers.email = orders.emailやcustomers.name = orders.name名前やメールは変更され得るし重複することもあります。IDは結合に適し、通常インデックスも張られています。
次の2点でJOINはかなり速くなります:
SELECT *を避ける)例:まずordersを絞ってから結合する
SELECT c.customer_id, c.name, o.order_id, o.created_at
FROM customers c
JOIN (
SELECT order_id, customer_id, created_at
FROM orders
WHERE created_at >= DATE '2025-01-01'
) o
ON o.customer_id = c.customer_id;
アプリのレポートページなどでJOINロジックが正確さを決める場合、スキーマやエンドポイント、UIの雛形作成を高速化するツール(例:Koder.ai)は便利ですが、JOINの正しさは開発速度が上がっても残る重要な責務です。
NULL)NULL)NULLSQLのJOINは、2つ(またはそれ以上)のテーブルの関連する列を照合して1つの結果セットに結合する操作です。多くの場合、主キーと外部キー(例:customers.customer_id = orders.customer_id)を使います。正規化されたテーブル群をレポートや監査、分析で「再接続」するための仕組みです。
INNER JOINは、関係が両方のテーブルに存在する行だけを取得したいときに使います。
「実際に関係が確認できる行」を表示する用途(例:実際に注文した顧客の一覧)に適しています。
メインの(左側の)テーブルの全行を取りつつ、右側の一致するデータを任意で取得したいときはLEFT JOINを使います。
「一致がない」行を見つけるための典型パターンは次の通りです:
SELECT c.customer_id, c.name
FROM customers c
LEFT JOIN orders o ON o.customer_id = c.customer_id
WHERE o.order_id IS NULL;
このクエリは「一度も注文をしたことがない顧客」を返します。
RIGHT JOINは右側のテーブルのすべての行を保持し、一致がなければ左側の列をNULLにします。多くのチームは読みやすさの観点からRIGHT JOINを避けますが、既存の長いクエリを編集するときなどに便利な場合があります。
通常はテーブル順を入れ替えてLEFT JOINで書き換えられます:
FROM payments p
orders o o.order_id p.order_id
FULL OUTER JOINは両方のテーブルの全行を返します。
NULLになります。NULLになります。監査や照合(例:注文と支払いの突合)で、支払いのない注文や注文のない支払いを一度に見たいときに便利です。
MySQLやSQLiteなど一部のDBはFULL OUTER JOINを直接サポートしていません。その場合は LEFT JOIN と RIGHT JOIN(またはLEFT JOINの結果に右側のみの行を追加する形)をUNIONで結合してエミュレートすることが一般的です。
概念:
CROSS JOINは2つのテーブル間のすべての組み合わせを返します(デカルト積)。シナリオ生成(例:サイズ×色)やテストデータ作成では有用です。
注意点:行数が掛け算で増えるため、入力が大きいとすぐに結果が爆発します。小さな入力で使うか、フィルタや制限を組み合わせて運用してください。
SELF JOINは同じテーブルを自分自身に結合することで、テーブル内の行同士の関係を扱えます(例:従業員とその上司)。
同じテーブルを2回使うので別名(エイリアス)が必須です:
FROM employees e
LEFT JOIN employees m
ON e.manager_id = m.id
ONは結合時のマッチ条件を定義し、WHEREは結合後の最終結果をフィルタリングします。LEFT JOINで右側の条件をWHEREに書くと、NULLが除外されてLEFT JOINが事実上INNER JOINになることがあります。
右側の行を制限しつつ左側の全行を保持したいときは、右テーブルに関する条件をに入れてください。
結合が行を「増やす」理由は、結合が一致する行ごとに出力行を作るからです。1対多、または多対多の関係で行が複製されます。
対処法の一つは「多側」を事前に集約してから結合することです(例:支払いをorder_idでSUMしてからordersに結合する)。DISTINCTは最後の手段として使うべきで、問題の根本原因を隠してしまう可能性があります。
orders LEFT JOIN payments(左側の全行+一致)UNION)実装はケースに応じて細かい条件調整が必要です。
ON